終于,業內迎來了首個全鏈條大模型開源體系。
大模型領域,有人探索前沿技術,有人在加速落地,也有人正在推動整個社區進步。
就在近日,AI 社區迎來首個統一的全鏈條貫穿的大模型開源體系。
雖然社區有LLaMA等影響力較大的開源模型,但由于許可證限制無法商用。InternLM-7B 除了向學術研究完全開放之外,也支持免費商用授權,是國內首個可免費商用的具備完整工具鏈的多語言大模型,通過開源開放惠及更多開發者和企業,賦能產業發展。

WAIC 上書生?浦語的發布。
今年世界人工智能大會 WAIC 上,上個月初「高考成績」超越 ChatGPT 的「書生」大模型來了次重大升級。
在 7 月 6 日的活動中,上海 AI 實驗室與商湯聯合香港中文大學、復旦大學、上海交通大學及清華大學共同發布了全新升級的「書生通用大模型體系」,包括書生?多模態、書生?浦語和書生?天際三大基礎模型。其中面向 NLP 領域的書生?浦語語言大模型迎來了 104B 的高性能版和 7B 的輕量級版。
相較初始模型,104B 的書生?浦語全面升級,高質量語料從 1.6 萬億 token 增至了 1.8 萬億,語境窗口長度從 2K 增至了 8K,支持語言達 20 多種,35 個評測集上超越 ChatGPT。這使得書生?浦語成為國內首個支持 8K 語境長度的千億參數多語種大模型。
而在全面升級的同時,更值得關注的是書生?浦語在開源上的一系列動作。
此次書生?浦語將 7B 的輕量級版 InternLM-7B 正式開源,并推出首個面向大模型研發與應用的全鏈條開源體系,貫穿數據、預訓練、微調、部署和評測五大環節。其中 InternLM-7B 是此次開源體系的核心和基座模型,五大環節緊緊圍繞大模型開發展開。
上海 AI 實驗室開放其整套基礎模型和開發體系。大模型的研究,第一次有了一套開源的、靠譜的全鏈條工具。
模型 + 全套工具,開源真正實現「徹底」
此前,AWS 等國內外公司紛紛推出了基礎大模型技術平臺。基于大廠的能力,人們可以構建起生成式 AI 應用。相比之下,基于上海 AI 實驗室的基座模型和全鏈條開源體系,企業、研究機構/團隊既可以構建先進的應用,也可以深入開發打造各自垂直領域的大模型。
在上海 AI 實驗室看來,基礎大模型是進一步創新的良好開端。「書生」提供的并非單個的大模型,而是一整套基座模型體系,在全鏈條開源體系加持下,為學界和業界提供了堅實的底座和成長的土壤,從底層支撐起 AI 社區的成長,并且與更多的探索者共同建設「枝繁葉茂」的生態。

