文章目錄
- 訓練部分
- 導入項目使用的庫
- 設置隨機因子
- 設置全局參數
- 圖像預處理與增強
- 讀取數據
- 設置Loss
- 設置模型
- 設置優化器和學習率調整策略
- 設置混合精度,DP多卡,EMA
- 定義訓練和驗證函數
- 訓練函數
- 驗證函數
- 調用訓練和驗證方法
- 運行以及結果查看
- 測試
- 完整的代碼
在上一篇文章中完成了前期的準備工作,見鏈接:
RDNet實戰:使用RDNet實現圖像分類任務(一)
前期的工作主要是數據的準備,安裝庫文件,數據增強方式的講解,模型的介紹和實驗效果等內容。接下來,這篇主要是講解如何訓練和測試
訓練部分
完成上面的步驟后,就開始train腳本的編寫,新建train.py
導入項目使用的庫
在train.py導入
import json
import os
os.environ["HF_ENDPOINT"] = "https://hf-mirror.com"
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torch.utils.data.distributed
import torchvision.transforms as transforms
from timm.utils import accuracy, AverageMeter, ModelEma
from sklearn.metrics import classification_report
from timm.data.mixup import Mixup
from timm.loss import SoftTargetCrossEntropy
from models.rdnet import rdnet_tiny
from torch.autograd import Variable
from torchvision import datasets
torch.backends.cudnn.benchmark = False
import warnings
warnings.filterwarnings("ignore")
os.environ['CUDA_VISIBLE_DEVICES']="0,1"
當您需要在具有多個GPU的機器上指定用于訓練的GPU時,可以通過設置環境變量CUDA_VISIBLE_DEVICES來實現。這個環境變量的值是一個由逗號分隔的GPU索引列表,索引從0開始。例如,如果您的機器上有8塊GPU,并且您希望僅使用前兩塊GPU(即索引為0和1的GPU)進行訓練,您應該設置:
os.environ['CUDA_VISIBLE_DEVICES'] = "0,1"
這樣,只有索引為0和1的GPU會被系統識別并用于訓練。類似地,如果您希望使用第三塊(索引為2)和第六塊(索引為5)GPU進行訓練,您應該相應地設置:
os.environ['CUDA_VISIBLE_DEVICES'] = "2,5"
通過這種方式,您可以靈活地選擇任意數量的GPU進行訓練,而無需擔心其他GPU的干擾。
設置隨機因子
def seed_everything(seed=42):# 設置Python的哈希種子os.environ['PYTHONHASHSEED'] = str(seed)# 設置PyTorch的CPU隨機種子torch.manual_seed(seed)# 如果使用CUDA,設置CUDA的隨機種子if torch.cuda.is_available():torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed) # 如果你的代碼在多個GPU上運行# 啟用CUDA的確定性行為(對卷積等操作的確定性有幫助)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = True# 使用示例
seed_everything(42)
這里有一些額外的說明和注意事項:
-
torch.cuda.manual_seed_all(seed):這個調用是可選的,但如果你在多GPU環境中工作(比如使用DataParallel或DistributedDataParallel),它確保所有GPU上的隨機操作都將從相同的種子開始。如果你的代碼只在一個GPU上運行,這個調用不是必需的,但也不會造成問題。 -
torch.backends.cudnn.benchmark = False:當設置為True時,cuDNN會在運行時自動選擇算法來優化性能。然而,這可能會導致每次運行時的行為不完全相同,因為算法的選擇可能會基于輸入數據的形狀和大小而變化。為了實驗的可重復性,最好將其設置為False。 -
圖片加載順序:雖然設置隨機種子有助于確保模型的隨機操作(如初始化權重、dropout等)是可重復的,但它本身并不直接控制圖片加載的順序。圖片加載順序通常由數據集加載器(如
DataLoader)的shuffle參數控制。如果你想要固定的加載順序,確保在創建DataLoader時將shuffle=False。 -
其他隨機性來源:請注意,即使你設置了這些隨機種子,還可能存在其他隨機性來源,如操作系統級別的調度或硬件層面的差異(如GPU的浮點精度差異)。在極端情況下,這些差異可能會影響結果的精確可重復性。然而,在大多數情況下,上述設置應該足以確保實驗在相同的軟件和環境配置下是可重復的。
設置全局參數
if __name__ == '__main__':# 創建保存模型的文件夾file_dir = 'checkpoints/RDNet/' os.makedirs(file_dir, exist_ok=True) # 設置全局參數model_lr = 1e-4BATCH_SIZE = 16EPOCHS = 300DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')use_amp = True # 是否使用混合精度use_dp = True # 是否開啟dp方式的多卡訓練classes = 12resume = NoneCLIP_GRAD = 5.0Best_ACC = 0 # 記錄最高得分use_ema = Truemodel_ema_decay = 0.9998start_epoch = 1seed = 1seed_everything(seed)
