一、通俗總結
Seq2Seq 就像一個 “序列轉換器”:先把輸入的一段話 “壓縮成一個核心意思”,再根據這個意思 “一句句生成另一段話”,能搞定翻譯、聽寫這類 “輸入輸出不一樣長” 的任務,但太長的內容可能記不全,還容易越錯越離譜。
二、拆解知識步驟
1. 由來的背景
傳統序列模型(如 RNN)只能處理 “輸入輸出長度固定” 或 “等長” 的任務(如文本分類、情感分析),但現實中很多任務需要 “不等長序列轉換”:
- 機器翻譯:輸入中文句子(長度 5)→ 輸出英文句子(長度 7)
- 語音轉文字:輸入音頻序列(時長 3 秒)→ 輸出文字序列(長度 10)
- 問答系統:輸入問題(長度 8)→ 輸出答案(長度 5)
這些場景下,需要一種能 “吃進一個序列,吐出另一個長度不同的序列” 的模型,Seq2Seq 由此被提出(2014 年由 Google 團隊提出)。
2. 目標及解決的問題
- 目標:實現 “任意長度輸入序列→任意長度輸出序列” 的端到端轉換,無需人工設計特征。
- 解決的問題:
- 解決 “輸入輸出長度不固定” 的問題:突破傳統模型對序列長度的限制。
- 解決 “序列依賴捕捉” 的問題:通過編碼器逐詞處理輸入,捕捉詞與詞的時序關系(如 “機器學習” 中 “機器” 和 “學習” 的關聯)。
- 解決 “跨模態轉換” 的問題:支持文本→文本(翻譯)、語音→文本(聽寫)、文本→語音(合成)等跨類型序列轉換。
3. 怎么實現的
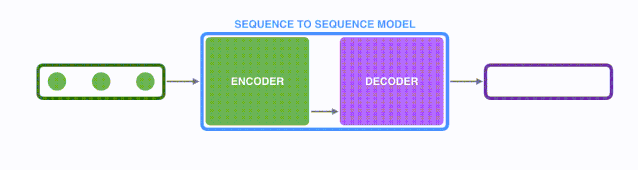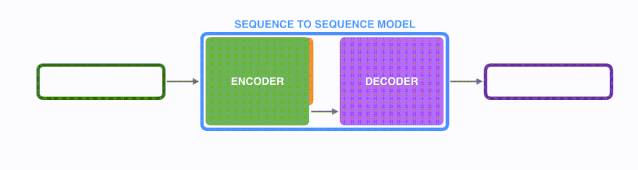