做數據的同學經常聽到一些數據相關的術語,常見的包括數據倉庫,邏輯數據倉庫,數據湖,數據湖倉/湖倉一體,數據網格 data mesh,數據編織 data fabric等.
筆者在這里回顧了下數據平臺的發展史,也介紹和對比了下常見的概念,主要包括數據倉庫,數據湖和數據湖倉,希望大家有所收獲。
回顧數據平臺發展歷史,梳理數據平臺變遷脈絡,更全面準確地理解數據倉庫數據湖和數據湖倉!
1 數據平臺概述
所謂「數據平臺,主要是指數據分析平臺,其消費(分析)內部和外部其它系統生成的各種原始數據(比如券商柜臺系統產生的各種交易流水數據,外部行情數據等),對這些數據進行各種分析挖掘以生成衍生數據,從而支持企業進行數據驅動的決策」:
數據分析平臺既可以部署在本地,也可以部署在云端,其典型特征有:
- 數據分析平臺,需要上游系統(內部或外部)提供原始數據;- 數據分析平臺,會經過分析生成各種結果數據(衍生數據);
- 數據分析平臺,生成的結果數據,一般主要服務于企業自身,支持企業進行數據驅動的決策,從而助力企業更好地經營:為顧客提供更好的服務,企業自身降本增效更好地運營,或發現新的商業洞察從而支持新的商業創新和新的業務增長點等(foster innovation);
- 數據分析平臺,生成的結果數據,也可以服務于外部客戶: 通過數據變現,為企業創造新的業務模式和利潤增長點;(各種提供數據服務的公司)
- 數據分析平臺,支持各種類型的數據分析應用,包括BI也包括AI;

數據(分析)平臺,常見的相關術語有:數據倉庫,數據湖,數據湖倉,數據中臺,邏輯數倉 Logical data warehouse,數據編織 Data fabric,Data mesh 等:
- 數據倉庫,數據湖,數據湖倉/湖倉一體:是數據平臺主要的支撐載體,是當前使用最廣泛的術語,其中數據湖倉也稱湖倉一體,本質是數據湖的2.0版本;
- 國內也經常講數據中臺:數據中臺在數據倉庫數據湖數據湖倉的基礎上,強調了將數據進行服務化API化,從而支持更快速敏捷地開發各種新型數據應用;
- 數據編織 Data fabric,數據網格 Data mesh:是隨著企業云化遷移以及微服務架構興起,逐漸流行起來的新的術語,在管理數據時更強調數據天然分布式的特性和數據產品的理念(數據是一種產品,來自不同服務由不同團隊管理);
- 需要注意的是,數據倉庫,數據湖與數據湖倉雖然有著明顯的學術定義上的區別,但是在業界很多場景下我們并不嚴格區分三者;
本次分享,我們主要關注數據倉庫數據湖和數據湖倉
2 數據平臺發展史-從數據倉庫數據湖到數據湖倉
整個數據平臺的發展史,其實可以用一句話簡單概括下:「數據平臺的發展,是隨著企業信息化和數字化的逐漸推進,從數據庫,數據倉庫,數據湖到數據湖倉逐漸演進的」:
- 在企業信息化早期,建設了各種線上業務系統如 ERP/CRM/OA等,這些業務系統通過數據庫沉淀了多種數據,其數據庫一般采用的是 OLTP的關系型數據庫;
- 隨著信息技術的進一步發展,企業逐漸意識到數據具有價值,并可以通過各種分析方法挖掘其中的價值,支持企業的管理決策,于是逐漸有了數據倉庫平臺(數據倉庫誕生于數據庫時代);
- 隨著大數據時代的到來,數據在種類和體量上都有了爆炸式的增長,數據的存儲和分析處理技術也有了進一步發展,為更好地挖掘數據中的價值,出現了數據湖平臺(數據湖脫胎于大數據時代,有著很強的開源和開放的基因);
- 隨著企業向數字驅動進一步邁進,對數據的存儲和分析處理有了更高的要求,出現了融合數據倉庫和數據湖各自特點的新型數據平臺,其實質是數據湖2.0,也被稱為數據湖倉;
