
📃博客主頁: 小鎮敲碼人
💚代碼倉庫,歡迎訪問
🚀 歡迎關注:👍點贊 👂🏽留言 😍收藏
🌏 任爾江湖滿血骨,我自踏雪尋梅香。 萬千浮云遮碧月,獨傲天下百堅強。 男兒應有龍騰志,蓋世一意轉洪荒。 莫使此生無痕度,終歸人間一捧黃。🍎🍎🍎
?? 什么?你問我答案,少年你看,下一個十年又來了 💞 💞 💞

【ZZULI數據結構實驗】壓縮與解碼的鑰匙:赫夫曼編碼應用
- 🏆 實驗目的和要求
- 🏆 實驗前的準備工作
- 🔑 確定漢字編碼
- 🔑 在文件中實現漢字的讀和寫
- 🍸 知道漢字的高位和低位在屏幕上打印漢字
- 👘 字符串形式(%s)打印
- 👘 字符形式(%c)打印
- 🍸 在文件中寫入漢字(以GBK編碼的形式)
- 🍸 在文件中讀入中文,并以GBK編碼的形式來輸出
- 🏆 赫夫曼樹的結構設計
- 🔑 知識點介紹
- 🔑 結構設計
- 🏆 赫夫曼樹函數的具體實現
- 🔑 List_Init(鏈表初始化)和 Node_Init(節點初始化)
- 🔑 鏈表的銷毀和赫夫曼樹的銷毀
- 🔑 鏈表的插入
- 🔑 buildHuffmanTree(構造赫夫曼樹)
- 🔑 assignCodes(編碼)
- 🍸 strdup函數介紹
- 🍸 編碼函數實現
- 🔑 打印字符出現的頻次
- 🔑 打印字符的編碼
- 🏆 最終效果演示
- 🔑 菜單及調用函數實現
- 🔑 效果展示
前言:上篇博客,博主分享了多項式的運算實驗,今天我們繼續來看實驗二——赫夫曼編碼及應用。相關代碼在博主的代碼倉庫自行查看。
🏆 實驗目的和要求

🏆 實驗前的準備工作
🔑 確定漢字編碼
我們這次實驗采用GBK編碼來編碼漢字,該編碼標準兼容GB2312(ANSI),由兩個字節來編碼確定一個漢字,而且高位和低位為了和英文字符做區分,都是大于128的。我們可以看一下編碼表。
- 也可以使用UTF-8編碼,但是該編碼會出現3個乃至4個字節編碼一個漢字的情況,控制起來太復雜,所以我們不采用這個。
🔑 在文件中實現漢字的讀和寫
在學習如何在漢字中編碼前,我們先來學習一下如何在屏幕上(標準輸出流stdout)上打印一個用GBK編碼的漢字。
🍸 知道漢字的高位和低位在屏幕上打印漢字
👘 字符串形式(%s)打印
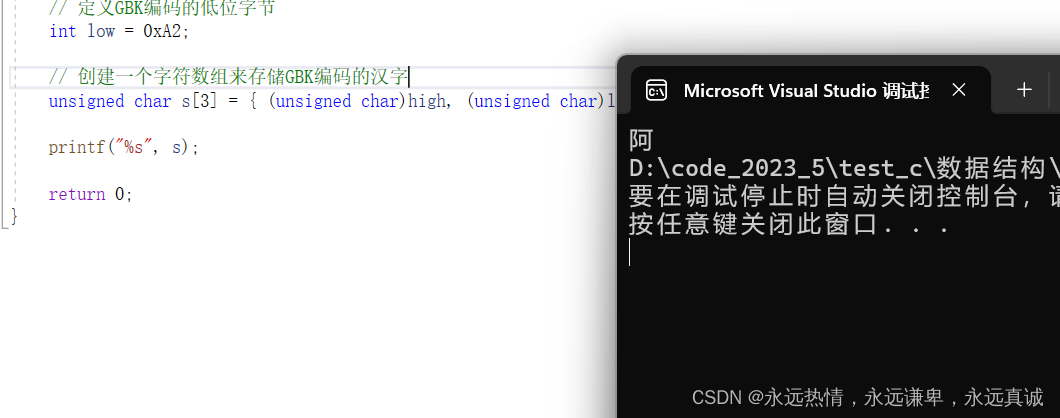
我們通過查閱資料,知道了中文阿的高位和低位是0xB0、0xA2。
#include <stdio.h> int main()
{// 定義GBK編碼的高位字節 int high = 0xB0;// 定義GBK編碼的低位字節 int low = 0xA2;// 創建一個字符數組來存儲GBK編碼的漢字unsigned char s[3] = { (unsigned char)high, (unsigned char)low, '\0' };printf("%s", s);return 0;
}
運行結果:
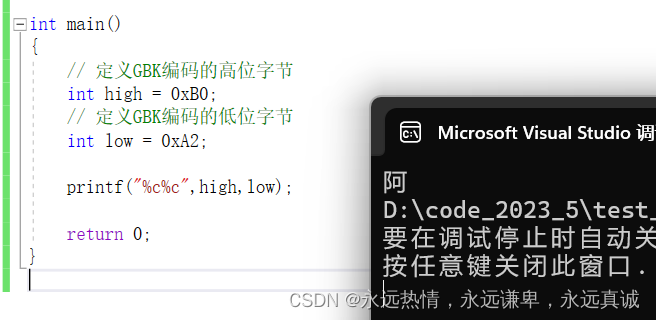
👘 字符形式(%c)打印
#include <stdio.h> int main()
{// 定義GBK編碼的高位字節 int high = 0xB0;// 定義GBK編碼的低位字節 int low = 0xA2;printf("%c%c",high,low);return 0;
}
運行結果:
- 這里高位字節和低位字節用大小為1字節的類型也是可以的,但是要注意,應該使用
unsigned char無符號類型,這樣就不會出現負數的情況(GBK編碼高位和低位第一位都為1),便于我們的判斷。的如果4字節的會發生截斷。
