昇思25天學習打卡營第16天 | Vision Transformer圖像分類
文章目錄
- 昇思25天學習打卡營第16天 | Vision Transformer圖像分類
- Vision Transform(ViT)模型
- Transformer
- Attention模塊
- Encoder模塊
- ViT模型輸入
- 模型構建
- Multi-Head Attention模塊
- Encoder模塊
- Patch Embedding模塊
- ViT網絡
- 總結
- 打卡
Vision Transform(ViT)模型
ViT是NLP和CV領域的融合,可以在不依賴于卷積操作的情況下在圖像分類任務上達到很好的效果。
ViT模型的主體結構是基于Transformer的Encoder部分。
Transformer
Transformer由很多Encoder和Decoder模塊構成,包括多頭注意力(Multi-Head Attention)層,Feed Forward層,Normalization層和殘差連接(Residual Connection)。
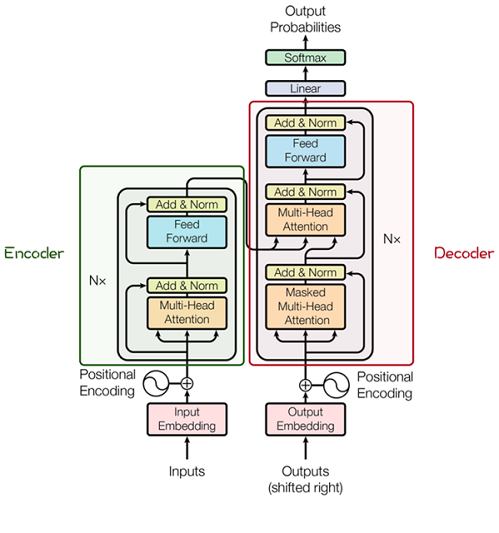
多頭注意力結構基于自注意力機制(Self-Attention),是多個Self-Attention的并行組成。
Attention模塊
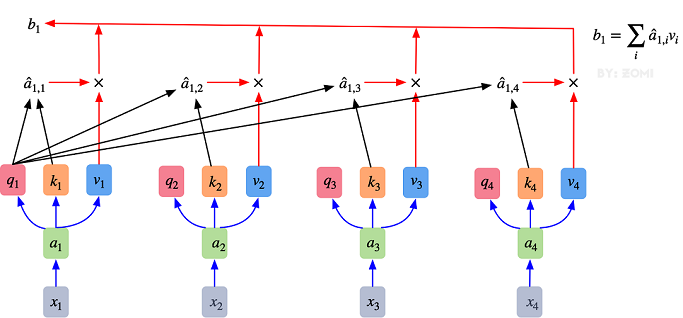
Attention的核心在于為輸入向量的每個單詞學習一個權重。
- 最初的輸入向量首先經過Embedding層映射為Q(Query),K(Key),V(Value)三個向量。
- 通過將Q和所有K進行點乘初一維度平方根,得到向量間的相似度,通過softmax獲取每詞向量之間的關系權重。
- 利用關系權重對詞向量的V加權求和,得到自注意力值。
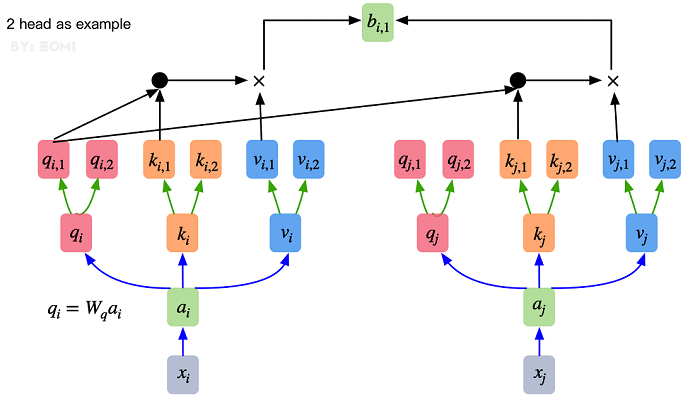
多頭注意力機制只是對self-attention的并行化:
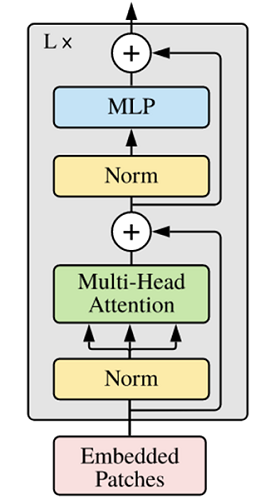
Encoder模塊
ViT中的Encoder相對于標準Transformer,主要在于將Normolization放在self-attention和Feed Forward之前,其他結構與標準Transformer相同。
ViT模型輸入
傳統Transformer主要應用于自然語言處理的一維詞向量,而圖像時二維矩陣的堆疊。
在ViT中:
- 通過卷積將輸入圖像在每個channel上劃分為 16 × 16 16\times 16 16×16個patch。如果輸入 224 × 224 224\times224 224×224的圖像,則每一個patch的大小為 14 × 14 14\times 14 14×14。
- 將每一個patch拉伸為一個一維向量,得到近似詞向量堆疊的效果。如將 14 × 14 14\times14 14×14展開為 196 196 196的向量。
這一部分Patch Embedding用來替換Transformer中Word Embedding,用作網絡中的圖像輸入。
模型構建
Multi-Head Attention模塊
from mindspore import nn, opsclass Attention(nn.Cell):def __init__(self,dim: int,num_heads: int = 8,keep_prob: float = 1.0,attention_keep_prob: float = 1.0):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = ms.Tensor(head_dim ** -0.5)self.qkv = nn.Dense(dim, dim * 3)self.attn_drop = nn.Dropout(p=1.0-attention_keep_prob)self.out = nn.Dense(dim, dim)self.out_drop = nn.Dropout(p=1.0-keep_prob)self.attn_matmul_v = ops.BatchMatMul()self.q_matmul_k = ops.BatchMatMul(transpose_b=True)self.softmax = nn.Softmax(axis=-1)def construct(self, x):"""Attention construct."""b, n, c = x.shapeqkv = self.qkv(x)qkv = ops.reshape(qkv, (b, n, 3, self.num_heads, c // self.num_heads))qkv = ops.transpose(qkv, (2, 0, 3, 1, 4))q, k, v = ops.unstack(qkv, axis=0)attn = self.q_matmul_k(q, k)attn = ops.mul(attn, self.scale)attn = self.softmax(attn)attn = self.attn_drop(attn)out = self.attn_matmul_v(attn, v)out = ops.transpose(out, (0, 2, 1, 3))out = ops.reshape(out, (b, n, c))out = self.out(out)out = self.out_drop(out)return out
