前言
本系列文章架構概覽:
??本文將介紹基本遺傳算法在解決優化問題中的應用,通過實驗展示其基本原理和實現過程:選取一個簡單的二次函數作為優化目標,并利用基本遺傳算法尋找其在指定范圍內的最大值。
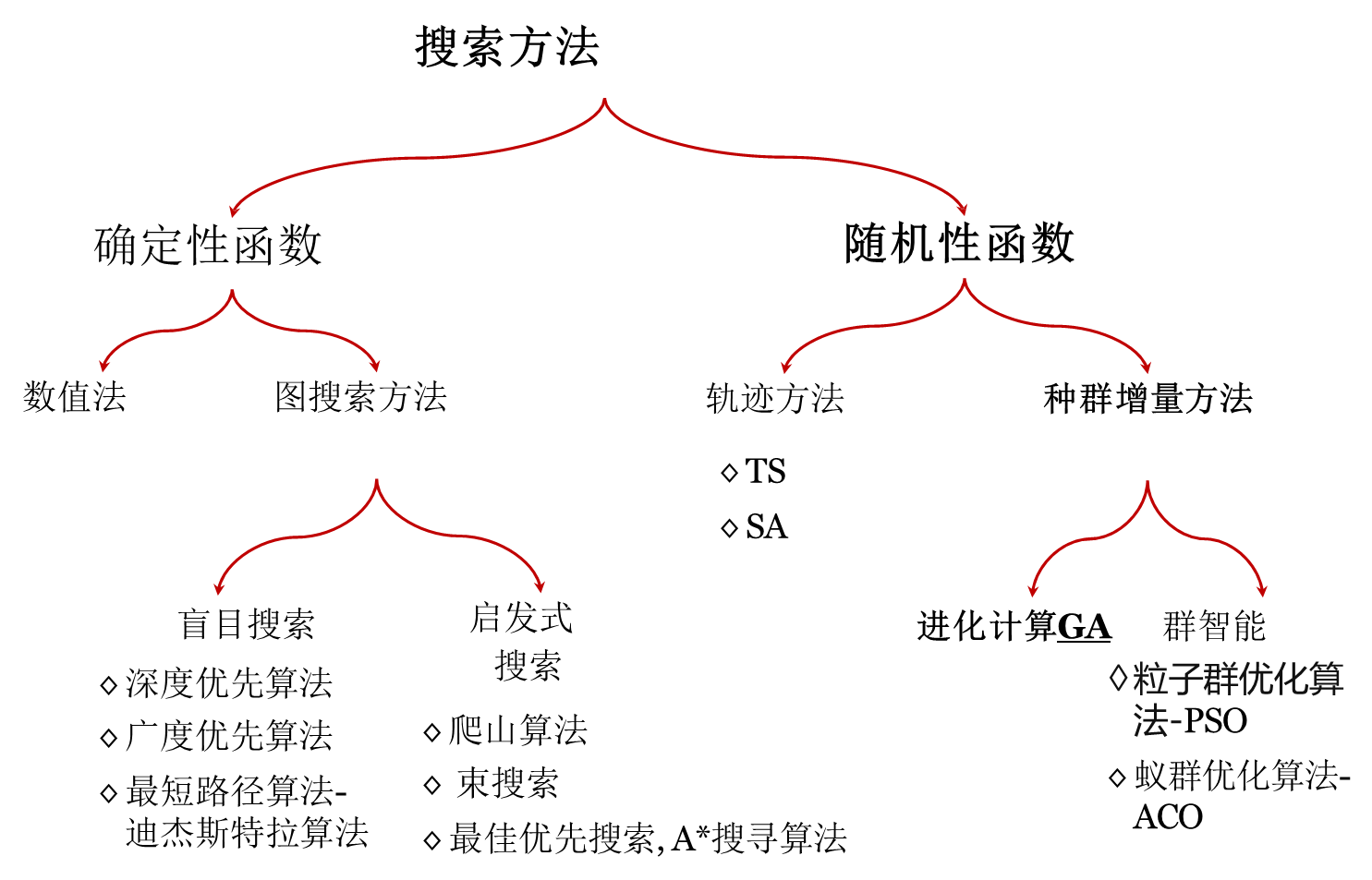
2. 基本遺傳算法(SGA)
??基本遺傳算法(Simple Genetic Algorithm : SGA)又稱為簡單遺傳算法,使用選擇算子、交叉算子和變異算子這三種基本的遺傳算子,操作簡單、容易理解,是其它遺傳算法的雛形和基礎。
2.1 基本遺傳算法的構成要素
??基本遺傳算法由染色體編碼方法、適應度函數和遺傳算子三個主要要素組成,前文已經對每個要素進行了詳細說明:
2.2 算法流程
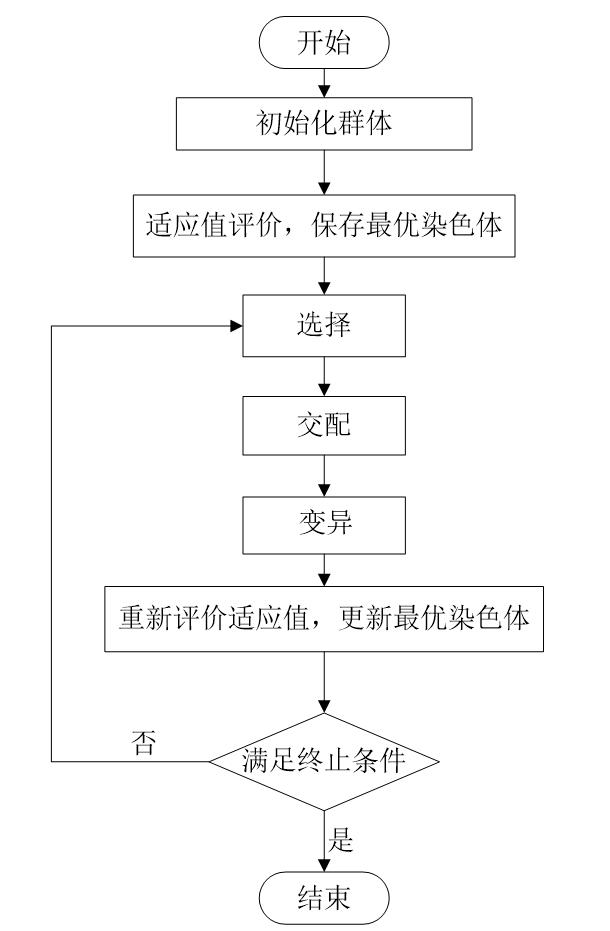
- 初始化種群: 隨機生成一定數量的個體,每個個體對應一個可能的解,用二進制或其他編碼方式表示。
- 適應度評價: 計算每個個體的適應度,適應度值反映了個體解的優劣程度。
- 選擇操作: 根據個體的適應度值,使用一定的選擇策略(如輪盤賭選擇、錦標賽選擇等)從當前種群中選擇出一部分個體,作為下一代種群的父代。
- 交叉操作: 對選中的父代個體進行交叉操作,產生新的子代個體。交叉操作通過==重組父代個體的基因==,產生新的解空間。
- 變異操作: 對交叉后的子代個體以一定的小概率進行變異操作,==引入新的基因==,增加種群的多樣性。
- 終止條件判斷: 檢查是否滿足算法終止條件(如達到最大迭代次數、找到滿意解等),若滿足則終止,否則回到步驟2,進行下一代種群的進化。
