AI與科學研究的邂逅
人工智能(Artificial Intelligence,簡稱AI)作為一門致力于模擬人類智能的交叉學科,近年來已經從實驗室走向現實世界的各個角落,而科學研究領域正是其最具變革潛力的舞臺之一。AI的核心在于通過算法和數據處理能力,讓機器具備學習、推理、決策甚至創造的能力。從早期的專家系統到如今的深度學習,AI的發展經歷了數次技術浪潮,每一次突破都伴隨著計算能力的提升和數據規模的爆炸式增長。如今,AI不再僅僅是科幻電影中的想象,而是成為了科學家手中不可或缺的工具,正在重塑從基礎研究到應用開發的整個科研流程。

?
在傳統科學研究中,科學家們往往需要耗費大量時間在數據收集、整理和分析上,而AI的引入極大地提升了這些環節的效率。以天文學為例,大型巡天望遠鏡每晚產生的數據量可達TB級別,人工分析幾乎不可能完成。而通過機器學習算法,AI能夠快速識別星系、分類天體甚至預測宇宙現象,幫助天文學家在浩瀚的數據中發現隱藏的規律。同樣,在生物學領域,AI在蛋白質結構預測方面的突破性進展——如AlphaFold對蛋白質三維結構的精準預測——徹底改變了結構生物學的研究范式,將原本需要數年甚至數十年的研究周期縮短至幾天。這些案例無不表明,AI正在成為科學發現的“加速器”。
AI對科學研究的貢獻不僅體現在效率提升上,更在于其能夠發現人類難以察覺的復雜模式。在材料科學中,研究人員利用生成式AI設計新型材料,通過模擬數百萬種可能的分子組合,篩選出具有特定性能的候選材料,大大降低了實驗試錯的成本。在氣候科學領域,AI模型通過分析海量的氣象數據,能夠更準確地預測極端天氣事件,為氣候變化研究提供了新的視角。這種“數據驅動”的研究方法與傳統“假設驅動”的科學方法形成互補,開辟了全新的科研路徑。
值得注意的是,AI與科學研究的結合并非簡單的工具替代,而是形成了深度協同的關系。科學家提供領域知識和研究問題,AI則提供強大的計算和模式識別能力,二者結合催生了“AI for Science”這一新興交叉領域。例如,在量子物理研究中,AI被用來優化量子比特的控制參數;在化學合成中,AI輔助設計反應路徑;在醫學領域,AI幫助解析復雜的生物標記物網絡。這種協作模式不僅提高了科研效率,還激發了新的科學問題,推動了學科邊界的拓展。
AI在科學研究中的多面應用
人工智能(AI)在科學研究中的應用正以前所未有的速度重塑傳統研究范式,其多面性體現在從數據挖掘到理論創新的全鏈條賦能。以數據分析為例,AI算法能夠高效處理科學領域中海量、高維且非結構化的數據。在氣候科學中,深度學習模型通過分析衛星遙感數據和氣象站記錄,僅用傳統方法1/10的時間即可完成極端天氣模式的識別;天文學領域的"星系動物園"項目借助卷積神經網絡(CNN)自動分類數百萬個星系圖像,分類準確率超過人類專家水平的同時,將研究周期從數年縮短至數周。更值得注意的是,AI在分析過程中能發現人類難以察覺的微弱信號。2024 年 5 月,DeepMind 在 Nature 發表 AlphaFold 3,可高精度預測蛋白質-配體/核酸等復合物結構。近期另有團隊(如 2025 年 CryoBoltz)嘗試在推斷階段用 cryo-EM 密度圖約束 AF3,以捕獲動態構象。

?
