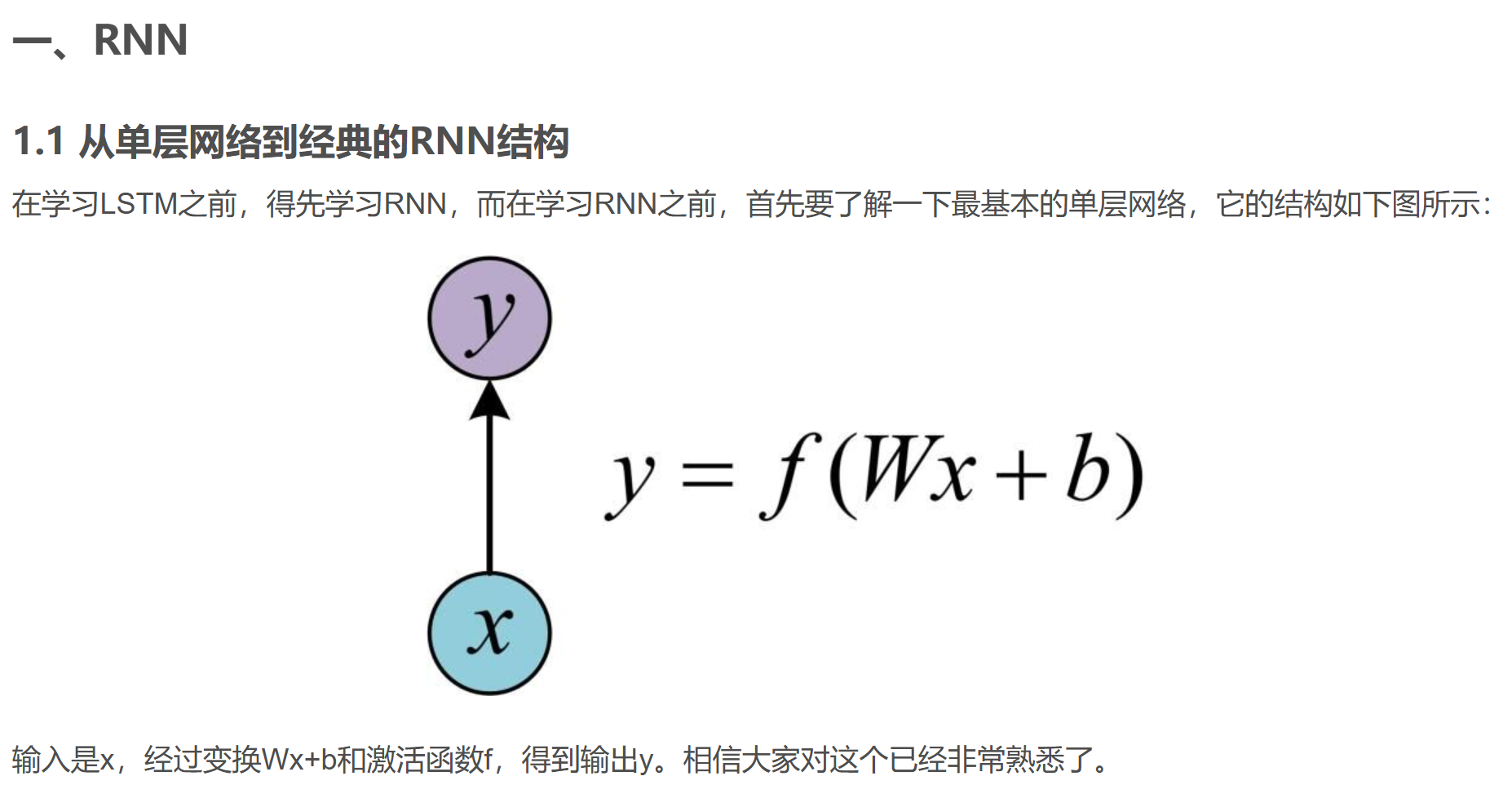


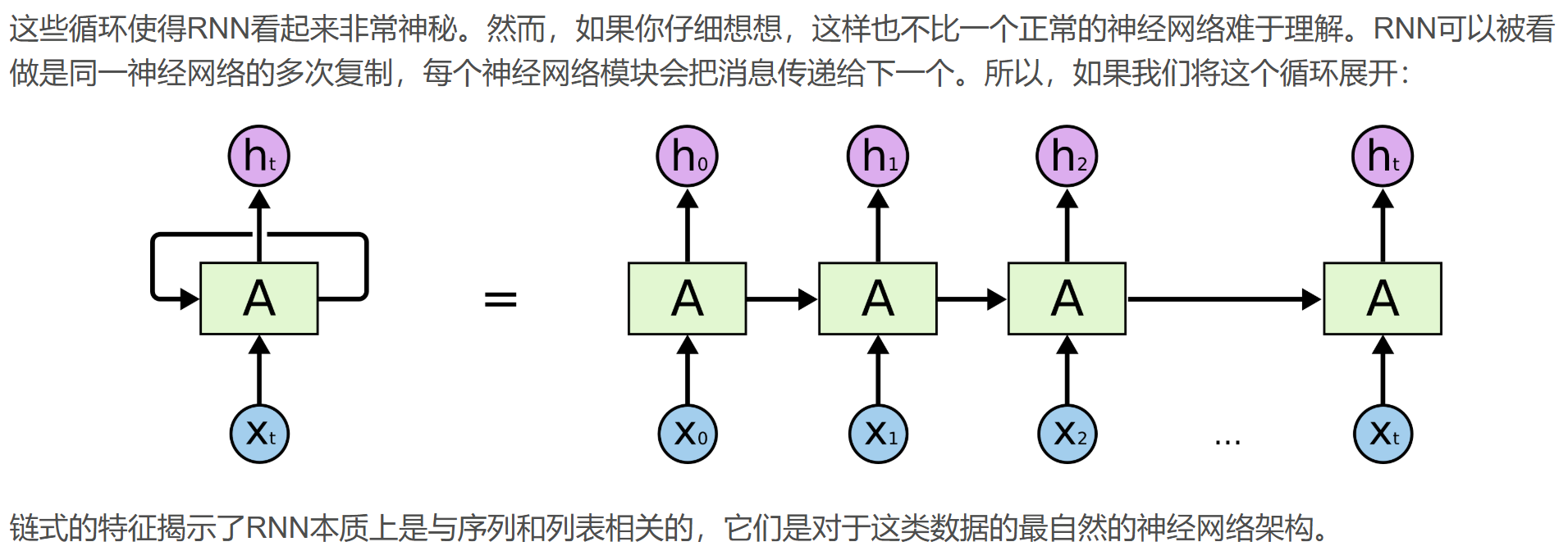
RNN的局限1:長期依賴(Long-TermDependencies)問題
但是同樣會有一些更加復雜的場景。比如我們試著去預測“I grew up in France...I speak fluent French”最后的詞“French”。當前的信息建議下一個詞可能是一種語言的名字,但是如果我們需要弄清楚是什么語言,我們是需要先前提到的離當前位置很遠的“France”的上下文。這說明相關信息和當前預測位置之間的間隔就肯定變得相當的大。