2.1 數據倉庫
數據倉庫(Data Warehouse),是由被譽為全球數據倉庫之父的 W.H.Inmon 于1990年提出的,其相對學術的解釋:「數據倉庫是一個面向主題的(Subject Oriented)、集成的(Integrated)、相對穩定的(Non-Volatile)、反映歷史變化的(Time Variant)數據集合,用于支持管理決策和信息的全局共享」;
- 所謂主題:是指用戶使用數據倉庫進行決策時所關心的重點方面,如:收入、客戶、銷售渠道等;
- 所謂面向主題,是指數據倉庫內的信息是按主題進行組織的,而不是像業務支撐系統那樣是按照業務功能進行組織的;
- 所謂集成:是指數據倉庫中的信息不是從各個業務系統中簡單抽取出來的,而是經過一系列加工、整理和匯總的過程,因此數據倉庫中的信息是關于整個企業的一致的全局信息。
- 所謂隨時間變化:是指數據倉庫內的信息并不只是反映企業當前的狀態,而是記錄了從過去某一時點到當前各個階段的信息。通過這些信息,可以對企業的發展歷程和未來趨勢做出定量分析和預測;
- 之所以使用數據倉庫而不是前臺線上業務系統的OLTP數據庫進行BI等數據分析,一個重要的原始是OLTP只能應對簡單的關聯查詢,支撐基本的和日常的事務處理,不適用數據的多維度分析;而數倉底層一般是擅長多維分析的OLAP數據庫(還有一個原因是數據分析屬于后臺系統,不能影響前臺線上業務系統的性能)
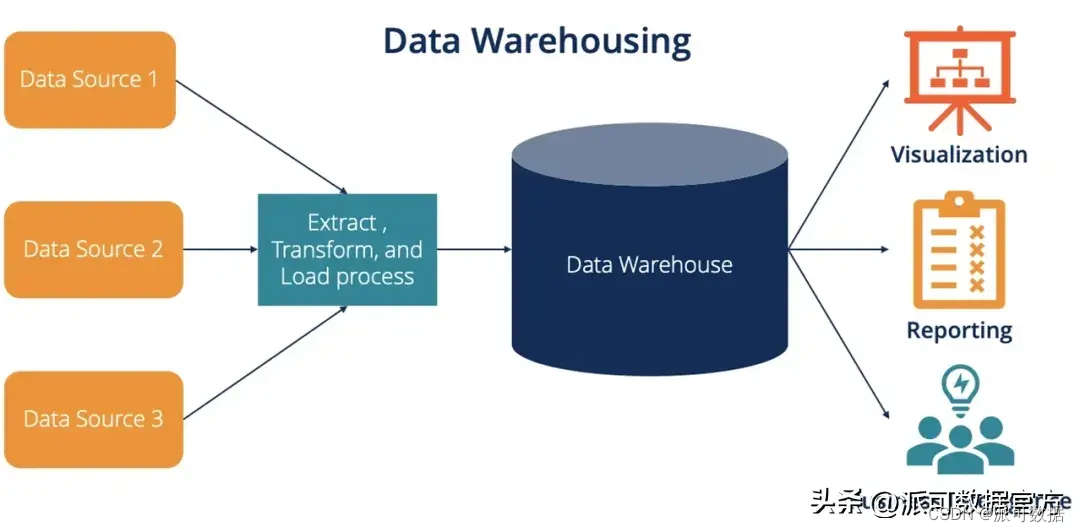
數據倉庫一般具有以下特點:
- 數倉強調數據建模,需要根據領域知識按照分層建模理論,進行詳細的模型設計;
- 數據由外部系統進入數倉時,需要經過清洗轉化后加載進數據倉庫,即 ETL;
- 數據需要ETL后進入數倉,本質是由于外部系統中的數據模型跟數倉中的數據模型是不同的(外部OLTP系統一般是按照范式設計的數據庫中的表,而數倉一般是OLAP中反范式的大寬表);
- 數倉模型的建設一般耗時耗力,但數倉模型一旦創建完畢,相對來說不會輕易做出改變;
- ETL的本質是 SCHEMA ON WRITE,即數據進入數倉時經由 ETL 完成了清洗和轉換,所以數倉中的數據質量較高;
- 數倉分層比較經典的有:ODS,DWD,DWS,ADS等;
- 數倉是商業智能BI的基礎,主要基于建好的數倉模型,經過分析回答固定的已知問題,從而支撐BI的報表和大屏等;
- 數倉一般內置存儲系統,且不對外直接暴露存儲系統接口(不允許外部系統直接訪問數倉底層存儲系統中的數據比如文件),而是將數據抽象的表或視圖的方式,通過提供數據進出的服務接口對外提供訪問(最常見的數據訪問方式是SQL,有的數倉對加載數據也提供了RESTFUL接口或專用的LOAD/COPY等命令);
- 數據倉庫通過抽象數據訪問接口/權限管理/數據本身,帶來了一定的封閉性,但換取了更高的性能(無論是存儲還是計算)、閉環的安全體系、數據治理的能力等,可以應對安全/合規等企業級要求;
- 數倉內置存儲系統但不對外直接暴露存儲系統接口,而是提供數據進出的服務接口,帶來了以下優缺點:
- 數倉具有封閉性,只能使用數倉專用的分析引擎,一般不能對接三方其它引擎;
- 數倉具有封閉性,不同數倉之間的數據遷移相對較難;
- 數倉性能較好:數倉計算引擎對內置存儲系統的數據存儲格式有深入了解,存儲和計算可以配合著做深度優化,提高數倉的性能;
- 數倉在數據治理上具有優勢:有完善的元數據管理能力,完善的血緣體系等,可以對數據進行全生命周期的細粒度的治理;
