【2025版】12 生成式對抗網絡GAN 一 – 基本概念介紹_嗶哩嗶哩_bilibili
目錄
1. GAN生成式對抗網絡
2. GAN的訓練 散度差異
3.WGAN
4.訓練GAN
5. 如何客觀評估GAN
6. 條件型生成(按照要求)
7. Cycle GAN(互轉配對)
8.?diffusion model 擴散模型
1. GAN生成式對抗網絡
生成式問題:模型的創造力? 沒有標準答案 就像大家頭腦風暴各自圍繞話題說一說,
比如問模型想吃一個水果? 機器人會回答 蘋果、梨、草莓等等,
又比如讓模型根據描述 生成更多的文字/圖片/視頻。
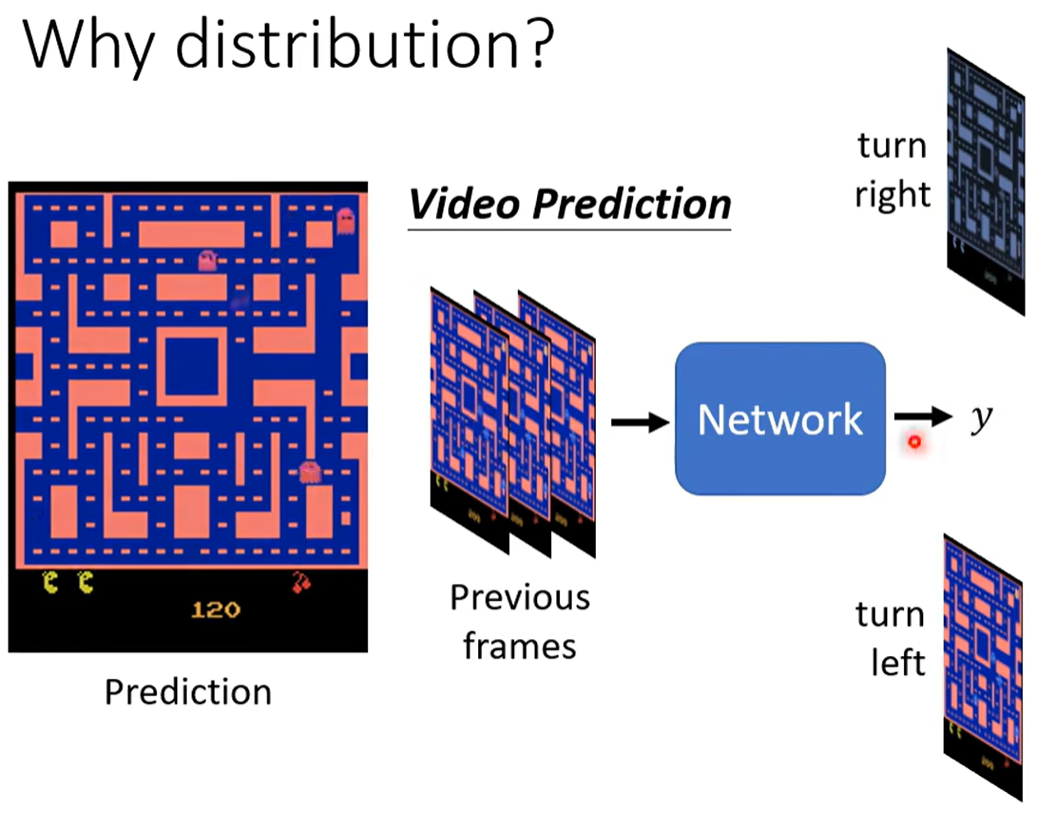
在監督學習下會存在問題:比如一個預測下一幀的游戲圖像 給網絡過去幾幀的游戲畫面,
