目錄
- 一、前言
- 二、結構
- 1. hmap(map) 結構
- 2. bmap(buckets) 結構
- 三、哈希沖突
- 四、負載因子
- 五、哈希函數
- 六、擴容
- 增量擴容
- 等量擴容
一、前言
在現代編程語言中,map 是一種非常重要的數據結構,廣泛用于存儲和快速查找鍵值對。Go 語言中的 map 是一種高效且靈活的數據結構,它不僅提供了基本的鍵值存儲功能,還在并發場景下具備了出色的性能表現
現在探討 Go 語言中 map 的實現原理,分析它的擴容策略、哈希計算方式等細節
二、結構
我對 map 的理解就是
一個指針,指向一個數組
這個數組呢,存儲的是結構體
這個結構體里面呢,有幾個元素
也就是,一個指向哈希桶數組的指針
一個哈希桶可以存儲多個鍵值對
這張圖現在可能不理解,因為還沒有了解 map 的結構,沒關系,看了后面再有這張圖會好理解很多
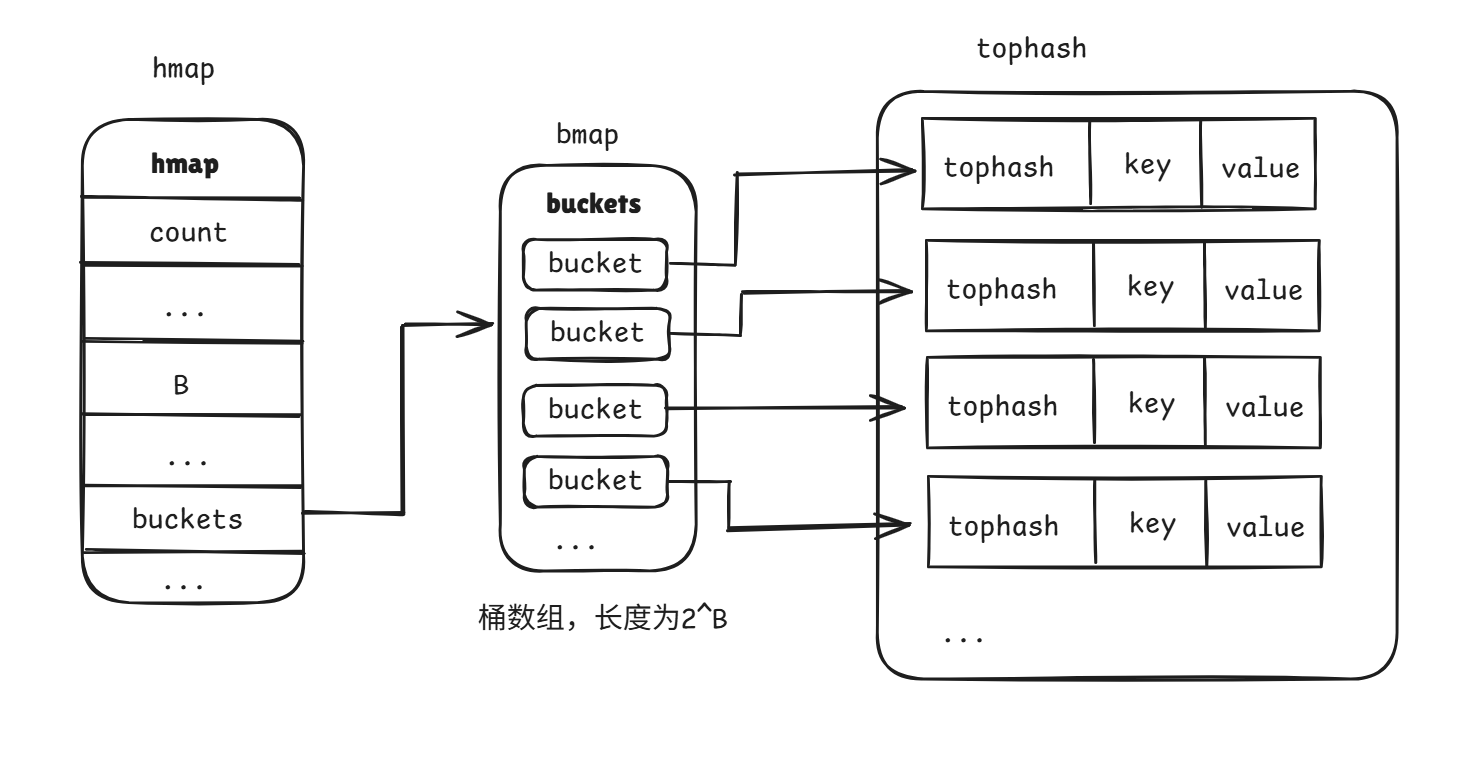
1. hmap(map) 結構
go 中的 map 就是 hmap 結構體,源碼在 runtime/map.go:hmap 中
type hmap struct {// Note: the format of the hmap is also encoded in cmd/compile/internal/reflectdata/reflect.go.// Make sure this stays in sync with the compiler's definition.count int // # live cells == size of map. Must be first (used by len() builtin)flags uint8B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for detailshash0 uint32 // hash seedbuckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growingnevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)clearSeq uint64extra *mapextra // optional fields