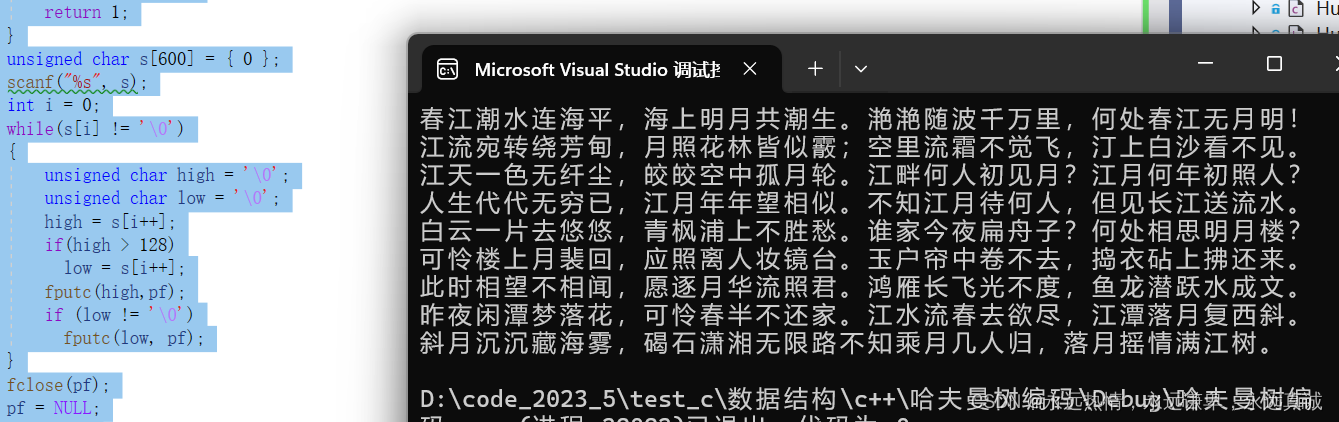
🍸 在文件中寫入漢字(以GBK編碼的形式)
#include <stdio.h> // 引入標準輸入輸出庫,用于文件操作和輸入/輸出函數 int main() // 主函數入口
{ // 聲明一個文件指針pf,并嘗試以寫入("w")模式打開名為"詩.txt"的文件 FILE* pf = fopen("詩.txt", "w"); // 檢查文件是否成功打開 if (NULL == pf) { // 如果文件打開失敗,則輸出錯誤信息(來自perror函數) perror("fopen"); // 并返回錯誤代碼1 return 1; } // 定義一個無符號字符數組s,用于存儲用戶輸入的字符串,并初始化為全0 unsigned char s[600] = { 0 }; // 使用scanf函數從標準輸入(通常是鍵盤)讀取一個字符串,并存儲在s中 // 注意:這里使用%s可能會引發緩沖區溢出問題,因為scanf不會檢查目標數組的大小 // 更好的做法是使用fgets函數或者限制scanf讀取的字符數 scanf("%s", s); // 初始化一個循環計數器i,用于遍歷字符串s int i = 0; // 循環遍歷字符串s,直到遇到字符串結束符'\0' while(s[i] != '\0') { // 聲明兩個無符號字符變量high和low,用于存儲GBK編碼的漢字的高位和低位字節 // 假設字符串s中包含GBK編碼的漢字,但實際上這種假設可能不正確 unsigned char high = '\0'; unsigned char low = '\0'; // 將s中的當前字符賦值給high high = s[i++]; // 如果high的值大于128(通常表示這是一個非ASCII字符),則假設它是GBK編碼的漢字的高位字節 if(high > 128) { // 嘗試將s中的下一個字符賦值給low(假設它是GBK編碼的漢字的低位字節) low = s[i++]; } // 將high寫入文件 fputc(high, pf); // 如果low不為'\0'(即存在低位字節),則將其寫入文件 if (low != '\0') fputc(low, pf); } // 關閉文件 fclose(pf); // 將文件指針設置為NULL,避免野指針 pf = NULL; // 程序正常結束,返回0 return 0;
}
這是我們寫入的內容:
看看文件中是否生成了對應內容:
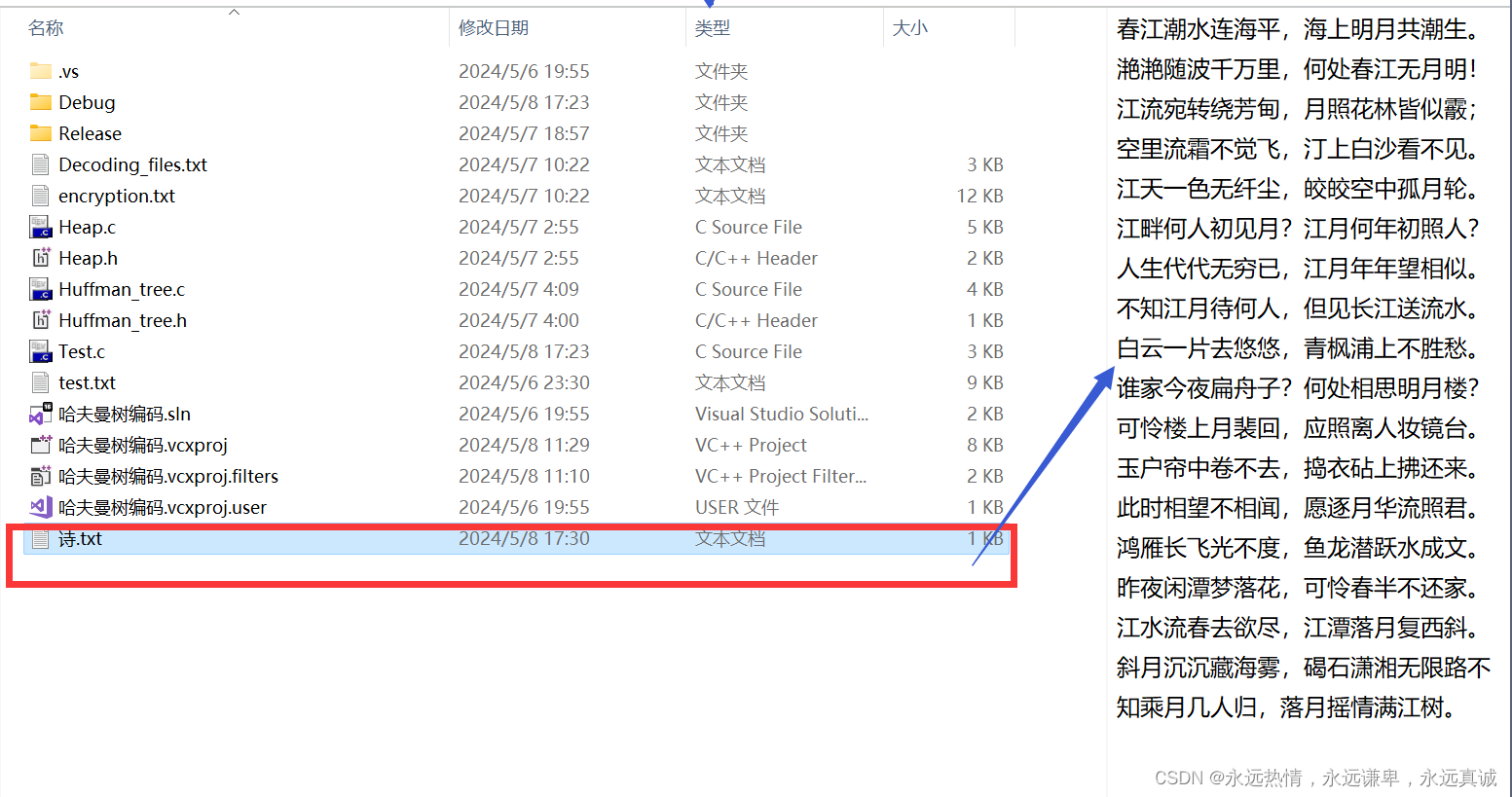
從右邊的預覽我們可以看見確實寫入了對應的內容,有小伙伴可以會好奇,為什么換行了呢?我們剛剛我們明明沒有換行呀,其實你如果點進這個文件會發現,其實并沒有換行,只是預覽這樣可能更方便我們閱讀:

🍸 在文件中讀入中文,并以GBK編碼的形式來輸出
首先我們需要新建一個文件寫入內容后,另存選擇編碼為GBK或者是它兼容的,因為程序編碼格式和文件的編碼格式必須保持一致。
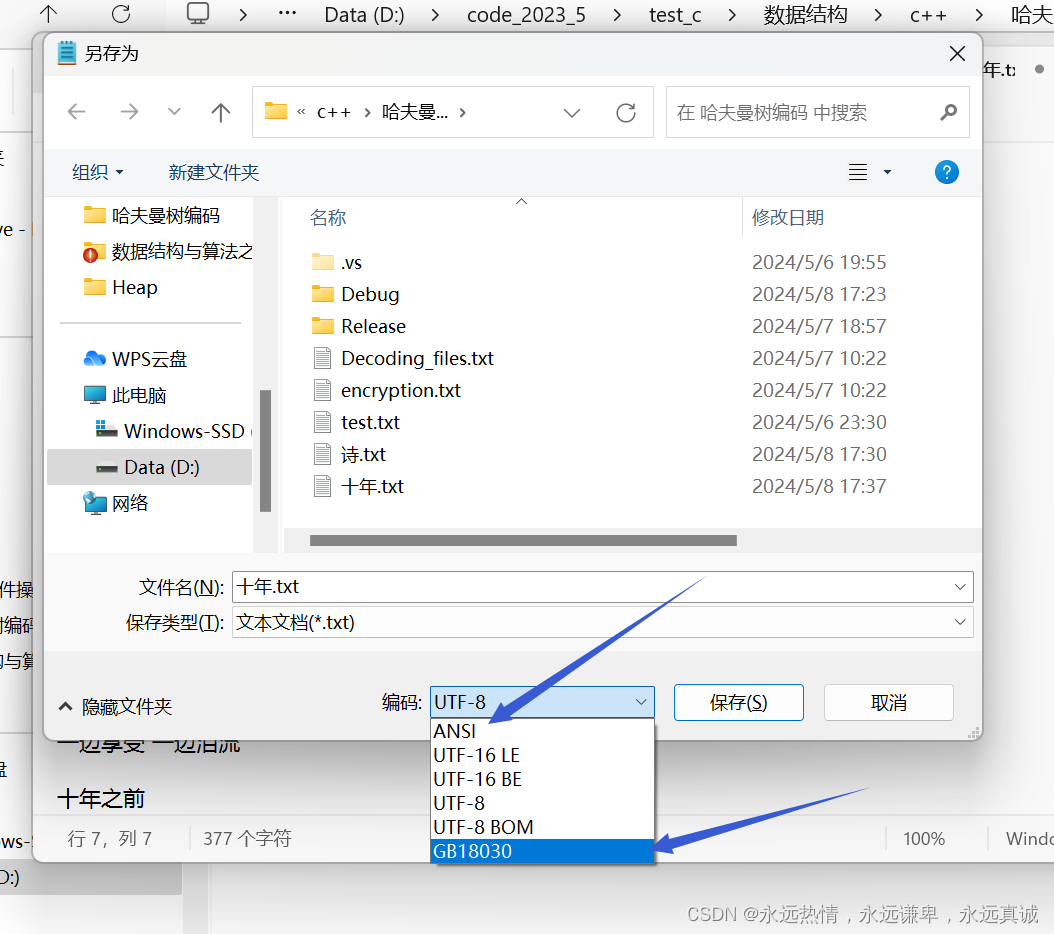
選擇GB類型的編碼或者ANSI都是,因為ANSI也是GB類型的一種,GBK都是兼容的他們的。這里我們選擇ANSI編碼。
文件中的內容如下:
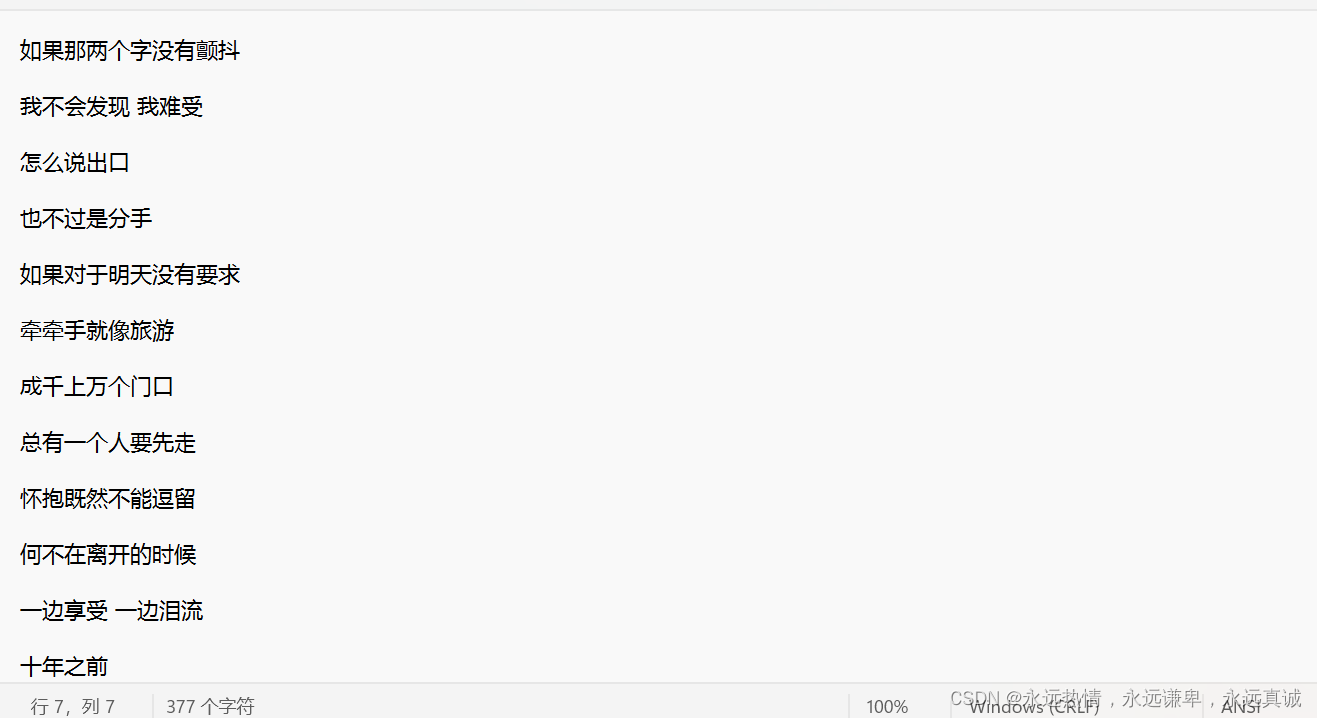
下面我們用代碼來以GBK的形式讀一下文件中的內容并輸出到屏幕上。
#include <stdio.h> // 引入標準輸入輸出庫 int main()
