一、引言
MindVLA 主要包括空間智能模塊、語言智能模塊、動作策略模塊、強化學習模塊,這些模塊分別有以下功能:
- 空間智能模塊:輸入為多模態傳感器數據,使用 3D 編碼器提取時空特征,然后將所有傳感器與語義信息融合成統一的表征。
- 語言智能模塊:嵌入式部署的大語言模型 MindGP,用于空間 + 語言的聯合推理,支持語音指令和反饋,可能實現人車交互。
- 動作策略模塊:使用擴散模型生成車輛未來的行為軌跡,引入噪聲來引導擴散過程以生成多樣化的動作規劃。
- 強化學習模塊:使用 World Model 模擬外部環境響應,評估行為后果;使用獎勵模型(Reward Model):提供偏好或安全性評估,可能采用人類反饋(RLHF);使用閉環學習根據行為軌跡進行持續優化和泛化。
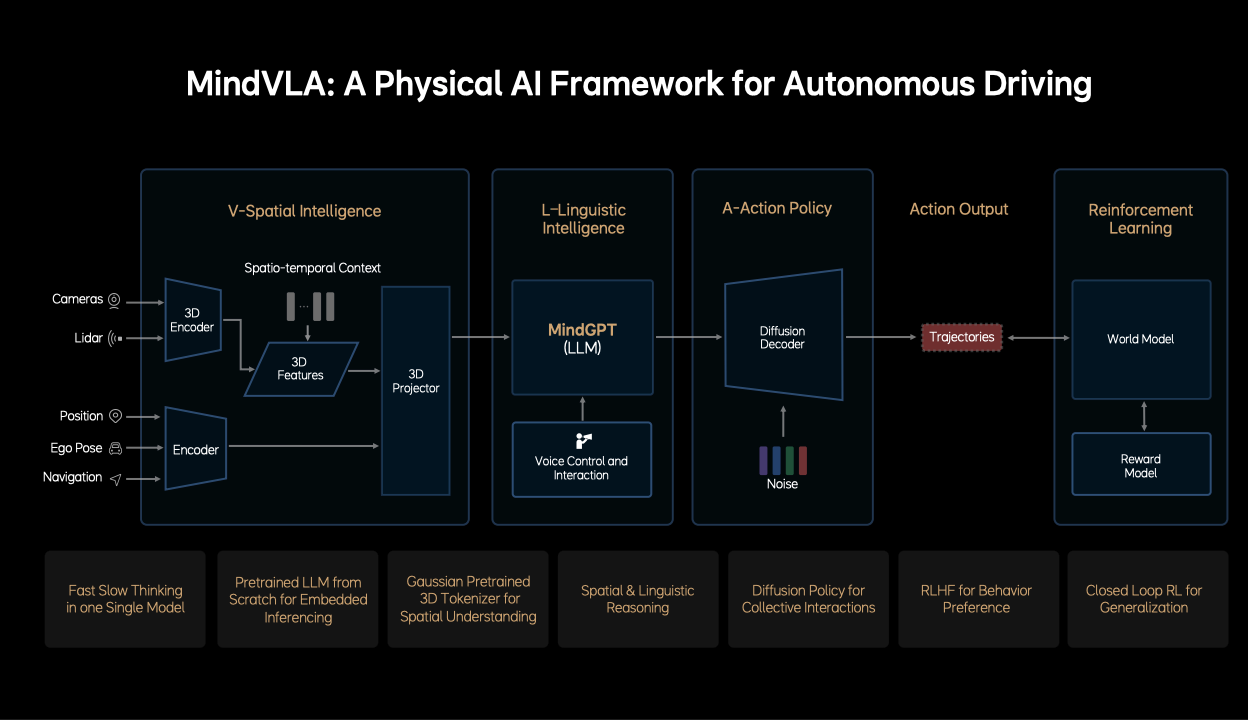
其亮點包括:
- 快慢思維融合于同一模型(Fast-Slow Thinking in One Model)
- 從零開始預訓練的嵌入式大語言模型
- 高斯建模的 3D Tokenizer 增強空間理解
- 支持空間與語言的聯合推理
- 擴散策略實現群體交互與行為生成
- 基于人類反饋的行為偏好學習(RLHF)
- 通過閉環強化學習實現泛化能力提升
- 下面將對以上提及的核心技術進行剖析。
二、V-Spatial Intelligence:自監督 3D 高斯編碼器預訓練
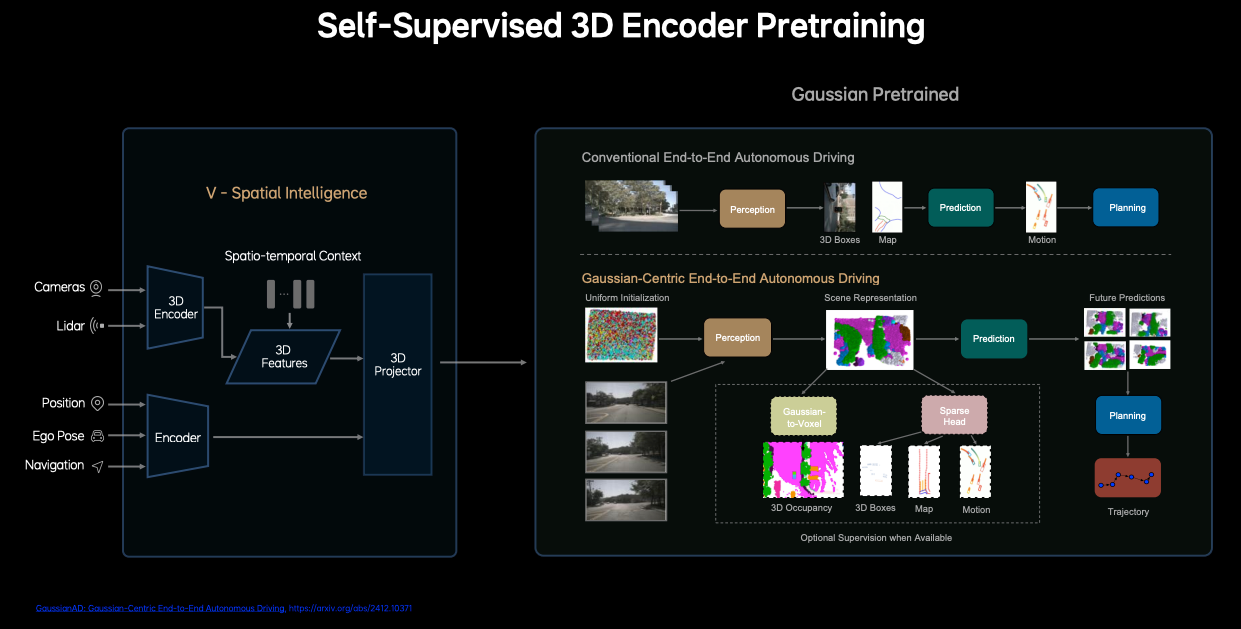
2.1 傳統端到端自動駕駛的不足
