在《分區策略和管理分區計劃的實踐方案》這篇文章中,我們介紹了在ODC中制定分區策略及有效管理分區計劃的經驗。有不少用戶在該帖下提出了使用中的問題,其中一個關于創建分區的限制條件的問題,也是很多用戶遭遇的老問題。因此本文以其為切入,將創建分區的幾個問題進行解析,與大家共同探討分享。
為什么主鍵必須包含全部分區鍵?
用戶問:“有一張訂單流水表,數據很大,想考慮按年份對數據進行分區。現在只有 ID 列是主鍵。嘗試了一下好像無法按日期進行分區。是必須要把日期做成和 ID 的聯合主鍵才可以分區么?”
答案是對的,主鍵必須包含所有分區鍵。因為主鍵的唯一性檢查是在各個分區內部進行的,如果主鍵不包含全部分區鍵,這個檢查就會失效,所以 MySQL 及其他數據庫,也一樣會有這個要求。
-- 如果主鍵不包含全部分區鍵,建表就會失敗報錯,報錯信息也挺明確的。
create table t1(c1 int, c2 int,c3 int,primary key (c1))
partition by range (c2) (partition p1 values less than(3),partition p1 values less than(6));ERROR 1503 (HY000): A PRIMARY KEY must include all columns in the table's partitioning function下面舉個例子:
create table t1(c1 int, c2 int,c3 int,primary key (c1, c2))
partition by range (c2) (partition p0 values less than(3),partition p1 values less than(6));
Query OK, 0 rows affected (0.146 sec)obclient [test]> insert into t1 values(1, 2, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> insert into t1 values(1, 5, 3);
Query OK, 1 row affected (0.032 sec)obclient [test]> select * from t1;
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
| 1 | 5 | 3 |
+----+----+------+
2 rows in set (0.032 sec)我們創建了一張表,主鍵是 c1 和 c2,分區鍵是 c2,小于 3 的值在 p0 分區,大于等于 3 且小于 6 的值在 p1 分區。然后插入了兩個行,第一行在 p0 分區,第二行在 p1 分區。
obclient [test]> select * from t1 PARTITION(p0);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 2 | 3 |
+----+----+------+
1 row in set (0.033 sec)obclient [test]> select * from t1 PARTITION(p1);
+----+----+------+
| c1 | c2 | c3 |
+----+----+------+
| 1 | 5 | 3 |
+----+----+------+
1 row in set (0.034 sec)如果主鍵只有 c1 而沒有 c2,那么在 p0 和 p1 分區內對 c1 列的唯一性檢測都會成功,因為在各個分區內 c1 列的值都不重復,然后就會判定插入的數據符合主鍵約束。但實際上在分區間會有重復值,數據并不符合主鍵約束,所以所有數據庫在分區時,都要求主鍵包含全部分區鍵。
為什么分區能讓查詢變快?
用戶另外一個問題:“按日期分區是否能達到讓查詢變快的目的?”
個人理解,分區除了可以讓一張超級大表的數據比較被均衡地被負載在不同的數據庫節點上,另外一個目的就是加速查詢。因為查詢時會利用過濾條件里面的分區鍵進行分區裁剪。例如下面這兩個例子:
如果過濾條件里有分區鍵,計劃中可以看到 partitions(p0),說明只掃描了 p0 這一個分區的數據。
obclient [test]> explain select * from t1 where c2 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t1 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c2 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p0) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
11 rows in set (0.034 sec)如果過濾條件里沒有分區鍵,計劃中可以看到 partitions(p[0-1]),說明掃描了 p0 和 p1 全部所有分區的數據。其中 PX PARTITION ITERATOR 算子就是用來循環掃描所有分區的迭代器。
obclient [test]> explain select * from t1 where c3 = 1;
+------------------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------------------+
| ============================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |6 | |
| |1 |└─EXCHANGE OUT DISTR |:EX10000|1 |6 | |
| |2 | └─PX PARTITION ITERATOR| |1 |5 | |
| |3 | └─TABLE FULL SCAN |t1 |1 |5 | |
| ============================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| 1 - output([INTERNAL_FUNCTION(t1.c1, t1.c2, t1.c3)]), filter(nil), rowset=16 |
| dop=1 |
| 2 - output([t1.c1], [t1.c2], [t1.c3]), filter(nil), rowset=16 |
| force partition granule |
| 3 - output([t1.c1], [t1.c2], [t1.c3]), filter([t1.c3 = 1]), rowset=16 |
| access([t1.c1], [t1.c2], [t1.c3]), partitions(p[0-1]) |
