手撕Diffusion系列 - 第十一期 - lora微調 - 基于Stable Diffusion(代碼)
目錄
- 手撕Diffusion系列 - 第十一期 - lora微調 - 基于Stable Diffusion(代碼)
- Stable Diffusion 原理圖
- Stable Diffusion的原理解釋
- Stable Diffusion 和Diffusion 的Unet對比
- Lora 微調原理
- Stable Diffusion 添加lora微調代碼
- Part1 添加lora.py文件 - 用于設置lora層以及替換
- 1. 引入相關庫函數
- 2. 定義LoraLayer的類
- 3. lora層的替換
- Part2 添加lora_finetune.py,用于參數微調訓練得到lora參數.pt文件
- 1. 引入相關庫函數
- 2. 替換模型中的注意力機制里面的Wq, Wk, Wv,替換線性層
- Part3 修改 denoise.py,修改測試的時候的lora參數加入
- 1. 引入相關庫函數
- 2. 定義去噪的函數
- 3. 測試-去噪
- 參考
Stable Diffusion 原理圖
Stable Diffusion的原理解釋
Stable Diffusion的網絡結構圖如下圖所示:

- 改動1:利用 AE,VAE,VQVAE 等自編碼器,進行了圖像特征提取,利用正確提取特征后的圖像作為自己原本在Diffusion中的圖像。
- 改動2:在訓練過程中,額外添加了一些引導信息,促使圖像生成,往我們所希望的方向去走,這里添加信息的方式主要是利用交叉注意力機制(這里我看圖應該是只用交叉注意力就行,但是我看視頻博主用的代碼以及參照的Stable-Diffusion Unet圖上都是利用的Transoformer的編碼器,也就是得到注意力值之后還得進行一個feedforward層)。
- **改動3:**利用 AE,VAE,VQVAE 等自編碼器進行解碼。(這個實質上和第一點是重復的)
- **注意:**本次的代碼改動先只改動第二個,也就是添加引導信息,對于編碼器用于減少計算量,本次改進先不參與(555~,因為視頻博主沒教),后續可能會進行添加(因為也比較簡單)。
Stable Diffusion 和Diffusion 的Unet對比


- 我們可以發現,兩者之間的區別主要在于,在卷積完了之后添加了一個Transformer的模塊,也就是其編碼器將兩個信息進行了融合,其他并沒有改變。
- 所以主要區別在卷積后的那一部分,如下圖。

- 這個ResnetBlock就是之前的卷積模塊,作為右邊的殘差部分,所以這里寫成 了ResnetBlock。
- 因此,如果我們將Tranformer模塊融入到Restnet模塊里面,并且保持其輸入卷積的圖像和transformer輸出的圖像形狀一致的話,那么就其他部分完全不需要改變了,只不過里面多添加了一些引導信息(MNIST數據集中是label,但是也可以添加文本等等引導信息) 而已。
Lora 微調原理
- LoRA算法