傳統的端到端自動駕駛通過感知(Perception)生成 3D 目標框(3D Boxes);然后預測模塊使用 3D 目標和地圖預測運動軌跡;規劃模塊根據預測進行軌跡規劃。這種傳統方法采用 BEV(鳥瞰圖)或稀疏實例框作為場景表示,存在信息全面性與效率的權衡。BEV 壓縮高度信息導致細節丟失,而稀疏查詢可能忽略關鍵環境細節(如不規則障礙物)。密集體素表示計算開銷大,難以支持實時決策。所以理想汽車提出了 GaussianAD 框架。
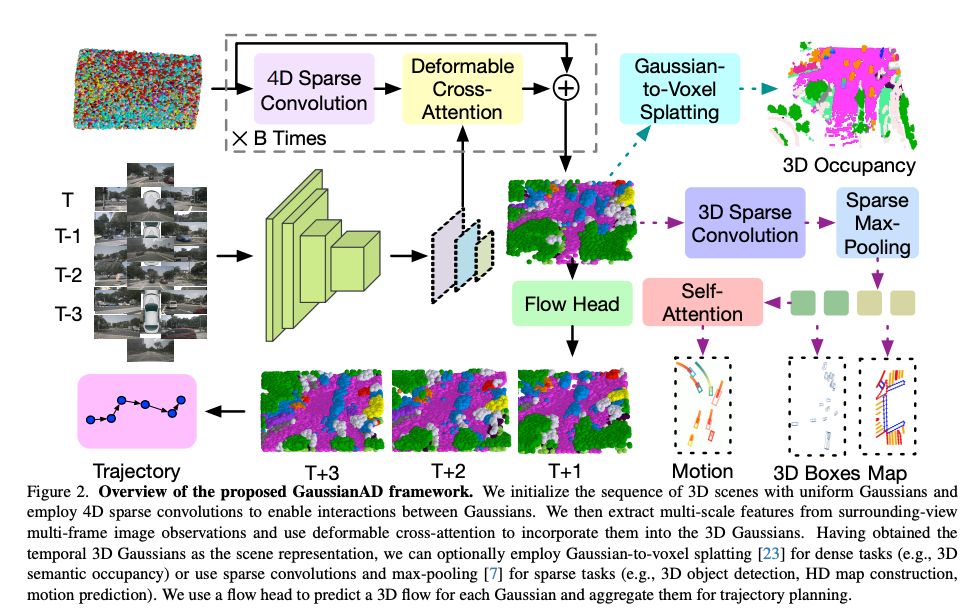
2.2 GaussianAD 框架的優點及核心方法
參考論文:GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
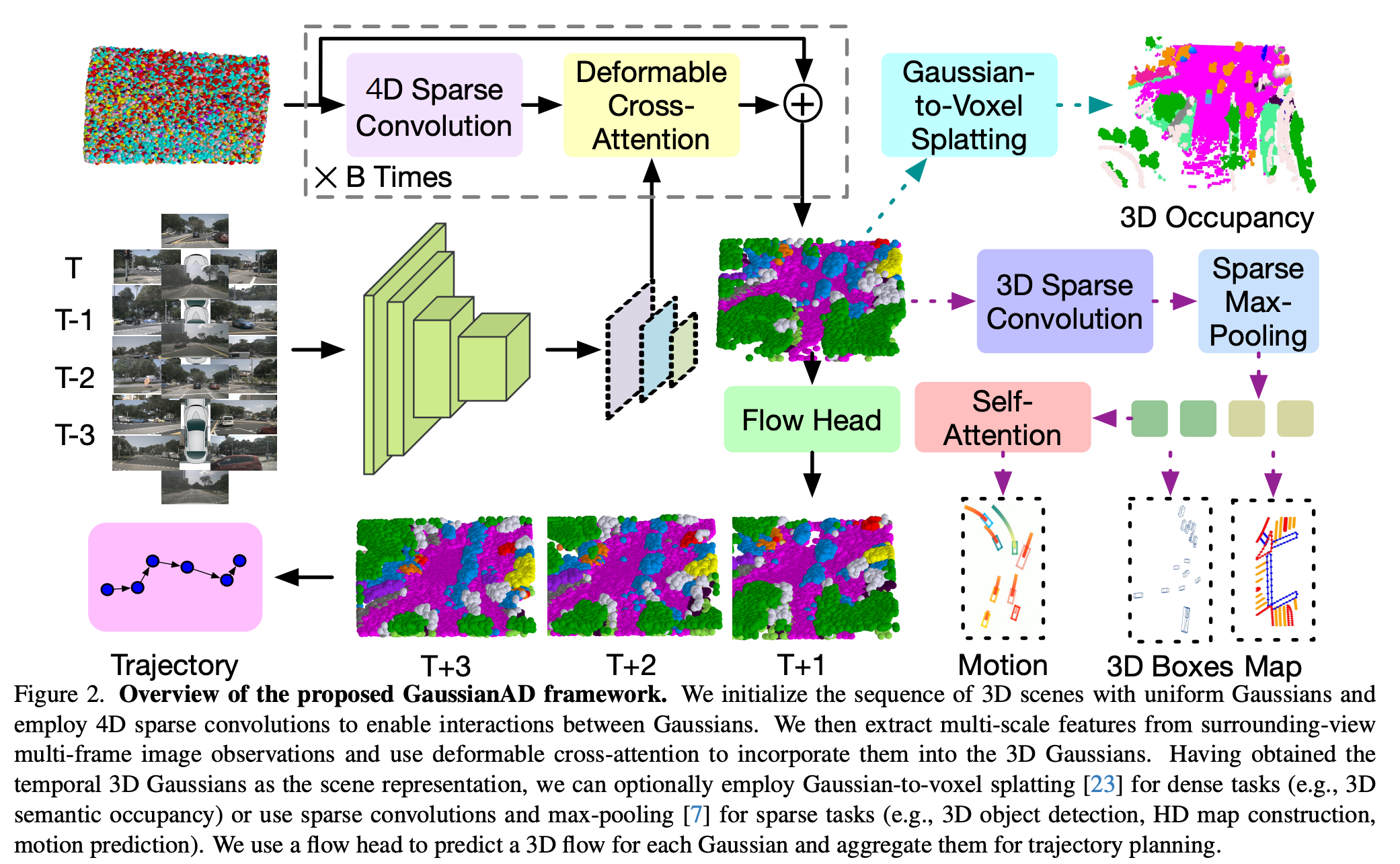
GaussianAD 用均勻的高斯序列初始化 3D 場景,并使用 4D 稀疏卷積來實現高斯之間的交互。然后從環視多幀圖像提取多尺度特征,并使用可變形的交叉注意力將它們納入 3D 高斯。在獲得時間 3D 高斯作為場景表示后,可以選擇使用對密集任務的高斯到體素 splatting(例如,3D 語義占用),或者使用稀疏卷積和最大池化進行稀疏任務(例如,3D 目標檢測、高清地圖構建、運動預測)。GaussianAD 使用 flow 頭來預測每個高斯的 3D 流,并將其匯總用于軌跡規劃。
2.2.1 3D 高斯場景表示
現有特征表示方法的不足
現有方法通常構建密集的 3D 特征來表示周圍環境,并處理具有相等存儲和計算資源的每個 3D 體素,這通常會因為資源分配不合理而導致難以解決的開銷。與此同時,這種密集的 3D 體素表示無法區分不同比例的目標。