創建一個名為 ‘checkpoints/RDNet/’ 的文件夾,用于保存訓練過程中的模型。如果該文件夾已經存在,則不會再次創建,否則會創建該文件夾。
設置訓練模型的全局參數,包括學習率、批次大小、訓練輪數、設備選擇(是否使用 GPU)、是否使用混合精度、是否開啟數據并行等。
注:建議使用GPU,CPU太慢了。
參數的詳細解釋:
model_lr:學習率,根據實際情況做調整。
BATCH_SIZE:batchsize,根據顯卡的大小設置。
EPOCHS:epoch的個數,一般300夠用。
use_amp:是否使用混合精度。
use_dp :是否開啟dp方式的多卡訓練?如果您打算使用多GPU訓練將use_dp 設置為 True。
classes:類別個數。
resume:再次訓練的模型路徑,如果不為None,則表示加載resume指向的模型繼續訓練。
CLIP_GRAD:梯度的最大范數,在梯度裁剪里設置。
Best_ACC:記錄最高ACC得分。
use_ema:是否使用ema,如果沒有使用預訓練模型,直接打開use_ema會造成不上分的情況。可以先關閉ema訓練幾個epoch,然后,將訓練的權重賦值到resume,再將啟用ema
model_ema_decay:設置了EMA的衰減率。衰減率決定了當前模型權重和之前的EMA權重在更新新的EMA權重時的相對貢獻。具體來說,每次更新EMA權重時,都會按照以下公式進行:
newemaweight = decay × oldemaweight + ( 1 ? decay ) × currentmodelweight \text{newemaweight} = \text{decay} \times \text{oldemaweight} + (1 - \text{decay}) \times \text{currentmodelweight} newemaweight=decay×oldemaweight+(1?decay)×currentmodelweight
例如,衰減率被設置為0.9998。這意味著在更新EMA權重時,大約99.98%的權重來自之前的EMA權重,而剩下的0.02%來自當前的模型權重。由于衰減率非常接近1,EMA權重會更多地依賴于之前的EMA權重,而不是當前的模型權重。這有助于平滑模型權重的波動,并減少噪聲對最終模型性能的影響。
start_epoch:開始的epoch,默認是1,如果重新訓練時,需要給start_epoch重新賦值。
SEED:隨機因子,數值可以隨意設定,但是設置后,不要隨意更改,更改后,圖片加載的順序會改變,影響測試結果。
file_dir = 'checkpoints/RDNet/'
這是存放RDNet模型的路徑。
圖像預處理與增強
# 數據預處理7transform = transforms.Compose([transforms.RandomRotation(10),transforms.GaussianBlur(kernel_size=(5,5),sigma=(0.1, 3.0)),transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5),transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])])transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])])mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)
數據處理和增強比較簡單,加入了隨機10度的旋轉、高斯模糊、色彩飽和度明亮度的變化、Mixup等比較常用的增強手段,做了Resize和歸一化。
transforms.Normalize(mean=[0.3281186, 0.28937867, 0.20702125], std= [0.09407319, 0.09732835, 0.106712654])
這里設置為計算mean和std。
這里注意下Resize的大小,由于選用的模型輸入是224×224的大小,所以要Resize為224×224。
數據預處理流程結合了多種常用的數據增強技術,包括隨機旋轉、高斯模糊、色彩抖動(ColorJitter)、Resize以及歸一化,還引入了Mixup和可能的CutMix技術來進一步增強模型的泛化能力。參數詳解:
- transforms.RandomRotation(10): 隨機旋轉圖像最多10度,有助于模型學習旋轉不變性。
- transforms.GaussianBlur(kernel_size=(5,5), sigma=(0.1, 3.0)): 應用高斯模糊,模擬圖像的模糊情況,增強模型對模糊圖像的魯棒性。
- transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5): 調整圖像的亮度、對比度和飽和度,增加數據的多樣性。
- transforms.Resize((224, 224)): 將圖像大小調整為224x224,以符合模型的輸入要求。
- transforms.ToTensor(): 將PIL Image或NumPy ndarray轉換為FloatTensor,并歸一化到[0.0, 1.0]。
- transforms.Normalize(mean, std): 使用指定的均值和標準差對圖像進行歸一化處理,有助于模型訓練。
mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=classes)
定義了一個 Mixup 函數。Mixup 是一種在圖像分類任務中常用的數據增強技術,它通過將兩張圖像以及其對應的標簽進行線性組合來生成新的數據和標簽。