}
一些字段的解釋(有幾個字段 只看干巴巴的文字解釋沒有具體用法不太好理解,到這里理解count、B、buckets 就可以,不理解的沒必要死磕,可以先跳過去,用到的時候再來看,不影響閱讀):
-
count:表示 hamp 中的元素數量,就是 len(map) -
flags,hmap:的標志位,用于表示 hmap 處于什么狀態,有以下幾種可能。
const (iterator = 1 // 迭代器正在使用桶oldIterator = 2 // 迭代器正在使用舊桶hashWriting = 4 // 一個協程正在寫入hmapsameSizeGrow = 8 // 正在等量擴容
)
-
B:map中的哈希桶的數量為1 << B (2^B 2的B次方)
這里 2^B 和 count 有一定關系,但不相等,可以理解為:count代表的是所有桶中存儲的所有鍵值對的個數,而2^B僅僅代表哈希桶的數量,而且一個哈希桶里面不只有一個鍵值對 -
noverflow: map 中溢出桶的大致數量 -
hash0: 哈希種子,在 hmap 被創建時指定,用于計算哈希值(key) -
buckets:指向哈希桶數組的指針 -
oldbuckets: 存放 hmap 在擴容前哈希桶數組的指針 -
extra: 存放著 hmap 中的溢出桶,溢出桶指的是就是當前桶已經滿了,創建新的桶來存放元素,新創建的桶就是溢出桶
2. bmap(buckets) 結構
hmap 中的 buckets 也就是桶切片指針,go 中的 buckets 就是 bmap 結構體,定義為:
type bmap struct {tophash [abi.OldMapBucketCount]uint8
}
bmap 中只有一個 tophash 字段(其實還有很多注釋,這里都刪掉了)
tophash 存儲的是每個鍵的哈希值的高 8 位。
當查找某個鍵時,通過只比較高 8 位來過濾掉一些鍵,避免了每次查找時都進行完整的哈希值比較,由此:它可以快速比較鍵值對,以便在哈希表中進行查找。
實際上,由于 map 可以存儲各種類型的鍵值對,不同的類型占用不同的內存空間,所以需要在編譯時根據類型來推導占用的內存空間,并且 map 的 key 必須是可比較的,所以也會判斷 key 是否滿足要求,由此可以推斷 bmap 中不止有這一個字段