高斯表示的優勢
高斯表示以均勻分布的 3D 高斯初始化場景,通過多視角圖像逐步優化高斯參數(均值、協方差、語義),生成稀疏的 3D 語義高斯集合。每個高斯單元描述局部區域的幾何和語義屬性。高斯混合模型能近似復雜場景,稀疏性減少冗余計算,同時保留細粒度 3D 結構,極大地促進下游任務的性能提升。
感知任務
- 高斯特征提取
GaussianAD 首先將 3D 高斯及其高維查詢表示為可學習的向量。然后,我們使用高斯編碼器來迭代地回放這些表示。每個高斯編碼器塊由三個模塊組成:一個促進高斯之間交互的自編碼模塊,一個用于聚合視覺信息的圖像交叉關注模塊,以及一個用于微調高斯屬性的細化模塊。與 GaussianFormer 不同,GaussianAD 使用由 4D 稀疏卷積組成的時間編碼器,將上一幀的高斯特征與當前幀中的相應特征集成。
- 稀疏 3D 目標檢測
提取到稀疏高斯特征后,采用 VoxelNeXt 根據稀疏體素特征預測 3D 目標。使用 3D 稀疏 CNN 網絡來編碼 3D 高斯表示,一組 Agent Tokens 來解碼 3D 動態物體邊界框。
- 稀疏語義地圖構建
使用一組 Map Tokens 生成車道、邊界等靜態元素。
預測與規劃
- 高斯流預測:基于當前高斯狀態和規劃軌跡,預測未來幀的高斯分布,通過仿射變換模擬自車運動后的觀測場景。
- 軌跡規劃:結合預測的高斯流和未來場景的占用情況,優化軌跡以最小化碰撞風險與軌跡偏差。
端到端訓練
- 靈活監督:支持多任務監督(3D 檢測、語義地圖、運動預測、占用預測),通過損失函數聯合優化:
- 感知損失(檢測、地圖、占用)
- 預測損失(未來場景與真實觀測的差異)
- 規劃損失(軌跡誤差與碰撞率)
- 未來場景自監督:利用未來幀的真實觀測作為預測監督,增強長期一致性。
三、L(Lingustic Intelligence):定制化設計 LLM
L 模塊的設計思想比較容易理解,LLM 模型是強大且通用的模型毋庸置疑,但是其使用的是互聯網多模態數據資源進行訓練的,數據場景和分布混亂,比如存在大量與自動駕駛無關的文史類數據,難以直接應用到自動駕駛場景中,尚不具備較強的 3D 空間理解能力、3D 空間推理能力和強大的語言能力,需要在模型的預訓練階段就要加入大量的相關數據。所以,理想汽車不計成本地從 0 開始設計和訓練一個適合 VLA 的基座模型。在模型架構上還進行了稀疏化設計,減少模型容量,從而實現推理性能的提升。
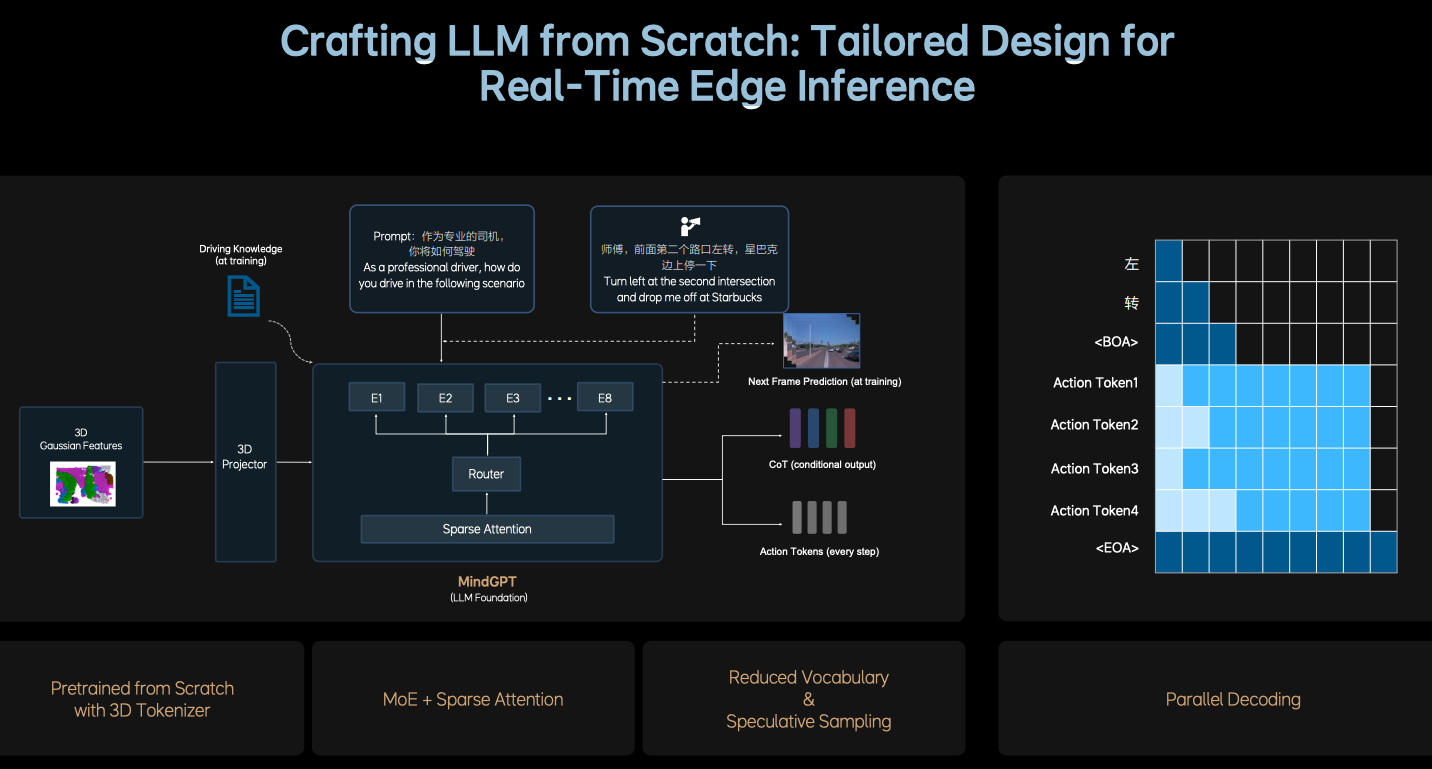
上圖為 PPT 上對 L 模塊的介紹,其核心設計思想可以總結為:
- 基于開源 LLM 結構,重新設計適用于智駕場景的 LLM input tokenizer;
- **稀疏化:**為了在增加模型參數量的同時平衡端側推理速率,采用 MoE+SparseAttention 的高效結構;使用多個專家實現模型擴容,還可以保證模型參數量不會大幅度增加;引入 SparseAttention 進一步提升稀疏化率。
- **訓練數據配比重構:**融入大量的 3D 場景數據和自動駕駛相關圖文數據,同時降低文史類數據的比例;
- **進一步強化 3D 空間理解和推理能力:**加入未來幀的預測生成 + 稠密深度的預測;