Mixup 是一種正則化技術,通過混合輸入數據和它們的標簽來增強模型的泛化能力。在您的代碼中,Mixup 類還包含了 CutMix 的參數,但具體實現可能需要根據您使用的庫(如 timm 或自定義實現)來確定。參數詳解:
mixup_alpha: Mixup 中用于Beta分布的α參數,控制混合強度的分布。 cutmix_alpha: CutMix
中用于Beta分布的α參數,同樣控制混合強度的分布。 cutmix_minmax: CutMix 中裁剪區域的最小和最大比例,但在這里設為
None,可能表示使用默認的或根據 cutmix_alpha 自動計算的比例。 prob: 應用Mixup或CutMix的概率。
switch_prob: 在Mixup和CutMix之間切換的概率(如果Mixup和CutMix都被啟用)。 mode:
指定Mixup是在整個批次上進行還是在單個樣本之間進行。 label_smoothing: 標簽平滑參數,用于減少模型對硬標簽的過度自信。
num_classes: 類別數,用于標簽平滑計算。
讀取數據
# 讀取數據dataset_train = datasets.ImageFolder('data/train', transform=transform)dataset_test = datasets.ImageFolder("data/val", transform=transform_test)with open('class.txt', 'w') as file:file.write(str(dataset_train.class_to_idx))with open('class.json', 'w', encoding='utf-8') as file:file.write(json.dumps(dataset_train.class_to_idx))# 導入數據train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE,num_workers=8,pin_memory=True,shuffle=True,drop_last=True)test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)
-
使用pytorch默認讀取數據的方式,然后將dataset_train.class_to_idx打印出來,預測的時候要用到。
-
對于train_loader ,drop_last設置為True,因為使用了Mixup數據增強,必須保證每個batch里面的圖片個數為偶數(不能為零),如果最后一個batch里面的圖片為奇數,則會報錯,所以舍棄最后batch的迭代,pin_memory設置為True,可以加快運行速度,num_workers多進程加載圖像,不要超過CPU 的核數。
-
將dataset_train.class_to_idx保存到txt文件或者json文件中。
class_to_idx的結果:
{'Black-grass': 0, 'Charlock': 1, 'Cleavers': 2, 'Common Chickweed': 3, 'Common wheat': 4, 'Fat Hen': 5, 'Loose Silky-bent': 6, 'Maize': 7, 'Scentless Mayweed': 8, 'Shepherds Purse': 9, 'Small-flowered Cranesbill': 10, 'Sugar beet': 11}
設置Loss
# 設置loss函數
# 訓練的loss函數為SoftTargetCrossEntropy,用于處理具有軟目標(soft targets)的訓練場景
criterion_train = SoftTargetCrossEntropy() # 驗證的loss函數為nn.CrossEntropyLoss(),適用于多分類問題的標準交叉熵損失
criterion_val = torch.nn.CrossEntropyLoss()
設置loss函數,訓練的loss為:SoftTargetCrossEntropy,驗證的loss:nn.CrossEntropyLoss()。
設置模型
#設置模型model_ft = rdnet_tiny(pretrained=True)num_fr=model_ft.head.fc.in_featuresmodel_ft.head.fc=nn.Linear(num_fr,classes)print(model_ft)if resume:model=torch.load(resume)print(model['state_dict'].keys())model_ft.load_state_dict(model['state_dict'])Best_ACC=model['Best_ACC']start_epoch=model['epoch']+1model_ft.to(DEVICE)
-
設置模型為rdnet_tiny,獲取分類模塊的in_features,然后,修改為數據集的類別,也就是classes。
-
如果resume設置為已經訓練的模型的路徑,則加載模型接著resume指向的模型接著訓練,使用模型里的Best_ACC初始化Best_ACC,使用epoch參數初始化start_epoch。
-
如果模型輸出是classes的長度,則表示修改正確了。

設置優化器和學習率調整策略
# 選擇簡單暴力的Adam優化器,學習率調低optimizer = optim.AdamW(model_ft.parameters(),lr=model_lr)cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)
- 優化器設置為adamW。
- 學習率調整策略選擇為余弦退火。
設置混合精度,DP多卡,EMA