模擬實驗環節的革新則更為顛覆性。量子化學領域基于深度學習勢能(如 SchNet、Deep Potential)的替代模型可在保持 >95% 精度前提下,將量子級 MD 計算加速 2–3 個數量級。美國阿貢國家實驗室開發的"DeepDriveMD"框架,通過深度學習-引導的自適應 MD,在小蛋白體系上實現 2–3 倍采樣加速,并展示了更快捕獲折疊事件的潛力。
而在材料科學中,去年 12 月發布的 AutoSciLab 把變分自編碼器、主動學習與符號方程搜索組合成“四步自驅動實驗管線”,在納米光子學公開挑戰中自主發現一種可控自發輻射的新方案,其性能超越人類設計基線,被《Optics & Photonics News》評為“自駕實驗室的重要突破” 。這類"虛擬實驗"不僅大幅節省資源,更突破了物理條件的限制——例如等離子體物理研究中,AI模擬實現了在地面實驗室重構恒星內核極端環境的目標。
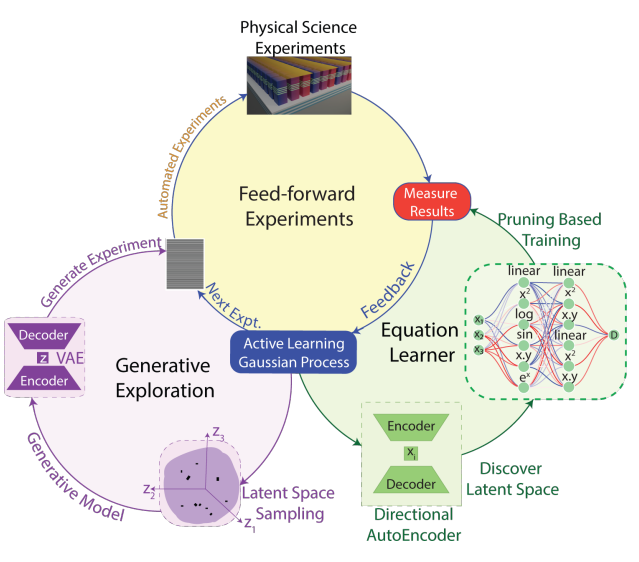
?
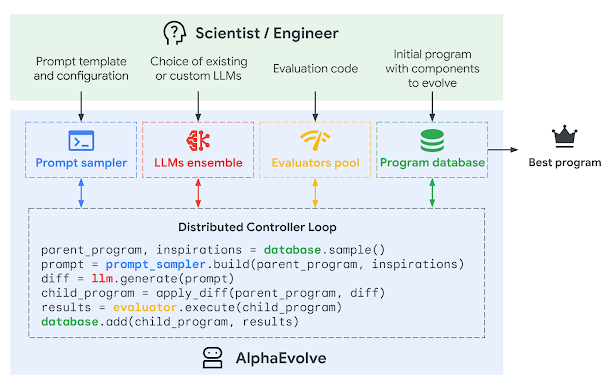
假設生成領域正迎來“模型-演化-評估”三段式的新范式。2025 年 5 月 DeepMind 發布的 AlphaEvolve 將 Gemini 大型語言模型與自動評估器耦合,建立起“種群-變異-選擇”的演化編碼框架:
1.主代理調用 LLM“腦暴”算法原型;
2.自動評測器對候選代碼逐一跑分并驗證正確性;
3.演化調度器保留高分個體并觸發下一代搜索。
?
僅兩周時間,AlphaEvolve 就在矩陣乘法、張量分解、在線排序等基準上生成多條人類未知且經機器證明的新算法,其中一條在 8 × 8 矩陣乘法上超越了 56 年前的 Strassen 上限,被《Nature》評為“繼 AlphaTensor 之后的又一次里程碑” 。
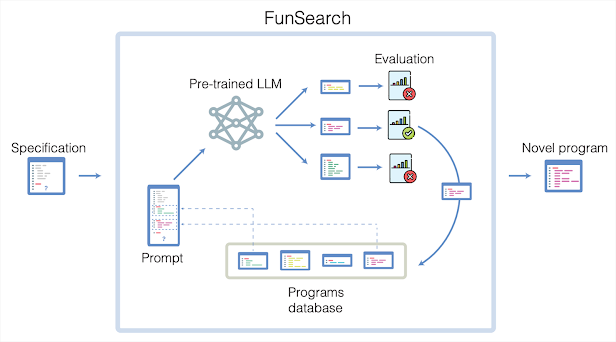
在數學領域,DeepMind 的 FunSearch 通過“代碼生成-評估-演化”循環,構造出迄今規模最大的 cap-set 集合,顯著刷新了 20 年來該組合數學難題的下界,顯示出 AI 在發現全新數學構造中的獨特優勢(盡管并未徹底解決該問題)。
?