關于數倉,有以下幾點需要注意下:
- 傳統的數倉,底層一般是基于數據庫的,底層只能以表的形式存儲結構化數據,如 GreenPlum,Teradata,Vertica等,成本相對較高;
- 傳統的數倉,一般是存儲計算耦合的架構,在橫向擴展性和彈性能力上相對不足,能管理的數據量相對較小;
- 新興的云數倉,底層一般是基于云上對象存儲的,如 AWS Redshift、Google BigQuery、阿里云MaxCompute, Snowflake 等;
- 新興的云數倉,一般是存算分離的架構,存儲和計算可以獨立進行擴展,有著很好的橫向擴展性和彈性,可以管理大量數據;
2.2 數據湖
數據湖是大數據時代的產物,本身沒有相對官方的概念,其最早是由 Pentaho 的創始人兼首席技術官James Dixon 與2010年10月提出的,其后不同廠商有所延伸和細化:
- AWS的定義相對簡潔:數據湖是一個集中式存儲庫,允許以任意規模存儲所有結構化和非結構化數據,可以按原樣存儲數據(無需先對數據進行結構化處理),并運行不同類型的分析 – 從控制面板和可視化到大數據處理、實時分析和機器學習,以指導做出更好的決策;
- 維基的定義:數據湖將數據以自然/原始格式存儲在對象存儲或文件系統中,數據湖通常把企業所有數據統一存儲,包括源系統中的原始數據副本,傳感器數據,社交媒體數據等,也包括轉換后的數據,以用于支撐報表, 可視化, 高級數據分析和機器學習等。數據湖中的數據包括關系數據庫的結構化數據(行與列)、半結構化的數據(CSV,日志,XML, JSON),非結構化數據 (電子郵件、文件、PDF)和 二進制數據(圖像、音頻、視頻);
- Wiki: A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files. A data lake is usually a single store of data including raw copies of source system data, sensor data, social data etc., and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning);
- 數據湖是人工智能AI的基礎,存儲了企業內部各種原始數據,支持豐富的計算模型/范式,所以數據科學家和數據分析人員,可以采用各種統計分析,機器學習,深度學習等方法,對數據進行各種探索性分析挖掘,回答各種已知問題和未知問題,從而支撐各種AI場景;
數據湖為什么叫數據湖,而不叫數據河,數據海?一個貼切的解釋是:
- “河”強調的是流動性,河終究是要流入大海的,“海納百川”,這與企業級數據需要長期沉淀對應,因此叫“湖”比叫“河”要貼切;
- “海”是無邊無界的,而“湖”是有邊界的,這與企業級數據有邊界向對應(這個邊界就是企業/組織的業務邊界),因此叫“湖”比叫“海”要貼切;
- “湖”天然是分層的,滿足不同的生態系統要求,這與企業建設統一數據中心,存放管理數據的需求是一致的,“熱”數據在上層,方便應用隨時使用;溫數據、冷數據位于數據中心不同的存儲介質中,達到數據存儲容量與成本的平衡;
- 還有一個有關的概念是“數據沼澤”:數據湖需要精細的數據治理,包括權限管理,一個缺乏管控、缺乏治理的數據湖最終會退化為“數據沼澤”,從而使應用無法有效訪問數據,使存于其中的數據失去價值(數據湖中數據越多越需要數據治理);
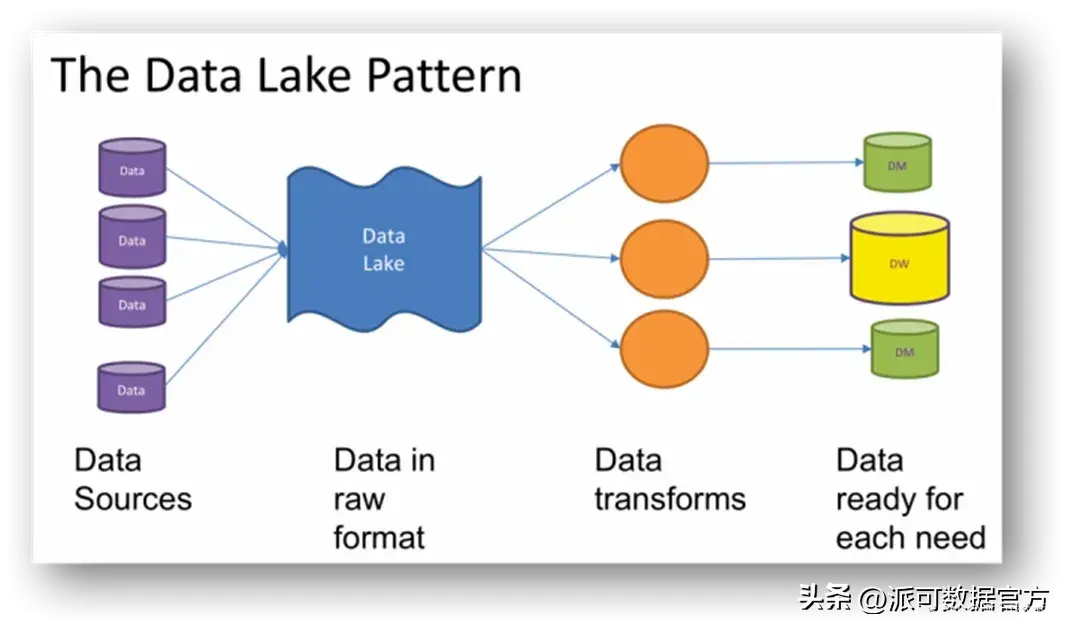
數據湖一般具有以下特點:
- 數據湖使用統一的存儲系統,可以存儲結構化數據(數據庫的表),半結構化數據(日志,JSON,xml等),也可以存儲非結構化數據(圖像音視頻等二級制格式);
- 數據由外部系統進入數據湖時,不需要經過清洗轉化后再加載進數據湖(ETL),而是采用 ELT,直接進行抽取和加載;
- 數據湖中的數據,在后續需要針對具體場景進行分析時,才會對湖中已經存在的原始數據進行 transform 轉化到特定的結構進而進行后續分析,即采用的是 schema on read 而不是 schema on write;
- 由于采用了 ELT 和 schema on read,所以數據湖落地初期不強調數據建模,不需要事先根據領域知識進行詳細的模型設計,所以數據湖相對數據倉庫,項目落地速度更快;
數據湖具有開放性,其開放性體現在以下幾點:
- 數據湖具有開放性,體現在數據湖中的數據可以使用多種文件格式進行存儲(如開源的 orc/parquet/avro等等);
- 數據湖具有開放性,體現在數據湖雖然內置了存儲系統,但一般會對外開放底層存儲系統的訪問接口;(如可以直接訪問HIVE底層表對應的HDFS/S3的文件);
- 數據湖具有開放性,也體現在數據湖中的數據可以使用多種分析引擎進行分析(本質還是因為數據湖底層存儲層是開放的,所以可以支持 spark/presto/flink 等多種分析引擎);
數據湖開放性的特點,帶來了以下優缺點:
- 通過底層存儲系統的開放性,使得數據湖存儲的數據結構可以是結構化的,可以是半結構化的,也可以是完全非結構化;
- 底層存儲系統的開放性,使得上層可以對接多種分析引擎,各種引擎也可以根據自己針對的場景有針對性地進行各種性能優化;
- 但底層存儲系統的開放性,也使得很多高階的功能很難實現,例如細粒度(小于文件粒度)的權限管理和統一化的文件管理,所以數據湖中如何對數據進行全生命周期的細粒度的治理是一個難題(包括統一的完善的元數據管理和血緣體系等 );
數據湖與上云無關,底層存儲可以采用文件系統也可以采用對象存儲,常見的實現有:
- 自建開源 Hadoop 數據湖架構(最常見);
- 云上托管 Hadoop 數據湖架構(如阿里和AWS的EMR數據湖);
- 云上非 hadoop 數據湖,如 Azure 數據湖,阿里云OSS 數據湖,Alluxio 虛擬數據湖等(對象存儲);
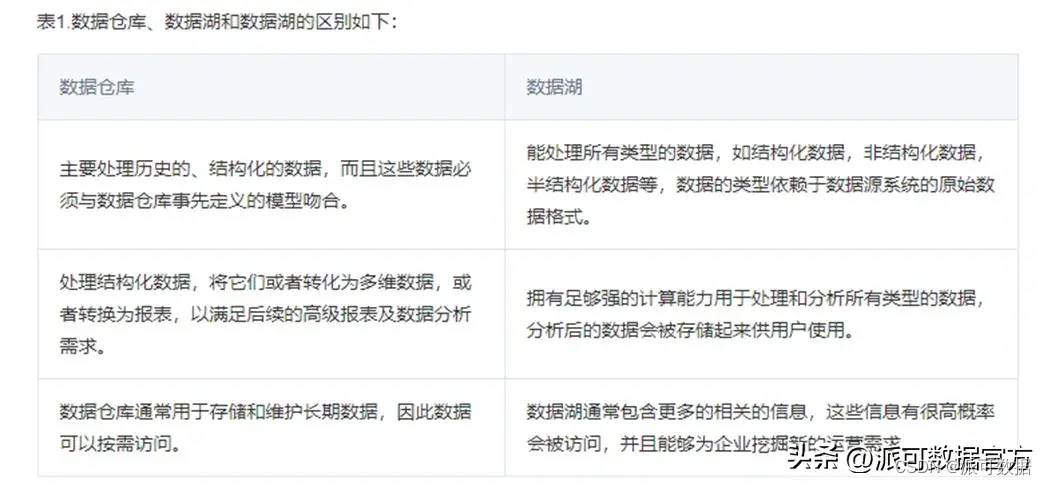
2.3 數據倉庫 vs 數據湖
經過前面對數據倉庫和數據湖的比較,我們可以看到,兩者在設計上的根本分歧點是對包括存儲系統訪問、權限管理、建模要求等方面的把控:
- 數據倉庫,更加關注的是數據使用效率、大規模下的數據管理、安全/合規這樣的企業級需求;
- 數據倉庫中,數據經過統一但開放的服務接口進入數據倉庫,數據通常預先定義 schema,用戶通過數據服務接口或者計算引擎訪問分布式存儲系統中的文件;
- 數據倉庫中,通過抽象數據訪問接口/權限管理/數據本身,換取了更高的性能(無論是存儲還是計算)、閉環的安全體系、數據治理的能力等,這些能力對于企業長遠的大數據使用都至關重要;
- 數據湖,通過開放底層文件存儲,給數據入湖帶來了最大的靈活性:進入數據湖的數據可以是結構化的,也可以是半結構化的,甚至可以是完全非結構化的原始日志。
- 數據湖,通過開放底層文件存儲,給上層的引擎也帶來了更多的靈活度:各種引擎可以根據自己針對的場景隨意讀寫數據湖中存儲的數據,而只需要遵循相當寬松的兼容性約定;