但因為訓練數據對同一個轉角 有向左走、向右走這樣不同且矛盾的數據,所以訓練的結果網絡會學會“兩面討好”,輸出“又要接近向左走 又要接近向右轉”。
我可以給一個二項分布 讓機器可能學到 0則左轉 1則右轉,這樣就不會沖突。
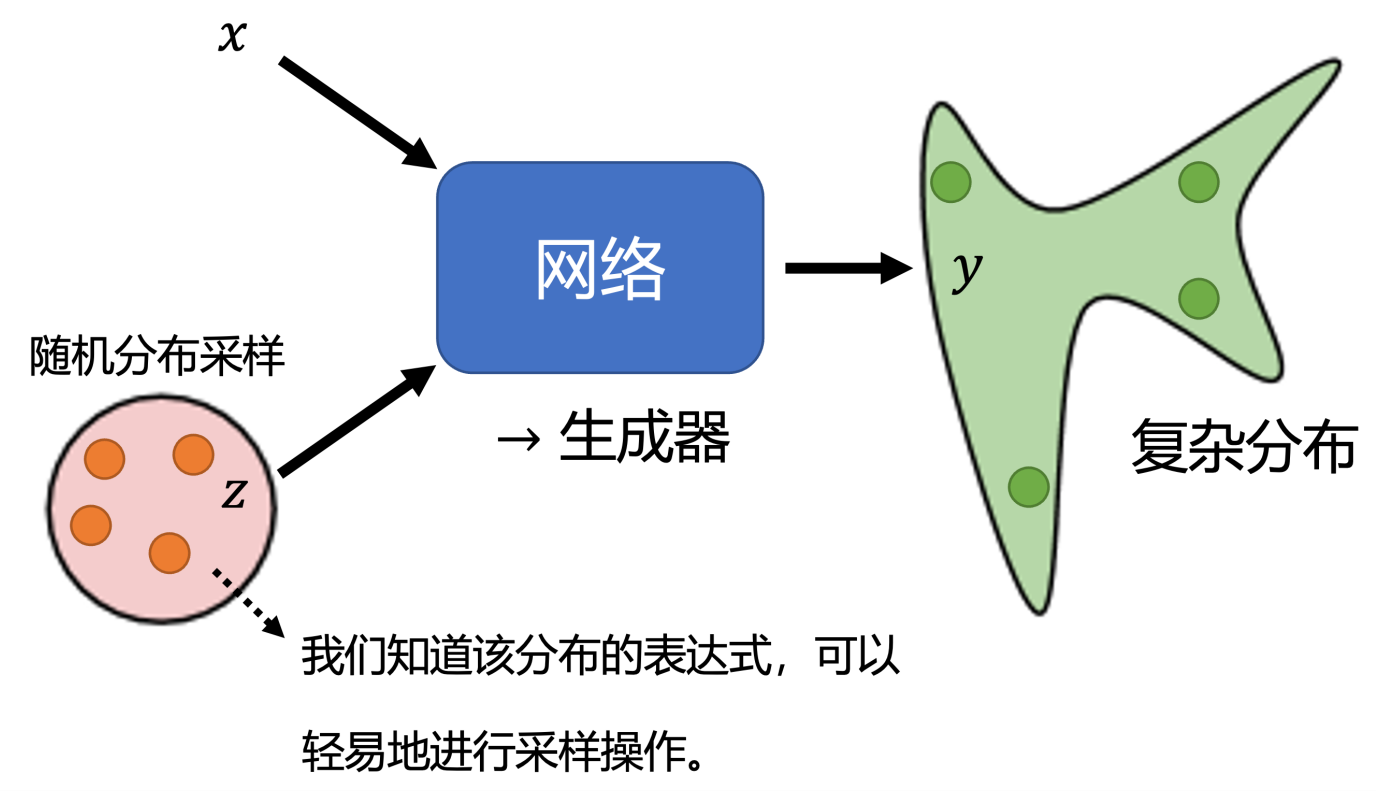
總的操作為:輸入x 并在一個隨機分布(通常用正態分布)獲得采樣值z 一起送到網絡中,然后產生最后的輸出y,這樣就可以實現輸出結果的分布是非固定,不沖突的。
2. GAN的訓練 散度差異
把原始樣本和生成器生成的樣本混在一起,辨別器discriminator需要從中挑出生成器生成的樣本。(就像圖靈測試 一方嘗試裝得像 一方盡量區分) 進行“騙”與“找”的對抗,二者一起越來越強。
原始數據的分布p?和生成數據分布q,生成器要讓這兩個分布盡可能接近,判別器做二分類操作。?