Encoder模塊
from typing import Optional, Dictclass FeedForward(nn.Cell):def __init__(self,in_features: int,hidden_features: Optional[int] = None,out_features: Optional[int] = None,activation: nn.Cell = nn.GELU,keep_prob: float = 1.0):super(FeedForward, self).__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.dense1 = nn.Dense(in_features, hidden_features)self.activation = activation()self.dense2 = nn.Dense(hidden_features, out_features)self.dropout = nn.Dropout(p=1.0-keep_prob)def construct(self, x):"""Feed Forward construct."""x = self.dense1(x)x = self.activation(x)x = self.dropout(x)x = self.dense2(x)x = self.dropout(x)return xclass ResidualCell(nn.Cell):def __init__(self, cell):super(ResidualCell, self).__init__()self.cell = celldef construct(self, x):"""ResidualCell construct."""return self.cell(x) + xclass TransformerEncoder(nn.Cell):def __init__(self,dim: int,num_layers: int,num_heads: int,mlp_dim: int,keep_prob: float = 1.,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: nn.Cell = nn.LayerNorm):super(TransformerEncoder, self).__init__()layers = []for _ in range(num_layers):normalization1 = norm((dim,))normalization2 = norm((dim,))attention = Attention(dim=dim,num_heads=num_heads,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob)feedforward = FeedForward(in_features=dim,hidden_features=mlp_dim,activation=activation,keep_prob=keep_prob)layers.append(nn.SequentialCell([ResidualCell(nn.SequentialCell([normalization1, attention])),ResidualCell(nn.SequentialCell([normalization2, feedforward]))]))self.layers = nn.SequentialCell(layers)def construct(self, x):"""Transformer construct."""return self.layers(x)
Patch Embedding模塊
class PatchEmbedding(nn.Cell):MIN_NUM_PATCHES = 4def __init__(self,image_size: int = 224,patch_size: int = 16,embed_dim: int = 768,input_channels: int = 3):super(PatchEmbedding, self).__init__()self.image_size = image_sizeself.patch_size = patch_sizeself.num_patches = (image_size // patch_size) ** 2self.conv = nn.Conv2d(input_channels, embed_dim, kernel_size=patch_size, stride=patch_size, has_bias=True)def construct(self, x):"""Path Embedding construct."""x = self.conv(x)b, c, h, w = x.shapex = ops.reshape(x, (b, c, h * w))x = ops.transpose(x, (0, 2, 1))return x