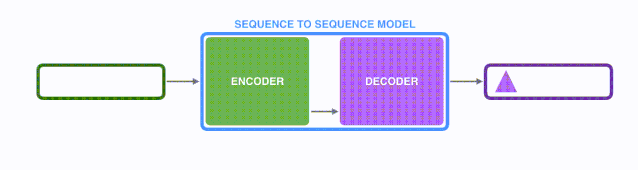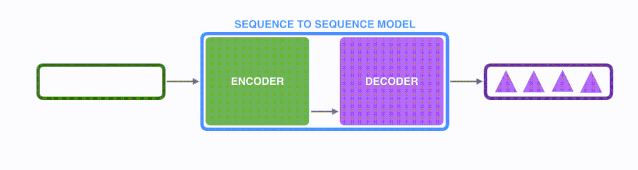
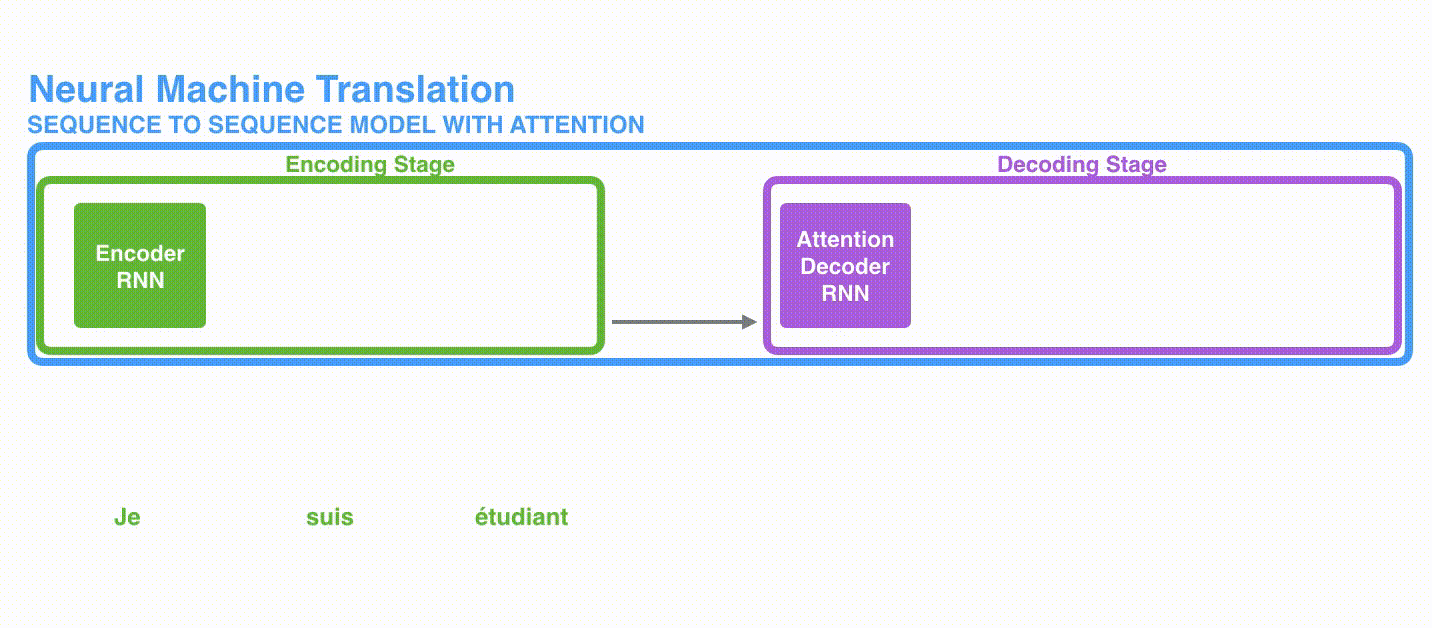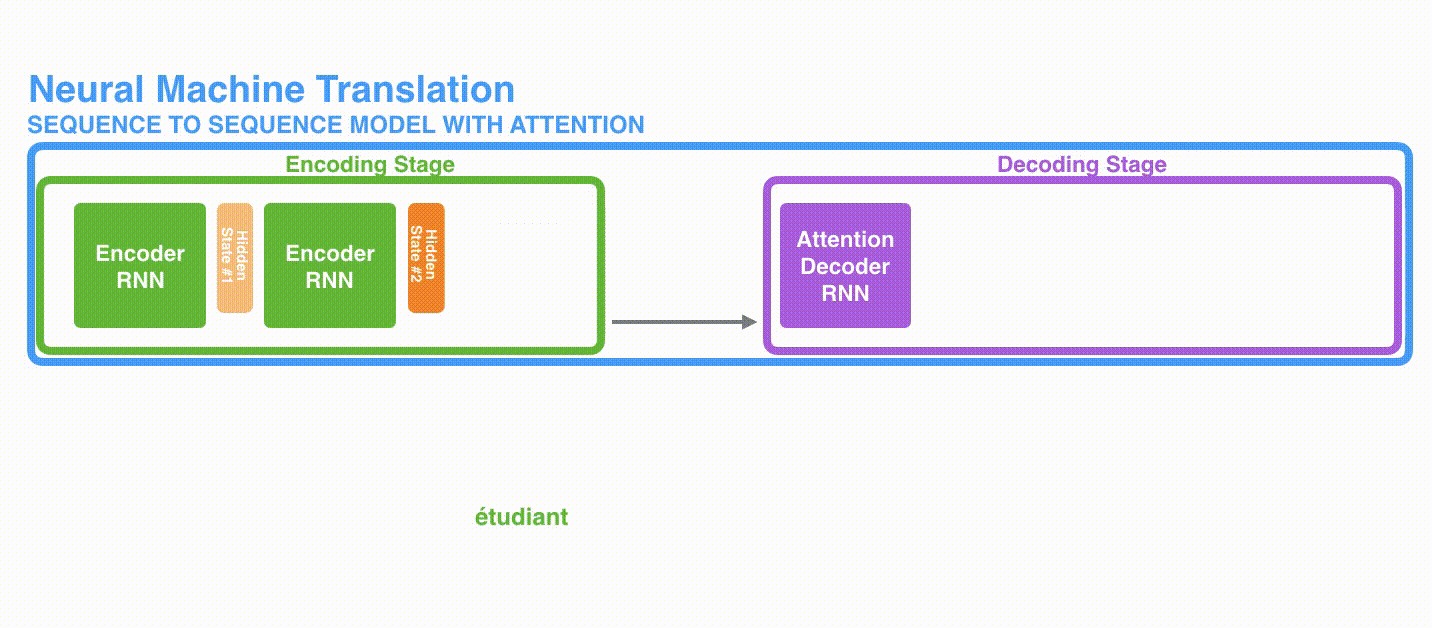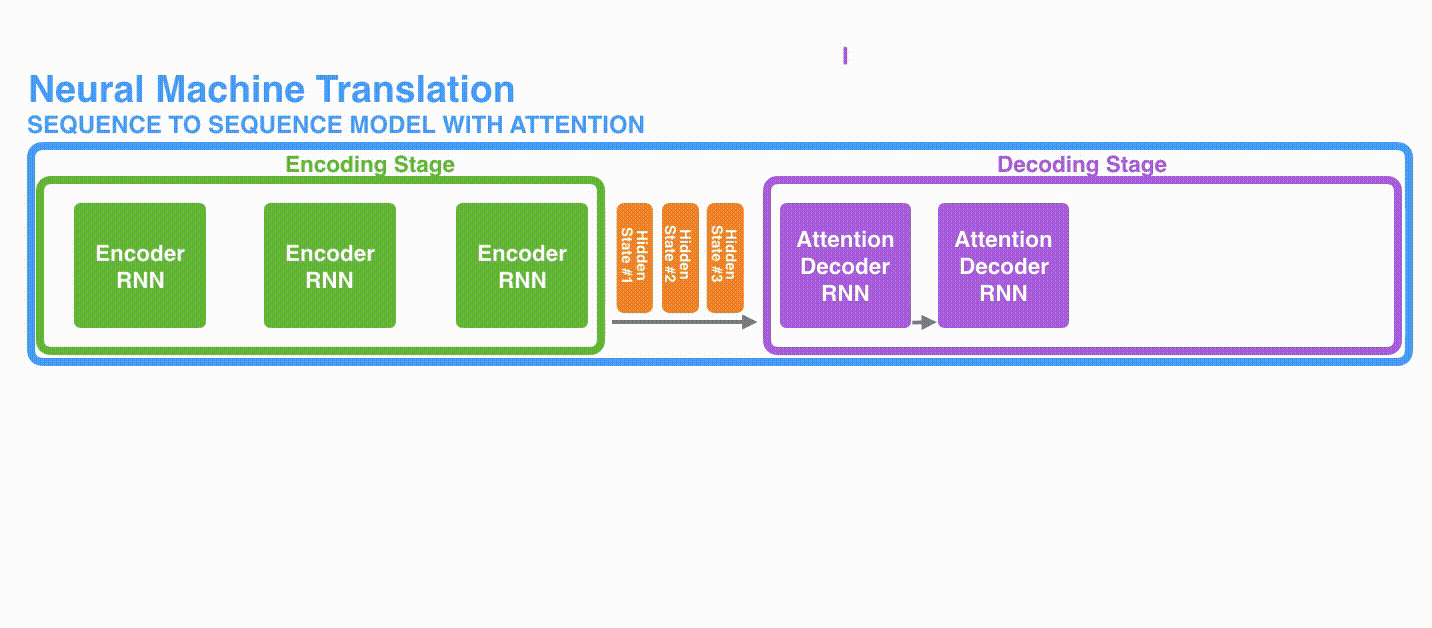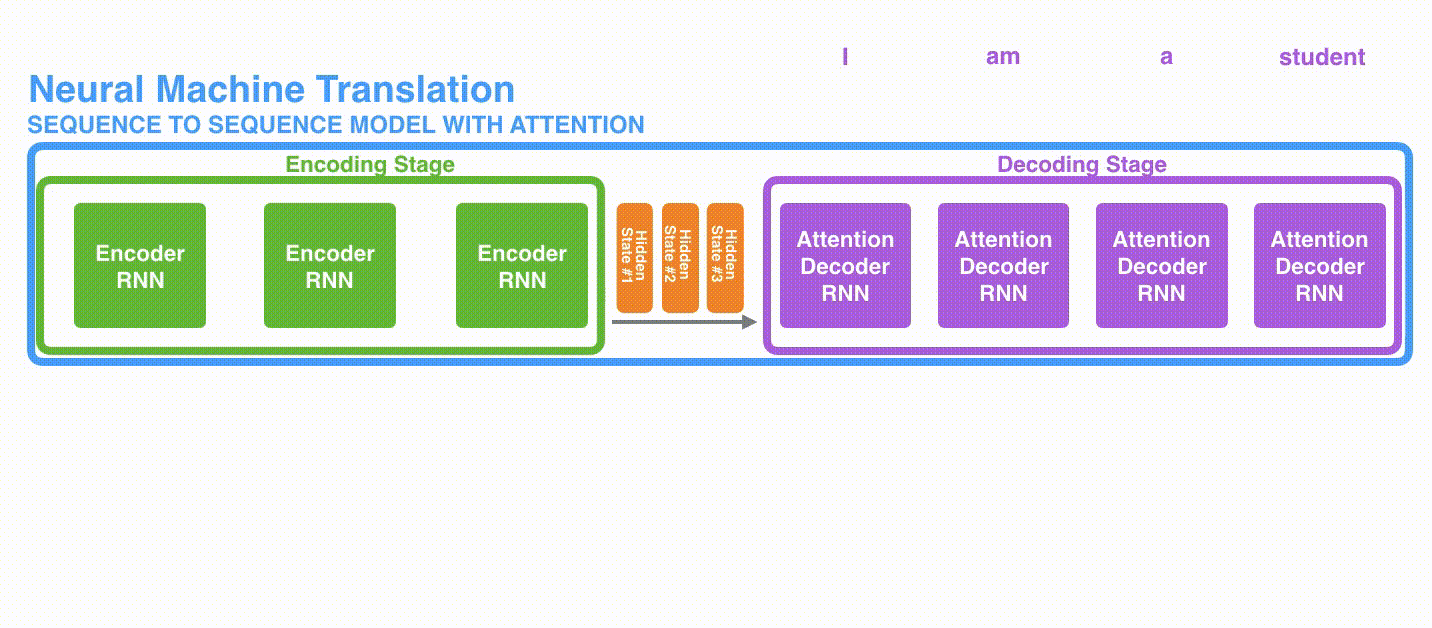
我們看seq2seq做了干了什么事情? seq2seq模型的輸入可以是一個 (單詞、字母或者圖像特征) 序列, 輸出是另外一個(單詞、字母或者圖像特征) 序列, 一個訓練好的seq2seq模型如下圖所示 :