- 數據湖,開放底層文件存儲允許文件系統直接訪問,使得很多更高階的功能很難實現:例如細粒度(小于文件粒度)的權限管理、統一化的文件管理,ACID事務管理等,讀寫接口升級也十分困難(需要完成每一個訪問文件的引擎升級,才算升級完畢);
- 由于數據湖的上述特點,數據湖雖然容易落地,但隨著湖中數據量的增多,一旦數據治理措施不善,數據湖容易退化為數據沼澤,數據質量低下,用戶無法訪問數據或不易找到需要的數據,整個數據湖的價值也就退化了;

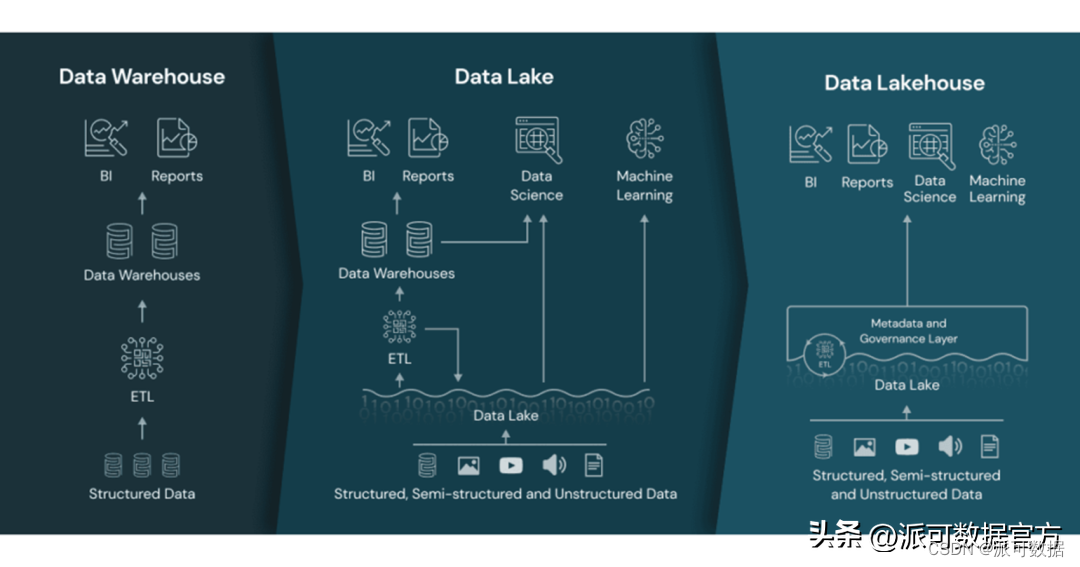
數據倉庫和數據湖,各有自己的優缺點,前者主要支撐BI場景,后者主要支撐AI場景,兩者并不是互斥的關系:「企業搭建數據平臺時,既有BI需求也有AI需求,所以現階段,很多數據平臺是融合了數據倉庫和數據湖的:使用數據湖泊作為底座,在數據湖基礎上組建多個數據倉庫,數據倉庫支撐各種BI業務場景,數據湖泊的底座除了支撐各個數據倉庫,也可以直接支撐機器學習和深度學習等AI場景;」
2.4 數據湖倉
上文講到,企業搭建數據平臺時,由于既有BI需求也有AI需求,所以現階段,很多數據平臺中融合搭建數據湖和數據倉庫以應對BI和AI兩大類數據分析場景,但是這樣勢必會造成資源的浪費,增加了數據成本。為解決數據平臺中融合搭建數據倉庫和數據湖造成的資源浪費問題,數據倉庫和數據湖廠商都做了自己的嘗試,給出了相應的解決方案:
- 數據倉庫廠商,推出的方案是,在自身已有功能的基礎上,開發各種連接器connector,然后以外表形式訪問外部數據湖底層存儲系統中的數據,從而擴展自己的功能;(如 GP/Doris 等都推出了訪問HDFS數據湖的connector)
- 而數據湖廠商,推出的方案是,補齊短板,改進和增強自身功能,包括支持ACID事務,加強數據治理能力等,這種方案本質是數據湖2.0,業界傾向叫它湖倉一體或數據湖倉 lake house,以強調其整合了傳統的data lake 和 data warehouse的能力;
筆者嘗試使用如下一句話概括總結下數據湖倉:「數據湖倉是在數據湖的基本架構上,通過一系列以表格式 Table Format 為代表的新技術解決了數據湖泊的各種傳統痛點,將數據倉庫和數據湖泊功能融合在一起,使其具有了數據倉庫在數據管理方面的各種優點,并直接支持 BI和AI的各種數據分析場景的新型架構」
數據湖倉最大的技術創新是,通過一系列以表格式 Table Format 為代表的新技術,為數據湖的基本架構帶來了ACID事務支持,提供了對記錄級別的增刪改的支持,對多作業并發讀寫同一個表或同一個分區的的支持,從而支持了以下特性:
- 數據湖倉在數據湖的架構基礎上融合了數倉式的數據管理能力:A lakehouse uses similar data structures and data management features as those in a data warehouse but instead runs them directly on data lakes,
- 數據湖倉同時直接支持BI和AI:A lakehouse allows traditional analytics, data science, and machine learning to coexist in the same system, all in an open format;
- 在數據湖倉lake house這個概念下,目前有 delta lake/hudi/iceberg 甚至 hive orc事務表這些框架來支持;
