概述
論文地址:https://arxiv.org/pdf/1409.1556.pdf
這項研究探討了卷積網絡深度對圖像識別準確性的影響。重要的是,對具有小型卷積濾波器的網絡進行的評估表明,具有 16-19 個權重層的深度網絡的性能優于傳統配置。這些結果使得該模型在2014年ImageNet挑戰賽中取得了成功,并在其他數據集上表現出色。研究人員的目標是向公眾提供兩個最有效的 ConvNet 模型,以促進深度視覺表示方面的研究。
導言
卷積網絡(ConvNet)最近已成功用于大規模圖像識別。這歸功于大型圖像數據集和高性能計算系統的進步。特別是,ImageNet 競賽推動了視覺識別技術的進步。卷積網絡正變得越來越普遍,人們也嘗試了許多改進方法。本研究表明,卷積網絡的深度非常重要,并提出了一種使用小型濾波器構建深度網絡的方法。因此,構建的網絡具有很高的準確性,其性能可應用于其他數據集。最后,我們向公眾提供了一個最先進的模型,有望推動相關研究的發展。
建筑學
在 ConvNet 訓練過程中,輸入是固定大小的 224 x 224 RGB 圖像,唯一的預處理是減去每個像素的平均 RGB 值。卷積層中使用了一個小型 3×3 過濾器,步距為 1 像素。空間池化由最大池化層執行。卷積層之后是三個全連接層,最后一個是用于 ILSVRC 分類的 softmax 層。所有隱藏層都具有 ReLU 非線性,網絡不包括局部響應歸一化。
配置
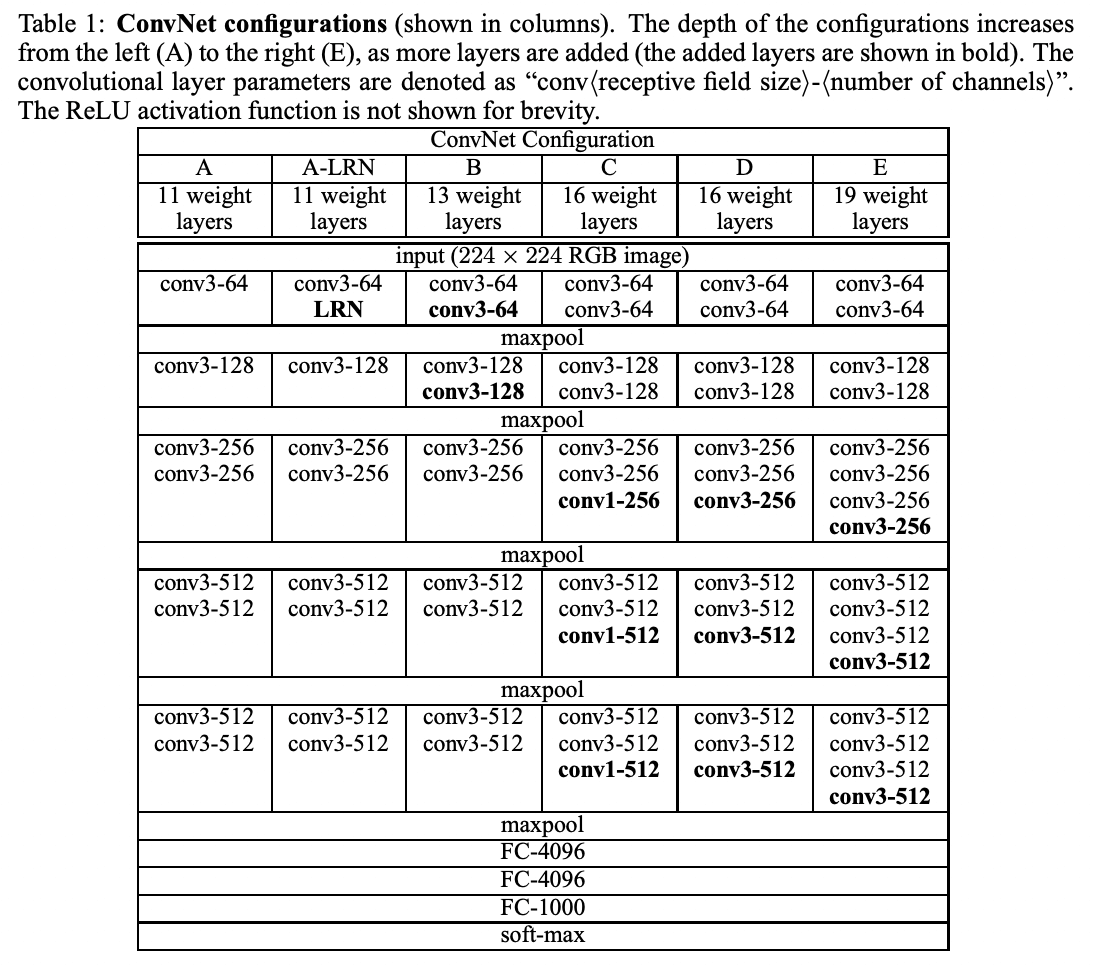
本文評估了五種卷積網絡(ConvNet)配置模型(A 至 E)。這些模型基于一般設計,深度不同(A 為 11 層,E 為 19 層)。權重層數和層寬隨網絡深度而變化,第一層從 64 開始,每增加一個最大池化層,權重層數和層寬就增加 2 倍,最終達到 512。