因此,就此次書生?浦語的開源而言,它是一套系統性工程,旨在推動行業進步,讓一線開發者更快獲取先進理念和工具。用「全方位開源開放」來形容可以說名副其實,模型、數據、工具和評測應有盡有。相比業界類似大模型平臺,書生?浦語首個實現了從數據到預訓練、微調,再到部署和評測全鏈條開源。
輕量化模型,性能業界最強
書生?浦語的 7B 輕量級版 InternLM-7B 不僅正式開源,還免費提供商用。作為書生?浦語開源體系中的基座模型,它為上海 AI 實驗室未來開源更大參數的模型做了一次探索性嘗試。
我們了解到,InternLM-7B 為實用場景量身定制,使用上萬億高質量語料來訓練,建立起了超強知識體系。另外提供多功能工具集,使用戶可以靈活自主地搭建流程。目前 GitHub star 量已經達到了 1.5K。
開源地址:
https://github.com/InternLM
InternLM-7B 的性能表現如何呢?上海 AI 實驗室給出的答案是:在同等參數量級的情況下全面領先國內外現有開源模型。
我們用數據來說話。對 InternLM-7B 的全面評測從學科綜合能力、語言能力、知識儲備能力、理解能力和推理能力五大維度展開,結果在包含 40 個評測集的評測中展現出卓越和均衡的性能,并實現全面超越。
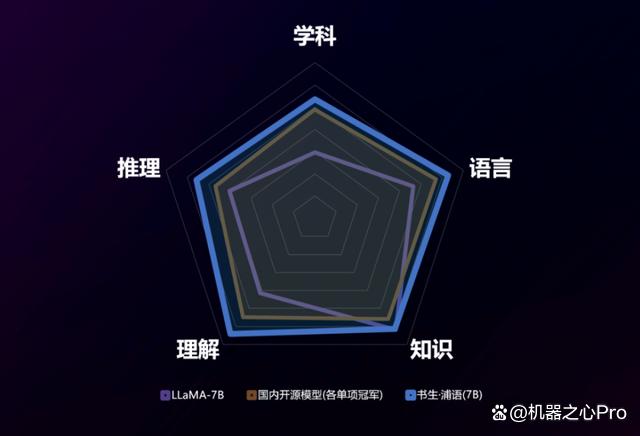
下圖展示了在幾個重點評測集上,InternLM-7B 與國內外代表性 7B 開源模型(如 LLaMA-7B)的比較。可以看到,InternLM-7B 全面勝出,在 CEval、MMLU 這兩個評價語言模型的廣泛基準上分別取得了 53.25 和 50.8 的高分,大幅領先目前業內最優的開源模型。
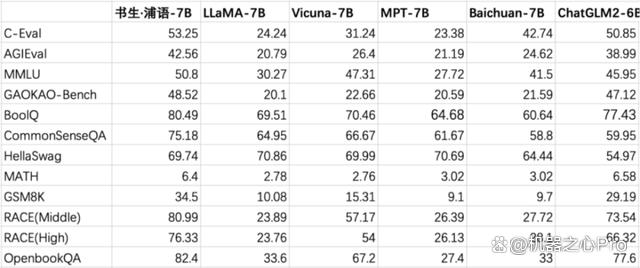
InternLM-7B 在開放評測平臺 OpenCompass 的比較結果。
書生是如何做到的?在接受機器之心專訪時,上海 AI 實驗室林達華教授向我們介紹了致勝之道。
與以往在單項或數項基準上達到高水平的模型不同,InternLM-7B 是一個基座模型,它不是針對某個特定任務或領域,而是面向廣泛的領域提供比較強大和均衡的基礎能力。因而強調各方面能力的均衡是它的一大特點。
為了實現均衡且強大的能力,InternLM-7B 在訓練和評估過程中使用了創新的動態調整模式:在每訓練一個短的階段之后,便對整個模型全面評估,并根據評估結果及時調整下一階段訓練數據分布。通過這套敏捷的閉環方式,模型在成長過程中始終保持能力均衡,不會因數據配比不合理而導致偏科。
同時,InternLM-7B 在微調體系上也有明顯升級,使用了更有效的微調手段,保證模型的行為更加可靠。
除了以上模型技術層面的升級,InternLM-7B 還具備可編程的通用工具調用能力。以 ChatGPT 為例,大模型可在解方程、信息查詢等簡單任務上調用工具來實現更準確有效的結果,但在復雜任務上需要調用更多機制才能解決問題。
InternLM-7B 具備了這種通用工具調用能力,使模型在需要工具的時候自動編寫一段 Python 程序,以綜合調用多種能力,將得到的結果糅合到回答過程,大幅拓展模型能力。
正是在訓練 - 評估 - 訓練數據分布調整閉環、微調以及工具調用等多個方面的技術創新,才讓 InternLM-7B 領跑所有同量級開源模型變成了可能。
大模型開源,就需要全鏈條
在書生?浦語全鏈條開源體系中,不僅囊括了豐富多元的訓練數據、性能先進的訓練與推理框架、靈活易用的微調與部署工具鏈,還有從非商業機構的更純粹學術和中立視角出發構建的 OpenCompass 開放評測體系。
與同類型開源體系相比,書生?浦語的最大特點體現在鏈條的「長」。競品工具鏈可能會覆蓋從微調到部署等少量環節,但書生?浦語將數據、預訓練框架、整個評測體系開源了出來。而且鏈條中一個環節到另一個環節,所有格式全部對齊,無縫銜接。
上海 AI 實驗室圍繞書生?浦語大模型打造了五位一體的技術內核。除了大模型本身,值得關注的還有預訓練環節開源的面向輕量級語言大模型訓練的訓練框架 InternLM-Train 以及評測環節的開放評測平臺 OpenCompass。
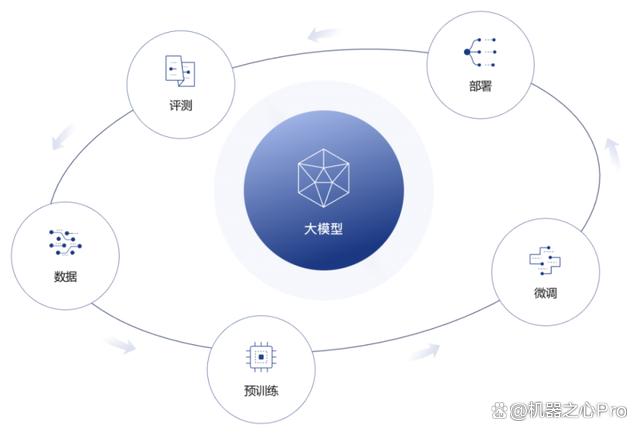
書生?浦語全鏈條工具體系。圖源:https://intern-ai.org.cn/home
我們知道,在現有 AI 大模型開發范式中,預訓練 + 微調是主流。可見預訓練對于大模型的重要性,很大程度上決定了模型任務效果。而其中底層的預訓練框架要在能耗、效率、成本等方面盡可能做到節能、高效、低成本,因此框架的創新勢在必行。
書生?浦語開源了訓練框架 InternLM-Train。一方面深度整合了 Transformer 模型算子,使得訓練效率得到提升。一方面提出了獨特的 Hybrid Zero 技術,實現了計算和通信的高效重疊,訓練過程中的跨節點通信流量大大降低。
得益于極致的性能優化,這套開源的體系實現了千卡并行計算的高效率。InternLM-Train 支持從 8 卡到 1024 卡的計算環境中高效訓練 InternLM-7B 或者量級相仿的模型,訓練性能達到了行業領先水平。千卡規模下的加速效率更是高達 90 %,訓練吞吐超過 180Tflop,平均單卡每秒處理 token 也超過 3600。
如果說預訓練決定了大模型的「成色」,評測則是校驗大模型成色的關鍵一環。當前由于語言大模型的能力邊界極廣,很難形成全面、整體的評價,因而需要在開放環境中逐漸迭代和沉淀。
書生?浦語開源體系上線了 OpenCompass 開放評測體系,更純粹學術和中立視角之外,它的另一大特點是基準「全」。除了自己的一套評測基準,OpenCompass 還整合了社區主流的幾十套基準,未來還將接納更多,從而讓開源模型更充分地彼此較量。
圖源:https://opencompass.org.cn/
具體地,OpenCompass 具有六大核心亮點。從模型評測框架來看,它開源可復現;從模型種類來看,它支持 Hugging Face 模型、API 模型和自定義開源模型等各類模型的一站式測評,比如 LLaMA、Vicuna、MPT、ChatGPT 等。InternLM-7B 正是在該平臺上完成評測。
從能力維度來看,它提供了學科綜合、語言能力、知識能力、理解能力、推理能力和安全性六大維度。同時提供這些能力維度下的 40+ 數據集、30 萬道題目,評估更全面。
林達華教授認為,能力維度的廣度和復雜度是模型評測面對的最大挑戰。一方面要充分考慮如何從不同的維度進行評價,一方面當要評測的指標變多的時候,還要兼顧如何以負擔得起的方式去評測。
此外,OpenCompass 非常高效,一行命令實現任務分割和分布式評測,數小時內完成千億模型全量評測;評測范式多樣化,支持零樣本、小樣本及思維鏈評測,結合標準型或對話型提示詞模板輕松激發各種模型最大性能;拓展性極強,輕松增加新模型或數據集、甚至可以接入新的集群管理系統。
目前,OpenCompass 上線了 NLP 模型的評測,也即將支持多模態模型的評測。
隨著 OpenCompass 平臺的影響力增加,上海 AI 實驗室希望對于大模型基準的評測也會對整個領域起到帶動作用。與此同時,在構建 AI 標準化的大模型專題組中,上海 AI 實驗室也與很多廠商形成了良好的合作關系。