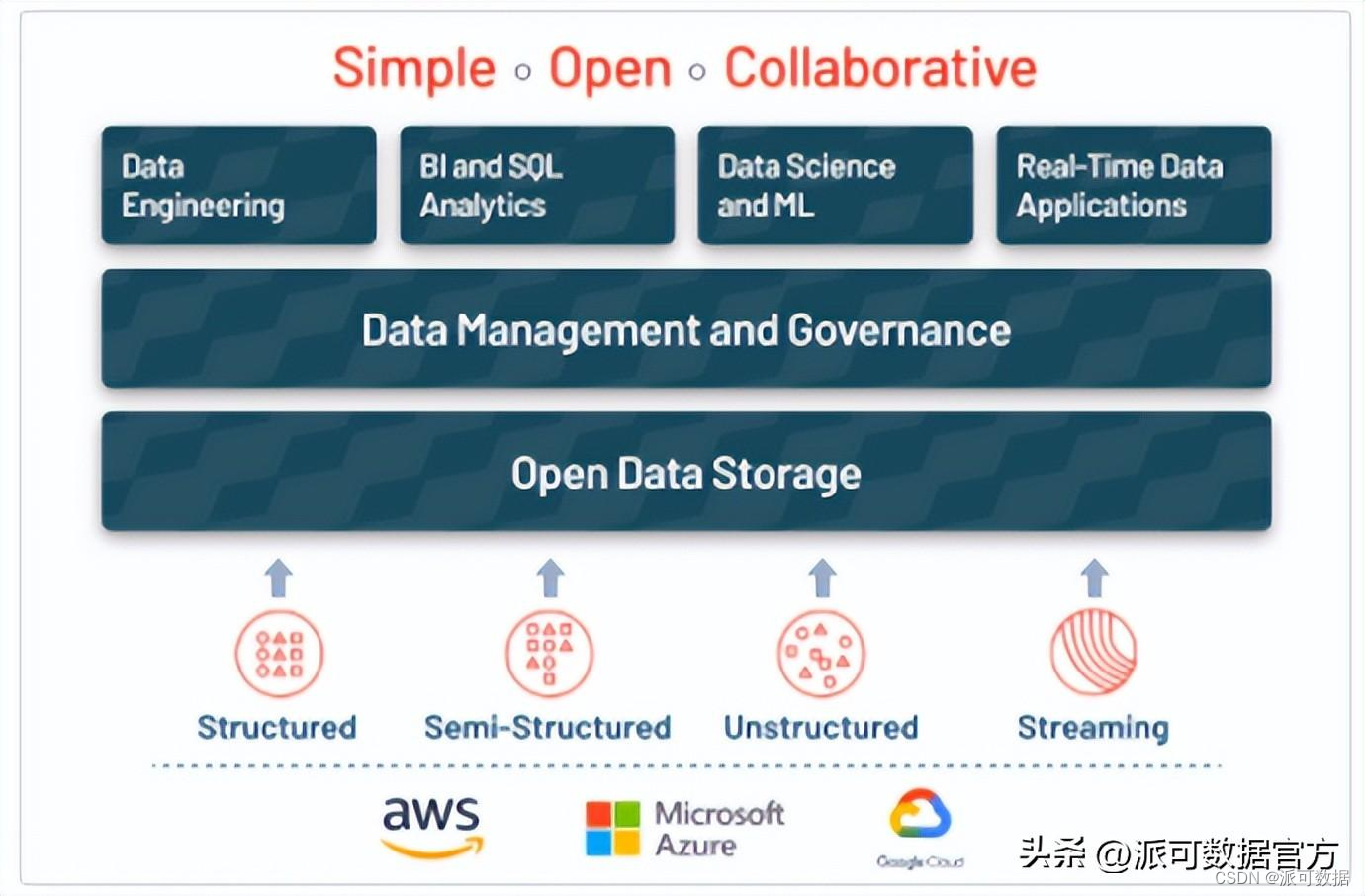
數據湖倉一般具有以下基本特征:
- 使用統一的存儲引擎和開放的格式(文件格式和表格式);
- 對象存儲優先;
- 支持多種分析引擎;
- 支持并發讀寫和事務的acid特性;
- 支持記錄級別的增刪改;
- 支持增量更新數據;數據湖倉通常也支持以下高級特性:
- 模式演化模式約束: schema evolution,schema enforecement
- 歷史版本回溯: history
- 流式增量導入(流批一體存儲)


3 數據湖倉典型框架的特性與架構
數據湖廠商,改進和增強了自身功能,包括支持ACID事務和加強數據治理能力等,融合了傳統的data lake 和 data warehouse的特點,推出了數據湖2.0方案,該方案即湖倉一體或數據湖倉 lake house,在數據湖倉lake house這個概念下,目前最主流的是數據湖三劍客:delta lake/apache hudi/apache iceberg;
- Delta lake: Delta Lake是由 Apache Spark 背后的商業公司 Databricks 推出的一個致力于在數據湖之上構建湖倉一體架構的開源項目,Delta Lake 支持ACID事務,可擴展的元數據存儲,在現有的數據湖(S3、ADLS、GCS、HDFS)之上實現流批數據處理的統一;
- Apache Hudi:Hudi 最初是由 Uber 的工程師為滿足其內部數據分析的需求而設計的數據湖項目, 其設計目標正如其名,Hadoop Upserts Deletes and Incrementals(原為 Hadoop Upserts anD Incrementals),在開源的文件系統之上引入了數據庫的表和事務的概念,支持高效的更新/刪除、索引、流式寫服務、數據合并、并發控制等功能特性。
- Apache Iceberg:Iceberg 最初是由 Netflix 為解決使用 HIVE 構建數據湖倉時的諸多缺陷而研發的,最終演化成 Apache 下一個高度抽象通用的開源數據湖方案,用于處理海量分析數據集的開放表格式,支持 Spark, Trino, PrestoDB, Flink and Hive等計算引擎,它具有高度的抽象和優雅的設計;
三大數據湖倉框架在官網對自身的介紹如下:
- Delta Lake is an open-source storage framework that enables building a Lakehouse architecture with compute engines including Spark, PrestoDB, Flink, Trino, and Hive and APIs for Scala, Java, Rust, Ruby, and Python.
- Apahce Hudi: Hudi is a rich platform to build streaming data lakes with incremental data pipelines on a self-managing database layer, while being optimized for lake engines and regular batch processing. brings transactions, record-level updates/deletes and change streams to data lakes!