- **提升邏輯推理能力:**人類思維模式 + 自主切換快思考慢思考,慢思考輸出精簡的 CoT(采用的固定簡短的 CoT 模板) + 輸出 action token;快思考直接輸出 action token;
- **實時推理性能(10HZ):**通過以下手段壓榨 OrinX 和 ThorU 的性能,在同一個 Transformer 模型中加入了兩種推理模式:
- CoT 生成加速:小詞表 + 投機推理(推理模式 1: 因果注意力機制 token by token 的逐字輸出);
- action token 生成加速:并行解碼的方式(推理模式 2: 雙向注意力機制并行一次性輸出);
四、A(Action Policy): 生成精細化動作
參考論文:https://arxiv.org/abs/2503.10434
4.1 總體介紹
LLM 基座模型構建完成后,利用擴散模型 Diffusion Model 將 action token 解碼為最終的軌跡,包括自車軌跡、他車和行人的軌跡,這樣可以提升 VLA 模型在復雜交通環境下的博弈能力。另外,Diffusion Model 還具有根據外部的條件改變生成結果,類似于圖像生成領域的多風格生成。
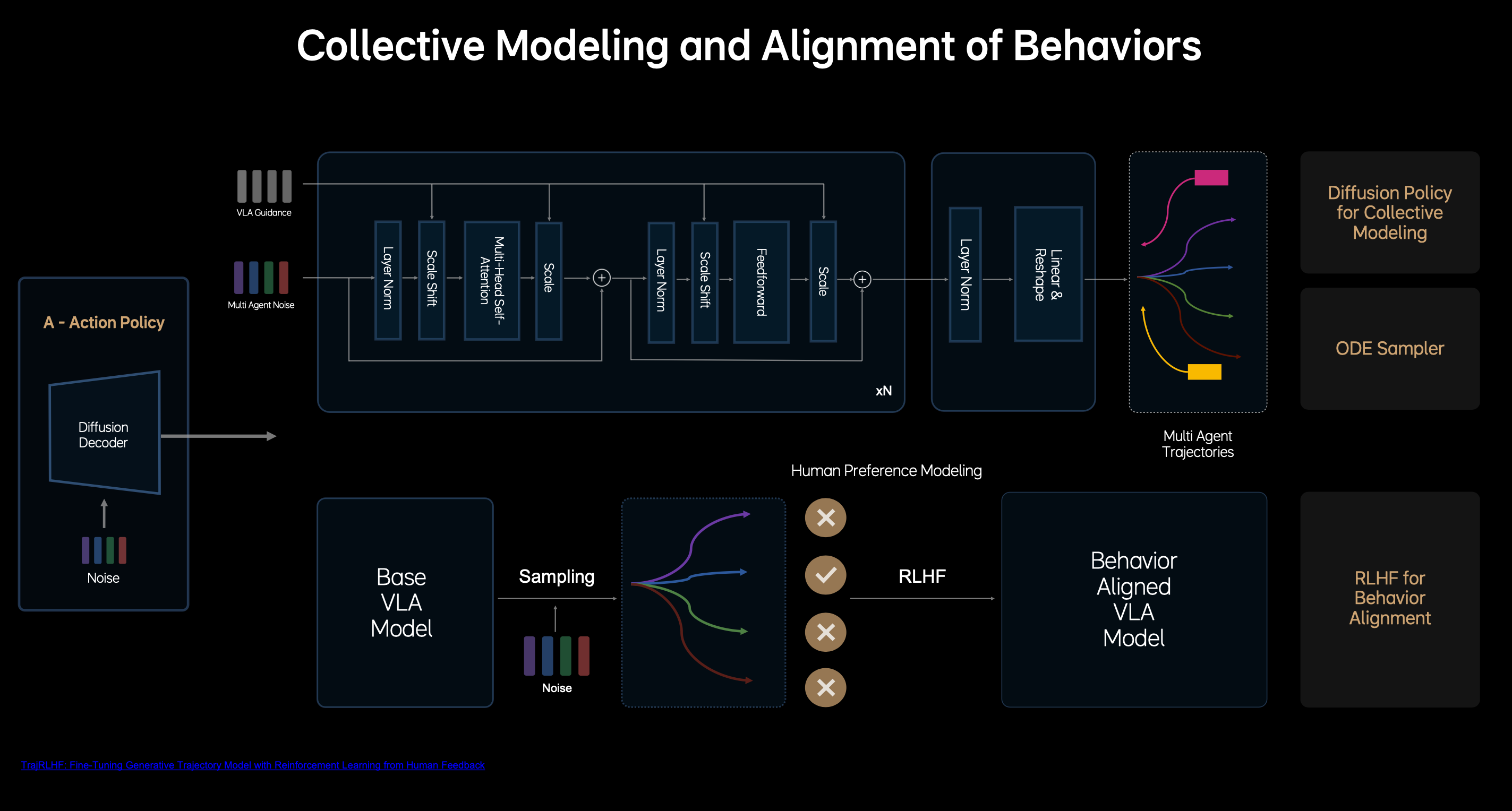
上圖為 PPT 上對 V 模塊的介紹,其核心設計思想可以總結為:
- 引入多層 DIT(Diffusion Transformer)結構;
- **提升生成效率:**基于常微分方程的 ode 采樣器大幅的加速 diffusion 的生成過程,使其在 2~3 步內完成穩定軌跡的生成;