不幸的是,在這個間隔不斷增大時,RNN會喪失學習到連接如此遠的信息的能力。
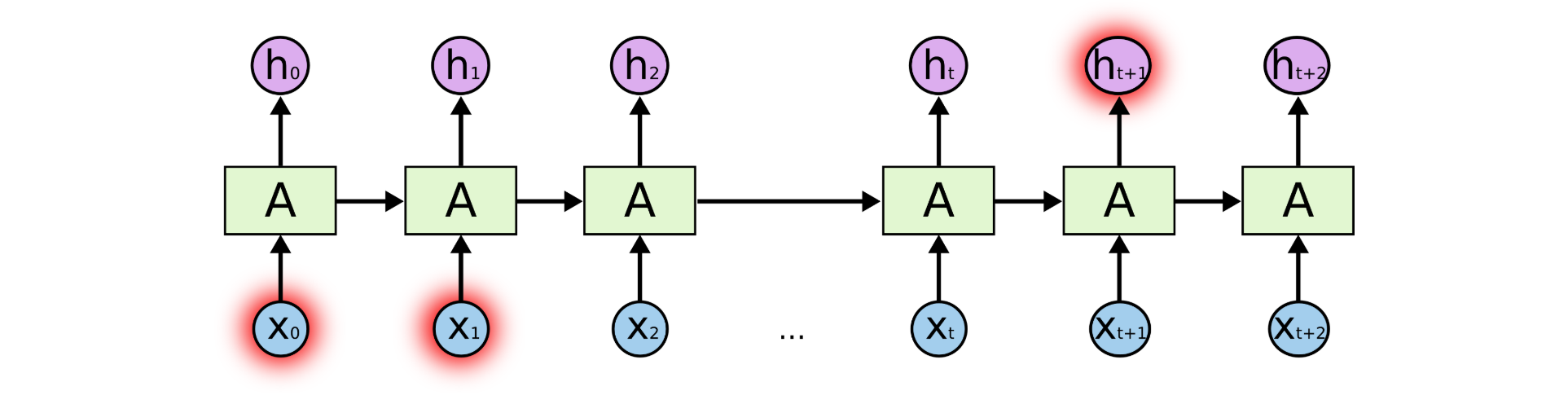
RNN的局限2:梯度消失和梯度爆炸問題
如果你正在嘗試處理一段文本進行預測,RNN 可能從一開始就會遺漏重要信息。在反向傳播期間(反向傳播是一個很重要的核心議題,本質是通過不斷縮小誤差去更新權值,從而不斷去修正擬合的函數),RNN 會面臨梯度消失的問題。
因為梯度是用于更新神經網絡的權重值(新的權值 = 舊權值 - 學習率*梯度),梯度會隨著時間的推移不斷下降減少,而當梯度值變得非常小時,就不會繼續學習。