所以實際上,bmap的結構如下,不過這些字段對我們是不可見的,go 在實際操作中是通過移動 unsafe 指針來進行訪問
type bmap struct {tophash [BUCKETSIZE]uint8keys [BUCKETSIZE]keyTypeelems [BUCKETSIZE]elemTypeoverflow *bucket
}
其中的一些解釋如下
tophash,存放每一個鍵的高八位值,對于一個 tophash 的元素而言,有下面幾種特殊的值
const (emptyRest = 0 // 當前元素是空的,并且該元素后面也沒有可用的鍵值了emptyOne = 1 // 當前元素是空的,但是該元素后面有可用的鍵值。evacuatedX = 2 // 擴容時出現,只能出現在oldbuckets中,表示當前元素被搬遷到了新哈希桶數組的上半區evacuatedY = 3 // 擴容時出現只能出現在oldbuckets中,表示當前元素被搬遷到了新哈希桶數組的下半區evacuatedEmpty = 4 // 擴容時出現,元素本身就是空的,在搬遷時被標記minTopHash = 5 // 對于一個正常的鍵值來說tophash的最小值
)
只要是tophash[i]的值大于minTophash的值,就說明對應下標存在正常的鍵值。
keys:存儲 key
elems:存儲 value
overflow:指向溢出桶的指針
三、哈希沖突
哈希沖突 并不陌生,在數據結構哈希表里面就有了哈希沖突這個定義
說白了就是有不止一個鍵 (k1, k2, …),計算出它們的哈希值相同,這些鍵就是發生了沖突
我們使用拉鏈法處理沖突,和數據結構中哈希桶處理方法一樣。就是你有一個桶,這個桶里原本已經有元素了,但是又有其他的鍵映射到這個桶里面,那就把這個新的元素和舊元素鏈起來,我認為理解成把元素一個一個掛在哈希桶下面比較好理解
當然了,這種處理方法是有缺陷的
數據量少的時候,假設有 4 個哈希桶,有 12 個元素,那么平均就是一個桶里存儲 3 個元素,查找一個鍵,計算出這個鍵對應的哈希值,就知道了這個元素在哪個桶,再遍歷這個桶,最壞就是要查找的鍵掛在桶的最下面,那遍歷三次就可以找到了。所以一個桶里面存儲的數據少的時候,時間復雜度就是常量級別的
