為什么深度學習和神經網絡要使用 GPU?
本篇文章的目標是幫助初學者了解 CUDA 是什么,以及它如何與 PyTorch 配合使用,更重要的是,我們為何在神經網絡編程中使用 GPU。
圖形處理單元 (GPU)
要了解 CUDA,我們需要對圖形處理單元 (GPU) 有一定的了解。GPU 是一種擅長處理 專門化 計算的處理器。
這與中央處理單元 (CPU) 形成對比,CPU 是一種擅長處理 通用 計算的處理器。CPU 是為我們的電子設備上大多數典型計算提供動力的處理器。
GPU 可以比 CPU 快得多,但并非總是如此。GPU 相對于 CPU 的速度取決于正在執行的計算類型。最適合 GPU 的計算類型是能夠 并行 進行的計算。
并行計算
并行計算是一種將特定計算分解為可以同時進行的獨立較小計算的計算類型。然后將得到的計算結果重新組合或同步,以形成原始較大計算的結果。
? ?
?
一個較大任務可以分解為的任務數量取決于特定硬件上包含的內核數量。內核是實際在給定處理器內進行計算的單元,CPU 通常有四、八或十六個內核,而 GPU 可能有數千個內核。
還有其他一些技術規格也很重要,但本描述旨在傳達一般概念。
有了這些基礎知識,我們可以得出結論,使用 GPU 進行并行計算,并且最適合使用 GPU 解決的任務是能夠并行完成的任務。如果計算可以并行完成,我們就可以通過并行編程方法和 GPU 加速我們的計算。
神經網絡是令人尷尬的并行
現在讓我們關注神經網絡,看看為何深度學習如此大量地使用 GPU。我們剛剛了解到 GPU 適合進行并行計算,而這一事實正是深度學習使用它們的原因。神經網絡是 令人尷尬的并行。
在并行計算中,一個 令人尷尬的并行 任務是指幾乎不需要將整體任務分解為一組可以并行計算的較小任務。
令人尷尬的并行任務是那些很容易看出一組較小任務彼此獨立的任務。
? ?
?
神經網絡之所以令人尷尬的并行,原因就在于此。我們使用神經網絡進行的許多計算可以很容易地分解為較小的計算,使得一組較小的計算彼此不依賴。一個這樣的例子是卷積。
卷積示例
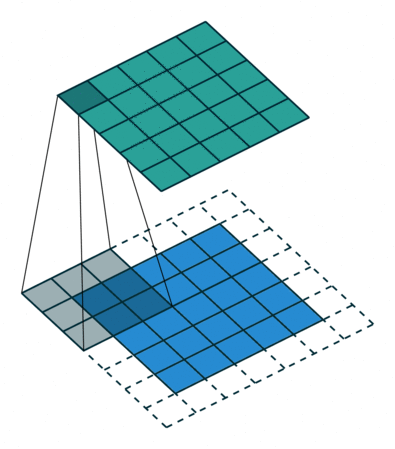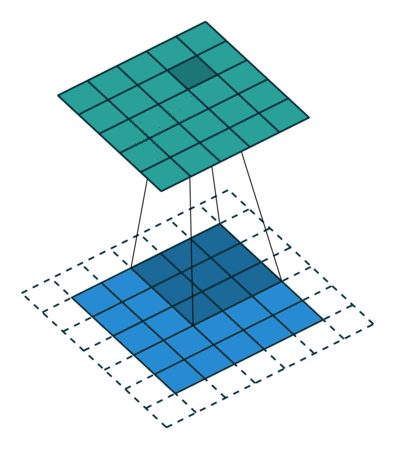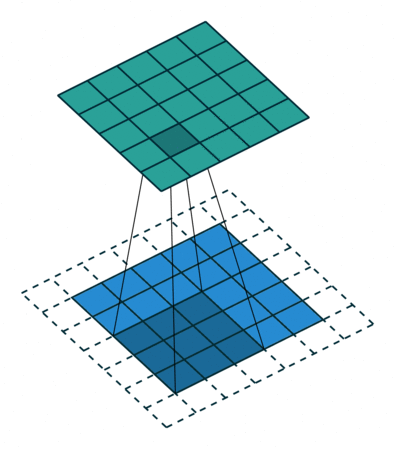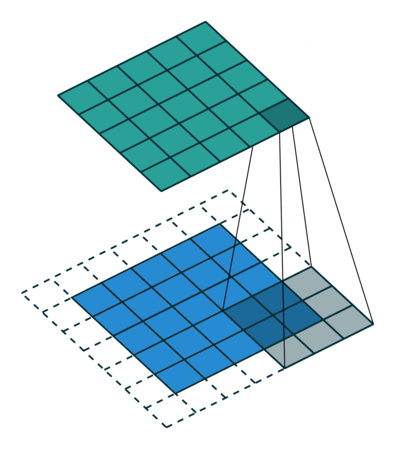
讓我們來看一個示例,卷積操作:
? ?
?
這個動畫展示了沒有數字的卷積過程。我們在底部有一個藍色的輸入通道。一個在底部陰影的卷積濾波器在輸入通道上滑動,以及一個綠色的輸出通道:
- 藍色(底部) - 輸入通道
- 陰影(在藍色上方) -
3 x 3? 卷積濾波器 - 綠色(頂部) - 輸出通道
對于藍色輸入通道上的每個位置,3 x 3? 濾波器都會進行一次計算,將藍色輸入通道的陰影部分映射到綠色輸出通道的相應陰影部分。
在動畫中,這些計算是依次一個接一個地進行的。然而,每次計算都與其他計算獨立,這意味著沒有計算依賴于其他任何計算的結果。
因此,所有這些獨立的計算都可以在 GPU 上并行進行,并產生整體的輸出通道。
這使我們能夠看到,通過使用并行編程方法和 GPU,可以加速卷積操作。
Nvidia 硬件 (GPU) 和軟件 (CUDA)
這就是 CUDA 發揮作用的地方。Nvidia 是一家設計 GPU 的技術公司,他們創建了 CUDA 作為一個軟件平臺,與他們的 GPU 硬件配合使用,使開發人員更容易構建利用 Nvidia GPU 并行處理能力加速計算的軟件。
? ?
?
Nvidia GPU 是實現并行計算的硬件,而 CUDA 是為開發人員提供 API 的軟件層。
因此,你可能已經猜到,要使用 CUDA,需要一個 Nvidia GPU,CUDA 可以從 Nvidia 的網站免費下載和安裝。
開發人員通過下載 CUDA 工具包來使用 CUDA。工具包中包含專門的庫,如 cuDNN,CUDA 深度神經網絡庫。
? ?
?
PyTorch 內置 CUDA