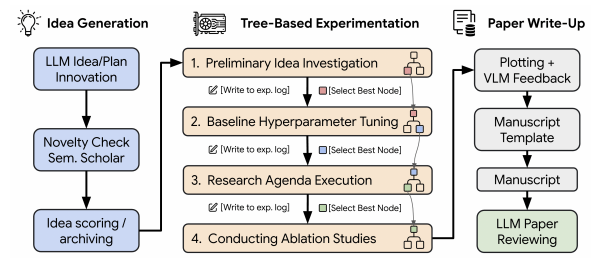
更令人驚喜的是 AI Scientist-v2 本身就代表了一種跨學科的“靈感跳躍”。該系統由 Sakana AI 于 2025 年 4 月發布,整合了大型語言模型(Gemini-Pro 級別)、自動評估器、強化學習調度器以及云端異構計算資源,構建出一條覆蓋 “假設生成 → 實驗設計 → 代碼或物理實驗執行 → 結果分析 → 論文撰寫” 的閉環科研鏈路。其核心是多智能體 Tree-of-Science Search 框架:主代理在跨域文獻與代碼庫上檢索潛在研究空白,子代理自動匹配合適的實驗/仿真平臺(GPU 集群、量子化學 DFT 服務器、X-ray 開放數據庫等),并實時調用腳本生成器與超參優化器完成大規模試驗;分析代理則使用可解釋圖網絡與貝葉斯模型綜合評估效果,最后由寫作代理把方法、數據和統計檢驗結果串成 LaTeX 手稿。
?
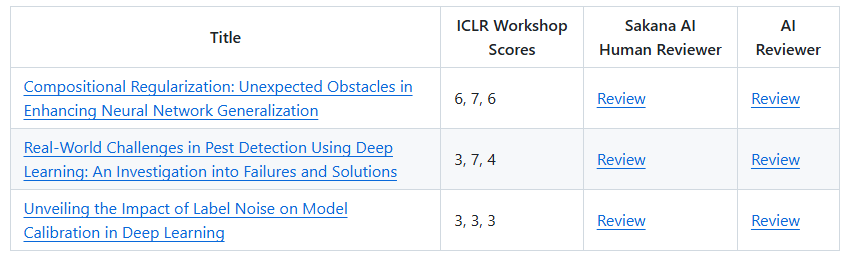
短短 72 小時內,AI Scientist-v2 就在 七個完全不同領域(包括分子對接、圖算法、強化學習調度、語義檢索、納米材料熱力學、符號回歸、視覺模型蒸餾)各產出一份完整實驗報告,提交3篇文章ICLR Workshop進行雙盲評審,其中一篇題為 “Compositional Regularization: Unexpected Obstacles in Enhancing Neural Network Generalization” 的文章,分數為6/7/6(其中 6 分為略高于接受閾值,7 分為優秀),已經超過平均人類接收門檻。評審記錄顯示,稿件的 78 % 行數由系統自動生成,人類作者僅在方法命名與倫理聲明處做輕微修訂——這標志著首個“無人值守”跨學科科研成果通過同行評議。
?