如下圖所示,以NLP中的機器翻譯任務為例, 序列指的是一連串的單詞, 輸出也是一連串的單詞

將上圖藍色的模型進行拆解, 如下圖所示: seq2seq模型由編碼器(Encoder) 和解碼器(Decoder) 組成。綠色的編碼器會處理輸入序列中的每個元素并獲得輸入信息,這些信息會被轉換成為一個黃色的向量(稱為context向量)。當我們處理完整個輸入序列后,編碼器把 context向量 發送給紫色的解碼器,解碼器通過context向量中的信息,逐個元素輸出新的序列。
在機器翻譯任務中,seq2seq模型實現翻譯的過程如下圖所示。seq2seq模型中的編碼器和解碼器一般采用的是循環神經網絡RNN,編碼器將輸入的法語單詞序列編碼成context向量(在綠色encoder和紫色decoder中間出現),然后解碼器根據context向量解碼出英語單詞序列

我們來看一下黃色的context向量是什么?本質上是一組浮點數。而這個context的數組長度是基于編碼器RNN的隱藏層神經元數量的。下圖展示了長度為4的context向量,但在實際應用中,context向量的長度是自定義的,比如可能是256,512或者1024.

我們再找個生活中的案例做對比, “翻譯官工作流程”:
階段 1:編碼器(理解輸入)
- 角色:像 “翻譯官聽原文”,逐詞 “閱讀” 輸入序列(如中文句子),每一步記住當前詞和之前的內容,最終把整段話的意思壓縮成一個 “核心記憶”(上下文向量c)。
- 工具:常用 LSTM/GRU(帶門控機制的 RNN),避免長序列信息丟失(比普通 RNN 更擅長記住早期內容)。
階段 2:解碼器(生成輸出)
- 角色:像 “翻譯官說譯文”,基于編碼器的 “核心記憶”(c),從第一個詞開始,結合已說的內容,逐詞生成輸出序列(如英文句子)。
- 邏輯:生成每個詞時,既要參考 “核心記憶”(確保不偏離原文意思),又要參考已生成的詞(確保句子通順,如生成 “love” 后,更可能接 “machine learning” 而非 “cat”)。
4. 局限性
- 信息瓶頸:上下文向量c是固定長度(如 512 維),當輸入序列過長(如 100 詞以上),早期信息會被 “壓縮丟失”(類似翻譯官記不住長句子的開頭)。
- 累積錯誤:解碼器生成依賴上一個詞,若某一步錯了(如把 “機器學習” 譯成 “machine study”),后續會跟著錯(類似翻譯錯一個詞,后面全跑偏)。
- 無法并行:編碼器和解碼器都是 “逐詞處理”(時序依賴),訓練速度慢(比 Transformer 慢 8-10 倍)。
- 雙向信息缺失:編碼器雖能看全輸入,但解碼器生成時只能看已生成的詞(單向),難以修正全局錯誤(如翻譯 “我不吃肉”,先譯 “I don't eat”,后面很難再補 “meat” 而非 “fish”)。
三、數學表達式及含義