- 算法過程:對于原先的參數不改變,通過右邊添加一個參數矩陣來進行微調,也就是利用新的參數矩陣來微調擬合新領域的參數和初始參數的差距。也就是ΔW。
理論:預訓練大型語言模型在適應新任務時具有較低的“內在維度” , 所以當對于一個預訓練模型來說,原先的參數是有非常多的冗余的,因此我們可以利用低維空間(也就是降維)去表示目標參數和原先參數之間的距離。因此ΔW是相對W來說維度非常小的,減少了非常多的參數量。
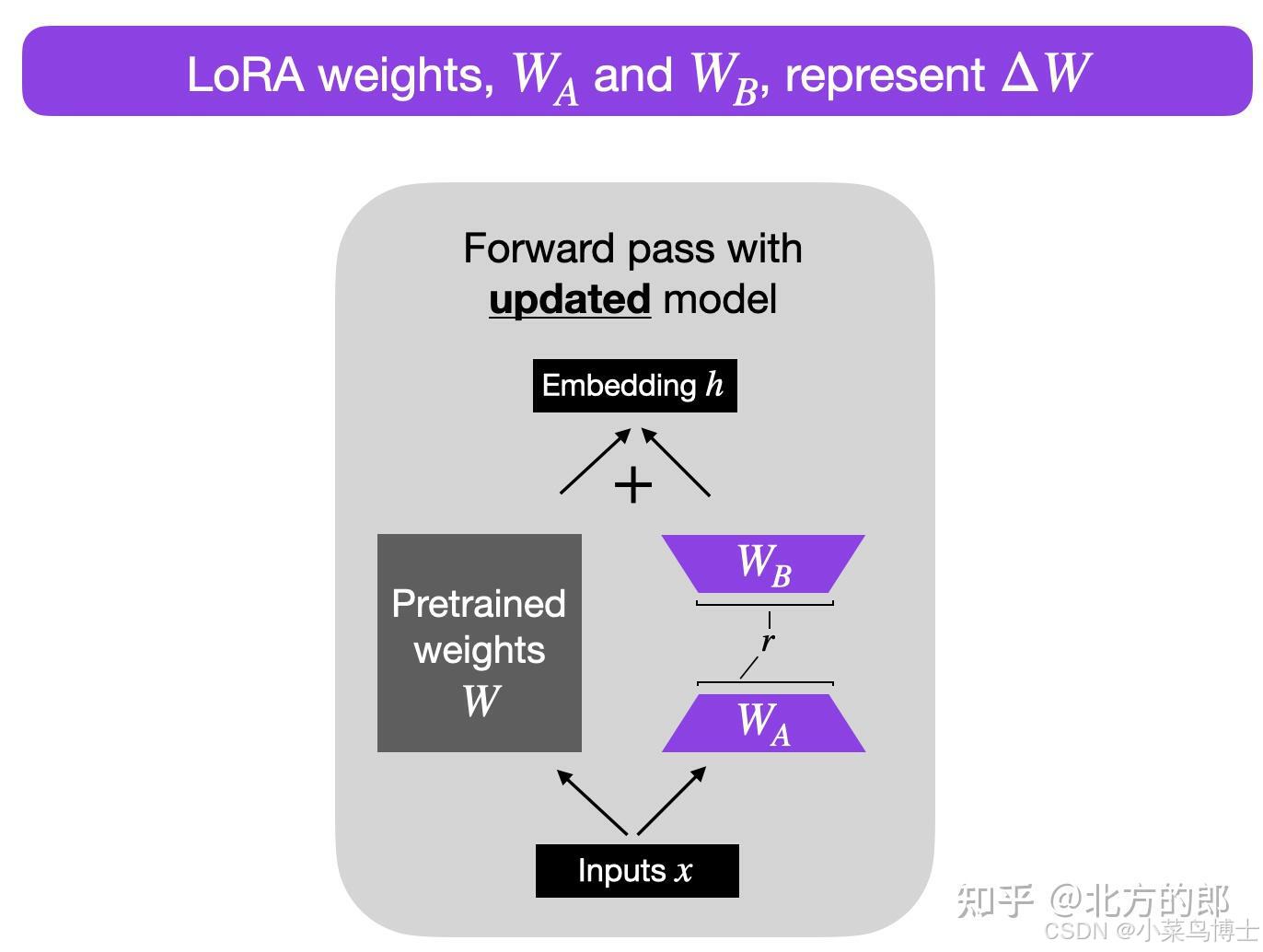
-
因為要保證輸入和輸出的維度和原本的參數W一樣,所以一般參數輸入的維度還是相同的,但是中間的維度小很多,從而達到減少參數量的結果。比如原本是100x100的參數量,現在變為100x5(r)x2,減少了10倍。
- 其中r就是低秩的那個秩數。可以自定義。
o u t p u t = n e t ( x ) + t o r c h . m a t m u l ( x , t o r c h . m a t m u l ( l o r a a , l o r a b ) ? a l p h a ( 可能這里也會除以 r ) output=net(x)+torch.matmul(x,torch.matmul(lora_a,lora_b)*alpha(可能這里也會除以r) output=net(x)+torch.matmul(x,torch.matmul(loraa?,lorab?)?alpha(可能這里也會除以r)
? alpha或者alpha/r 是一個縮放因子,用于調整組合結果(原始模型輸出加上低秩自適應)的大小。這平衡了預訓練模型的知識和新的特定于任務的適應——默認情況下,alpha通常設置為 1。另請注意,雖然W A被初始化為小的隨機權重,但WB被初始化為 0,因此訓練開始時ΔW = WAxWB = 0 ,這意味著我們以原始權重開始訓練。
Stable Diffusion 添加lora微調代碼
Part1 添加lora.py文件 - 用于設置lora層以及替換
1. 引入相關庫函數
# 該模塊主要是實現lora類,實現lora層的alpha和beta通路,把輸入的x經過兩條通路后的結果,進行聯合輸出。
# 然后添加一個函數,主要是為了實現將原本的線性層換曾lora層。'''
# Part1 引入相關的庫函數
'''
import torch
from torch import nn
from config import *
2. 定義LoraLayer的類
'''
# Part2 設計一個類,實現lora_layer
'''class LoraLayer(nn.Module):def __init__(self, target_linear_layer, feature_in, feature_out, r, alpha):super().__init__()# 第一步,初始化lora的一些參數,包含a矩陣,b矩陣,r秩.比例系數等等。self.lora_a = nn.Parameter(torch.empty(feature_in, r), requires_grad=True)self.lora_b = nn.Parameter(torch.zeros(r, feature_out), requires_grad=True)self.alpha = alphaself.r = r# 第二步對alpha進行初始化nn.init.kaiming_uniform_(self.lora_a)# 第三步,初始化原本的目標線性層self.net = target_linear_layerdef forward(self, x):output1 = self.net(x)output2 = torch.matmul(x, torch.matmul(self.lora_a, self.lora_b)) * (self.alpha / self.r) # 得到結果后,乘上比例系數(alpha/r)return output2 + output1
3. lora層的替換
'''
# Part3 定義一個函數,實現lora層的替換
'''def inject_lora(module, name, target_linear_layer): # 輸入完整的模型,目標線性層的位置,目標線性層name_list = name.split('.') # 按照.進行拆分路徑# 獲取到目標線性層的模型的上一層所有參數和模型{模型name1:模型,模型name2:模型}for i, item in enumerate(name_list[:-1]):module = getattr(module, item)# 初始化需要替換進入的lora層lora_layer = LoraLayer(target_linear_layer,feature_in=target_linear_layer.in_features, feature_out=target_linear_layer.out_features,r=LORA_R, alpha=LORA_ALPHA)# 替換對應的層setattr(module, name_list[-1], lora_layer)