if use_amp:scaler = torch.cuda.amp.GradScaler()if torch.cuda.device_count() > 1 and use_dp:print("Let's use", torch.cuda.device_count(), "GPUs!")model_ft = torch.nn.DataParallel(model_ft)if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device=DEVICE,resume=resume)else:model_ema=None
定義訓練和驗證函數
訓練函數
def train(model, device, train_loader, optimizer, epoch,model_ema):model.train()loss_meter = AverageMeter()acc1_meter = AverageMeter()acc5_meter = AverageMeter()total_num = len(train_loader.dataset)print(total_num, len(train_loader))for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)samples, targets = mixup_fn(data, target)output = model(samples)optimizer.zero_grad()if use_amp:with torch.cuda.amp.autocast():loss = torch.nan_to_num(criterion_train(output, targets))scaler.scale(loss).backward()torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)# Unscales gradients and calls# or skips optimizer.step()scaler.step(optimizer)# Updates the scale for next iterationscaler.update()else:loss = criterion_train(output, targets)torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD)loss.backward()optimizer.step()if model_ema is not None:model_ema.update(model)lr = optimizer.state_dict()['param_groups'][0]['lr']loss_meter.update(loss.item(), target.size(0))acc1, acc5 = accuracy(output, target, topk=(1, 5))acc1_meter.update(acc1.item(), target.size(0))acc5_meter.update(acc5.item(), target.size(0))if (batch_idx + 1) % 10 == 0:print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format(epoch, (batch_idx + 1) * train_loader.batch_size, len(train_loader.dataset),100. * (batch_idx + 1) / len(train_loader), loss.item(), lr))ave_loss =loss_meter.avgacc = acc1_meter.avgprint('epoch:{}\tloss:{:.2f}\tacc:{:.2f}'.format(epoch, ave_loss, acc))return ave_loss, acc
訓練的主要步驟:
1、使用AverageMeter保存自定義變量,包括loss,ACC1,ACC5。
2、進入循環,將data和target放入device上,non_blocking設置為True。如果pin_memory=True的話,將數據放入GPU的時候,也應該把non_blocking打開,這樣就只把數據放入GPU而不取出,訪問時間會大大減少。
如果pin_memory=False時,則將non_blocking設置為False。
3、將數據輸入mixup_fn生成mixup數據。
4、將第三部生成的mixup數據輸入model,輸出預測結果,然后再計算loss。
5、 optimizer.zero_grad() 梯度清零,把loss關于weight的導數變成0。
6、如果使用混合精度,則
- with torch.cuda.amp.autocast(),開啟混合精度。
- 計算loss。torch.nan_to_num將輸入中的NaN、正無窮大和負無窮大替換為NaN、posinf和neginf。默認情況下,nan會被替換為零,正無窮大會被替換為輸入的dtype所能表示的最大有限值,負無窮大會被替換為輸入的dtype所能表示的最小有限值。
- scaler.scale(loss).backward(),梯度放大。
- torch.nn.utils.clip_grad_norm_,梯度裁剪,放置梯度爆炸。
- scaler.step(optimizer) ,首先把梯度值unscale回來,如果梯度值不是inf或NaN,則調用optimizer.step()來更新權重,否則,忽略step調用,從而保證權重不更新。
- 更新下一次迭代的scaler。
否則,直接反向傳播求梯度。torch.nn.utils.clip_grad_norm_函數執行梯度裁剪,防止梯度爆炸。
7、如果use_ema為True,則執行model_ema的updata函數,更新模型。
8、 torch.cuda.synchronize(),等待上面所有的操作執行完成。