訓練過程:固定生成器G 訓練辨別器D ; 再固定辨別器D 訓練生成器G;二者交替。
需要設置 生成數據q(x) 參考數據p(x) 的差異度量divergence,
相當于最小最大博弈過程,可用Conjugate共軛對偶的知識 設置差異函數。?經典差異函數有KL JS.

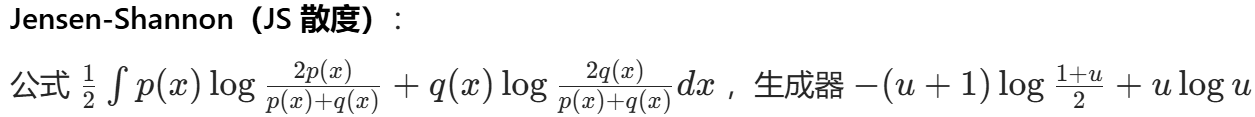
3.WGAN
JS散度的問題:原始 GAN 中,當生成分布與真實分布幾乎沒有重疊時,JS 散度為常數 log 2。這意味著基于 JS 散度構建的判別器損失對于生成器參數梯度幾乎為零,導致生成器難以更新參數。
如果要構建一張人物頭像,對于一組隨機像素,幾乎不可能恰好就是一張人物頭像。
所以人物頭像的分布,在高維的空間中其實是非常狹窄的,就算是這兩個分布實際上很相似,也很難有任何的重疊的部分。
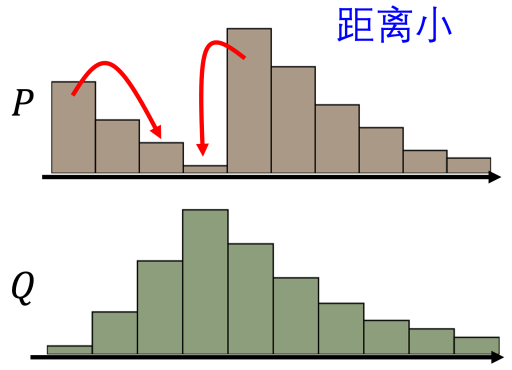
WGAN 使用 Wasserstein 距離(推土機距離),可以衡量兩個分布之間的真實 “距離”,即使兩個分布沒有重疊,仍然能夠提供有意義的梯度信息,使得生成器能夠在訓練初期也能穩定地更新參數,避免了梯度消失問題,從而讓訓練過程更加穩定和可控。
Wasserstein 距離:所有邊緣分布為Pr Pg 的最小聯合分布距離。
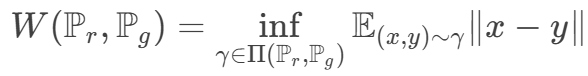
對偶問題為
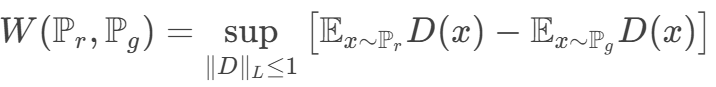
![]()
這個條件限制(可以使用梯度懲罰/譜歸一化的操作) 保證訓練的平滑收斂
![]() ? ?