Part2 添加lora_finetune.py,用于參數微調訓練得到lora參數.pt文件
1. 引入相關庫函數
# 該模塊主要實現對于模型的一些模塊進行微調訓練,只對lora里面的新增參數進行訓練。
'''
# Part 1 引入相關的庫函數
'''
import osimport torch
from torch import nn
from dataset import minist_train
from torch.utils import data
from diffusion import forward_diffusion
from config import *
from unet import Unet
from lora import inject_lora
2. 替換模型中的注意力機制里面的Wq, Wk, Wv,替換線性層
if __name__ =='__main__':'''# Part2 對需要訓練的模型參數進行設置,將需要替換的線性層進行lora替換,并且只對lora進行訓練'''# 首先第一步得先下載網絡net = torch.load('unet_epoch0.pt')# 開始對所需的部分進行替換。# 首先,我們要對線性層進行lora替換,所以需要,輸入inject_lora的參數包含(整個模型,路徑,layer)for name, layer in net.named_modules():name_list = name.split('.')target = ['Wq', 'Wk', 'Wv']for i in target:if i in name_list and isinstance(layer, nn.Linear):# 替換inject_lora(net, name, layer)# 替換完之后,先看看需不需要添加之前的參數try:# 先下載參數lora_para=torch.load('lora_para_epoch0.pt')# 再填充到模型里面net.load_state_dict(lora_para,strict=False)except:pass# 替換完之后,需要對所有的參數進行設置,不是lora的參數梯度設置為Falsefor name, para in net.named_parameters():name_list = name.split('.')lora_para_list = ['lora_a', 'lora_b']if name_list[-1] in lora_para_list:para.requires_grad = Falseelse:para.requires_grad = True'''# Part3 進行訓練'''epoch = 5batch_size = 50minist_loader = data.DataLoader(dataset=minist_train, batch_size=batch_size, shuffle=True)# 初始化模型loss = nn.L1Loss()opt = torch.optim.Adam(net.parameters(), lr=1e-3)n_iter = 0net.train()for i in range(epoch):for imgs, labels in minist_loader:imgs = imgs * 2 - 1# 先隨機初始化batch_tbatch_t = torch.randint(0, T, size=(imgs.size()[0],))# 首先對清晰圖像進行加噪,得到batch_x_tbatch_x_t, batch_noise = forward_diffusion(imgs, batch_t)# 預測對應的噪聲batch_noise_pre = net(batch_x_t, batch_t, labels)# 計算損失l = loss(batch_noise, batch_noise_pre)# 清除梯度opt.zero_grad()# 損失反向傳播l.backward()# 更新參數opt.step()# 