9、接下來,更新loss,ACC1,ACC5的值。
等待一個epoch訓練完成后,計算平均loss和平均acc
驗證函數
# 驗證過程
@torch.no_grad()
def val(model, device, test_loader):global Best_ACCmodel.eval()loss_meter = AverageMeter()acc1_meter = AverageMeter()acc5_meter = AverageMeter()total_num = len(test_loader.dataset)print(total_num, len(test_loader))val_list = []pred_list = []for data, target in test_loader:for t in target:val_list.append(t.data.item())data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True)output = model(data)loss = criterion_val(output, target)_, pred = torch.max(output.data, 1)for p in pred:pred_list.append(p.data.item())acc1, acc5 = accuracy(output, target, topk=(1, 5))loss_meter.update(loss.item(), target.size(0))acc1_meter.update(acc1.item(), target.size(0))acc5_meter.update(acc5.item(), target.size(0))acc = acc1_meter.avgprint('\nVal set: Average loss: {:.4f}\tAcc1:{:.3f}%\tAcc5:{:.3f}%\n'.format(loss_meter.avg, acc, acc5_meter.avg))if acc > Best_ACC:if isinstance(model, torch.nn.DataParallel):torch.save(model.module, file_dir + '/' + 'best.pth')else:torch.save(model, file_dir + '/' + 'best.pth')Best_ACC = accif isinstance(model, torch.nn.DataParallel):state = {'epoch': epoch,'state_dict': model.module.state_dict(),'Best_ACC': Best_ACC}if use_ema:state['state_dict_ema'] = model.module.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')else:state = {'epoch': epoch,'state_dict': model.state_dict(),'Best_ACC': Best_ACC}if use_ema:state['state_dict_ema'] = model.state_dict()torch.save(state, file_dir + "/" + 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth')return val_list, pred_list, loss_meter.avg, acc
驗證集和訓練集大致相似,主要步驟:
1、在val的函數上面添加@torch.no_grad(),作用:所有計算得出的tensor的requires_grad都自動設置為False。即使一個tensor(命名為x)的requires_grad = True,在with torch.no_grad計算,由x得到的新tensor(命名為w-標量)requires_grad也為False,且grad_fn也為None,即不會對w求導。
2、定義參數:
loss_meter: 測試的loss
acc1_meter:top1的ACC。
acc5_meter:top5的ACC。
total_num:總的驗證集的數量。
val_list:驗證集的label。
pred_list:預測的label。
3、進入循環,迭代test_loader:將label保存到val_list。
將data和target放入device上,non_blocking設置為True。
將data輸入到model中,求出預測值,然后輸入到loss函數中,求出loss。
調用torch.max函數,將預測值轉為對應的label。
將輸出的預測值的label存入pred_list。
調用accuracy函數計算ACC1和ACC5
更新loss_meter、acc1_meter、acc5_meter的參數。
4、本次epoch循環完成后,求得本次epoch的acc、loss。
5、接下來是保存模型的邏輯
如果ACC比Best_ACC高,則保存best模型
判斷模型是否為DP方式訓練的模型。如果是DP方式訓練的模型,模型參數放在model.module,則需要保存model.module。
否則直接保存model。
注:保存best模型,我們采用保存整個模型的方式,這樣保存的模型包含網絡結構,在預測的時候,就不用再重新定義網絡了。6、接下來保存每個epoch的模型。
判斷模型是否為DP方式訓練的模型。如果是DP方式訓練的模型,模型參數放在model.module,則需要保存model.module.state_dict()。
新建個字典,放置Best_ACC、epoch和 model.module.state_dict()等參數。然后將這個字典保存。判斷是否是使用EMA,如果使用,則還需要保存一份ema的權重。