但是當數據量很大很大的時候,有 100億, 這時候如果有 4 個桶, 一個桶里面平均存儲 25億 個元素,再去查找元素,再去遍歷桶,那就很慢很慢了
所以哈希桶下面可以掛元素,但是這不是無限的,規定不超過八個
如果超過八個了怎么辦
那就會創建一個新的桶來存放這些鍵,這個桶就叫 溢出桶。其實就是原來的桶放不下了,元素溢出到這個桶來了,創建完畢后,原來的哈希桶會有一個指針指向這個溢出桶,那原來的桶和溢出桶連起來就形成了一個 bmap 鏈表
超過八個創建溢出桶的情況:
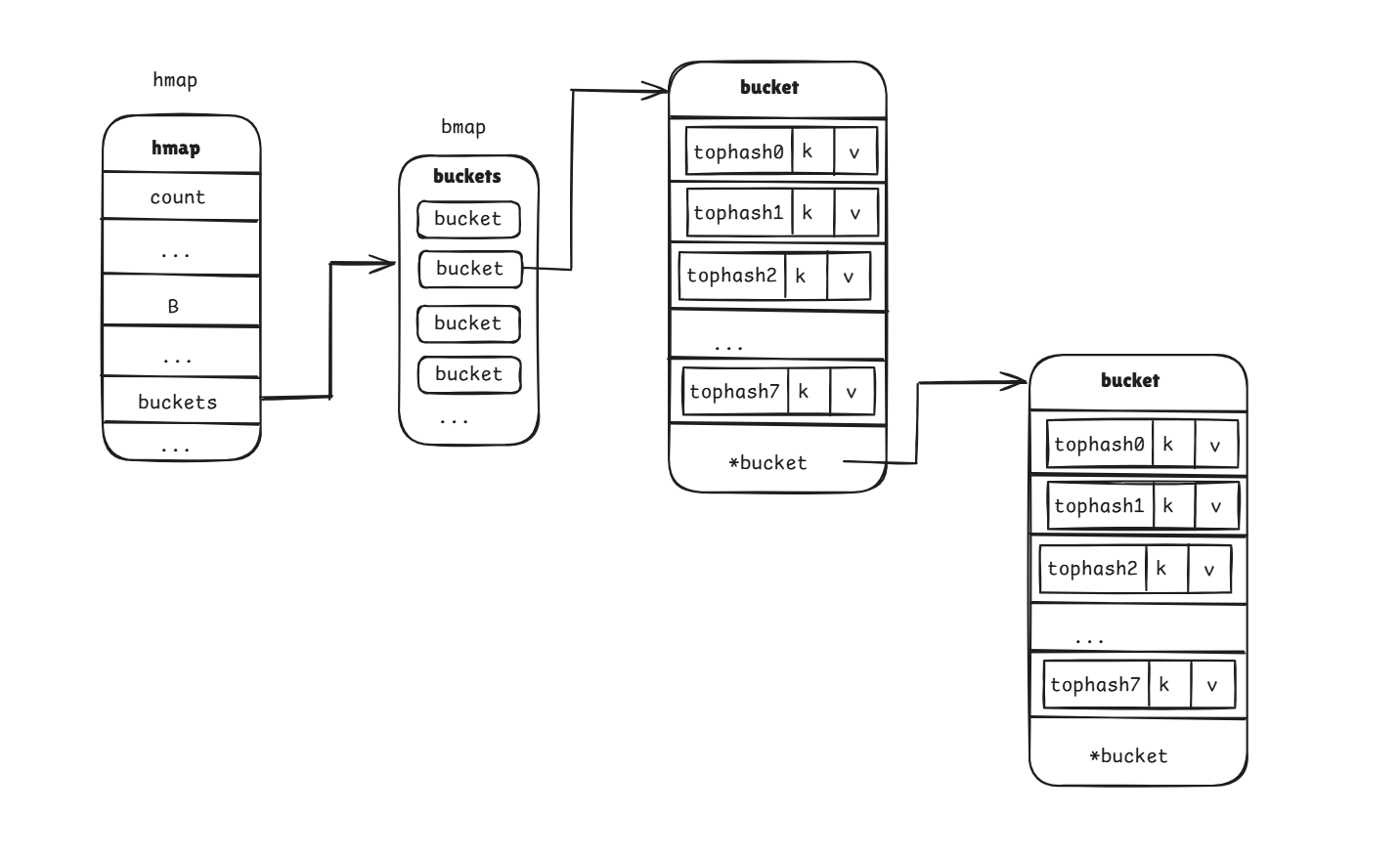
實際上溢出的桶是:
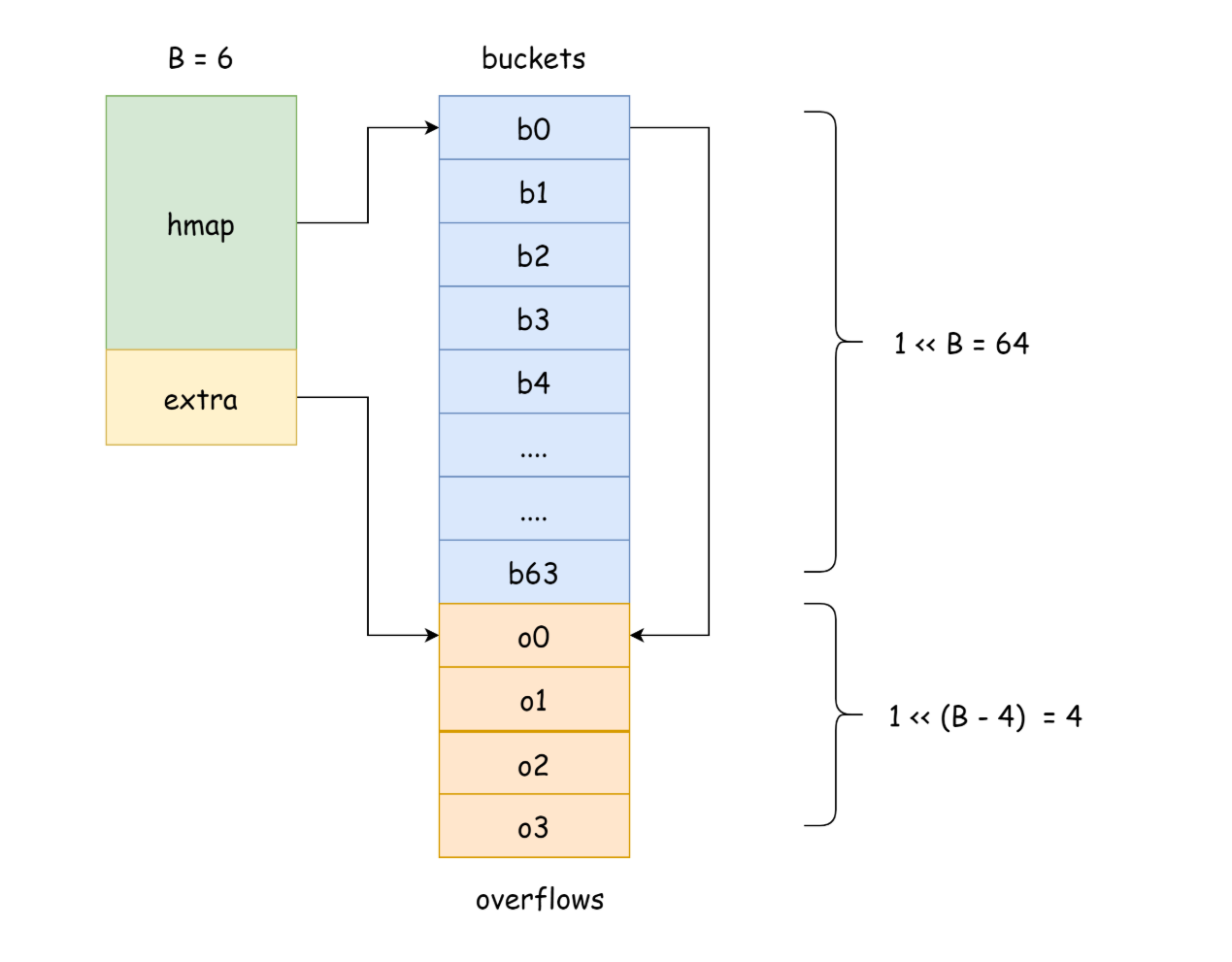
如果哈希沖突很多很多,溢出桶也會越來越多,那么在讀寫哈希表時,就需要遍歷更多的溢出桶鏈表,才能找到指定的位置,所以性能就越差。為了改善這種情況,應該增加buckets桶的數量,也就是 擴容
那什么時候進行擴容呢,總需要一個標準吧
所以引出了 負載因子 loadfactor
四、負載因子
負載因子 = 元素個數 ÷ 桶的個數,意思就是 實際的元素個數 / 哈希桶總個數
loadfactor := len(elems) / len(buckets)
負載因子越大,說明實際有的元素個數越多,也就是哈希沖突越大
負載因子越小,說明實際有的元素比較少,也就是說有更多的桶沒有用到,所以 hmap 的內存利用率低,占用的內存就越大
擴容的條件:
- 負載因子超過閾值 bucketCnt*13/16,也就是6.5 (bucketCnt 是每個哈希桶最多存儲的鍵值對個數,也就是 8 )
- 溢出桶數量過多
overLoadFactor 函數是 Go 語言中用于計算和檢查 map 的負載因子的函數,判斷負載因子是否超過閾值
func overLoadFactor(count int, B uint8) bool {return count > bucketCnt && uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
}
這段代碼返回一個 bool 值,負載因子超過閾值返回 true,否則返回false