??通過不斷重復上述過程,種群中個體的適應度將逐漸提高,最終converge到問題的最優解或近似最優解。
2.3 偽代碼
Procedure GeneticAlgorithm()t = 0 // 初始化迭代次數InitializePopulation(P(t)) // 初始化種群Evaluate(P(t)) // 評估種群中個體的適應度Best = KeepBest(P(t)) // 保留當前最優個體while (not TerminationConditionMet()) doP(t) = Selection(P(t)) // 選擇操作P(t) = Crossover(P(t)) // 交叉操作P(t) = Mutation(P(t)) // 變異操作t = t + 1 // 更新迭代次數P(t) = P(t-1)Evaluate(P(t)) // 重新評估種群中個體的適應度if (BestIndividual(P(t)) > Best) thenBest = ReplaceBest(P(t)) // 更新最優個體end ifend whilereturn Best // 返回找到的最優解
End Procedure
3. 應用到優化問題中
3.1 理論分析
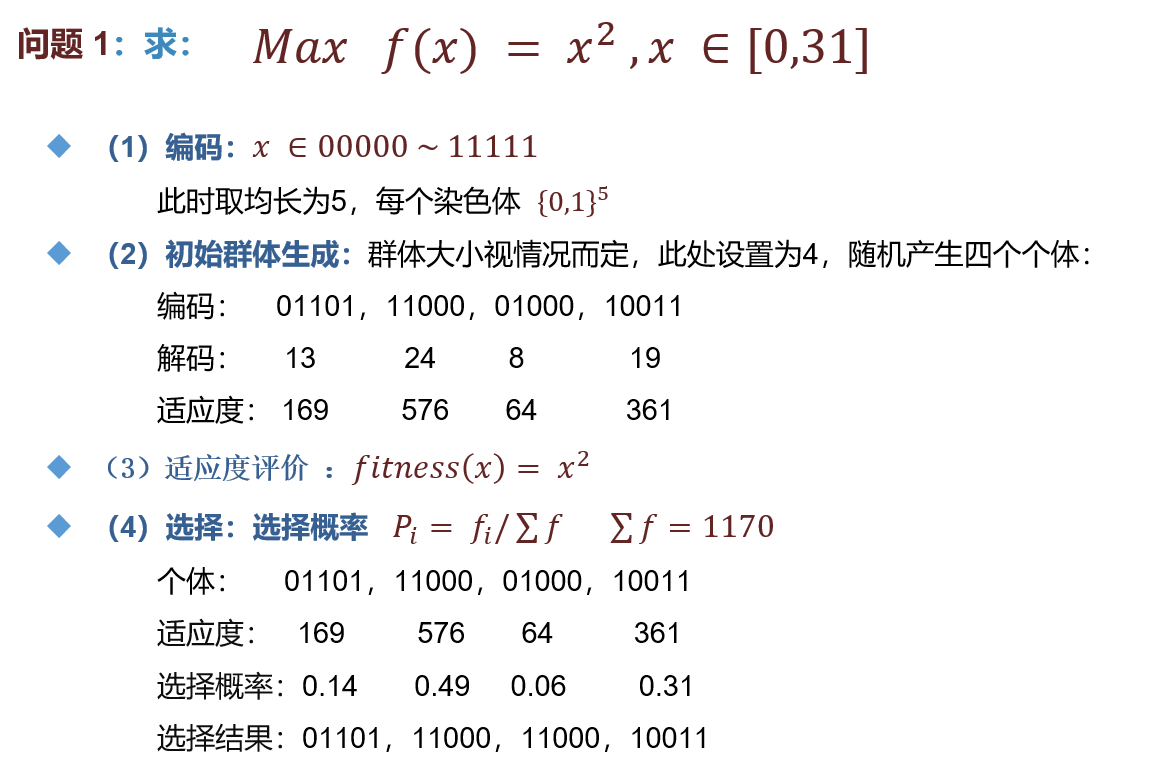
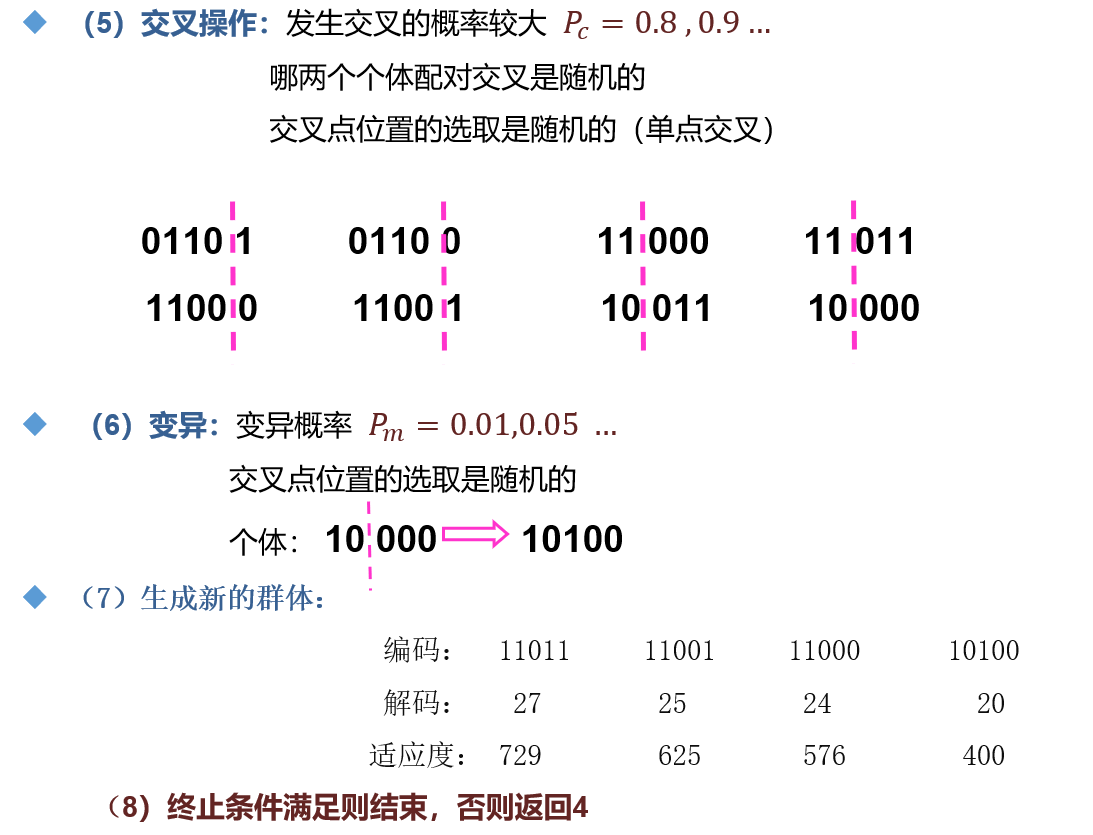
3.2 代碼實現
1. 導入所需庫
import random
2. 目標函數 f(x)
def f(x):return x ** 2
3 初始化種群