ViT網絡
from mindspore.common.initializer import Normal
from mindspore.common.initializer import initializer
from mindspore import Parameterdef init(init_type, shape, dtype, name, requires_grad):"""Init."""initial = initializer(init_type, shape, dtype).init_data()return Parameter(initial, name=name, requires_grad=requires_grad)class ViT(nn.Cell):def __init__(self,image_size: int = 224,input_channels: int = 3,patch_size: int = 16,embed_dim: int = 768,num_layers: int = 12,num_heads: int = 12,mlp_dim: int = 3072,keep_prob: float = 1.0,attention_keep_prob: float = 1.0,drop_path_keep_prob: float = 1.0,activation: nn.Cell = nn.GELU,norm: Optional[nn.Cell] = nn.LayerNorm,pool: str = 'cls') -> None:super(ViT, self).__init__()self.patch_embedding = PatchEmbedding(image_size=image_size,patch_size=patch_size,embed_dim=embed_dim,input_channels=input_channels)num_patches = self.patch_embedding.num_patchesself.cls_token = init(init_type=Normal(sigma=1.0),shape=(1, 1, embed_dim),dtype=ms.float32,name='cls',requires_grad=True)self.pos_embedding = init(init_type=Normal(sigma=1.0),shape=(1, num_patches + 1, embed_dim),dtype=ms.float32,name='pos_embedding',requires_grad=True)self.pool = poolself.pos_dropout = nn.Dropout(p=1.0-keep_prob)self.norm = norm((embed_dim,))self.transformer = TransformerEncoder(dim=embed_dim,num_layers=num_layers,num_heads=num_heads,mlp_dim=mlp_dim,keep_prob=keep_prob,attention_keep_prob=attention_keep_prob,drop_path_keep_prob=drop_path_keep_prob,activation=activation,norm=norm)self.dropout = nn.Dropout(p=1.0-keep_prob)self.dense = nn.Dense(embed_dim, num_classes)def construct(self, x):"""ViT construct."""x = self.patch_embedding(x)cls_tokens = ops.tile(self.cls_token.astype(x.dtype), (x.shape[0], 1, 1))x = ops.concat((cls_tokens, x), axis=1)x += self.pos_embeddingx = self.pos_dropout(x)x = self.transformer(x)x = self.norm(x)x = x[:, 0]if self.training:x = self.dropout(x)x = self.dense(x)return x
總結
這一節對Transformer進行介紹,包括Attention機制、并行化的Attention以及Encoder模塊。由于傳統Transformer主要作用于一維的詞向量,因此二維圖像需要被轉換為類似的一維詞向量堆疊,在ViT中通過將Patch Embedding解決這一問題,并用來代替傳統Transformer中的Word Embedding作為網絡的輸入。
打卡

)














-RS232(2))

![[USACO18JAN] Cow at Large P](http://pic.xiahunao.cn/[USACO18JAN] Cow at Large P)