- **對齊人類駕駛員行為:**使用 RLHF 做后訓練,通過人類偏好數據集微調模型的采樣過程, 對齊專業駕駛員的行為,提高安全駕駛的下限。其中,人類偏好數據集搭建:人類駕駛數據 + NOA 的接管數據
4.2 TrajHF
TrajHF 通過 多條件去噪器生成多樣化軌跡 + 人類反饋驅動的強化學習微調,解決了生成模型與人類駕駛偏好的對齊問題。其結構兼顧生成能力與個性化適配,在安全約束下實現了駕駛風格的靈活調節,為自動駕駛的“人車共駕”提供了新范式。
4.2.1 動機
- 數據集偏差:傳統模仿學習(IL)僅學習數據集的平均行為,忽略人類駕駛的微妙偏好(如攻擊性超車、保守跟車等)。
- 分布偏移:生成模型易受高頻模式主導,難以生成低頻但符合人類偏好的軌跡(如復雜交互中的適應性行為)。
- 高階因素缺失:人類駕駛受風險容忍度、社會交互等隱性因素影響,現有模型難以編碼。
4.2.2 核心思想
- 人類反饋作為監督信號:通過人類標注的軌跡排序或偏好標簽,引導模型學習多樣化駕駛風格。
- 強化學習微調(RLHF):將偏好轉化為獎勵函數,優化策略以最大化人類偏好獎勵。
- 多模態生成與約束平衡:結合擴散模型生成多樣化候選軌跡,通過強化學習微調對齊偏好,同時用行為克隆(BC)損失保留基礎駕駛能力。
4.2.3 模型結構
TrajHF 包括生成軌跡模型(Diffusion Policy)和 強化學習微調(RL Finetuning)這兩個部分,其中 RL Finetuning 是最大化人類偏好獎勵。