表 2 列出了每種配置的參數數量。 盡管深度較大,但網絡中的權重層數并不比變換較大的較淺網絡中的權重層數多。
討論
本研究對卷積網絡(ConvNet)進行了重新配置,通過使用小型 3×3 過濾器而不是傳統的大型感受野來提高性能。這樣就能引入非線性整流層并減少參數。較小濾波器的引入提高了決策函數的可辨別性,1×1 卷積也改善了非線性。這比以前的方法更有效,在更深的網絡中性能更高。
分類框架
訓練
在本研究中,使用了帶動量的迷你批次梯度下降法來訓練 ConvNet,批次大小為 256,動量設置為 0.9。權重衰減和丟棄用于規范化,學習率逐步降低。初始權重從淺層模型開始設置,在訓練深層結構時對某些層進行初始化。對圖像進行隨機裁剪,并添加水平翻轉和 RGB 顏色偏移以增強訓練集。
圖像大小
本研究嘗試了兩種方法,一種是將 S 設置為代表 ConvNet 訓練圖像最小邊緣的比例,另一種是將 S 設置為固定比例或隨機比例。首先,模型在兩個固定比例(S=256 和 S=384)下進行訓練。其次,在多尺度訓練中,每幅圖像都被隨機重新縮放,以便識別各種尺度的物體。最后,在 S=384 下訓練的模型基礎上建立多尺度模型,并通過隨機縮放進行微調。
測試
在測試過程中,訓練好的 ConvNet 對輸入圖像進行各向同性重縮放,然后將網絡密集地應用到重縮放的測試圖像上。這樣,整個圖像上就會出現一個類得分圖,最終得出類得分。測試集被水平翻轉,原始圖像和翻轉圖像的結果取平均值。全卷積網絡適用于整個圖像,無需對每種作物進行重新計算,從而提高了測試效率。我們也考慮過使用多作物,但認為增加的計算時間并不能證明準確率的提高是合理的。
實施細節