根據這段代碼也可以看出來,在滿足這兩個條件下負載因子超過閾值:
一是元素個數(count)大于桶內最多元素個數(bucketCnt),也就是語句
count > bucketCnt
二是負載因子大于閾值,也就是語句uintptr(count) > loadFactorNum*(bucketShift(B)/loadFactorDen)
解釋:其中 loadFactorNum 和 loadFactorDen 都是一個常數,bucketshift 是計算1 << B,并且已知loadFactorNum = (bucketCnt * 13 / 16) * loadFactorDen
,將 loadFactorNum 代入這個式子,最后化簡得到uintptr(count) / 1 << B > (bucketCnt * 13 / 16)
其中(bucketCnt * 13 / 16)值為 6.5,1 << B就是哈希桶的數量,count 是元素個數
五、哈希函數
f32hash 函數是 Go 語言中用于計算 float32 類型數據的哈希值的函數,位于 runtime/alg.go 文件中,作用是根據 float32 數據的內存內容計算一個哈希值。在計算哈希時,它會根據浮點數的值處理 +0、-0 和 NaN 等特殊情況。最終會返回一個基于內存的哈希值。
func f32hash(p unsafe.Pointer, h uintptr) uintptr {f := *(*float32)(p)switch {case f == 0:return c1 * (c0 ^ h) // +0, -0case f != f:return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaNdefault:return memhash(p, h, 4)}
}
各個部分解釋
1.
p unsafe.Pointer 和 h uintptr
p 是一個指向內存的指針,它指向 float32 類型的數據
h 是一個哈希種子,通常用于哈希計算的初始值,可能來自于現有的計算或隨機值
f := *(*float32)(p):
這行代碼將 unsafe.Pointer 轉換為 float32 類型