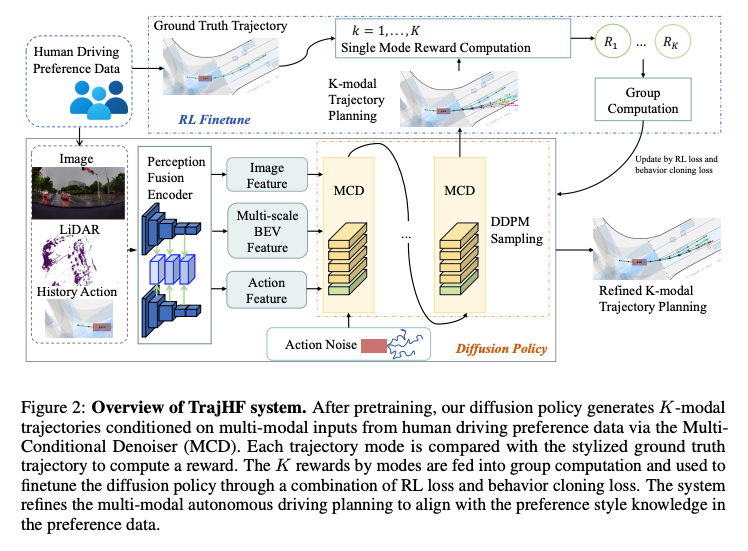
除了這兩個部分,個人認為 TrajHF 中最重要的是偏好數據的自動構建,我們首先就來介紹這個部分。
偏好數據自動構建
偏好數據自動構建過程如下圖所示,這個過程涉及用不同的駕駛風格標簽標記大量駕駛數據。然而,出現了實際挑戰,例如確定每個場景或框架是否需要駕駛風格標簽。以下步驟概述了這些挑戰和相應的解決方案。
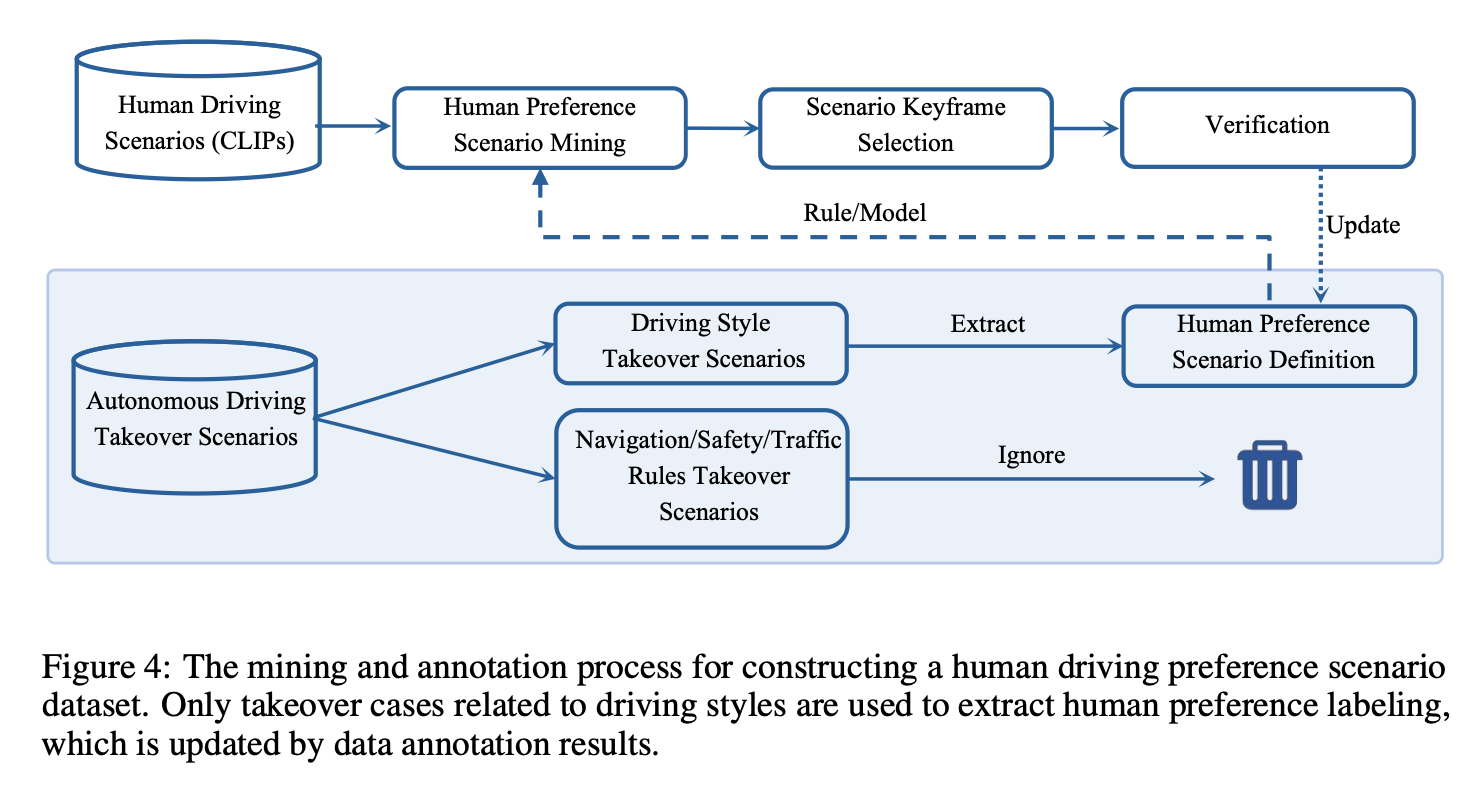
- **場景挖掘:**人類駕駛通常發生在普通環境中,這使得很難為每個決定定義特定的駕駛風格,而且手動手動注釋效率低下。論文發現人類司機接管數據可以幫助識別偏好場景。這些數據分為六類(例如,“過于激進”或“過于保守”),每個類別對應不同的駕駛風格,可用于定義規則或訓練模型,以識別偏好場景。
- **關鍵幀標注:**在確定偏好場景后,只需要標記與偏好相關的部分,專注于發生重要動作的關鍵幀,例如速度或方向的變化。如果幀標記過早,則定義操作尚未發生;如果標記過晚,則該操作已經開始。關鍵幀識別的明確規范允許基于規則的自動檢測,從而實現潛在的大規模注釋。
- **手動檢查:**注釋的關鍵幀經過隨機手動檢查,以確保數據質量。人工檢查員可以在特殊情況下更新場景定義或引入新的偏好場景。
Diffusion Policy
Diffusion Policy 的核心組件是多條件去噪器(Multi-Conditional Denoiser, MCD),它的工作過程如下:
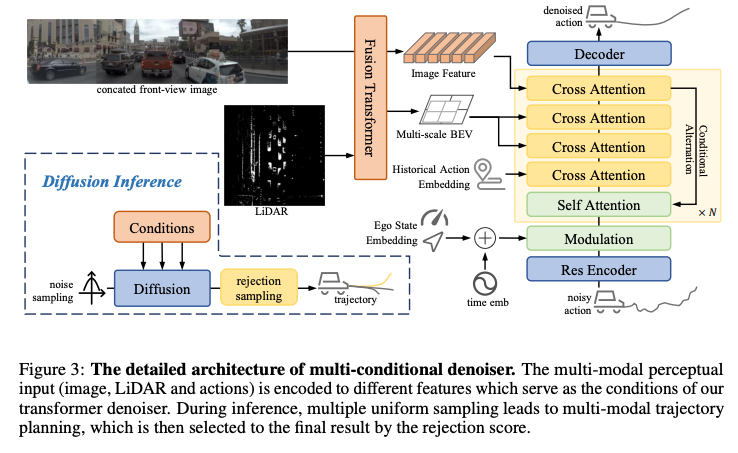
- 輸入:多模態感知數據;