{ // 聲明一個文件指針pf,并嘗試以只讀("r")模式打開名為"十年.txt"的文件 FILE* pf = fopen("十年.txt", "r"); // 檢查文件是否成功打開 if (NULL == pf) { // 如果文件打開失敗,則輸出錯誤信息 perror("fopen"); // 并返回錯誤代碼1 return 1; } // 初始化兩個變量high和low,high用于存儲從文件中讀取的字符,low用于存儲漢字的低字節(如果存在) int high = 0, low = '\0'; // 使用while循環從文件中逐個字符地讀取,直到遇到文件結束符EOF while ((high = fgetc(pf)) != EOF) { // 如果讀取到的字符(存在于high中)大于128(假設是GBK或其他多字節編碼的漢字的高字節) if (high > 128) { // 讀取下一個字符作為漢字的低字節(如果存在) low = fgetc(pf); // 輸出高字節和低字節,但由于low可能不是漢字的低字節(例如遇到非漢字字符), // 直接輸出可能會導致亂碼或不正確的輸出。 printf("%c%c", high, low); } else { // 如果不是漢字的高字節,則只輸出該字符 printf("%c", high); } } // 關閉文件 fclose(pf); // 將文件指針設置為NULL,避免野指針 pf = NULL; // 程序正常結束,返回0 return 0;
}
運行結果:

這里還是用int來保存低位和高位較好,因為既要與128作比較來區分因為字符和中文字符,不能讓系統把首位的1當作負號位,又要做判斷文件結束的判斷,因為EOF是-1,無符號數沒有負數,所以如果使用無符號數,程序會陷入死循環。
所以接下來的實驗中我們會以int類型保存字符的高位和低位。最終系統會發生截斷的,所以我們不用擔心int和char不匹配的問題。
🏆 赫夫曼樹的結構設計
🔑 知識點介紹
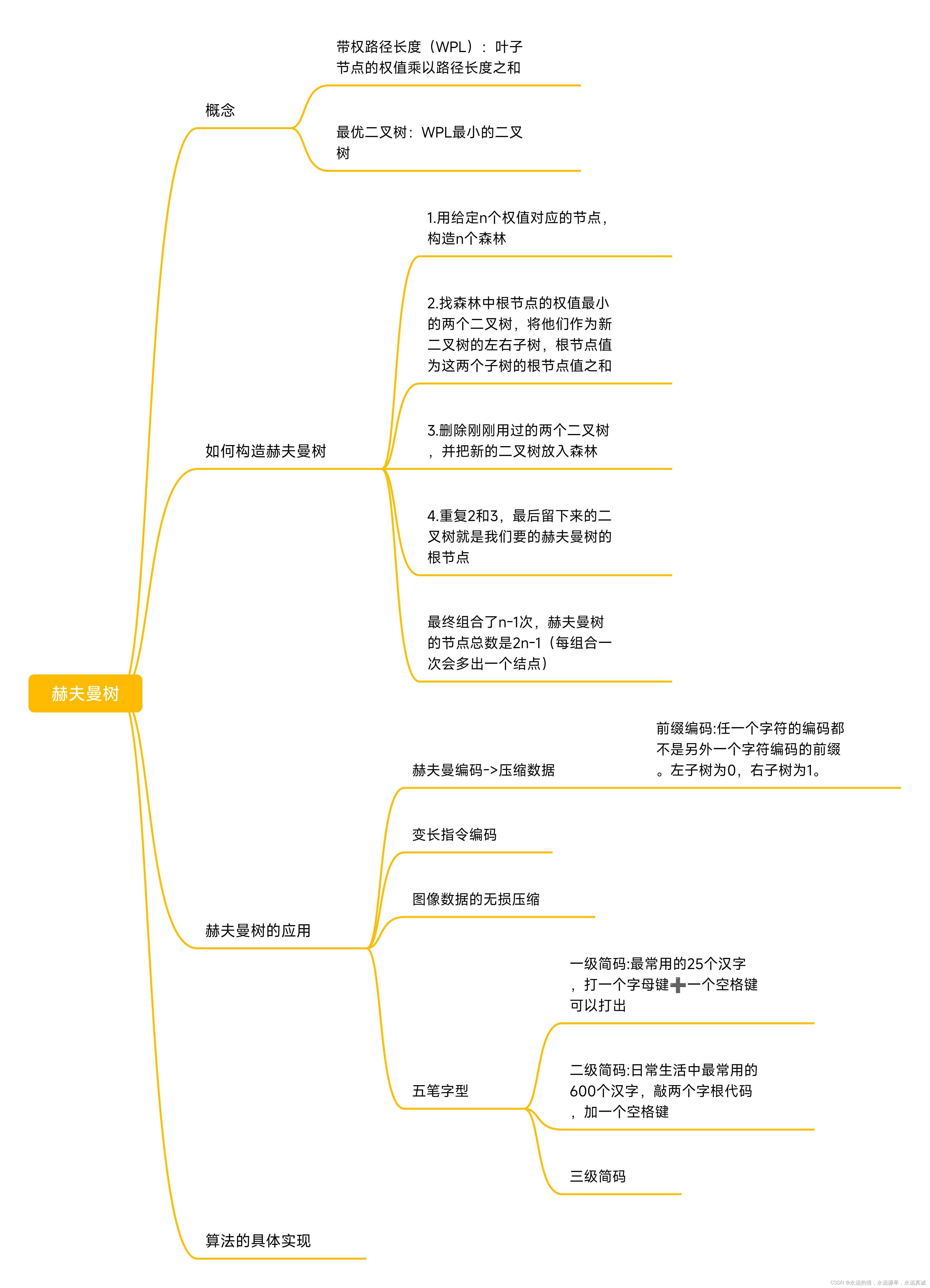
🔑 結構設計
赫夫曼樹是一種特殊的二叉樹,WPL最小的二叉樹,所以赫夫曼樹又叫最優二叉樹。
首先就是哈夫曼樹的節點類型,我們需要在這個類型里面放5個數據,節點的左孩子、右孩子、還有這個節點保存的字符即它的低位和高位,還有這個字符的字符串編碼(char*類型,動態開辟內存按需申請)。
typedef struct HuffmanNode* NodeP;
typedef struct HuffmanNode {unsigned int freq;//出現的頻率NodeP left, right;//節點的左孩子和右孩子int low;//低位int high;//高位char* code; // 編碼,在構造樹后分配
}Node;
然后我們還需要一個線性表的結構,這個線性表用來保存每種字符的頻率,可以使用鏈表或者線性表,這里我們使用的是鏈表。因為鏈表無需我們考慮申請空間的問題,省事很多。
typedef struct HuffmanList* ListP;//創建一個雙向循環鏈表,存儲節點的頻度
typedef struct HuffmanList{NodeP data;//哈夫曼樹節點ListP next;
}List;
這里我們把鏈表指針和樹的節點指針類型取了一下別名,因為后面要多次使用,這樣做可以少寫一個*,指針的英文是Pointer,所以我們后面加了P代表這個是指針類型。
函數接口:
void List_insert(ListP Head,ListP newnode);//插入新的節點ListP List_Init(NodeP data);//初始化鏈表void Print_freq(ListP Head);//打印各個詞出現的頻率void Destroy_List(ListP newnode);//銷毀鏈表NodeP Node_Init(int freq, int low, int high);//節點初始化NodeP buildHuffmanTree(ListP* Head);//構造哈夫曼樹void assignCodes(NodeP root, char* code);//編碼void decode(NodeP root, FILE* encodedFile, FILE* decodedFile);//解碼void dfs(NodeP root);//前序遍歷,打印節點和其對應的編碼
🏆 赫夫曼樹函數的具體實現
🔑 List_Init(鏈表初始化)和 Node_Init(節點初始化)
過于簡單不過多敘述。
ListP List_Init(NodeP data)//鏈表節點初始化
{ListP newL = (ListP)malloc(sizeof(List));//為鏈表節點申請空間if (NULL == newL){printf("malloc Failed\n");exit(-1);}//初始化newL->data = data;//初始化數據節點newL->next = NULL;//初始化next為空
}NodeP Node_Init(int freq, int low, int high)//赫夫曼樹節點初始化
{NodeP NewN = (NodeP)malloc(sizeof(Node));//為赫夫曼樹節點申請空間if (NULL == NewN){printf("malloc Failed\n");exit(-1);}//初始化NewN->freq = freq;NewN->high = high;NewN->low = low;NewN->left = NULL;NewN->right = NULL;NewN->code = NULL;
}
🔑 鏈表的銷毀和赫夫曼樹的銷毀
- 注意:雖然鏈表里面存的有赫夫曼樹的節點指針,但是節點的內存并不是和鏈表節點一起申請的,鏈表節點只是有一個4字節的變量也指向那片空間而以,而且鏈表里有的節點在赫夫曼樹中肯定是存在的,節點的內存在赫夫曼樹中走一個后序就可以釋放,但是如果你在鏈表中就釋放了,在釋放赫夫曼樹的時候,釋放葉子節點時還需要特判一下,因為葉子節點已經釋放過了(重復釋放程序會崩潰),而且非法訪問也會出問題,所以我們統一走后序在樹中釋放節點的內存。
void Destroy_List(ListP Head)
{assert(Head);//斷言,頭節點不能為空ListP Cur = Head;while (Cur != NULL){ListP next = Cur->next;free(Cur);Cur = next;}
}void Destroy_HuffmanTree(NodeP root)//銷毀赫夫曼樹
{if (root == NULL)return;Destroy_HuffmanTree(root->left);//先去釋放根節點的左樹Destroy_HuffmanTree(root->right);//再去釋放根節點的右樹free(root);//最后釋放根節點
}
🔑 鏈表的插入
