突破PPO訓練效率瓶頸!字節跳動提出T-PPO,推理LLM訓練速度提升2.5倍
在大語言模型(LLM)通過長思維鏈(CoT)展現出強大推理能力的當下,強化學習(RL)作為關鍵技術卻面臨訓練效率難題。本文將介紹字節跳動提出的Truncated Proximal Policy Optimization(T-PPO),其通過創新方法提升訓練效率,在AIME 2024基準測試中表現亮眼,一起來了解這一重要進展。
論文標題
Truncated Proximal Policy Optimization
來源
arXiv:2506.15050v1 [cs.AI] + https://arxiv.org/abs/2506.15050
文章核心
研究背景
近年來,推理導向的大型語言模型(LLM)如OpenAI的o1、DeepSeekR1和QwQ等,借助擴展的思維鏈(CoT)推理在數學推理、編程和基于代理的任務等復雜領域展現出最先進的性能,而深度強化學習(RL)技術是這些模型提升推理能力的重要支撐。
研究問題
-
PPO的在線策略特性導致訓練效率低下:PPO作為LLM優化的主要RL方法,其在線策略本質限制了訓練效率,在處理長CoT軌跡時,這種限制尤為明顯,會導致大量計算開銷和延長訓練時間。
-
長生成過程中硬件利用率低:完全同步的長生成過程中,資源在等待完整rollout期間經常處于閑置狀態,存在硬件利用率低的固有缺點。
-
離線策略方法存在訓練不穩定問題:雖然離線策略方法訓練效率更高,但通常在策略梯度估計器中存在高方差,導致訓練不穩定和性能下降。
主要貢獻
-
提出EGAE進行優勢估計:開發Extended Generalized Advantage Estimation(EGAE),可從不完整響應中進行優勢估計,同時保持策略學習的完整性,使策略更新能在軌跡完全生成前進行,提高計算資源利用率。
-
設計計算優化機制:創建一種計算優化機制,允許策略和價值模型獨立優化,通過選擇性過濾提示和截斷令牌,減少冗余計算并加速訓練過程,且不犧牲收斂性能。
-
提升訓練效率與性能:在AIME 2024上使用32B基礎模型的實驗表明,T-PPO將推理LLM的訓練效率提高了2.5倍,性能優于現有競爭對手,在AIME’24基準測試中取得62的pass@1分數。

方法論精要
核心算法/框架
T-PPO是PPO的新型擴展,核心在于EGAE和令牌過濾策略。EGAE擴展了傳統的GAE,支持使用部分生成的響應進行策略優化;令牌過濾策略通過截斷生成和選擇性使用令牌,實現策略和價值模型的獨立優化。
(所以EGAE的關鍵是,對于未生成的tokens V ( s l ) = V ( s l ? 1 ) V(s_{l})=V(s_{l-1}) V(sl?)=V(sl?1?),算是一種近似。那 δ t \delta _ t δt?里的 r t r_t rt?是怎么來的?kl?)



關鍵參數設計原理
窗口長度 l l l:用于截斷生成,假設實際最大響應長度 L L L與窗口長度 l l l的比值為 k k k,生成時間和訓練時間大約可節省k倍。
EGAE中的參數 λ λ λ和 γ γ γ: λ λ λ控制未來獎勵對優勢估計的影響, γ γ γ為折扣因子,通過調整它們控制偏差-方差權衡。
裁剪參數:策略的 ? l o w = 0.2 \epsilon_{low}=0.2 ?low?=0.2和 ? h i g h = 0.28 \epsilon_{high}=0.28 ?high?=0.28,價值函數的 ξ l o w = 0.5 \xi_{low}=0.5 ξlow?=0.5和 ξ h i g h = 0.6 \xi_{high}=0.6 ξhigh?=0.6,限制更新幅度以保證穩定性。