-
switch 語句的三個分支:
前面提到了,它會根據浮點數的值處理 +0、-0 和 NaN 等特殊情況,最終會返回一個基于內存的哈希值。switch 語句就是做這個工作的
- 處理 +0 和 -0
case f == 0:return c1 * (c0 ^ h) // +0, -0
f == 0 會處理 float32 類型的 +0 和 -0(它們在內存中是相同的)。為了確保它們產生不同的哈希值(避免沖突),這個條件會根據 h 和常數 c0、c1 計算哈希
- 處理 NaN
case f != f:return c1 * (c0 ^ h ^ uintptr(fastrand())) // any kind of NaN
f != f 是一個典型的用來檢測 NaN(Not a Number,非數字)的技巧,因為 NaN 是唯一一個不等于自身的浮點數。這個分支處理 NaN 值的情況,并通過引入 fastrand()(一個生成隨機數的函數)來增強哈希的隨機性。
- 默認情況(普通情況)
default:return memhash(p, h, 4) // 普通情況,計算基于內存的哈希值
如果 f 既不是 0 也不是 NaN,那么就會調用 memhash 函數來計算該 float32 值的哈希。memhash 通過讀取 f 在內存中的實際內容來計算哈希值。
- memhash 函數
memhash 函數通常用于基于內存內容來計算哈希值。它的計算是基于內存塊的字節內容,因此不同內存位置的相同數據可能會產生不同的哈希值。4 表示這里的內存塊是 4 字節(即 float32 類型的大小)。
??
為什么要處理 0 ?
在浮點數中,+0 和 -0 是不同的值,但是它們在比較時是相等的。為了區分它們,Go 可能會采用不同的哈希策略
這里使用 c1 * (c0 ^ h) 的方式對它們進行哈希計算,防止它們在哈希表中發生沖突
??
為什么 map 哈希計算基于內存?
Go 中的 map 哈希計算并不僅僅依賴于數據的類型,還基于數據的內存布局。這是為了保證哈希計算的高效性和減少哈希沖突。通過直接操作內存地址和數據內容,可以更加高效地計算哈希值,減少對類型的依賴。尤其是在 map 中,鍵的哈希值越唯一,查找和插入操作的性能越高
為什么內存中的哈希值不能持久化?