- Apache Iceberg: Iceberg is a high-performance format for huge analytic tables. Iceberg brings the reliability and simplicity of SQL tables to big data, while making it possible for engines like Spark, Trino, Flink, Presto, Hive and Impala to safely work with the same tables, at the same time.
三者均為 Data Lake 的數據存儲中間層,是文件格式 file format之上的表格式 table format,其數據管理的功能均是基于一系列的 meta 文件:
- 文件格式:文件格式描述的是單個文件中數據的組織和管理格式,如ORC/PARQUET/AVRO等;
- 表格式:表格式表述的是由一系列文件構成的邏輯集合,即表,其底層的文件與數據的組織和管理格式;
- meta 文件類似于數據庫的 catalog/wal,起到 schema 管理、事務管理和數據管理的功能:
- 與數據庫不同的是,這些 meta 文件是與數據文件是一起存放在存儲引擎中的,用戶可以直接看到;
- meta 文件通常使用行存 json/avro格式,數據文件通常使用列存 parquet/orc格式;
- Meta 文件包含有表的 schema 信息: 因此系統可以自己掌握 Schema 的變動,提供 Schema 演化的支持;
- Meta 文件包含有事務日志 transaction log: meta 文件中記錄了 transaction log,所以可以提供 ACID 事務支持;
- 所有對表的變更操作都會生成一份新的 meta 文件:于是系統就有了多版本的支持,可以提供訪問歷史版本的能力;
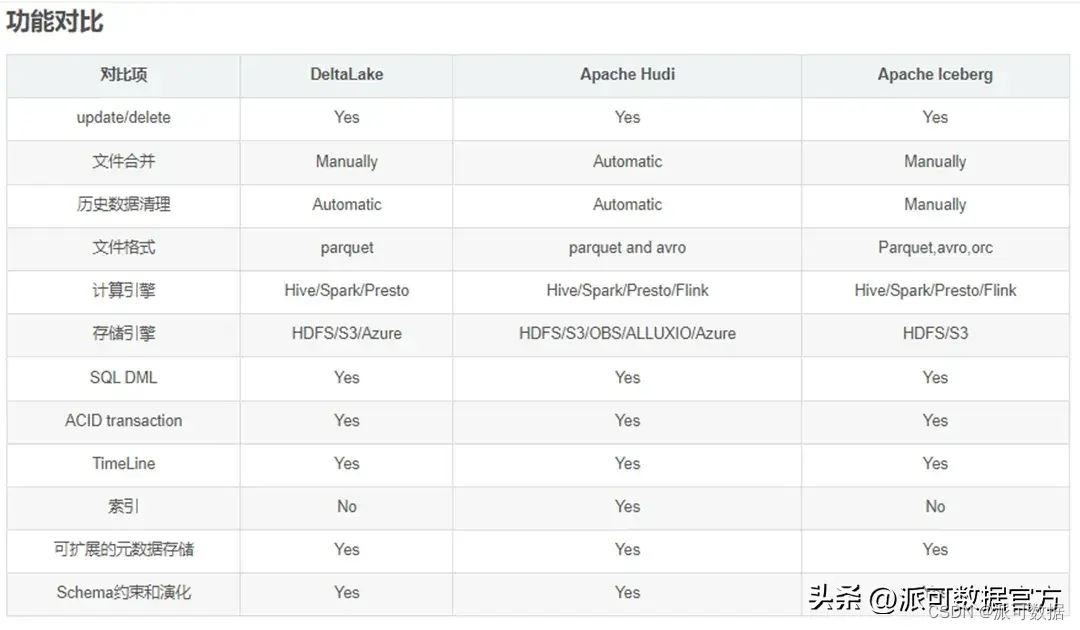
三者的相似點如下:
- 三者都是 Data Lake 的數據存儲中間層,在技術實現上都是基于一系列的 meta 文件構建了file format 之上的table format;
- 三者都使用了統一的存儲引擎和開放的格式(文件格式和表格式);
- 三者都能支持主流的高可用存儲如 HDFS、S3,對象存儲優先;
- 三者都支持記錄級別的 update/delete,以增量更新數據;
- 三者都支持并發讀寫和事務ACID特性:即原子性、一致性、隔離性、持久性,通過避免垃圾數據的產生保證了數據質量;
- 三者都 (努力)支持流批一體存儲,以流式增量導入數據;
- 三者都提供了對多查詢引擎的支持:如 Spark/Hive/Presto;
- 三者都支持歷史版本回溯;
- 三者都支持模式約束和演化 schema evolution,schema enforecement;
三者最初的設計初衷和對應場景并不完全相同,尤其是Hudi,其設計與另外兩個相比差別更為明顯,但數據湖倉要解決的問題是共同的,隨著時間的發展,三者都在不斷補齊自己缺失的能力,在將來會彼此趨同,成為功能相似卻又各有特點的主流數據湖倉框架,目前三者的差異點主要如下:
- Hudi 為了高效的 incremental 的 upserts,設計了類似于主鍵的HoodieKey 的概念,表也分為 Copy On write和Merge On Read,分別為讀和寫進行了優化;
- Iceberg 定位于高性能的分析與可靠的數據管理,專門針對HIVE的諸多痛點進行了設計;(如 HIVE 只有目錄級別而沒有文件級別的統計信息,元數據分散在 MySQL 和 HDFS中寫入操作原子性差,等等)
- Delta 定位于流批一體的數據處理,與SPARK的兼容性最好;
以下重點看下Iceberg的架構特點: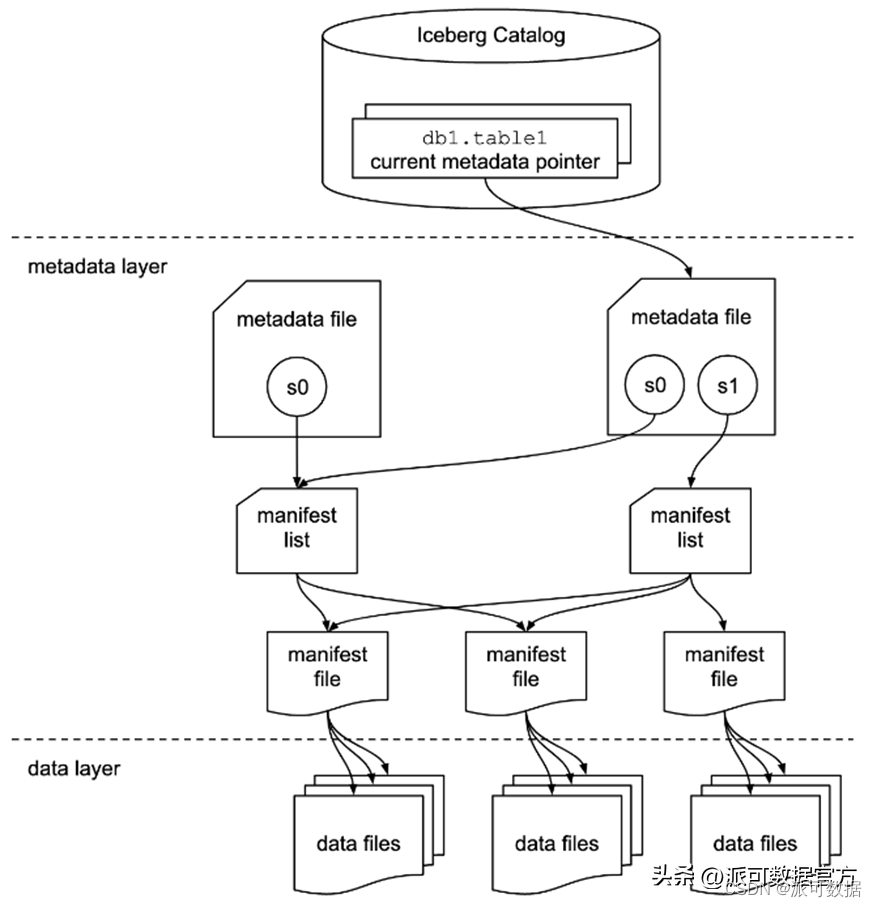
- 整體分為三層:Catalog層,元數據層和數據層;
- 元數據層本身又是多層級的體系,包括:metadata file, manifest list, manifest file;