創新性技術組合
將EGAE與令牌過濾策略結合,實現不完整軌跡的優勢計算和漸進式策略更新。
策略模型訓練使用當前訓練步驟生成的響應令牌,價值模型訓練使用完成序列的所有生成令牌,且價值模型采用蒙特卡洛訓練范式以確保無偏估計。
采用連續批處理策略,當某些序列達到結束條件時,在下一步插入新提示,未完成樣本保留,保持每步批大小恒定。
實驗驗證方式
數據集:使用美國數學邀請賽(AIME)作為推理問題的代表性基準,訓練集為DAPO-Math-17K,包含過去所有AIME競賽問題及一些人工構造的難題。
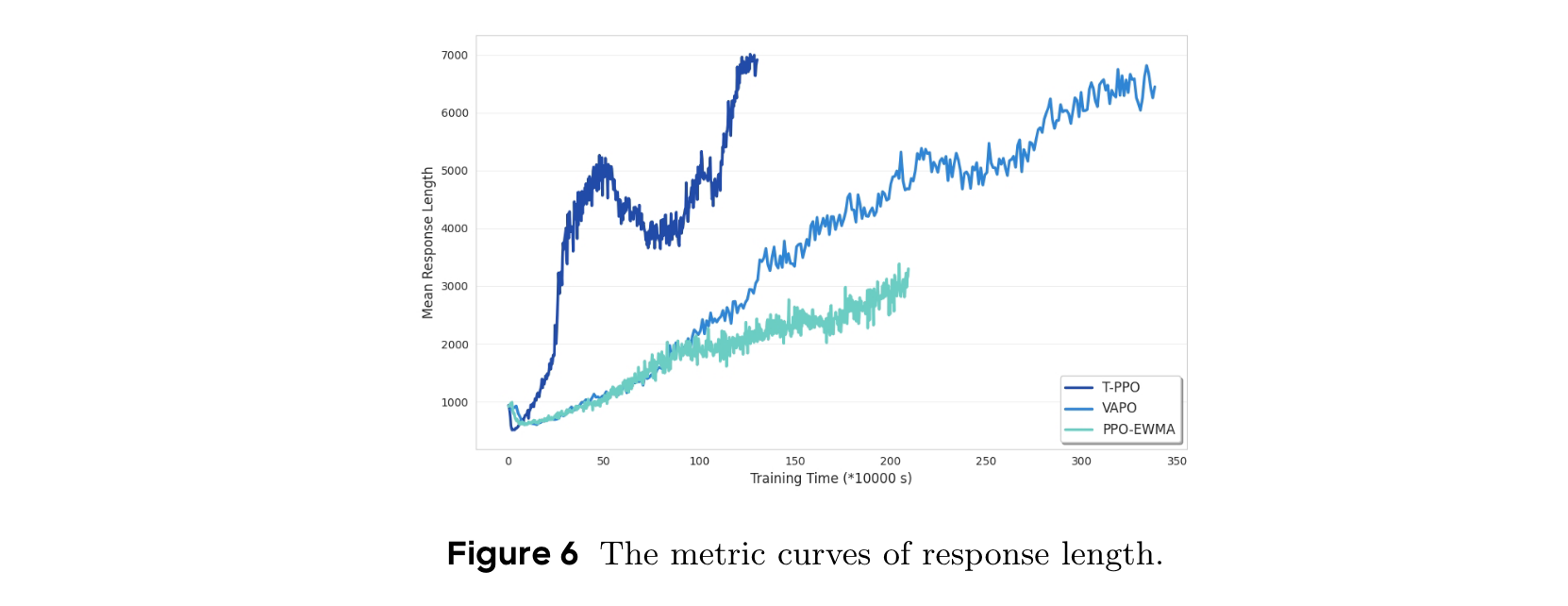
基線方法:對比DeepSeek-R1-Zero-Qwen-32B、DAPO、VAPO、GePPO、PPO-EWMA等,通過AIME 2024的pass@1分數和訓練時間評估性能。

實驗洞察
性能優勢
T-PPO在AIME 24上實現61.88的pass@1分數,超越DeepSeek-R1-Zero-Qwen-32B和現有的最佳異步PPO算法,在相同性能下,與需要20k響應長度的PPO相比,在AIME24基準上wall-clock time減少60%。
效率突破
T-PPO的平均每1000步壁鐘時間與PPO-EWMA相當,遠低于vanillaPPO算法,且收斂步驟(6720步)顯著少于PPO-EWMA(11200步),總運行時間更短;在policy rollout中的計算強度為249 operations/byte,遠高于PPO的84 operations/byte,更好地利用了計算資源。

訓練動態分析
對響應長度的分析表明,其呈現先增加、暫時下降、再恢復并最終穩定的特征,最終穩定的響應長度超過vanillaPPO,說明T-PPO保留并可能增強了推理模型的長度縮放能力,模型在學習過程中不斷完善推理方法。












)


ModelSer--強大的實景三維數據分布式管理平臺)