? ?![]()
本來兩個分布 p和 q 距離非常遙遠,要它一步從開始就直接跳到結尾,這是非常困難的。但是如果用 Wasserstein 距離,可以讓 它們慢慢挪近到一起,最后就可以讓它們對齊在一起。所以在訓練時它可以讓我們的生成器一步一步地變好,而不是一下子就變好。
4.訓練GAN
訓練難點是 需要生成器和判別器同時訓練 互相一步一步一起變強
1. 假設一方突然太強 另一方就會很難進行判別/生成操作 導致訓練停止

2.?文本生成時,生成器輸出的詞是離散的 微小參數變化可能不改變最終輸出詞 導致梯度無法回傳
技巧:1. 生成器與判別器交替訓練幾步 保持二者勢均力敵
2. 標簽平滑:判別器對真實樣本標簽 標1.0會使得判別過于自信 可以縮減改標為0.9
3. 使用?VAE(變分自編碼器)?Flow-based Generative Model 等其它算法
5. 如何客觀評估GAN
主觀上:人眼看這張圖是否合乎常理 像現實中真的物品? ? ? ? 但需要找客觀的評估指標
一個想法:訓練一個圖像的分類系統 會輸出生成的這張圖片是某一類別的概率分布
如果某樣概率特別特別大 那說明就是這個類別;否則四不像 說明生成的質量比較差
比如一個專門生成“辛普森一家”的生成器 生產了下面兩張圖片 哪張圖生成的更符合要求呢?
丟到分類系統里 這個“霸子”概率特別高 說明就是“霸子”;下面這張幾個都不太屬于,則不符合要求

但會出現模式坍塌的問題 多樣性降低 生成數據的分布只是原來真實數據分布的一小部分
比如說我給了它一堆各種品類蘋果的樣本 模式坍塌值生成器只會拼命生成某一類蘋果
但判別器會覺得它生成的圖片都沒問題 但檢測不出多樣性太少
(這會導致看幾張它生成的圖片不覺得有問題,但看多了很多雷同的 就知道生成器有問題)

度量多樣性:看之前分類系統 概率分布的平均分布,如果平均分布很集中說明多樣性比較差;
如果平均分布比較分散 說明有較好的多樣性。
評估的難點:1.同時考慮生成圖片的質量和多樣性? ? ?2.定量評估一個 對于人來說主觀的東西
FID(Frechet Inception Distance)使用預訓練的Inception-v3網絡提取生成圖像和真實圖像的高維特征,然后計算兩個分布之間的Frechet距離(即均值和協方差的差異)。
![]()
距離越小,生成數據越接近真實數據的多樣性
6. 條件型生成(按照要求)
生成器根據條件x 與隨機變量z 生成y
提出文字要求(條件) 可以用 Transformer 把文字轉成向量,再喂給生成器。
普通判別器只看生成的圖片真不真實,條件型判別器則要 "雙查",還要看圖片和條件對不對得上(比如 "紅眼睛" 的條件,不能生成藍眼睛)。
訓練時,可以故意搞些 "錯題"(比如用 "黑頭發" 的文字配 "黃頭發" 的圖)讓判別器練手,確保它能精準判斷 "內容是否符合條件"。
除了文字條件外,條件型生成還能做 "圖片變圖片"(Pix2pix),原理和文字變圖一樣,只是 "條件 x" 從文字換成了圖片。
例如:給張素描,生成實景;給張白天的街景,生成夜景;給張房屋設計圖,生成 3D 效果圖。
7. Cycle GAN(互轉配對)
如果沒有成對的 pariwise訓練數據(比如有一堆真人照片和動漫頭像,卻沒有 "同一個人" 的真人 - 動漫對照圖),怎么讓 AI 把真人轉成動漫風格?