否則,新建個字典,放置Best_ACC、epoch和 model.state_dict()等參數。然后將這個字典保存。判斷是否是使用EMA,如果使用,則還需要保存一份ema的權重。注意:對于每個epoch的模型只保存了state_dict參數,沒有保存整個模型文件。
調用訓練和驗證方法
# 訓練與驗證is_set_lr = Falselog_dir = {}train_loss_list, val_loss_list, train_acc_list, val_acc_list, epoch_list = [], [], [], [], []if resume and os.path.isfile(file_dir+"result.json"):with open(file_dir+'result.json', 'r', encoding='utf-8') as file:logs = json.load(file)train_acc_list = logs['train_acc']train_loss_list = logs['train_loss']val_acc_list = logs['val_acc']val_loss_list = logs['val_loss']epoch_list = logs['epoch_list']for epoch in range(start_epoch, EPOCHS + 1):epoch_list.append(epoch)log_dir['epoch_list'] = epoch_listtrain_loss, train_acc = train(model_ft, DEVICE, train_loader, optimizer, epoch,model_ema)train_loss_list.append(train_loss)train_acc_list.append(train_acc)log_dir['train_acc'] = train_acc_listlog_dir['train_loss'] = train_loss_listif use_ema:val_list, pred_list, val_loss, val_acc = val(model_ema.ema, DEVICE, test_loader)else:val_list, pred_list, val_loss, val_acc = val(model_ft, DEVICE, test_loader)val_loss_list.append(val_loss)val_acc_list.append(val_acc)log_dir['val_acc'] = val_acc_listlog_dir['val_loss'] = val_loss_listlog_dir['best_acc'] = Best_ACCwith open(file_dir + '/result.json', 'w', encoding='utf-8') as file:file.write(json.dumps(log_dir))print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))if epoch < 600:cosine_schedule.step()else:if not is_set_lr:for param_group in optimizer.param_groups:param_group["lr"] = 1e-6is_set_lr = Truefig = plt.figure(1)plt.plot(epoch_list, train_loss_list, 'r-', label=u'Train Loss')# 顯示圖例plt.plot(epoch_list, val_loss_list, 'b-', label=u'Val Loss')plt.legend(["Train Loss", "Val Loss"], loc="upper right")plt.xlabel(u'epoch')plt.ylabel(u'loss')plt.title('Model Loss ')plt.savefig(file_dir + "/loss.png")plt.close(1)fig2 = plt.figure(2)plt.plot(epoch_list, train_acc_list, 'r-', label=u'Train Acc')plt.plot(epoch_list, val_acc_list, 'b-', label=u'Val Acc')plt.legend(["Train Acc", "Val Acc"], loc="lower right")plt.title("Model Acc")plt.ylabel("acc")plt.xlabel("epoch")plt.savefig(file_dir + "/acc.png")plt.close(2)
調用訓練函數和驗證函數的主要步驟:
1、定義參數:
- is_set_lr,是否已經設置了學習率,當epoch大于一定的次數后,會將學習率設置到一定的值,并將其置為True。
- log_dir:記錄log用的,將有用的信息保存到字典中,然后轉為json保存起來。
- train_loss_list:保存每個epoch的訓練loss。
- val_loss_list:保存每個epoch的驗證loss。
- train_acc_list:保存每個epoch的訓練acc。
- val_acc_list:保存么每個epoch的驗證acc。
- epoch_list:存放每個epoch的值。
如果是接著上次的斷點繼續訓練則讀取log文件,然后把log取出來,賦值到對應的list上。
循環epoch1、調用train函數,得到 train_loss, train_acc,并將分別放入train_loss_list,train_acc_list,然后存入到logdir字典中。
2、調用驗證函數,判斷是否使用EMA?