| is_index_back=false, is_global_index=false, filter_before_indexback[false], |
| range_key([t1.c1], [t1.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------------------+
19 rows in set (0.038 sec)range 分區不支持 datetime 類型咋辦?
用戶的另另外一個問題:“range 分區不支持 datetime 類型咋辦?”。
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE(UNIX_TIMESTAMP(a))(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 1486 (HY000): Constant or random or timezone-dependent expressions in (sub)partitioning function are not allowed試了下,OB 的 MySQL 模式,為了兼容 MySQL 行為,會和 MySQL 對 random expressions 進行一些限制。我第一時間想到的是用生成列繞過,不過很快發現,為了兼容 MySQL 行為,OB 對生成列的使用也進行了限制,生成列里也不允許出現 UNIX_TIMESTAMP 這個特殊的表達式,所以并沒什么卵用:
CREATE TABLE ff01 (a datetime , b timestamp as (UNIX_TIMESTAMP(a)))
PARTITION BY RANGE(b)(PARTITION p0 VALUES less than (UNIX_TIMESTAMP('2000-2-3 00:00:00')),PARTITION p1 VALUES less than (UNIX_TIMESTAMP('2001-2-3 00:00:00')),PARTITION pn VALUES less than MAXVALUE);ERROR 3102 (HY000): Expression of generated column contains a disallowed function至于為啥 UNIX_TIMESTAMP 在生成列里屬于 disallowed function,猜測大概率是因為它是個非 deterministic 的系統函數。非 deterministic 簡單來說就是這個 UNIX_TIMESTAMP() 函數在前一秒執行,和在后一秒執行,可能會返回不同的結果。像分區表達式、生成列表達式、check 約束里面的表達式,都不允許出現這種非確定性的函數。
下面舉個簡單的例子,解釋一下上面 ERROR 1486 這個報錯里 random 一詞,以及非 deterministic 的含義:
obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008180 |
+------------------+
1 row in set (0.042 sec)obclient [test]> select UNIX_TIMESTAMP();
+------------------+
| UNIX_TIMESTAMP() |
+------------------+
| 1725008419 |
+------------------+
1 row in set (0.041 sec)-- 是不是一下子就明白,為啥 UNIX_TIMESTAMP 這么特殊,在哪里都不受待見了吧?不過不得不說,OB 的 MySQL 兼容性做的還挺好的,不僅是兼容了 MySQL 各種使用上的限制,甚至是一些 MySQL 的 bug 都給兼容了,雖然給使用帶來了一些不便,不過遷移 MySQL 大概會變得比較輕松。
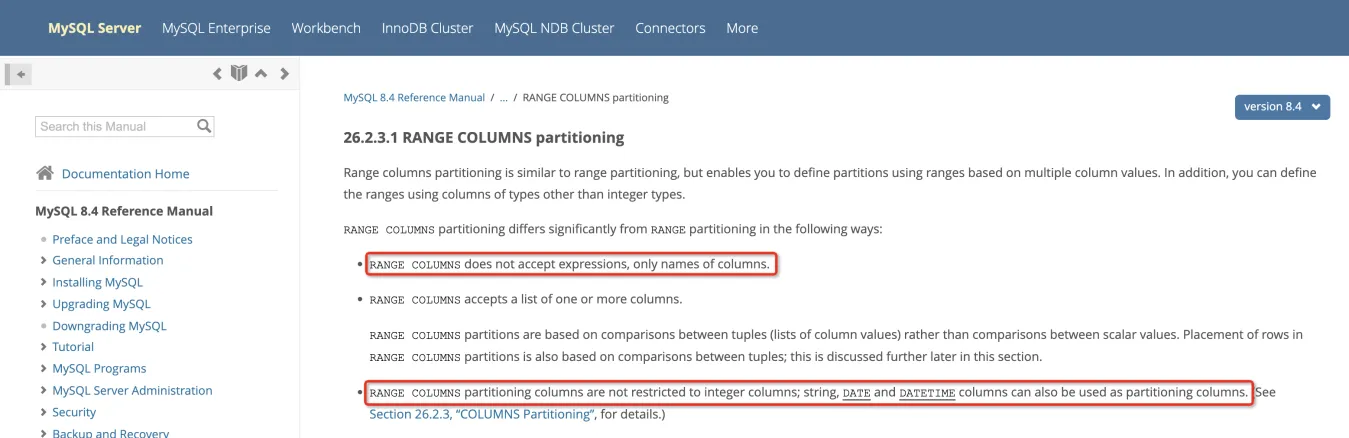
扯遠了,回歸正題,后面查了下?OB 官網,發現有一種分區方式叫?Range Columns,和 Range 分區十分類似,優點是相比 Range 分區可以支持更多的數據類型,例如用戶需要的 datetime 類型,缺點是分區定義不支持表達式。
因為 Range 不支持?UNIX_TIMESTAMP?這類特殊的非 deterministic?表達式,所以個人理解這里可以通過 Range Columns 解決用戶的問題。例如:
CREATE TABLE ff01 (a datetime , b timestamp)
PARTITION BY RANGE COLUMNS(a)(PARTITION p0 VALUES less than ('2023-01-01'),PARTITION p1 VALUES less than ('2023-01-02'),PARTITION pn VALUES less than MAXVALUE);Query OK, 0 rows affected (0.101 sec)說來慚愧,我之前也一直沒注意過?Range 分區和 Range Columns 分區的區別,一直是把他們等價的,今天也算是學習到了,哈哈~
最后附上一個?MySQL 的官網文檔鏈接,感覺它對 RANGE COLUMNS partitioning 的介紹比 OB 的官網要更清楚些,在這里推薦給對分區方式感興趣的朋友閱讀~
What else?
? ?有同學提出還可以通過利用 to_days 函數代替 UNIX_TIMESTAMP 函數的方式解決第三個問題,這樣就不需要更改 range 分區為 range columns 分區了。例如:
##創建range分區表
-- 分區字段是start_time,類型datetime
CREATE TABLE dba_test_range_1 (id bigint unsigned NOT NULL AUTO_INCREMENT COMMENT '主鍵',`name` varchar(50) NOT NULL COMMENT 'name',start_time datetime NOT NULL COMMENT '開始時間',
PRIMARY KEY (id,start_time)
)AUTO_INCREMENT = 1 DEFAULT CHARSET = utf8mb4 COMMENT = 'test range'
PARTITION BY RANGE(to_days(start_time))(PARTITION M202301 VALUES LESS THAN(to_days('2023-02-01')),PARTITION M202302 VALUES LESS THAN(to_days('2023-03-01')),PARTITION M202303 VALUES LESS THAN(to_days('2023-04-01')));




)


)


)
(信號原理、操作系統的原理、volatile))





)
