1、map算子
對RDD內的元素進行逐個處理,并返回一個新的RDD,可以使用lambda以及鏈式編程,簡化代碼。
?注意:再python中的lambda只能有行,如果有多行,要寫成外部函數;(T)->U表示要傳入一個函數
from pyspark import SparkConf,SparkContext
import os
# pyspark無法自動尋到python的編譯器,所以需要我們自己手動配置
os.environ['PYSPARK_PYTHON']='"D:\\softer\\anaconda\\Anacond\\python.exe"'conf =SparkConf().setMaster("local[*]").setAppName("text_spark")
sc =SparkContext(conf=conf)
rdd1=sc.parallelize(["123,123","123,123"]) # list類型
rdd2=rdd1.map(lambda x:x.split(","))
print(rdd2.collect())
sc.stop()2、FlatMap算子
整體邏輯與map相同,但多了一個嵌套解除功能
from pyspark import SparkConf,SparkContext
import os
# pyspark無法自動尋到python的編譯器,所以需要我們自己手動配置
os.environ['PYSPARK_PYTHON']='"D:\\softer\\anaconda\\Anacond\\python.exe"'conf =SparkConf().setMaster("local[*]").setAppName("text_spark")
sc =SparkContext(conf=conf)
rdd1=sc.parallelize(["123,123","123,123"]) # list類型
rdd2=rdd1.flatMap(lambda x:x.split(","))
print(rdd2.collect())
sc.stop()
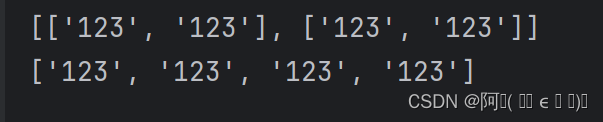
flatMap ->? ['123', '123', '123', '123']
map ->? [['123', '123'], ['123', '123']](少了一層[ ])
3、reduce算子
功能:對傳入的數據進行聚合
from pyspark import SparkConf,SparkContext
import os
# pyspark無法自動尋到python的編譯器,所以需要我們自己手動配置
os.environ['PYSPARK_PYTHON']='"D:\\softer\\anaconda\\Anacond\\python.exe"'conf =SparkConf().setMaster("local[*]").setAppName("text_spark")
sc =SparkContext(conf=conf)
rdd1=sc.parallelize([1,2,3,4,5,6,6]) # list類型
print(rdd1.reduce(lambda x,y: x+y)) # 27
sc.stop()4、reduceBykey算子
功能:傳入數據組,能進行分組,并進行邏輯運算。
from pyspark import SparkConf,SparkContext
import os
# pyspark無法自動尋到python的編譯器,所以需要我們自己手動配置
os.environ['PYSPARK_PYTHON']='"D:\\softer\\anaconda\\Anacond\\python.exe"'conf =SparkConf().setMaster("local[*]").setAppName("text_spark")
sc =SparkContext(conf=conf)
rdd1=sc.parallelize([('k1',10),("k2",20),('k1',30),("k2",40)]) # list類型
rdd2=rdd1.reduceByKey(lambda x,y: x+y)
print(rdd2.collect())
sc.stop()
#[('k1', 40), ('k2', 60)]5、filter算子
功能:過濾,保留想要的數據,結果為True就對該結果進行返回;
6、distinct算子
功能:對傳入的數據進行去重,不需要傳入參數,直接調用該方法即可
7、sortBy算子
功能:排序,可自定義排序;func:(T)->U;ascending=False(降序)/True(升序)
numPartition=>分區(可設置為1)

)

 to str)










量子物理概念(二))

—— 邏輯回歸)