如果使用EMA,則傳入model_ema.ema,否則,傳入model_ft。得到val_list, pred_list, val_loss, val_acc。將val_loss, val_acc分別放入val_loss_list和val_acc_list中,然后存入到logdir字典中。3、保存log。
4、打印本次的測試報告。
5、如果epoch大于600,將學習率設置為固定的1e-6。
6、繪制loss曲線和acc曲線。
運行以及結果查看
完成上面的所有代碼就可以開始運行了。點擊右鍵,然后選擇“run train.py”即可,運行結果如下:
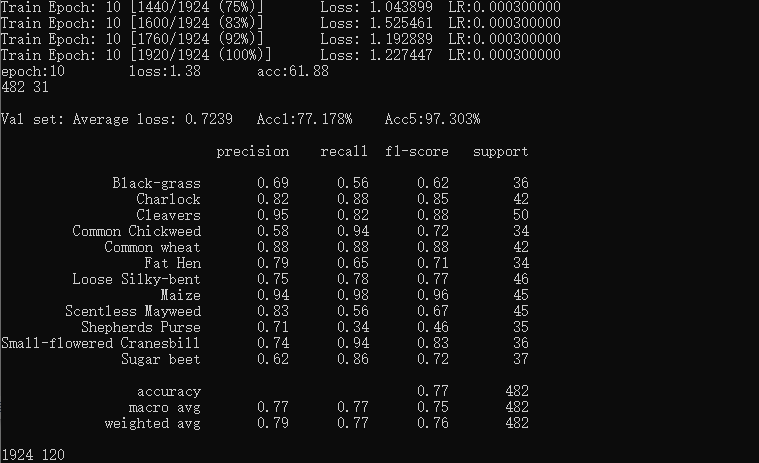
在每個epoch測試完成之后,打印驗證集的acc、recall等指標。
StarNet測試結果:


測試
測試,我們采用一種通用的方式。
測試集存放的目錄如下圖:
StarNet_Demo
├─test
│ ├─1.jpg
│ ├─2.jpg
│ ├─3.jpg
│ ├ ......
└─test.py
import torch.utils.data.distributed
import torchvision.transforms as transforms
from PIL import Image
from torch.autograd import Variable
import osclasses = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed','Common wheat', 'Fat Hen', 'Loose Silky-bent','Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')
transform_test = transforms.Compose([transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933])
])DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model=torch.load('checkpoints/Star/best.pth')
model.eval()
model.to(DEVICE)path = 'test/'
testList = os.listdir(path)
for file in testList:img = Image.open(path + file)img = transform_test(img)img.unsqueeze_(0)img = Variable(img).to(DEVICE)out = model(img)# Predict_, pred = torch.max(out.data, 1)print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))測試的主要邏輯:
1、定義類別,這個類別的順序和訓練時的類別順序對應,一定不要改變順序!!!!
2、定義transforms,transforms和驗證集的transforms一樣即可,別做數據增強。
3、 torch.load加載model,然后將模型放在DEVICE里,
4、循環 讀取圖片并預測圖片的類別,在這里注意,讀取圖片用PIL庫的Image。不要用cv2,transforms不支持。循環里面的主要邏輯:
- 使用Image.open讀取圖片
- 使用transform_test對圖片做歸一化和標椎化。
- img.unsqueeze_(0) 增加一個維度,由(3,224,224)變為(1,3,224,224)
- Variable(img).to(DEVICE):將數據放入DEVICE中。
- model(img):執行預測。
- _, pred = torch.max(out.data, 1):獲取預測值的最大下角標。
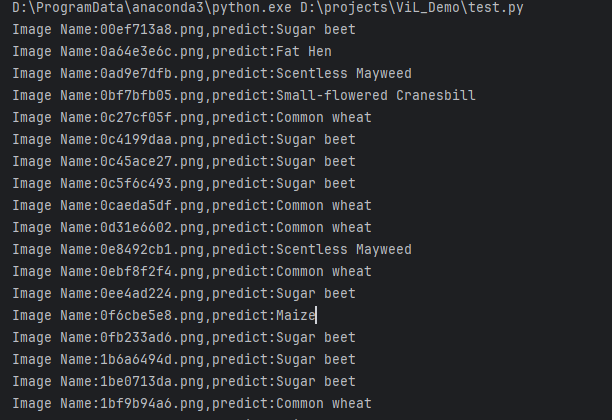
運行結果:
完整的代碼
完整的代碼:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/89527715








- 函數)

行業概覽,2027年將達到235.1億元)


數據結構:高效數據處理)
)


)