- Metadata file: Table state is maintained in metadata files. All changes to table state create a new metadata file and replace the old metadata with an atomic swap. The table metadata file tracks the table schema, partitioning config, custom properties, and snapshots of the table contents. A snapshot represents the state of a table at some time and is used to access the complete set of data files in the table.
- Manifest file: Data files in snapshots are tracked by one or more manifest files that contain a row for each data file in the table, the file’s partition data, and its metrics. The data in a snapshot is the union of all files in its manifests. Manifest files are reused across snapshots to avoid rewriting metadata that is slow-changing. Manifests can track data files with any subset of a table and are not associated with partitions.
- Manifest list/snapshot: The manifests that make up a snapshot are stored in a manifest list file. Each manifest list stores metadata about manifests, including partition stats and data file counts. These stats are used to avoid reading manifests that are not required for an operation.
- 通過表格式在文件而不是目錄級別進行管理(顯著區別與HIVE的地方):This table format tracks individual data files in a table instead of directories. This allows writers to create data files in-place and only adds files to the table in an explicit commit.
4. 數據湖倉的應用現狀與發展建議
對大多數尚未大規模引進數據湖倉技術的公司,筆者有如下幾點建議:
- 隨著數字化轉型的進一步推進,BI和AI等各類數據分析需求日益遞增,為更好地支撐各種數據需求,應盡早調研嘗試引入數據湖倉作為企業級數據平臺;(選擇合適的產品/項目/場景,可以先從公司自身的數據平臺著手);
- 隨著數字化轉型的進一步推進,大數據與云計算的結合越來越緊密,數據湖倉平臺底層的存儲系統更傾向于使用S3/MINIO/OZONE等對象存儲,應盡早調研嘗試使用對象存儲(公有云私有云行業云甚至數據中心等場景,都有相應的對象存儲解決方案,存算分離架構下可以通過Alluxio 等緩存框架加速分析性能);
- 隨著數字化轉型的進一步推進,企業愈加重視資源和應用的彈性/可擴展性以及成本,應盡早調研嘗試在K8S上搭建數據湖倉平臺;(大數據計算引擎如 spark/flink 等在 ON K8S 上部署方案已經成熟,AI的 tensorflow 等引擎在K8S上的部署方案也已成熟);
- 加強公司內部AI和大數據部門之間的交流合作,嘗試通過數據湖倉平臺滿足兩個部門日常各種BI/AI類數據分析需求;
文章來源于明哥的IT隨筆 ,作者IT明哥。




——數組,常量)


)






方法——判斷字符串是否只由字母組成)

配置bond0的mac地址為指定子網卡的mac地址)