該實現源自 C++ Caffe 工具箱,可在多個 GPU 上進行訓練和評估。多 GPU 訓練使用數據并行性,在每個 GPU 上處理批處理,計算梯度,最后求平均值。這樣得出的結果與在單個 GPU 上進行的訓練結果相當。在我們的實驗中,我們使用了一個配備四個英偉達?(NVIDIA?)Titan Black GPU的系統,訓練耗時兩到三周,比現成的4GPU系統快3.75倍。
分類實驗
數據集
本節展示了 ConvNet 架構在 ILSVRC-2012 數據集上取得的圖像分類結果。該數據集包含 1000 類圖像,分為三個集:訓練集、驗證集和測試集。分類性能通過兩個指標進行評估:前 1 名錯誤和前 5 名錯誤,前者表示錯誤分類圖像的百分比,后者表示在前 5 名預測中不包含正確答案的圖像的百分比。
單一量表評估
首先,使用上一節所述的層配置,在單一尺度上評估各個 ConvNet 模型的性能。對于固定 S,Q = S;對于抖動 S∈[Smin,Smax],Q = 0.5(Smin+Smax)。 結果如表 3 所示。
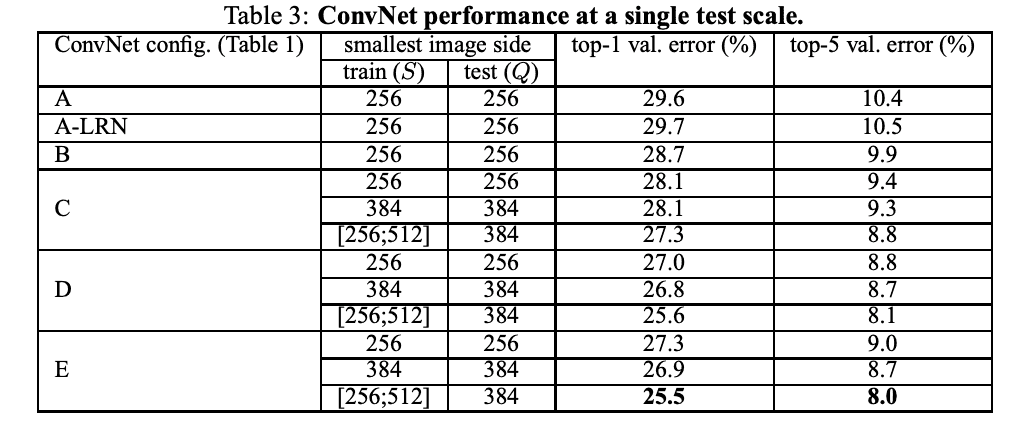
比較卷積神經網絡(ConvNet)各種配置的實驗結果表明,有無歸一化層和深度的增加都會影響分類誤差。誤差隨著深度的增加而減小,非線性變換和空間上下文捕捉也很重要。研究還表明,深度模型對大型數據集也有好處,具有小濾波器的深度網絡表現更好。訓練過程中的尺度抖動也很有效,有助于獲得多尺度圖像統計數據。
多階段評估
在對 ConvNet 模型進行評估時,研究了測試過程中尺度抖動的影響。該技術包括將測試圖像重新縮放為不同尺度,然后運行模型計算類的后驗均值。為了考慮到訓練和測試尺度不匹配對性能的潛在影響,在訓練過程中由于尺度抖動,以固定尺度訓練的模型在接近的尺寸下進行評估,并同時在大范圍的尺度下進行測試。
