大模型的基礎模式是transformer,所以很多芯片都實現先專門的transformer引擎來加速模型訓練或者推理。本文將拆解Transformer的算子組成,展開具體的數據流分析,結合不同的芯片架構實現,分析如何做性能優化。
Transformer結構
transformer結構包含兩個過程,Encoder和Decoder。其中Decoder較Encoder結構相同,多了對于kv_cache的處理。
如下圖經典的結構示意圖,可以看到在Decoder階段的Multi-Head Attentiond的三個輸入箭頭其中兩個來自Encoderde輸出,關于kv-cache對內容管理的優化也是一個很重要的研究方向。本文暫時重點關注與Transformer的Encoder階段的優化分析。

Transformer的數據流圖
下圖對應上面transformer的左邊Encoder階段。不同顏色表示不同的算子,其中linear, 其實也是一種matmul算子,只不過它的兩個輸入一個來自tensor, 一個來自常量。藍色標記的matmul算子則兩個輸入全部是tensor。
包含的算子為:linear, matmul, transpose, softmax, add_layernorm。
通過代入參數,了解具體的數據流執行過程,可以讓我們更加直觀的理解下面的優化之后,得到相同的輸出數據的思路。

優化設計1:圖優化
根據上面的數據流圖可以發現,transpose算子只是對數據進行重排,并不需要計算,但是過多的transpose算子需要不停從內存搬移數據,消耗緊缺的帶寬資源,所以一個簡單的優化點就是通過硬件架構的設計,來減少transpose層。
對硬件來說,在實現GEMM算子是的時候,對兩個矩陣取數過程,增加一個transpose的邏輯,?不會消耗很多的資源,所以可以對GEMM的兩個輸入數據,分別設計是否打開transpose的參數。
假設GEMM算子原始的數據存放排布矩陣A為(batch, M, K), 矩陣B為(batch, K, N)。得到的輸出為(Batch, M , N)。下面對transpose的多頭注意力模塊進行優化,示例了兩種方案,來減少單獨的transpose算子開銷。
transpose前置(A_transpose_en)
利用矩陣A的transpose開關,將q, k, v的transpose前置,?數據流圖如下,這樣可以將原本的5個transpose操作減小為2個。
注意圖中用紅色和藍色標記了GEMM算子的矩陣A,矩陣B的設定,當一個linear或者matmul算子的兩個輸入中顯示(Batch, K, M)時候,即認為打開了GEMM算子的A矩陣transpose開關