-
內存不一致:
哈希值是根據數據在內存中的表示來計算的。由于 Go 的內存布局可能在不同的運行中不同(例如由于編譯器優化或操作系統調度等原因),內存地址的分布在不同的運行時是不一致的。因此,基于內存的哈希值不適合持久化,因為它在每次程序執行時都會有所變化。
-
運行時依賴:
map 中的哈希值依賴于數據在內存中的位置或布局,這些信息只有在程序運行時才可用,無法在磁盤上持久保存。因此,每次程序運行時,哈希值的計算都會重新基于內存進行,而不能依賴于之前保存的哈希值。
在該文件中還有一個名為 typehash 的函數,它是一個通用的哈希計算方法,依據類型信息和數據本身來計算哈希值
func typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr
解釋:
t *_type : 這是類型信息,指向存儲類型信息的結構體 _type。_type 是 Go 內部用于表示類型的結構體,包含了類型的詳細信息(如類型大小、種類、結構體字段等)。
p unsafe.Pointer : 這是指向實際數據的指針。數據的類型會根據 t 來確定。
h uintptr : 這是哈希計算的種子,用于初始化哈希計算。
typehash 函數通過對類型信息 ( t ) 和數據本身 ( p ) 進行處理,返回一個最終的哈希值。由于不同類型的數據可能需要不同的哈希計算策略,typehash 會根據類型的不同來調整計算方法
通用性和速度
typehash 相比于其他類型特定的哈希函數(如 f32hash),要慢一些,因為它要處理不同類型的情況。比如它需要根據類型的結構、字段以及其他特征來計算哈希值,因此它的計算會更復雜一些,但卻非常通用,能處理各種類型的數據
reflect_typehash 函數
在 Go 中,reflect_typehash 是一個使用 typehash 的輔助函數,主要用于通過反射機制來獲取對象的哈希值。
//go:linkname reflect_typehash reflect.typehash
func reflect_typehash(t *_type, p unsafe.Pointer, h uintptr) uintptr {return typehash(t, p, h)
}
typehash 的實現會根據傳入的數據類型來采取不同的計算策略。例如:
-
基礎類型(如整數、浮點數):直接對數據本身進行哈希計算。
-
結構體類型:對結構體中的各個字段進行哈希計算,并合并所有字段的哈希值。
-
數組、切片:對數組或切片中的元素進行哈希計算。
-
接口類型:由于接口在 Go 中由類型和數據兩個部分組成,typehash 需要同時考慮這兩個部分來計算哈希值。
為什么 typehash 不用于 map 計算?
map 在 Go 中是一個特殊的類型,它具有高效的哈希計算過程。map 使用基于內存地址的哈希計算方法(如 memhash)來確保高效的哈希操作,特別是在內存分布和性能優化方面。相比之下,typehash 的計算方式更加通用,但也更慢。對于 map 來說,它并不需要處理如此復雜的類型,因此采用了更加高效、類型特定的哈希方法
六、擴容
前面已經提到了,擴容有兩個條件:
- 負載因子超過 6.5
- 溢出桶的數量過多
判斷負載因子是否超過閾值的函數是overLoadFactor,前面負載因子部分已經提到過
判斷溢出桶的數量是否過多的函數是runtime.tooManyOverflowBuckets,代碼如下
func tooManyOverflowBuckets(noverflow uint16, B uint8) bool {if B > 15 {B = 15}return noverflow >= uint16(1)<<(B&15)
}
解釋:
noverflow uint16 :無符號 16 位整數,表示當前哈希表中溢出桶的數量
B uint8:無符號 8 位整數,表示哈希表中哈希桶的數量的大小( 1 << B)