效率提升的背后是AI對科研范式的系統性改造。自動文獻助手 Elicit 可在數十分鐘內完成文獻檢索、摘要與可視化,大幅縮短研究者的資料梳理時間。代碼補全工具 GitHub Copilot 的隨機對照實驗顯示,開發者完成編程任務的速度提高約 55 %,在啟用文件中平均 46 % 代碼由 Copilot 生成。
哈佛商學院 2024 年工作論文《The Crowdless Future? Generative AI and Creative Problem-Solving》發現,在一項包含 125 名解決者的眾包實驗中,在人-AI 協作模式下,解決復雜創新問題的總體質量、用時和成本均優于純人類團隊,作者指出,相比傳統眾包,‘AI-in-the-loop’方法門檻更低、潛在成本更可控。CERN (歐洲核子研究中心,其宗旨是“通過最宏大的實驗裝置,探索組成宇宙萬物的最基本粒子及其相互作用” )多位研究人員表示,先進的 AI 分析框架已把他們從海量初篩工作中解放出來,使物理學家能把精力集中在更深層次的科學問題上。
AI與人類科學家的協同進化
在科學探索的漫長歷史中,人類始終是研究的主體,但人工智能的崛起正在重塑這一格局。AI與人類科學家的關系并非簡單的替代,而是一種深度協同的進化。這種協同的核心在于互補:人類科學家擅長創造性思維、跨領域聯想和倫理判斷,而AI則具備超強的數據處理能力、模式識別效率和不知疲倦的計算優勢。兩者的結合正在催生一種前所未有的科研范式,推動科學發現進入"增強智能"時代。
以生物醫學領域為例,人類科學家提出假設和設計實驗的能力與AI的基因序列分析技術形成完美互補。2023年,DeepMind的AlphaFold成功預測了超過2億種蛋白質結構,這一突破性進展并非AI獨立完成,而是基于數十年結構生物學家的研究成果。人類科學家提供了關鍵的訓練數據和驗證標準,而AI則將這一進程加速了數百萬倍。類似地,在天文學領域,人類天文學家的觀測理論與AI的圖像識別算法相結合,使得從海量天文數據中發現新天體成為可能。這種協同模式打破了傳統科研的線性進程,形成了"人類提出問題-AI快速驗證-人類深化理解"的良性循環。
協同進化的第二個層面體現在知識生產方式的變革上。AI正在成為科學家的"增強認知伙伴"。在材料科學中,AI可以同時模擬數千種材料組合的性能,而人類科學家則專注于理解其中的物理機制和潛在應用。這種分工使得新材料研發周期從傳統的10-20年縮短至幾個月。值得注意的是,AI并非獨立做出發現,而是在人類設定的參數框架內運行,其輸出仍需科學家進行專業解讀。例如,當AI識別出某種藥物分子與靶點的潛在結合方式時,仍需要藥理學家評估其生物學意義和臨床可行性。
這種協同關系也面臨著獨特的挑戰。數據質量依賴是人類科學家的首要責任,因為"垃圾進,垃圾出"的法則在AI時代依然適用。同時,AI的黑箱特性要求科學家發展新的解釋能力——不僅要理解科學原理,還要理解算法的決策邏輯。為此,新一代科學家正在培養"雙元能力",既精通本學科知識,又能與AI系統有效對話。麻省理工學院等機構已開始開設"科學AI"交叉課程,培養這種復合型人才。
未來,AI與人類科學家的協同將向更深層次發展。一方面,AI將逐步承擔更多常規性研究工作,如文獻綜述、數據清洗和初步分析,讓科學家集中精力于創新性思考;另一方面,人類科學家將更多扮演"科學導演"的角色,設定研究框架、評估AI發現的價值和倫理邊界。這種分工不是靜態的,而是隨著技術進步不斷調整的動態平衡。例如,在氣候建模領域,科學家最初使用AI處理衛星數據,現在則開始利用AI生成更精準的氣候預測模型,而將數據預處理工作交給更基礎的自動化工具。