transpose內置(B_transpose_en)
當利用B矩陣的transpose_en功能,優化后的數據流圖如下。在QV的matmul計算過程,逆向利用矩陣B的transpose開關,這樣可以將原本的5個transpose操作減小為1個。
當一個linear或者matmul算子的兩個輸入中顯示(Batch, N, K)時候,即認為打開了GEMM算子的B矩陣transpose開關
???????????????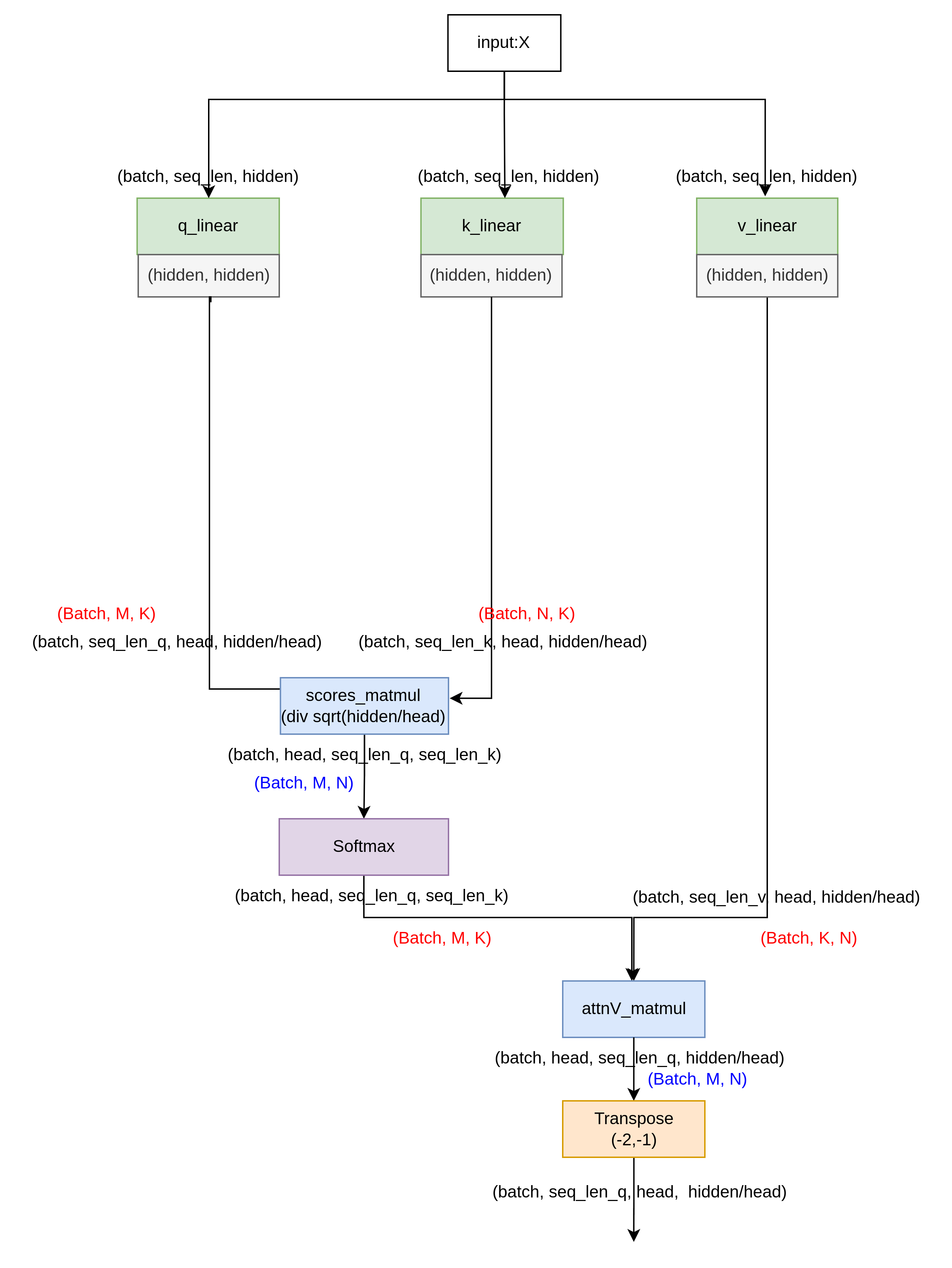
通過上面兩個方案,大家可能會對attnV_matmul那一步的數據流關于head位置有點疑問,在這里我們不妨這樣考慮,將head分給多個thread線程來做,只要thread的數據位置取的對,是可以將(batch, head,seq_len_q, seq_len_k)和(batch, seq_len_v, head, hidden/head)進行矩陣乘得到(batch, head, seq_len_q, hidden/head)的輸出的。
優化設計2:任務并行拆解
模型的分布式并行策略有數據并行,張量并行,pipline 并行等,這些策略的一個要點就是合理利用集群資源,讓更多的任務并行基礎上,減少中間節點的數據通信。
當我們在一個有很多節點的集群上部署大模型時候,因為模型數據維度較大,往往需要將其拆解到不同的芯片(集群)運行,尤其是GEMM算子,不同的拆分方案對應不同的通信開銷。下面我們來具體分析一個任務并行的拆解方案。
如圖,首先針對attention模塊的多頭特征,選擇在qkv_linear的weights的outZ方向切分為head份,假設有head個計算節點,每個節點計算1個head的matmul任務,因為沒有在累加的維度拆分,所以這樣每個節點可以順序執行下一層任務,不需要交互數據。直到attnV_matmul之后,需要做fc0_linear的任務,要把所有的head合并起來累加運算,所以增加了all_gather的通信開銷。接著為了避免通信開銷,fc0和add_layernorm選擇在seq維度拆分。當到達fc1_linear,對depth_hidden進行了拆分,但是fc2_linear需要對所有的depth_hidden進行累加,所以fc2_linear之前需要再一次的all_gather通信。

當然根據具體的硬件條件限制,還可以有其他的任務拆解方案,總之,需要具體場景具體分析。這里僅做簡單的優化示例參考。
歡迎評論交流,如果覺得內容有幫助,需要您的點贊鼓勵!


)










:深入解析與實戰示例)




)