返回值:返回一個布爾值(bool),如果當前的溢出桶數量 noverflow 超過了預期的閾值,返回 true,否則返回 false
return noverflow >= uint16(1)<<(B&15):判斷當前的溢出桶數量是否超出閾值
uint16(1) << (B & 15):B & 15:通過 B & 15,將 B 限制在一個 4 位二進制數范圍內(即 0 到 15)。這等同于取 B 的低 4 位。如果 B 的值大于 15,這個操作會確保計算結果不會超出 2^15
判斷是否需要擴容的代碼如下
if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {hashGrow(t, h)goto again // Growing the table invalidates everything, so try again
}
!h.growing():檢查哈希表是否沒有處于擴容狀態。如果 growing() 返回 false,說明當前哈希表沒有擴容
可以看到的就是這三個條件限制
- 當前不能正在擴容
- 負載因子小于 6.5
- 溢出桶數量不能過多
負責擴容的函數是runtime.hashGrow:
func hashGrow(t *maptype, h *hmap)
根據觸發擴容的條件不同,擴容的類型也不同,分為兩種:
- 增量擴容
- 等量擴容
增量擴容
當負載因子很大時,哈希沖突比較嚴重,就會形成很多溢出桶
這時候再去查找一個元素,就要遍歷更多的溢出桶鏈表,導致 map 讀寫性能下降
為什么溢出桶過多會導致 map 讀寫性能下降呢?
遍歷的時間復雜度是O(n),哈希表查找的時間復雜度主要取決于哈希值的計算時間和遍歷的時間,若遍歷的時間遠小于計算哈希的時間,查找的時間復雜度近似為O(1) 。但如果哈希沖突比較嚴重,過多 key 都被分到同一個哈希桶,溢出桶鏈表過長導致遍歷時間增大,就會導致查找的時間增大,而增刪改查都需要先進性查找操作,因而導致性能下降
這種情況使用 增量擴容:新增更多的哈希桶,避免形成過長的溢出桶鏈表
增量擴容意味著 map 在擴容時,并不是立即將所有元素遷移到新的桶中,而是逐步進行遷移,隨著操作的進行,逐漸完成遷移。這樣做的好處是可以減少擴容過程中對性能的影響,避免一次性擴容帶來的性能瓶頸
增量擴容的核心機制
-
老桶數組(oldbuckets):hmap 中的 oldBuckets 指向原來的哈希桶數組,表示這是舊數據
-
創建新桶:創建更大容量的哈希桶數組,讓 hmap 中的 buckets 指向新的哈希桶數組
-
元素遷移:遷移的過程是增量的,即在每次對 map 進行操作(插入、刪除等)時,都會將一些原本應該遷移的元素從 oldbuckets 遷移到新桶數組中。直到所有元素都完成遷移,擴容過程才算完成。擴容完成后,舊桶的內存被釋放
-
增量遷移的實現:這種增量遷移的方式通過一個標志 oldbuckets 來標識 map 是否正在進行擴容。如果 oldbuckets 不為 nil,則說明擴容正在進行中。如果為 nil,則說明擴容已經完成
等量擴容
前面提到過,等量擴容的觸發條件是溢出桶數量過多
假如 map 先是添加了大量的元素,導致溢出桶增多,然后又大量刪除元素,這樣可能會導致數據分布不均勻,也就是有的桶有很多元素,有的桶元素很少甚至是空的,那也有可能導致很多的溢出桶都是空的,但是又占用了不少內存
這種情況使用 等量擴容:創建一個同等容量的新 map,重新分配一次哈希桶
所以所謂等量擴容,實際上并不是擴大容量,buckets 數量不變,只是將所有元素二次分配使得數據分布更均勻





-----刪除鏈表中指定值的節點)






自動曝光中Lv值的計算方式實現猜想)
![[docker]鏡像操作:關于docker pull、save、load一些疑惑解答](http://pic.xiahunao.cn/[docker]鏡像操作:關于docker pull、save、load一些疑惑解答)