結果表明,測試時的尺度抖動比在單一尺度下評估同一模型更能提高性能。最深的配置(D 和 E)顯示出最好的性能,表明比例抖動比使用固定的最小邊 S 進行訓練更有益。
評估多種作物
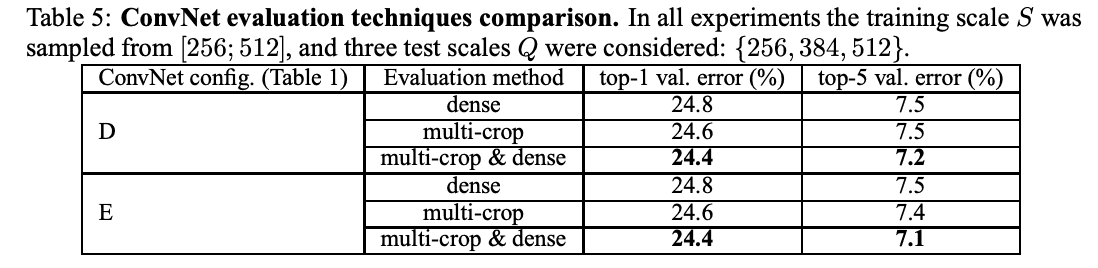
表 5 比較了高密度 ConvNet 評估和多作物評估,并通過平均 softmax 輸出檢驗了兩種方法的互補性。當使用多作物時,性能略好,而兩者的組合則優于對方。這被認為是由于處理了不同的卷積邊界條件。
COMBNET 融合

在本實驗中,不同 ConvNet 模型的輸出被組合在一起,通過互補來提高性能。結合不同模型后,ILSVRC 測試誤差為 7.3%。僅將兩個最佳多尺度模型組合起來,誤差就降低到了 6.8%,而最佳單一模型的誤差為 7.1%。
與最新技術的比較
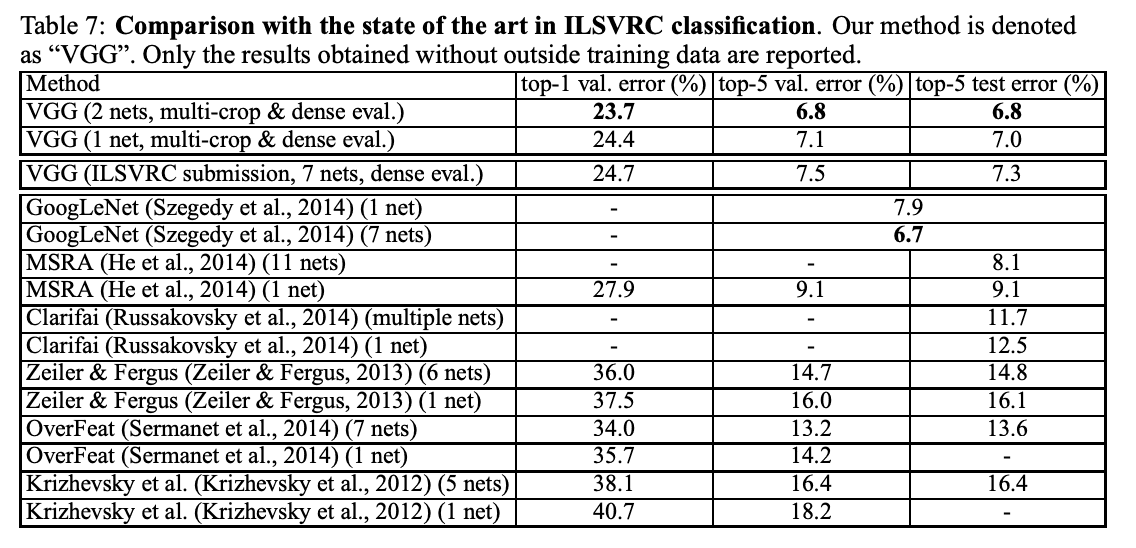
在 ILSVRC-2014 的分類任務中,作者的深度 ConvNet 明顯優于上一代模型,使用七個模型的集合將錯誤率降低到 6.8%。這使得深度 ConvNet 在 ILSVRC-2012 和 ILSVRC-2013 比賽中取得了最佳成績,大大超過了競爭對手的參賽作品。特別是,兩個模型的組合取得了最佳成績,與許多其他模型相比,它以更少的資源實現了更高的性能。
結論
該研究評估了大規模圖像分類中的深度卷積網絡(最多 19 層)。 使用傳統的 ConvNet 架構,在 ImageNet Challenge 數據集上取得了最先進的性能,表明隨著深度的增加,表示深度有助于提高分類準確性。該模型還適用于廣泛的任務和數據集,其性能不亞于或優于基于淺層圖像表征的復雜識別管道。這再次證明了深度在視覺表示中的重要性。










)