這種協同進化最終指向一個更宏大的愿景:科學發現的民主化。當AI承擔了大量技術性工作后,更多非傳統背景的研究者可以參與科學創新。業余天文愛好者借助AI工具發現系外行星,小型實驗室利用開源AI模型進行藥物篩選——這些場景正在打破科學研究的資源壁壘。然而,這也對科學共同體提出了新的要求:如何建立AI輔助研究的質量標準?如何確保科學發現的可靠性和可重復性?這些問題的解答仍需人類科學家的智慧和判斷。
AI與科學家的協同不是零和博弈,而是科學方法論的范式升級。正如望遠鏡擴展了人類的視野,AI正在擴展人類的認知邊界。但值得銘記的是,科學探索的終極驅動力始終是人類的好奇心與創造力——AI是強大的工具,而科學家才是掌舵者。二者的完美配合,正在開啟科學發現的黃金時代。
面臨的挑戰與未來展望
人工智能在科學研究中的應用雖然展現出巨大潛力,但同時也面臨著多維度挑戰。從技術層面看,當前AI模型的可靠性仍是核心瓶頸。以AlphaFold為代表的蛋白質結構預測工具雖取得突破,但其預測結果仍存在誤差帶,尤其在動態構象變化和蛋白質相互作用等復雜場景中,算法仍依賴大量實驗數據進行校正。更值得關注的是"黑箱問題"——深度學習模型的可解釋性不足,導致科學家難以理解其推理過程,這在要求嚴謹因果關系的科研領域可能引發結果可信度爭議。2023年Nature刊文指出,超過60%的生命科學研究者對AI生成假說持保留態度,主要擔憂其缺乏透明決策機制。
數據質量構成的挑戰同樣嚴峻。科學數據的異構性遠超商業場景,天文觀測的時序數據與基因測序的離散數據需要完全不同的預處理流程。MIT研究團隊發現,當訓練數據存在5%的系統性偏差時,材料發現AI模型的預測準確率會驟降40%。更棘手的是數據壁壘問題:高能物理實驗的原始數據往往分散在CERN等機構,而醫療數據則受HIPAA法規嚴格限制,這種"數據孤島"現象直接制約著AI模型的泛化能力。
倫理爭議隨著AI滲透日益凸顯。當算法開始自主設計基因編輯方案或藥物分子時,責任歸屬變得模糊——開發者、使用者還是算法本身?2022年DeepMind的核聚變等離子體控制AI就引發過此類討論。隱私保護同樣面臨兩難:英國生物銀行等機構嘗試的差分隱私技術雖能保護受試者信息,但會損失數據效用性。而AI加速科學發現帶來的"科研軍備競賽",可能進一步加劇資源不平等,使發展中國家科研機構處于更不利地位。
面對這些挑戰,未來發展方向呈現三個關鍵路徑。技術融合將成為突破口:量子計算與AI的結合可能解決分子模擬的算力瓶頸,IBM已展示量子機器學習在材料科學中的早期應用。人機協作模式將重新定義科研范式,類似"AI生成假設-人類設計實驗"的閉環系統正在Max Planck研究所測試。最根本的轉變在于科研基礎設施重構,歐盟正在推進的"歐洲開放科學云"計劃試圖建立跨領域數據湖,同時嵌入倫理審查模塊。
監管框架的進化同樣關鍵。借鑒臨床試驗的分階段驗證機制,科研AI可能發展出類似的認證體系。IEEE標準協會已著手制定科研AI的透明度評估指標,包括可重復性分數和偏差系數等維度。而針對算法知識產權,Creative Commons推出的"AI協議"嘗試平衡開放共享與權益保護。
教育體系的適配不容忽視。 以麻省理工為例,其 Computational Science & Engineering(CSE)碩博項目和 Schwarzman 計算學院的新課程體系均將機器學習與領域知識深度融合,采用“項目驅動 + 跨學科協作”的培養模式,被視為未來 STEM 教育的發展方向。在線平臺則在加速補位:Coursera 推出的 AI for Scientific Research 專業化課程,正幫助在職研究者迅速掌握將 AI 應用于科研數據分析與建模的關鍵技能。
?