使用 PyTorch 或任何其他神經網絡 API 的一個好處是并行性已經內置在 API 中。這意味著作為神經網絡程序員,我們可以更多地專注于構建神經網絡,而不是性能問題。
對于 PyTorch 來說,CUDA 從一開始就內置其中。不需要額外下載。我們只需要有一個支持的 Nvidia GPU,就可以使用 PyTorch 利用 CUDA。我們不需要直接了解如何使用 CUDA API。
當然,如果我們想在 PyTorch 核心開發團隊工作或編寫 PyTorch 擴展,那么直接了解如何使用 CUDA 可能會很有用。
畢竟,PyTorch 是用所有這些編寫的:
- Python
- C++
- CUDA
在 PyTorch 中使用 CUDA
在 PyTorch 中利用 CUDA 非常容易。如果我們希望某個特定的計算在 GPU 上執行,我們可以通過在數據結構 (張量) 上調用 cuda()? 來指示 PyTorch 這樣做。
假設我們有以下代碼:
> t = torch.tensor([1,2,3])
> t
tensor([1, 2, 3])以這種方式創建的張量對象默認在 CPU 上。因此,使用這個張量對象進行的任何操作都將在 CPU 上執行。
現在,要將張量移動到 GPU 上,我們只需編寫:
> t = t.cuda()
> t
tensor([1, 2, 3], device='cuda:0')這種能力使 PyTorch 非常靈活,因為計算可以選擇性地在 CPU 或 GPU 上執行。
GPU 可能比 CPU 慢
我們說我們可以選擇性地在 GPU 或 CPU 上運行我們的計算,但為何不將 每個 計算都運行在 GPU 上呢?
GPU 不是比 CPU 快嗎?
答案是 GPU 只對特定 (專門化) 任務更快。我們可能會遇到的一個問題是瓶頸,這會降低我們的性能。例如,將數據從 CPU 移動到 GPU 是代價高昂的,所以在這種情況下,如果計算任務很簡單,整體性能可能會更慢。
將相對較小的計算任務移動到 GPU 上不會讓我們加速很多,實際上可能會讓我們變慢。記住,GPU 適合將任務分解為許多較小任務,如果計算任務已經很小,我們將不會通過將任務移動到 GPU 上獲得太多好處。
因此,通常在剛開始時只使用 CPU 是可以接受的,隨著我們解決更大更復雜的問題,開始更頻繁地使用 GPU。
GPGPU 計算
起初,使用 GPU 加速的主要任務是計算機圖形,因此得名圖形處理單元,但在近年來,出現了許多其他種類的并行任務。我們已經看到的一個這樣的任務是深度學習。
深度學習以及許多其他使用并行編程技術的科學計算任務,正在導致一種新的編程模型的出現,稱為 GPGPU 或通用 GPU 計算。
GPGPU 計算現在更常見地僅稱為 GPU 計算或加速計算,因為現在在 GPU 上執行各種任務變得越來越普遍。
Nvidia 在這個領域一直是先驅。Nvidia 的 CEO 黃仁勛很早就設想了 GPU 計算,這就是 CUDA 在大約十年前被創建的原因。
盡管 CUDA 已經存在很長時間了,但它現在才真正開始騰飛,Nvidia 直到目前為止在 CUDA 上的工作是 Nvidia 在深度學習 GPU 計算方面處于領先地位的原因。
當我們聽到黃仁勛談論 GPU 計算棧時,他指的是 GPU 作為底部的硬件,CUDA 作為 GPU 頂部的軟件架構,最后是像 cuDNN 這樣的庫位于 CUDA 頂部。
這個 GPU 計算棧支持在芯片上進行通用計算能力,而芯片本身是非常專門化的。我們經常在計算機科學中看到像這樣的棧,因為技術是分層構建的,就像神經網絡一樣。
位于 CUDA 和 cuDNN 頂部的是 PyTorch,這是我們將會工作的框架,最終支持頂部的應用程序。

)

究竟應該配置多少個BROKER?)
)



![[項目][boost搜索引擎#4] cpp-httplib使用 log.hpp 前端 測試及總結](http://pic.xiahunao.cn/[項目][boost搜索引擎#4] cpp-httplib使用 log.hpp 前端 測試及總結)



+Flowable工作流前后端整合教程)

)


)