累加損失last_loss = l.item()# 更新迭代次數n_iter += 1print('當前的iter為{},當前損失為{}'.format(n_iter, last_loss))print('當前的epoch為{},當前的損失為{}'.format(i, last_loss))# 保存訓練好的lora參數,但是得先找到lora_dic = {}# 遍歷net的參數for name, para in net.named_parameters():name_list = name.split('.')need_find = ['lora_a', 'lora_b']# 如果最后一個名字在需要找的參數里面if name_list[-1] in need_find:# 在存儲的字典里面添加參數和名字lora_dic[name] = para# 先存儲為臨時文件torch.save(lora_dic, 'lora_para_epoch{}.pt.tmp'.format(i))# 然后改變路徑,形成最終的參數(主要是為了防止寫入出錯)os.replace('lora_para_epoch{}.pt.tmp'.format(i), 'lora_para_epoch{}.pt'.format(i))
Part3 修改 denoise.py,修改測試的時候的lora參數加入
1. 引入相關庫函數
# 該模塊主要實現的是對圖像進行去噪的測試。
'''
# 首先第一步,引入相關的庫函數
'''import torch
from torch import nn
from config import *
from diffusion import alpha_t, alpha_bar
from dataset import *
import matplotlib.pyplot as plt
from diffusion import forward_diffusion
from lora import inject_lora
from lora import LoraLayer
2. 定義去噪的函數
'''
# 第二步定義一個去噪的函數
'''def backward_denoise(net, batch_x_t, batch_labels):# 首先計算所需要的數據,方差variance,也就公式里面的beta_talpha_bar_late = torch.cat((torch.tensor([1.0]), alpha_bar[:-1]), dim=0)variance = (1 - alpha_t) * (1 - alpha_bar_late) / (1 - alpha_bar)# 得到方差后,開始去噪net.eval() # 開啟測試模式# 記錄每次得到的圖像steps = [batch_x_t]for t in range(T - 1, -1, -1):# 初始化當前每張圖像對應的時間狀態batch_t = torch.full(size=(batch_x_t.size()[0],), fill_value=t) # 表示此時的時間狀態 (batch,)# 預測噪聲# 修改第十四處batch_noise_pre = net(batch_x_t, batch_t, batch_labels) # (batch,channel,iamg,imag)# 開始去噪(需要注意一個點,就是去噪的公式,在t不等于0和等于0是不一樣的,先進行都需要處理部分也就是添加噪聲前面的均值部分)# 同時記得要統一維度,便于廣播reshape_size = (batch_t.size()[0], 1, 1, 1)# 先取出對應的數值alpha_t_batch = alpha_t[batch_t]alpha_bar_batch = alpha_bar[batch_t]variance_batch = variance[batch_t]# 計算前面的均值batch_mean_t = 1 / torch.sqrt(alpha_t_batch).reshape(*reshape_size) \* (batch_x_t - (1 - alpha_t_batch.reshape(*reshape_size)) * batch_noise_pre / torch.sqrt(1 - alpha_bar_batch.reshape(*reshape_size)))# 分類,看t的值,判斷是否添加噪聲if t != 0:batch_x_t = batch_mean_t \+ torch.sqrt(variance_batch.reshape(*reshape_size)) \* torch.randn_like(batch_x_t)else:batch_x_t = batch_mean_t# 對每次得到的結果進行上下限的限制batch_x_t = torch.clamp(batch_x_t, min=-1, max=1)# 添加每步的去噪結果steps.append(batch_x_t)return steps
