在本教程中,我們將使用 WebGPU 技術中的計算著色器實現圖像效果。更多精彩內容盡在數字孿生平臺。

程序結構
主要構建兩個 WebGPU 管道:
- 運行反應擴散算法多次迭代的計算管道(
js/rd-compute.js和js/shader/rd-compute-shader.js) - 渲染管道,它獲取計算管道的結果并通過渲染全屏三角形(
js/composite.js和js/shader/composite-shader.js)來創建最終合成圖像。
WebGPU 是一個非常繁瑣的 API,為了使其更容易使用,我使用了 webgpu-utils 庫。此外,還包含 float16 庫,用于創建和更新計算管道的存儲紋理。
計算管道流程
在 GPU 上運行反應擴散模擬的一種常見方法是使用紋理交替。就是創建兩個紋理,一個紋理保存要讀取的模擬的當前狀態,另一個紋理存儲當前迭代的結果。每次迭代后,紋理都會交換。
此方法也可以使用片段著色器和幀緩沖在 WebGL 中實現。但是在 WebGPU 中,我們可以使用計算著色器和存儲紋理作為緩沖區來實現相同的效果。這樣做的優點是我們可以直接寫入我們想要的紋理內的任何像素,還獲得了計算著色器帶來的性能優勢。
初始化
首先是使用所有必要的布局描述符初始化管道。此外,還必須設置所有的緩沖區、紋理和綁定組。webgpu-utils 庫就可以在這里節省大量工作。
WebGPU 不允許在創建緩沖區或紋理后更改其大小。因此,我們必須區分大小不變的緩沖區(例如uniform)和在某些情況下發生變化的緩沖區(例如調整畫布大小時的紋理)。對于后者,我們需要一種方法來重新創建它們并在必要時銷毀舊的緩沖區。
用于反應擴散模擬的所有紋理都是畫布大小的一小部分(例如畫布大小的四分之一)。要處理的像素數量較少,可以釋放計算資源以進行更多迭代。因此,可以以相對較小的視覺損失進行更快的模擬。
除了“紋理交換”中涉及的兩個紋理之外,示例中還有第三個紋理,我將其稱為種子紋理。此紋理包含在其上繪制時鐘字母的 HTML 畫布的圖像數據。種子紋理用作反應擴散模擬的一種影響圖,以可視化時鐘字母。當 WebGPU 畫布調整大小時,必須重新創建該紋理以及相應的 HTML 畫布大小調整。
運行模擬
完成所有必要的初始化后,我們可以使用計算著色器實際運行反應擴散模擬。我們先回顧一下計算著色器的一些特性。
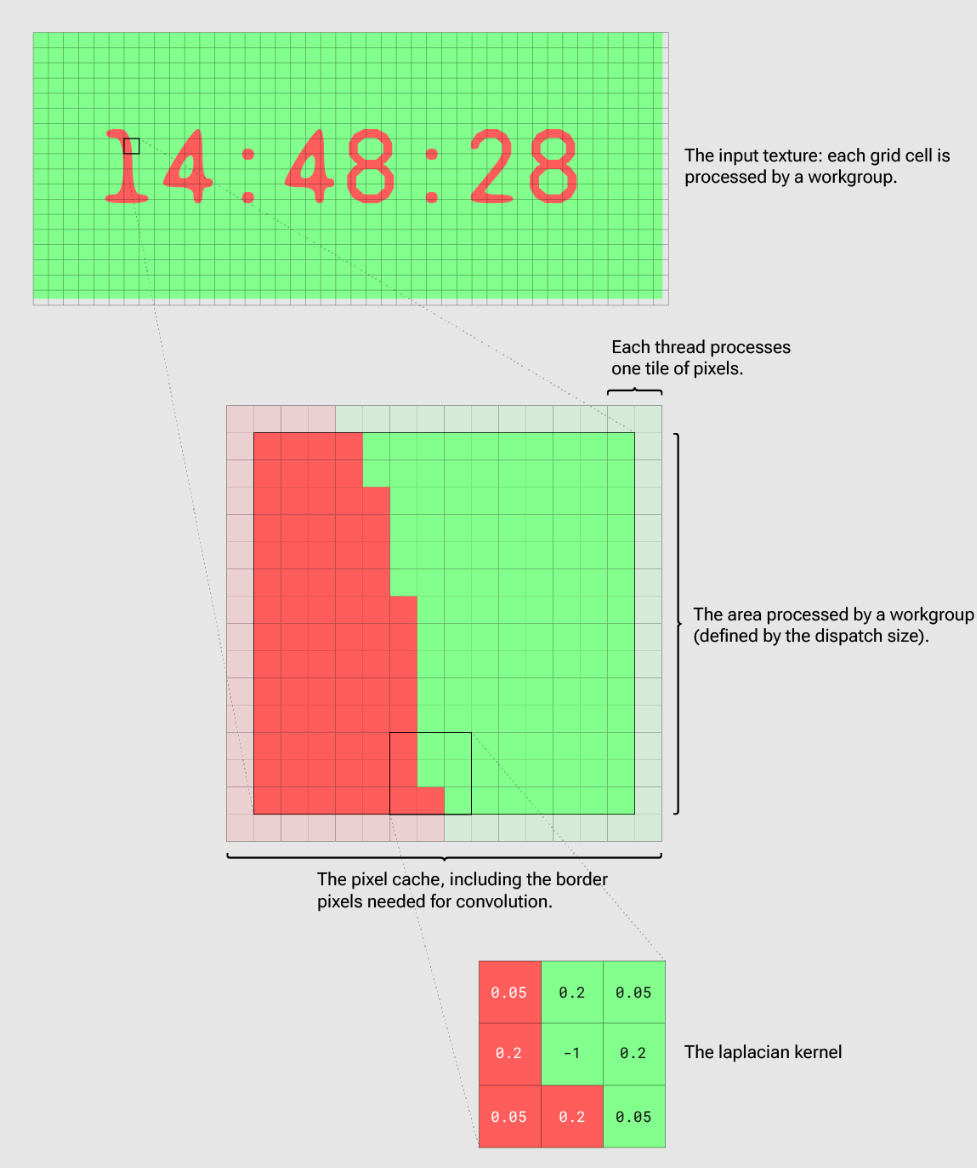
計算著色器的每次調用都會并行處理多個線程。線程數由計算著色器的工作組(workgroup)大小定義。著色器的調用次數由調度(dispatch)大小定義(線程總數 = 工作組大小 * 調度大小)。
這些值以三個維度指定。因此,并行處理 64 個線程的計算著色器可能如下所示:
@compute @workgroup_size(8, 8, 1) fn compute() {}
運行此著色器 256 次(即 16,384 個線程)需要如下的調度大小:
pass.dispatchWorkgroups(16, 16, 1);
反應擴散模擬要求我們處理紋理的每個像素。實現此目的的一種方法是使用 workgroup 大小為 1 和 dispatch大小等于像素總數(像是模仿片段著色器)。但是這樣不會提高性能,因為 workgroup 中的多個線程比單獨的調度更快。
另一方面,我們可能想到使用等于像素數的 workgroup 大小,并且僅調用一次(dispatch 大小為 1)。然而這是不可能的,因為最大 workgroup 大小是有限的。對于 WebGPU 的一般建議是選擇 workgroup 大小為 64。這要求我們將紋理內的像素數量劃分為 workgroup 大小(= 64 像素)的塊,并經常調度工作組以覆蓋整個紋理。
因此,現在我們有了 workgroup 大小的恒定值,并且能夠找到適當的 dispatch 大小來運行我們的模擬。但是其實我們還有更多可以優化的地方。
每線程像素數
為了使每個workgroup覆蓋更大的區域(更多像素),我們引入了圖塊大小。圖塊大小定義每個單獨線程處理的像素數,這就需要我們在著色器中使用嵌套 for 循環,所以我們需要保持圖塊大小非常小(例如 2×2)。
像素緩存
運行反應擴散模擬的一個重要步驟是與拉普拉斯核(3×3 矩陣)進行卷積。因此,對于我們處理的每個像素,我們必須讀取內核覆蓋的所有 9 個像素才能執行計算。由于像素與像素之間的內核重疊,因此會出現大量冗余紋理讀取。
幸運的是,計算著色器允許我們跨線程共享內存。所以我們可以創建像素緩存。這個方式(來自圖像模糊示例)是每個線程讀取其圖塊的像素并將它們寫入緩存。一旦workgroup的每個線程都將其像素存儲在緩存中(我們通過工作組屏障確保這一點),實際處理只需要使用從緩存中預取的像素。因此它不需要任何進一步的紋理讀取。計算函數的結構可能如下所示:
// workgroup所有線程共享的像素緩存
var<workgroup> cache: array<array<vec4f, 128>, 128>;@compute @workgroup_size(8, 8, 1)
fn compute_main(/* ...builtin variables */ ) {// 將此線程的圖塊的像素添加到緩存中for (var c=0u; c<2; c++) {for (var r=0u; r<2; r++) {// ... 從內置變量計算像素坐標// 將像素值存儲在緩存中cache[y][x] = value;}}// 在所有線程都到達此點之前不要繼續workgroupBarrier();// 處理該線程圖塊的每個像素for (var c=0u; c<2; c++) {for (var r=0u; r<2; r++) {// ... 執行反應擴散算法textureStore(/* ... */);}}}
}
但我們還必須注意另一個棘手的問題:內核卷積要求我們讀取比最終處理的像素更多的像素。我們可以擴展像素緩存大小,但是workgroup線程共享的內存大小限制為 16,384 字節。因此,我們必須將每一側的dispatch大小減少 (kernelSize - 1)/2。下面的插圖可以讓這些步驟更加清晰:
UV擾動
與片段著色器解決方案相比,使用計算著色器的一個缺點是無法在計算著色器中使用采樣器來存儲紋理(只能加載整數像素坐標)。如果想通過移動紋理空間(即以小數增量擾動 UV 坐標)來對模擬進行動畫處理,則必須自己進行采樣。
解決這個問題的一種方法是使用手動雙線性采樣函數。示例中使用的采樣函數基于此處所示的采樣函數,并進行了一些調整以供在計算著色器中使用。這允許我們對浮點像素值進行采樣:
fn texture2D_bilinear(t: texture_2d<f32>, coord: vec2f, dims: vec2u) -> vec4f {let f: vec2f = fract(coord);let sample: vec2u = vec2u(coord + (0.5 - f));let tl: vec4f = textureLoad(t, clamp(sample, vec2u(1, 1), dims), 0);let tr: vec4f = textureLoad(t, clamp(sample + vec2u(1, 0), vec2u(1, 1), dims), 0);let bl: vec4f = textureLoad(t, clamp(sample + vec2u(0, 1), vec2u(1, 1), dims), 0);let br: vec4f = textureLoad(t, clamp(sample + vec2u(1, 1), vec2u(1, 1), dims), 0);let tA: vec4f = mix(tl, tr, f.x);let tB: vec4f = mix(bl, br, f.x);return mix(tA, tB, f.y);
}
這就是示例中所示的從中心開始的模擬脈動運動的創建方式。
合成渲染
反應擴散模擬完成后,唯一剩下的就是將結果繪制到屏幕上。這是合成渲染管道的工作。
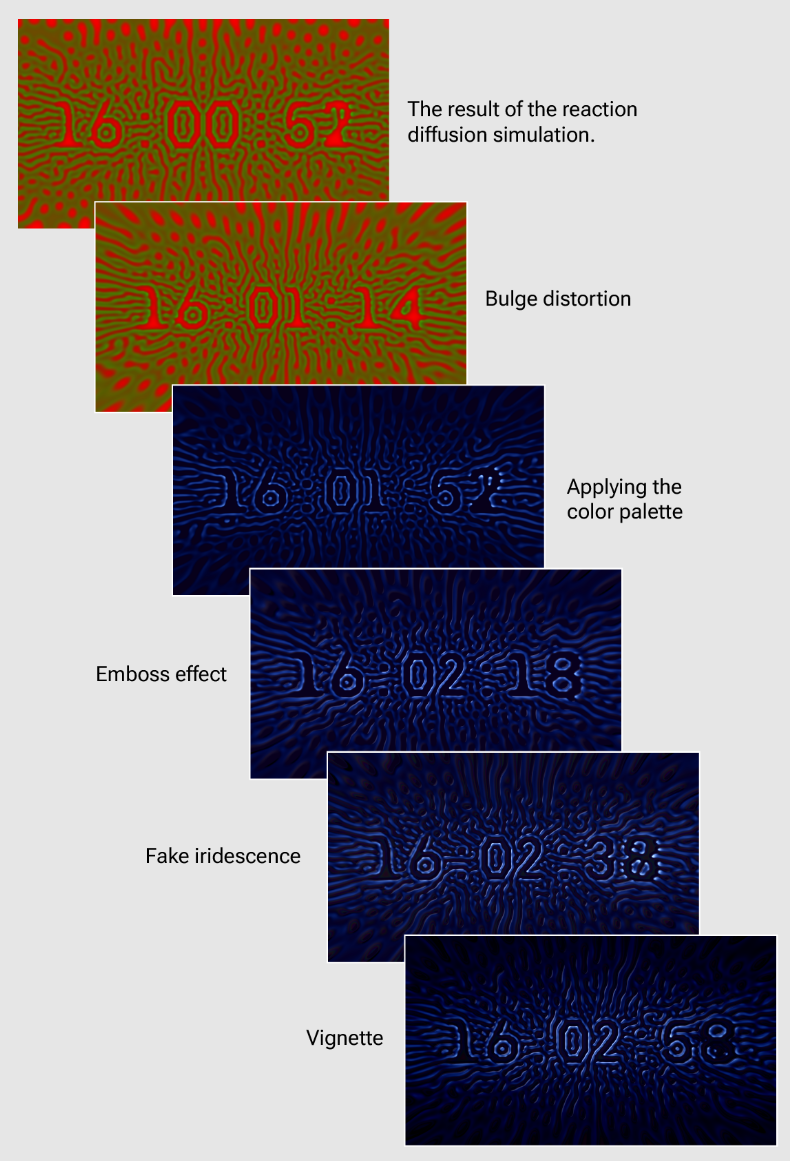
我這里簡要概述示例程序中涉及的步驟:
- 凸出變形:在對反應擴散結果紋理進行采樣之前,將凸出變形應用于 UV 坐標(基于此 Shadertoy 代碼),可以增加場景的深度感。
- 顏色:應用調色板(來自 Inigo Quilez)
- 浮雕濾鏡:簡單的浮雕效果賦予“紋理”一定的體積。
- 假彩虹色:這種微妙的效果基于不同的調色板,但應用于壓花結果的負空間。假虹彩使場景看起來更加充滿活力。
- 暈影:暈影疊加用于使邊緣變暗。



)


)

)
![P8805 [藍橋杯 2022 國 B] 機房](http://pic.xiahunao.cn/P8805 [藍橋杯 2022 國 B] 機房)

-2024年SCI新算法-公式原理詳解與性能測評 Matlab代碼免費獲取)

)





)