四、Attention的引入
引入注意力機制前, 看看前文說的局限性后, 再思考兩個問題:
- 1、 seq2seq模型處理長文本序列有哪些難點?
- 2、 基于RNN的seq2seq模型如何結合attention來解決問題1 并提升模型效果?
基于RNN的seq2seq模型編碼器所有信息都編碼到了一個context向量中,便是這類模型的瓶頸。一方面單個向量很難包含所有文本序列的信息,另一方面RNN遞歸地編碼文本序列使得模型在處理長文本時面臨非常大的挑戰(比如RNN處理到第500個單詞的時候,很難再包含1-499個單詞中的所有信息了)。
面對上面的問題, Bahdanau等2014發布的Neural Machine Translation by Jointly Learning to Align and Translate 和 Luong等2015年發布的Effective Approaches to Attention-based Neural Machine Translation 兩篇論文中提出了一種叫做注意力attetion的技術。通過attention技術,seq2seq模型極大地提高了機器翻譯的質量。歸其原因是:attention注意力機制,使得seq2seq模型可以有區分度、有重點地關注輸入序列。
讓我們繼續來理解帶有注意力的seq2seq模型:一個注意力模型與經典的seq2seq模型主要有2點不同:
1、首先,編碼器會把更多的數據傳遞給解碼器。編碼器把所有時間步的hidden state(隱藏層狀態)傳遞給解碼器,而不是只傳遞最后一個hidden state(隱藏層狀態),如下面的動態圖所示:
2、注意力模型的解碼器在產生輸出之前,做了一個額外的attention處理。如下圖所示,具體為:
- 由于編碼器中每個hidden state(隱藏層狀態)都對應到輸入句子中一個單詞,那么解碼器要查看所有接收到的編碼器的hidden state(隱藏層狀態)。
- 給每個hidden state(隱藏層狀態)計算出一個分數(我們先忽略這個分數的計算過程)。
- 所有hidden state(隱藏層狀態)的分數經過softmax進行歸一化。
- 將每個hidden state(隱藏層狀態)乘以所對應的分數,從而能夠讓高分對應的 hidden state(隱藏層狀態)會被放大,而低分對應的hidden state(隱藏層狀態)會被縮小。
- 將所有hidden state根據對應分數進行加權求和,得到對應時間步的context向量。

所以,attention可以簡單理解為:一種有效的加權求和技術,其藝術在于如何獲得權重。
現在,讓我們把所有內容都融合到下面的圖中,來看看結合注意力的seq2seq模型解碼器全流程,動態圖展示的是第4個時間步:
- 注意力模型的解碼器 RNN 的輸入包括:一個word embedding 向量,和一個初始化好的解碼器 hidden state,圖中是 h_init 。
- RNN 處理上述的 2 個輸入,產生一個輸出和一個新的 hidden state,圖中為 h_4 。
- 注意力的步驟:我們使用編碼器的所有 hidden state向量和 h_4 向量來計算這個時間步的context向量( C_4 )。
- 再把 h_4 和 C_4 拼接起來,得到一個橙色向量。
- 我們把這個橙色向量輸入一個前饋神經網絡(這個網絡是和整個模型一起訓練的)。
- 根據前饋神經網絡的輸出向量得到輸出單詞:假設輸出序列可能的單詞有 N 個,那么這個前饋神經網絡的輸出向量通常是 N 維的,每個維度的下標對應一個輸出單詞,每個維度的數值對應的是該單詞的輸出概率。
- 在下一個時間步重復1-6步驟。
最后,我們可視化一下注意力機制,看看在解碼器在每個時間步關注了輸入序列的哪些部分

需要注意的是:注意力模型不是無意識地把輸出的第一個單詞對應到輸入的第一個單詞,它是在訓練階段學習到如何對兩種語言的單詞進行對應(在本文的例子中,是法語和英語)
該知識點的學習為我們后續學習Transformer打下堅實的基礎





圖表--儀表盤)

)
:如何快速創建一個組件)


)







)