def initialize_population(population_size, chromosome_length):return [bin(random.randint(0, 31))[2:].zfill(chromosome_length) for _ in range(population_size)]
??生成指定大小的種群,每個個體都是一個長度為?chromosome_length?(本實驗為5)的二進制字符串,代表一個取值范圍在 0 到 31 之間的整數。函數可以拆分為:
def initialize_population(size):return [encode(random.randint(0, 31)) for _ in range(size)]
- 染色體編碼函數 encode(x)
def encode(x):return bin(x)[2:].zfill(5)
??將整數 x 編碼成一個長度為 5 的二進制字符串。內置的 bin() 函數將整數轉換為二進制字符串,然后使用 zfill() 函數填充到長度為 5。
4. 計算適應度
def evaluate_individual(individual):x = int(individual, 2)return f(x)def evaluate_population(population):return [evaluate_individual(individual) for individual in population]
evaluate_individual函數計算單個個體的適應度,將個體的二進制編碼轉換為十進制數x,然后計算目標函數f(x)的值作為適應度;evaluate_population函數遍歷整個種群,計算每個個體的適應度,返回一個包含所有個體適應度值的列表。
5. 選擇操作:輪盤賭選擇
def selection(population, fitness_values):total_fitness = sum(fitness_values)# 計算每個個體被選中的概率probabilities = [fitness / total_fitness for fitness in fitness_values]# print("\t選擇概率: {}".format(probabilities))selected_population = []for _ in range(len(population)):selected_individual = random.choices(population, weights=probabilities)[0]# print("\t被選個體: {}".format(selected_individual))selected_population.append(selected_individual)return selected_population
??從輪盤賭選擇的機制中可以看到,較優染色體的P值較大,被選擇的概率就相對較大。但由于選擇過程具有隨機性,并不能保證每次選擇均選中這些較優的染色體,因此也給予了較差染色體一定的生存空間。
點擊【計算智能】遺傳算法(二):基本遺傳算法在優化問題中的應用【實驗】——古月居可查看全文
)

)




】理解五種IO模型)











)