鏈表的插入就是用來統計每個字符出現的頻次的,具體邏輯是這樣的,我們在外面的函數只需要傳入字符的高位和低位即可,如果high和low已經出現了,就沒有構造鏈表節點和赫夫曼樹節點的必要,如果沒有出現,外面就需要依次構造赫夫曼樹節點和鏈表節點頭插進鏈表中。
void List_insert(ListP Head,int high,int low)//插入節點
{ListP cur = Head->next;//循環遍歷,看是否該字符已經存在while (cur != NULL){if (cur->data->high == high && cur->data->low == low){cur->data->freq++;break;}cur = cur->next;}if (cur == NULL)//沒有找到,或者鏈表為空(只有一個頭節點){//構造新節點NodeP newHnode = Node_Init(1,low, high);ListP newLnode = List_Init(newHnode);//頭插進鏈表中newLnode->next = Head->next;//先把Head后面的節點和新節點鏈接Head->next = newLnode;//在把頭節點的next更新}
}
🔑 buildHuffmanTree(構造赫夫曼樹)
統計完文件中每個字符的頻次,我們得到對應的樹節點,也可以將它們視作森林。因為此時它們還沒有鏈接起來,因為每次我們需要依次取兩個頻次最小的節點,所以我們可以使用小堆(按照頻次來調整)這種數據結構,一共有N個節點,每次調整只需要logN,調整N次,時間復雜度的量級在O(N * logN),我們來看排序一次排序是NlogN,有N次,大概在O(N logN* N)的量級。如果你直接找兩個最小的,比排序還快一點N*N量級。如何構造我們不再詳細贅述,在之前的思維導圖中已經敘述過了。如果你對堆這種數據結構不太了解,可以看一下博主這篇博客。
NodeP buildHuffmanTree(ListP Head)//構造哈夫曼樹
{// 初始化最小堆,并將所有葉子節點加入堆中 Heap hp;HeapInit(&hp);ListP cur = Head->next;while (cur != Head){HeapPush(&hp, cur->data);cur = cur->next;}//開始構造赫夫曼樹while (HeapSize(&hp) > 1) {NodeP left = HeapTop(&hp);HeapPop(&hp);NodeP right = HeapTop(&hp);HeapPop(&hp);NodeP top = (NodeP)malloc(sizeof(Node));top->freq = left->freq + right->freq;top->left = left;top->right = right;top->high = -1;top->low = -1;top->code = NULL;// 暫時不分配編碼 HeapPush(&hp, top);//把新節點插入到堆中}// 堆中只剩一個節點,即根節點 NodeP root = HeapTop(&hp);HeapDestory(&hp);return root;
}
🔑 assignCodes(編碼)
編碼就是為葉子節點的code寫入相應的字符編碼,左孩子寫字符0,右孩子寫字符1,這是前綴編碼模式,可以保證我們的每個葉子節點的編碼都是唯一的,不存在二義性。我們先來隆重介紹一下一個非常棒的字符串函數strdup,如果你會使用這個函數,那簡直是太酷了!