在大模型快速演進的關鍵時期,標準制定與實施是推動產業進步的現實需求,也將為產業的可持續發展指明方向。
林達華教授表示:「創新是人工智能技術進步的源動力,而基座模型和相關的工具體系則是大模型創新的技術基石。通過此次書生?浦語的高質量全方位開源開放,我們希望可以助力大模型的創新和應用,讓更多的領域和行業可以受惠于大模型變革的浪潮。」
做真正有影響力的工作
值得一提的是,上海AI 實驗室成立的時間并不長——成立于 2020 年 7 月。作為一個新型研發機構,其主要開展重要基礎理論和關鍵核心技術。得益于其原創性、前瞻性的科研布局,以及強大的科研團隊,實驗室近期在多個關鍵領域實現重大突破。
「我們堅持上下游協同,做出的大模型第一時間在團隊中進行分享,在應用中得到反饋,進而持續迭代,」林達華介紹稱。
上海 AI 實驗室的技術領先,還在于做好三個方面的事:不設定發表論文或盈利的 KPI,做真正前沿有影響力的工作;開放創新空間,鼓勵團隊間積極交流,勇于嘗試不同的方向與想法;最后,實驗室為研究團隊提供了海量數據和算力作為支持。
此次書生?浦語的開源體系降低了大模型技術探索和落地的門檻,對于學界和業界而言意義重大,幫助更多研究結構和企業省去了基礎模型構建的步驟,他們可以在已有的強大模型與工具體系的基礎上繼續演進,實現創新。
未來,上海 AI 實驗室還將基于「書生?浦語」,在基礎模型和應用拓展方面進行探索,努力構建適用于關鍵領域落地的基礎模型。
書生開源體系可以大幅降低大模型技術探索和落地的門檻,如果你感興趣,歡迎來試試。
書生官網鏈接:
https://intern-ai.org.cn/home









)

數據庫備份與還原)