Cycle GAN ?——在沒有 "配對數據" 的情況下,學會兩種風格的轉換。
核心思路:用 "循環一致性" 逼 AI 學規律 就像學翻譯時,把中文譯成英文,再把英文譯回中文,兩次翻譯后要和原文差不多 ——Cycle GAN 用了同樣的 trick: 訓練兩個生成器:G 負責把 "真人域" 轉成 "動漫域",F 負責把 "動漫域" 轉回 "真人域"。
強制要求:一張真人照片經 G 轉成動漫后,再經 F 轉回真人,結果必須和原圖幾乎一樣。
這樣一來,G 不敢亂生成(否則 F 轉不回去),只能學到 "保留原圖特征 + 轉換風格" 的規律(比如把真人的五官保留,換成動漫的線條和色彩)。
Cycle GAN 還能雙向工作:既能把真人轉動漫,也能把動漫轉真人。每個方向都配一個判別器,確保轉換后的圖片符合目標域的風格(比如動漫轉真人時,結果要像真實照片)。
文字風格、語音文字互轉、縮句與擴充也同理可用Cycle GAN操作。
8.?diffusion model 擴散模型
去噪擴散概率模型(Denoising Diffusion Probabilistic Model,DDPM)
“塑像就在石頭里,我只是把不需要的部分去掉”——米開朗基羅
我要生成一張貓的圖像 就是從一張隨機像素點開始,重復用噪聲預測器去噪 越來越接近一只貓。
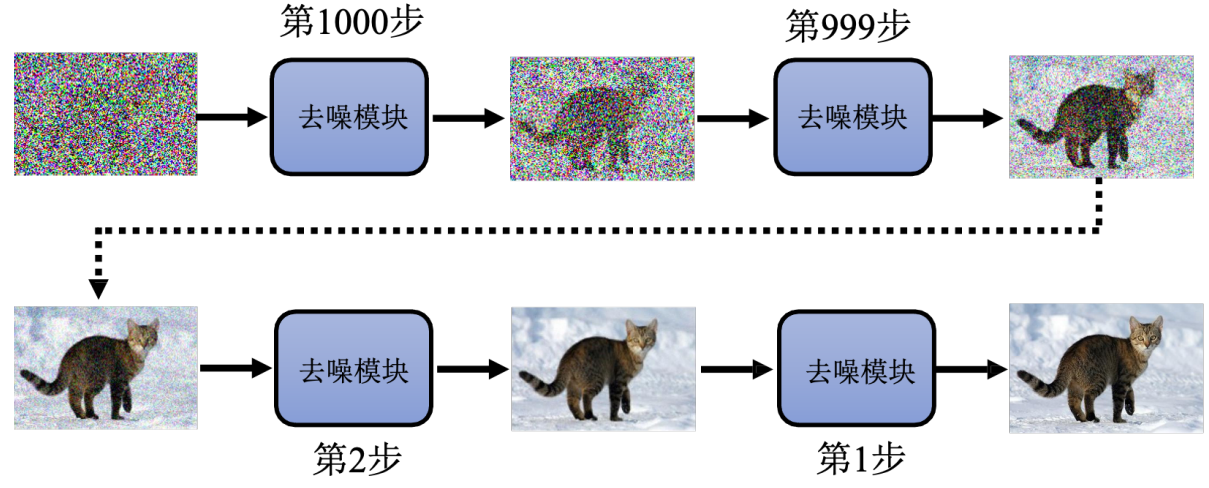
Q:為啥不直接端到端 從噪聲圖直接到結果
A:使用一個噪聲預測器 比端到端產生一個帶噪聲的貓的圖片 簡單的多
訓練數據:第n步去噪應該去成什么樣子呢?
用一只貓的圖像 一步一步加噪聲;第n步去噪的訓練參考 就是這個第n次加噪("前向擴散")
就像老師故意把作業弄臟,讓學生練習 "擦掉臟東西"—— 練熟了,模型自然會在生成時反向操作,從純噪聲里 "擦掉" 所有噪聲
想實現“文生圖” 只需給去噪模塊加個 "文字理解" 功能
目標:噪聲預測器會結合文字,判斷該保留哪些特征(比如 "帽子" 的形狀)、去掉哪些噪聲
訓練時,用 "圖片 + 對應文字" 的數據:先給圖片加噪聲,再讓模型結合文字預測噪聲

-利用ida分析app的so文件中frida檢測函數過檢測)

)

)
)


核心原理與設計精髓)
)