🍸 strdup函數介紹
這個函數主要做兩件事,第一件事是拷貝字符串,第二件事是為這個字符串重新申請一片空間(在堆上),所以這個函數相當于是strcpy和malloc函數的結合,它拷貝的結束條件是\0,并且這個函數會給\0開一個空間。它會返回新開空間的起始地址。
- 如果我們給普通的字符指針的
\0位置賦值,是會報錯的:
#include<stdio.h>
int main()
{char* s = "11";s[2] = '\0';return 0;
}
運行結果:
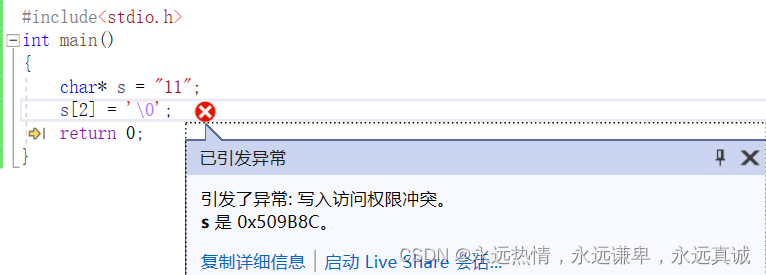
說我們非法訪問了,但是字符串的結束標志不就是\0嗎,如果你不把那一個字節的空間給我,該如何處理呢?這里我們先理解為是字符指針,系統會給它開這個空間但是不允許我們訪問,這也算是一種保護機制,因為字符串是以\0來判斷結束的,如果你隨意更改,就會打印亂碼。
- 如果我們把這個相同的字符串給
_strdup函數,執行同樣的操作,系統不會報錯但是打印出來會亂碼。
#include<stdio.h>int main()
{char* s = _strdup("11");s[2] = '2';printf("%s", s);return 0;
}
運行結果:

這是因為我們把原先的\0給修改了,這個函數變相的給了我們控制字符指針\0的權利,有好處也有壞處。
- 將
strcat和strdup函數結合,恢復字符串特性(以\0)結尾。
因為strcat函數會把源字符串的\0也拷貝進去,如果你不懂字符串拼接函數strcat,可以看一下博主這篇博客,這里正常應該會報錯因為那個字節的空間,并不是我們的。我們暫且認為這里是特殊處理,但是博主發現這個函數還是存在很大的不確定性,所以實際項目里面還是老老實實的使用malloc和循環去計算字符串長度。
#include<stdio.h>
int main()
{char* s = _strdup("11");strcat(s, "1");printf("%s", s);return 0;
}
運行結果:

不再出現亂碼。
🍸 編碼函數實現
void assignCodes(NodeP root, char* code)//編碼
{if (root == NULL) return;if (root->left == NULL && root->right == NULL) {// 葉子節點,分配編碼 root->code = _strdup(code);}else {// 遞歸為左樹和右樹上的葉子節點分配編碼assignCodes(root->left, strcat(_strdup(code),"0"));assignCodes(root->right, strcat(_strdup(code),"1"));}
}
🔑 打印字符出現的頻次
// 打印各個詞及其出現頻度的函數
// 參數:
// ListP Head - 指向鏈表頭部的指針,鏈表中的每個節點存儲了一個詞及其相關信息 void Print_freq(ListP Head) // 打印各個詞出現的頻度
{assert(Head);//Head不能為空// cur 是一個臨時指針,用于遍歷鏈表 ListP cur = Head->next; // 從鏈表的第一個有效節點開始遍歷(假設Head是頭節點,不存儲數據) // 當cur不為空時,說明還有節點未遍歷 while (cur != NULL){// 檢查當前節點的數據(詞)是否有'low'屬性(可能是指多字符的詞或某種特殊標識) if (cur->data->low == -1){// 如果'low'為-1,說明只有一個字符(可能是單字符詞或特殊標識),直接打印該字符和它的頻度 char c = cur->data->high;if (c == '\n' || c == '\r')printf("\\n\\r: %d次\n", cur->data->freq);elseprintf("%c: %d次\n", cur->data->high, cur->data->freq);}else{// 如果'low'不為-1,說明是多字符的詞,打印兩個字符(或特殊標識)和它的頻度 printf("%c%c: %d次\n", cur->data->high, cur->data->low, cur->data->freq);}// 移動到下一個節點 cur = cur->next;}
}
🔑 打印字符的編碼
// 深度優先搜索函數,用于遍歷樹結構
// 參數:
// NodeP root - 指向樹節點的指針,該節點是遍歷的起始點
void dfs(NodeP root)