- 軌跡表示:將軌跡 轉換為動作空間,減少時間異方差性。
- 去噪過程:
- 噪聲動作經 MLP 編碼,與狀態/時間嵌入融合。
- 圖像與激光雷達特征通過骨干網絡(ViT + ResNet34)提取,經融合 Transformer 交互生成 BEV 特征。
- 條件與噪聲動作通過交叉注意力模塊迭代去噪。
- 輸出:生成 K 條多模態候選軌跡(8 個航跡點,覆蓋 4 秒)。
RL Finetuning
RL Finetuning 的目標是最大化人類偏好獎勵,主要包括獎勵計算和策略優化兩個步驟,其中涉及較多數學計算,感興趣的同學可以自行研讀論文。

參考資料
https://zhuanlan.zhihu.com/p/1885988337225032557
理想賈鵬 GTC 2025 演講 PPT
理想賈鵬 GTC 2025 講 VLA 完整視頻
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
ibili.com/video/BV11yX5Y9EEj/?vd_source=115911bd71b74bfcc0cad43e576887e4)
GaussianAD: Gaussian-Centric End-to-End Autonomous Driving
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
 --- TCP/IP網絡結構(運輸層))


Java 對象創建的完整過程)
JSON數據類型在酒店管理系統搜索—仙盟創夢IDE)
)

)