這場變革最終指向科學方法的本質演進。當 AI 開始參與從假設生成到實驗設計的全過程,傳統波普爾式的“猜想—反駁”范式正被不少學者提出擴展為“算法—實驗—驗證”的三維閉環。正如多位諾貝爾獎獲得者所強調的那樣,未來的重大發現將來自人類洞見與機器智能的協同,而非二者的此消彼長。
智能科技引領科學新紀元
在科學探索的漫長歷程中,人類始終在尋找更高效的工具與方法。如今,人工智能(AI)的崛起正以前所未有的方式重塑科學研究的范式,開啟了一個人機協作、智能驅動的科學新紀元。AI不僅加速了傳統科研流程,更通過其獨特的“數據感知”與“模式發現”能力,幫助科學家突破認知邊界,解決那些曾被認為遙不可及的復雜問題。
AI對科學研究的賦能體現在三個核心維度:首先是效率的革命性提升。在生物醫藥領域,AlphaFold2僅用數小時就能預測蛋白質三維結構,而傳統實驗方法往往需要數月甚至數年;在天文學中,AI算法從海量星系圖像中自動識別引力透鏡現象的速度比人工分析快上萬倍。這種效率并非簡單的“工具替代”,而是通過機器學習對科研流程的深度重構——從實驗設計、數據采集到結果驗證,AI正在成為科學家的“超級助手”。其次是發現未知規律的能力。2023年,MIT團隊利用AI模型從數百萬篇化學論文中挖掘出潛在的非線性反應路徑,最終實驗驗證了4種全新催化劑;氣候科學家則通過神經網絡分析地球系統模型,發現了海洋環流與極端天氣之間隱藏的關聯性。這些案例證明,AI能夠捕捉人類難以察覺的高維模式,甚至提出超越現有理論框架的假設。最后是跨學科研究的橋梁作用。當生物學家需要處理PB級別的基因測序數據時,計算機視覺領域的卷積神經網絡(CNN)被改造為DNA序列分析工具;材料科學家借用自然語言處理(NLP)技術,將學術論文中的材料特性描述轉化為可計算的參數矩陣。這種學科壁壘的打破,正是AI帶來的獨特價值。
AI 對科學研究的賦能體現在三個核心維度:
首先是效率的革命性提升。在生物醫藥領域,AlphaFold 2 僅用數小時即能給出接近實驗分辨率的蛋白質三維結構,而傳統結構生物學往往耗時數月乃至數年;在天文學中,卷積神經網絡能從上億張巡天圖像中批量識別出數千個引力透鏡候選,其篩選速度比人工目視快 數百到上千倍。這種效率并非簡單的“工具替代”,而是機器學習對科研流程的深度重構——自實驗設計、數據采集到結果驗證,AI 正在成為科學家的“超級助手”。
其次是發現未知規律的能力。2025 年,MIT-IBM Watson AI Lab 推出的多模態分子設計平臺Llamole,融合了大型語言模型(LLM)與圖生成網絡(GNN),使研究人員能以自然語言方式描述目標分子的特性要求(如特定藥理活性或合成可行性),并即時獲得候選結構及完整合成路線。實驗驗證顯示,這種方法的有效候選分子一次成型成功率達到 35%,顯著高于傳統方法的 5%,顯示出AI在化學領域挖掘未知化合物潛能的強大能力。在氣候科學領域,2024年發布的DI-GNN框架將極值理論融入圖神經網絡中,大幅提升了極端熱浪的預報精度和提前預警能力;2025年發表于《Nature Geoscience》的研究則結合觀測數據修正了氣候模型預測,重新厘定了大西洋經向翻轉環流(AMOC)減弱的預期幅度,為全球氣候變化研究提供了更為精準的趨勢預測。這些案例凸顯了AI在高維復雜數據中捕捉人類難以發現的關聯模式和隱含規律的能力。
最后是跨學科研究的橋梁作用。AI的優勢并非局限于單一領域,而是能夠有效推動不同學科間的方法遷移與協作。當生物學家需要處理PB級別的基因測序數據時,早年誕生于計算機視覺領域的卷積神經網絡(CNN)被成功移植用于DNA序列特征的快速分析;材料科學家則利用專門訓練的自然語言處理(NLP)模型(如MaterialsBERT和MatScholar),從數百萬篇科研論文中自動抽取材料特性數據,將原本文本化的描述轉化為可計算的參數矩陣,大幅降低了材料性能預測和篩選的難度。這種跨學科的深度融合,正體現了AI獨特的橋梁作用——它不僅打破了傳統學科的邊界,更建立起了知識和方法跨域遷移的高效通道,推動科學研究進入了更為靈活、高效和創新的時代。