3. 測試-去噪
# 開始測試
if __name__ == '__main__':# 加載模型model = torch.load('unet_epoch0.pt')model.eval()is_lora = Trueis_hebing = False# 如果是利用lora,需要把微調的也加進去模型進行推理if is_lora:for name, layer in model.named_modules():name_list = name.split('.')target_list = ['Wk', 'Wv', 'Wq']for i in target_list:if i in name_list and isinstance(layer, nn.Linear):inject_lora(model, name, layer)# 加載權重參數try:para_load = torch.load('lora_para_epoch0.pt')model.load_state_dict(para_load, strict=False)except:pass# 如果需要合并,也就是把lora參數添加到原本的線性層上面的話,也就是把插入重新實現一遍,這次是把lora_layer換成linear。if is_lora and is_hebing:for name, layer in model:name_list = name.split('.')if isinstance(layer, LoraLayer):# 找到了對應的參數,把對應的lora參數添加到原本的參數上# 為什么要確定參數位置的上一層,因為setattr只能在上一層用,不能層層進入屬性。cur_layer=modelfor n in name_list[:-1]:cur_layer=getattr(cur_layer,n)# 首先計算lora參數lora_weight = torch.matmul(layer.lora_a, layer.lora_b) * layer.alpha / layer.r# 把參數進行添加,線性層的權重矩陣通常是 (out_features, in_features),所以需要對lora矩陣進行轉置layer.net.weight = nn.Parameter(layer.net.weight.add(lora_weight.T))setattr(cur_layer, name_list[-1], layer)# 生成噪音圖batch_size = 10batch_x_t = torch.randn(size=(batch_size, 1, IMAGE_SIZE, IMAGE_SIZE)) # (5,1,48,48)batch_labels = torch.arange(start=0, end=10, dtype=torch.long) # 引導詞promot# 逐步去噪得到原圖# 修改第十五處steps = backward_denoise(model, batch_x_t, batch_labels)# 繪制數量num_imgs = 20# 繪制還原過程plt.figure(figsize=(15, 15))for b in range(batch_size):for i in range(0, num_imgs):idx = int(T / num_imgs) * (i + 1)# 像素值還原到[0,1]final_img = (steps[idx][b] + 1) / 2# tensor轉回PIL圖final_img = TenosrtoPil_action(final_img)plt.subplot(batch_size, num_imgs, b * num_imgs + i + 1)plt.imshow(final_img)plt.show()
參考
視頻講解:Lora微調代碼實現_嗶哩嗶哩_bilibili
原理博客:手撕Diffusion系列 - 第九期 - 改進為Stable Diffusion(原理介紹)-CSDN博客,自學資料 - LoRA - 低秩微調技術-CSDN博客
)

)
)

發布的一系列人工智能模型)





及多任務學習)




-- 3D渲染引擎實現詳解)

)