{// 如果當前節點為空(到達葉子節點的下一層或根節點之前就是空的),則直接返回 if (!root)return;// 如果當前節點是葉子節點(即沒有左孩子和右孩子) if (root->left == NULL && root->right == NULL){// 檢查節點是否有'low'屬性(可能是某種輔助信息或鍵值) if (root->low == -1){// 如果'low'為-1,說明只有一個字符(可能是單字符詞或特殊標識),直接打印該字符和它的頻度 char c = root->high;if (c == '\n' || c == '\r')//換行符特殊處理printf("\\n\\r: %s\n",root->code);elseprintf("%c: %s\n", root->high, root->code);}// 如果'low'不是-1(即存在'low'屬性),則按照指定格式打印 elseprintf("%c%c: %s\n", root->high, root->low, root->code);}// 遞歸遍歷左子樹 dfs(root->left);// 遞歸遍歷右子樹 dfs(root->right);
}
🏆 最終效果演示
🔑 菜單及調用函數實現
#define _CRT_SECURE_NO_WARNINGS 1
#include"Huffman_tree.h"char file[200] = { 0 };//存儲原始文件路徑
ListP Head = NULL;//鏈表頭指針
NodeP root = NULL;//赫夫曼樹的根節點指針void Test1()//完成統計字符頻次的事情
{FILE* pf = fopen(file, "r");//打開原始文件if (NULL == pf)//如果打開失敗{perror("fopen");return 1;}int high = 0;int low = -1;Head = List_Init(NULL);//帶頭單鏈表,創建它的頭while ((high = fgetc(pf)) != EOF)//開始讀取文件的內容{if (high > 128)//如果是中文字符low = fgetc(pf);List_insert(Head,high,low);low = -1;//注意要及時置為-1,因為有時候不是中文字符}
}void Test2()//完成打印字符頻次表的工作
{assert(Head != NULL);//Head不能為空Print_freq(Head);
}void Test3()//完成構建赫夫曼樹,并打印每個字符對應的01編碼的工作
{assert(Head != NULL);//Head不能為空root = buildHuffmanTree(Head);assignCodes(root, "");//編碼dfs(root);//遍歷打印
}void Test4()//完成寫入加密文件并打印加密文件的路徑的工作
{assert(Head != NULL);//Head不能為空assert(root != NULL);//root不能為空,保證已經加密過了FILE* pf = fopen(file, "r");//打開原始文件if (NULL == pf){perror("fopen");return 1;}FILE* pfw = fopen("encryption.txt", "w");//創建加密文件,相對路徑if (NULL == pfw){perror("fopen");return 1;}int high = -1, low = -1;while ((high = fgetc(pf)) != EOF)//讀取文件字符{if (high > 128)//判斷中文字符{low = fgetc(pf);}ListP cur = NULL;cur = Head->next;while (cur != NULL)//依次在表中找對應的字符并寫入它的編碼{if (cur->data->high == high && cur->data->low == low){fputs(cur->data->code, pfw);break;}cur = cur->next;}low = -1;//防止中文字符對英文字符產生干擾}printf("加密文件的路徑為:D:\\code_2023_5\\test_c\\數據結構\\c++\\哈夫曼樹編碼\\encryption.txt\n");//打印加密文件路徑,這個是自己事先就確定的//關閉對應的文件fclose(pfw);fclose(pf);pfw = NULL;pf = NULL;
}void Test5()//完成解密的工作,并打印解密的路徑