換言之,在遞歸神經網絡中,獲得小梯度更新的層會停止學習—— 那些通常是較早的層。 由于這些層不學習,RNN會忘記它在較長序列中以前看到的內容,因此RNN只具有短時記憶。
而梯度爆炸則是因為計算的難度越來越復雜導致。
然而,幸運的是,有個RNN的變體——LSTM,可以在一定程度上解決梯度消失和梯度爆炸這兩個問題!

二、LSTM網絡

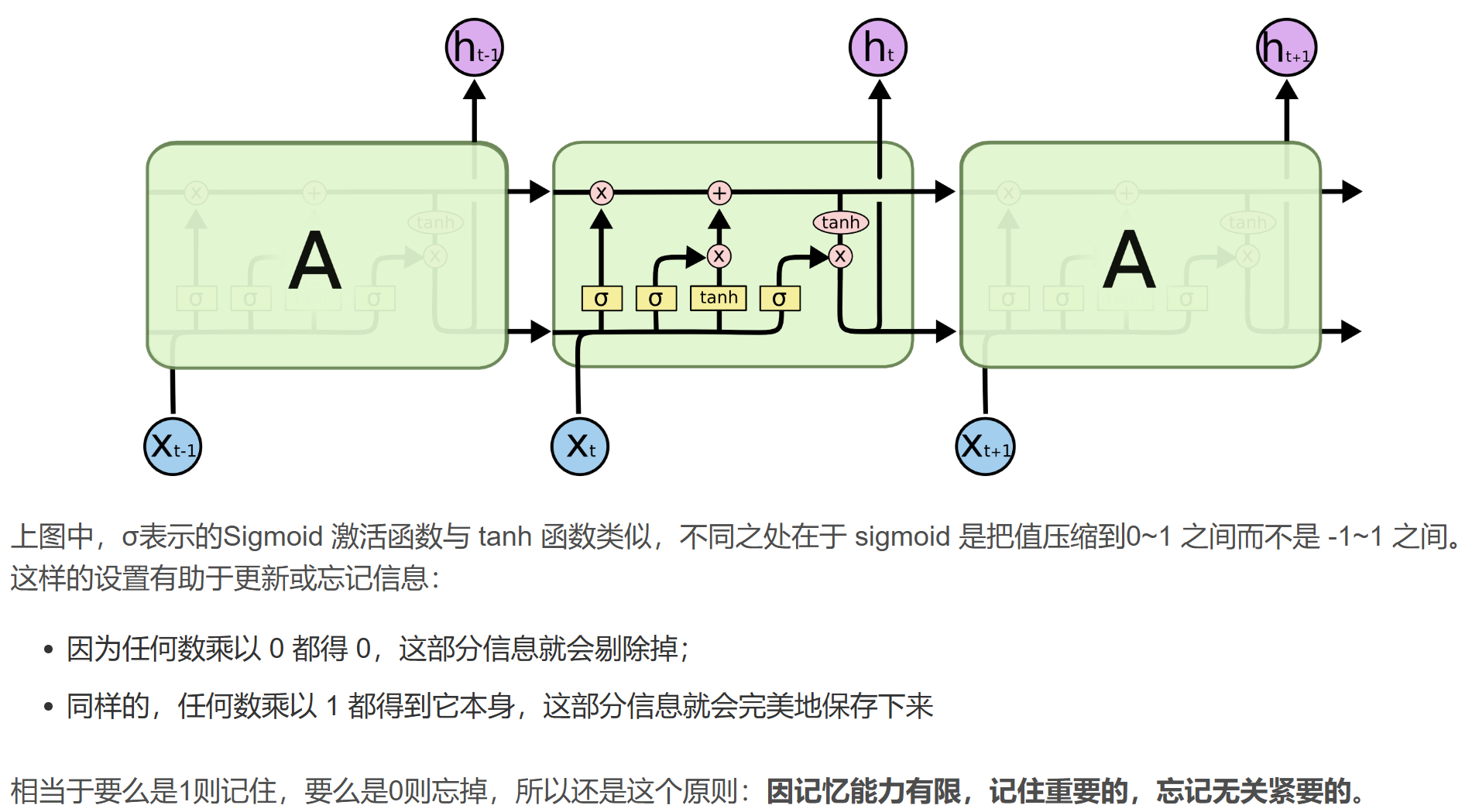
三.?GRU

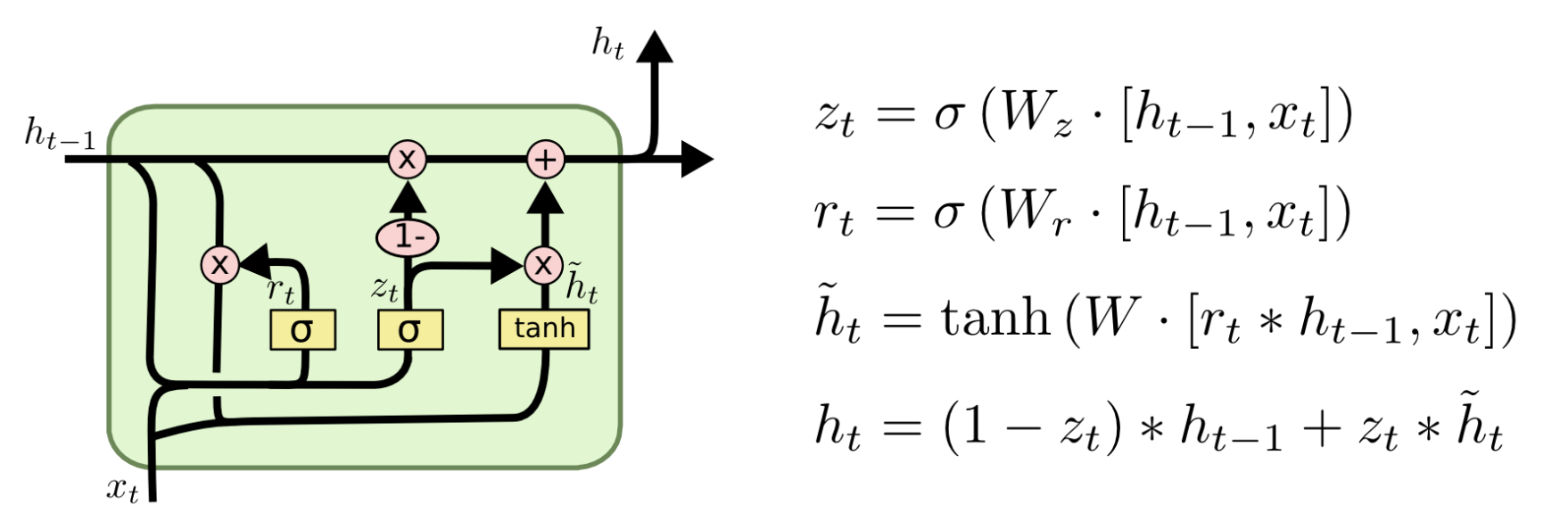
LSTM:功能更強,能更精細地控制記憶(但慢)。
GRU:簡化版,更快、更省資源,在很多任務上效果相當,甚至更好。
在工業界,如果資源有限,GRU 往往更受歡迎;而學術研究/復雜任務里,LSTM 更常用。
Transformer和RNN(原始 or LSTM or GRU)的區別:
1.RNN采用一種類似于遞歸的方式運行,無法執行并行化操作,也就無法利用GPU強大的并行化能力,而Transfomer基于Attention機制,使得模型可以并行化操作,而且能夠擁有全局的信息。
2.Transformer本身是不能利用單詞之間的位置信息的,所以需要在輸入中添加一個位置embedding信息,否則Transformer就類似于詞袋模型了。
3.RNN利用循環順序結構,對于長句需要的訓練步驟很多,加大了訓練的難度和時間。而Transfomer不需要循環,并行地處理單詞,而且其多頭注意力機制可以將很遠的詞聯系起來,大大提高了訓練速度和預測準確度。
網頁讀取電子秤數據——仙盟創夢IDE)






(錯誤日志實現))

)





與arm-linux-gcc、ARMGCC、ICCARM(IAR)、C51編譯器的兼容性)


》)