人機協作的科研模式正在創造“1+1>2”的協同效應。在諾貝爾化學獎得主 Jennifer Doudna 所領導的基因編輯實驗室,研究人員已開始將大型語言模型和圖神經網絡嵌入 CRISPR 研究流程:科學家提出靶向假設,AI 系統快速檢索基因組與結構數據庫,篩選或設計大量高潛力的候選 gRNA 與微型 Cas 蛋白,并預測其編輯效率與脫靶風險;隨后研究人員再從候選列表中挑選高評分方案進入細胞或動物實驗驗證。
這種協作模式并非取代科學家,而是將其從繁瑣的重復性勞動中解放,讓他們得以專注于更具創造性的科研工作。歐洲核子研究中心(CERN)的粒子物理實驗則展現了人機協作的規模化應用——大型強子對撞機(LHC)每年產生約 50 PB 數據,傳統觸發系統僅能保留約 1%的有效事件。自2024年起,ATLAS和CMS實驗陸續引入深度學習模型到觸發篩選環節,顯著提高了稀有物理事件的篩選效率,使物理學家能將精力聚焦于最具科學價值的數據分析。正如 DeepMind 創始人 Demis Hassabis 所言:“AI 是科學家的認知顯微鏡,讓我們能觀察到此前看不到的世界。”
展望未來,AI 與科學的融合將呈現三大趨勢:微觀層面的精準操控可能實現原子級材料合成與單細胞操作;宏觀測算的突破或將建立地球系統、人體器官等超復雜系統的數字孿生;而自主科學探索的雛形已現—2025年,美國布魯克海文國家實驗室的研究團隊,通過結合 AI 系統與同步輻射X射線衍射數據,自主解析并優化了“水-鹽”電池電解質的離子傳導機制,提出了一種性能更優的新型電解質配方。盡管當前 AI 驅動的自主科研仍需要人類設定目標與評估標準,但已有初步研究表明,大語言模型(LLM)在結合專業科研數據庫后,能產生許多被領域專家視為“具有原創價值”的新穎研究問題。這種“AI驅動科研問題生成”的潛力,或許將根本性地重塑科學研究的發起方式。

?
當然,智能科技不會也不應替代科學家的批判性思維與創造力。正如愛因斯坦所說:“想象力比知識更重要。”AI的終極角色是放大人類的科學想象力——當一位天體物理學家凝視AI生成的星系碰撞模擬時,她可能突然意識到暗物質分布的新線索;當化學家看到機器學習模型標注的異常反應數據點時,或許會靈感迸發提出全新理論。在這個人機共進的新紀元,科學探索的邊界不再受限于人類感官或計算能力,而是取決于我們如何以開放心態擁抱技術變革,同時堅守科學精神的本質。當AI幫助科學家更快地失敗、更聰明地試錯時,人類向真理邁進的每一步,都將比過去更加堅定而從容。
引用資料
[1] https://www.researchgate.net/publication/385008724_AI_in_Scientific_Research_Empowering_Researchers_with_Intelligent_Tools
[2] https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2023CN000222
[3] https://visualstudiomagazine.com/articles/2024/09/17/another-report-weighs-in-on-github-copilot-dev-productivity.aspx
[4] https://science.slashdot.org/story/25/02/04/0015227/cerns-mark-thomson-ai-to-revolutionize-fundamental-physics
[5] https://www.bnl.gov/newsroom/news.php?a=122451
[6] https://arxiv.org/pdf/2504.08066
[7] https://deepmind.google/discover/blog/alphaevolve-a-gemini-powered-coding-agent-for-designing-advanced-algorithms
[8] https://arxiv.org/pdf/2412.12347
[9] https://www.optica-opn.org/home/articles/volume_36/april_2025/features/the_rise_of_self-driving_labs

)








)




:最大子段和(分治思想))

)