{assert(root != NULL);//root不為空FILE* pfw = fopen("encryption.txt", "r");//打開加密的文件if (NULL == pfw){perror("fopen");return 1;}FILE* pfD = fopen("Decoding_files.txt", "w");//創建解密文件if (NULL == pfD){perror("fopen");return 1;}decode(root, pfw, pfD);//調用解密函數printf("解密文件的路徑為:D:\\code_2023_5\\test_c\\數據結構\\c++\\哈夫曼樹編碼\\encryption.txt\n");//打印解密文件的絕對路徑//關閉文件fclose(pfw);fclose(pfD);pfw = NULL;pfD = NULL;
}void Test6()//完成清理資源的操作
{Destroy_HuffmanTree(root);//清理赫夫曼樹中的資源root = NULL;Destroy_List(Head);//清理鏈表中的資源Head = NULL;printf("清理資源成功<>\n");
}
void menu()//菜單函數
{int instructions = 0;printf("請輸入指令以執行操作<>\n: ");printf("***********************************************************************************************************\n");printf("****************************1.輸入要加密的文件路徑(絕對路徑和相對路徑均可)*******************************\n");printf("****************************2.打印字符頻次表***************************************************************\n");printf("****************************3.打印字符編碼*****************************************************************\n");printf("****************************4.輸出加密01文件路徑***********************************************************\n");printf("****************************5.輸出解碼文件路徑*************************************************************\n");printf("****************************6.清理相關資源*****************************************************************\n");printf("****************************7.刷新屏幕*********************************************************************\n"); printf("****************************8.結束程序*********************************************************************\n");scanf("%d", &instructions);switch(instructions){case 1: { printf("請輸入要加密的文件路徑<>:\n"); scanf("%199s", file); Test1(); }break;case 2: Test2();break;case 3: Test3();break;case 4: Test4();break;case 5: Test5();break;case 6: Test6();break;case 7: system("cls");break;case 8: exit(0);break;default: printf("指令不合法,重新輸入\n");break;}
}int main()
{while (1)//循環打印菜單{menu();}return 0;
}
🔑 效果展示
- 代碼運行結果:
詞頻及字符串編碼打印:

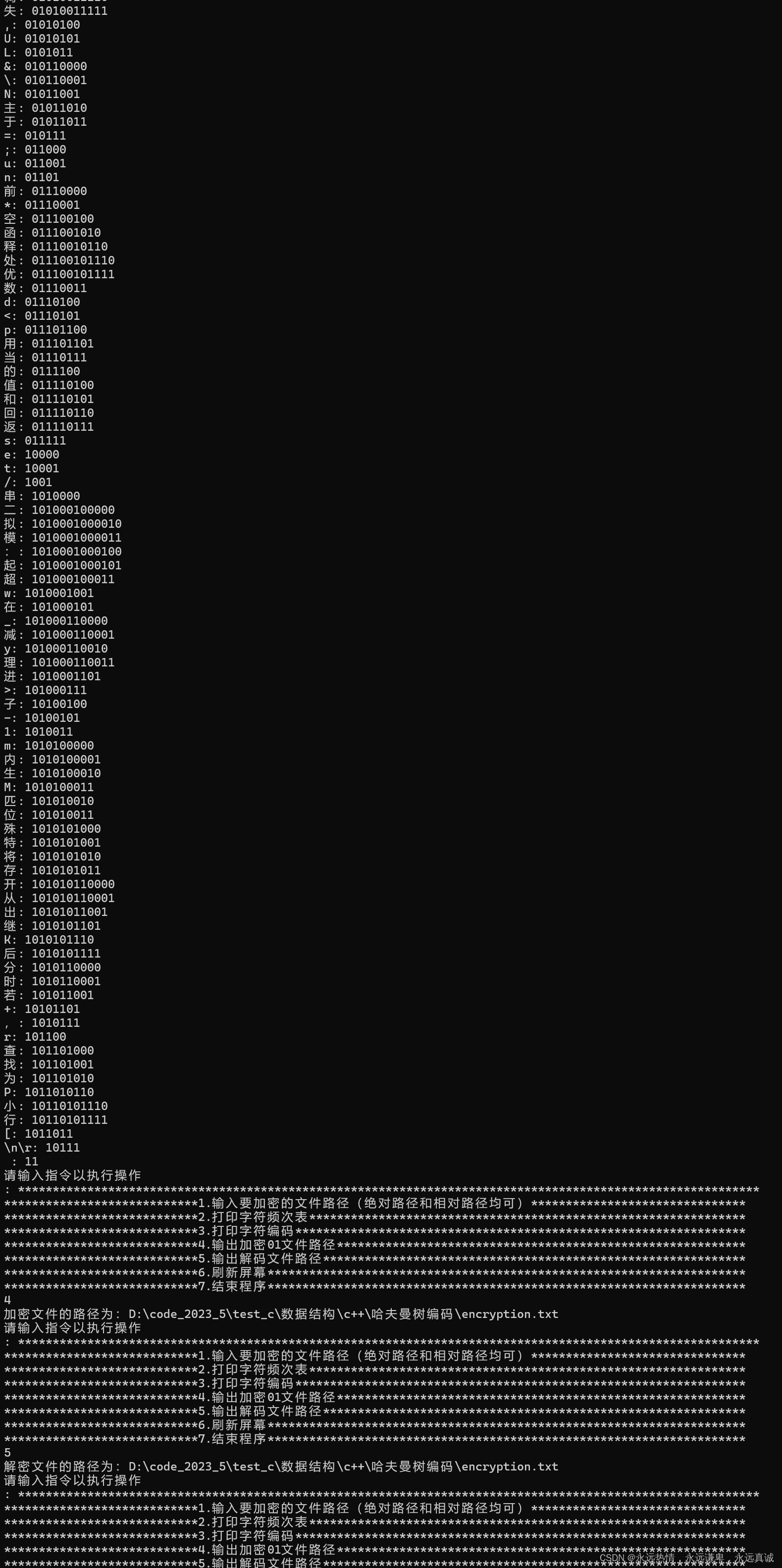
- 加密01字符串文件
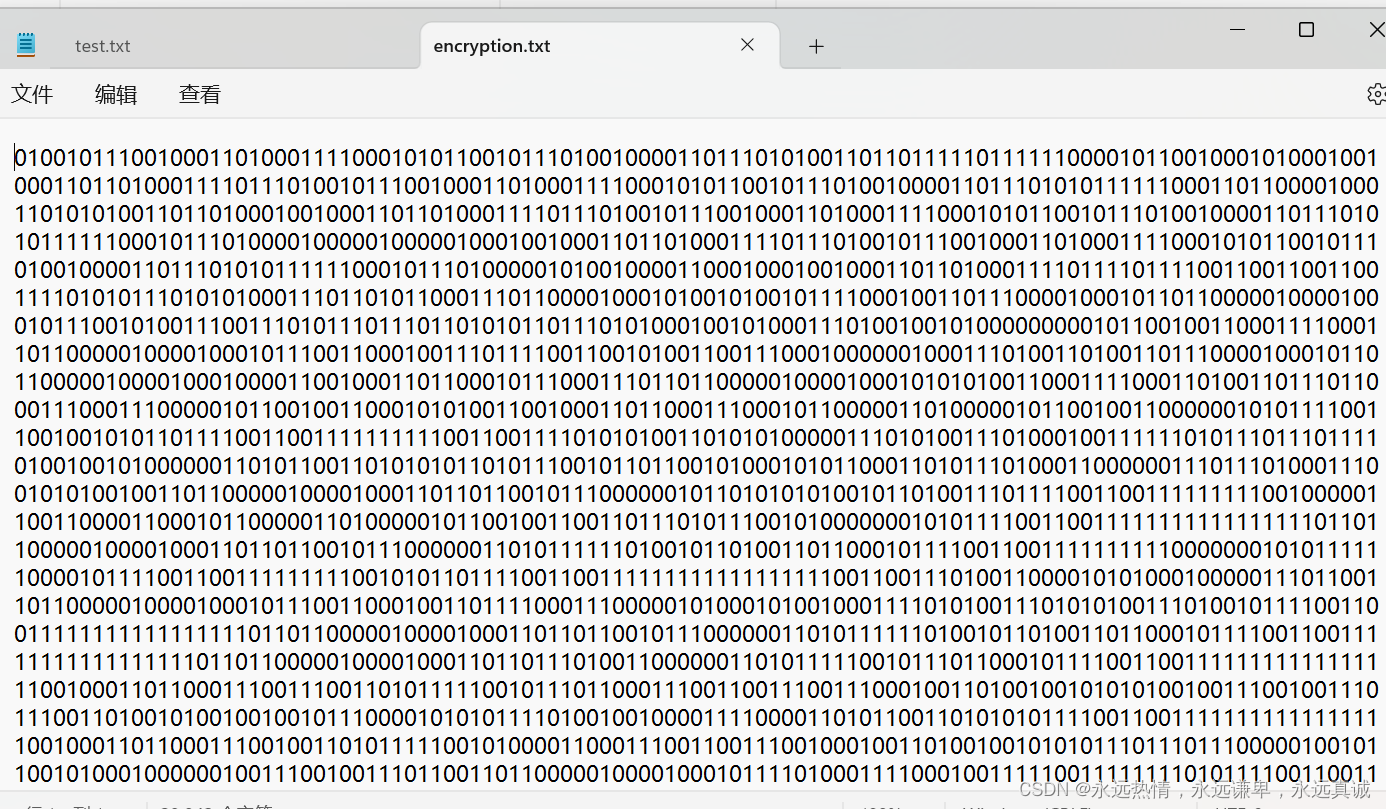
3. 解密文件與原文件對比結果。




】多線程代碼案例)














