事務
事務:在多個操作合在一起視為一個整體。要么就不做、要么就做完。
事務應該滿足ACID
- A : 原子性。不可分割。
- C : 一致性。追求的目標,在開始到結束沒有發生預定外的情況。
- I : 隔離性。不同的事務是獨立的。
- D : 持久性。系統崩潰,數據依然要存在。
AID是為了C。
我們之前一直在使用事務
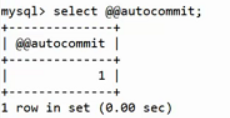
@@autocommit 為1,說明啟用了自動提交屬性,每個SQL指令都單獨看成是一個事務。
在開兩個命令窗口對同一個表進行一次操作,不會出現一個進行到一半另一個窗口指令執行的現象,因為每個SQL指令都單獨看為一個事務。
讓多個SQL指令合成一個事務
begin;/start transaction;? ?開啟事務
寫各種指令
commit;事務完成
rollback;事務回滾(放棄該事務前面所作的所有操作)
開啟事務后,一定要以事務完成或者事務回滾結束本次事務。
用了begin;后面的每單獨一條指令不是事務(非原子操作)。
接下來演示事務回滾與事務完成
準備一張表:
?
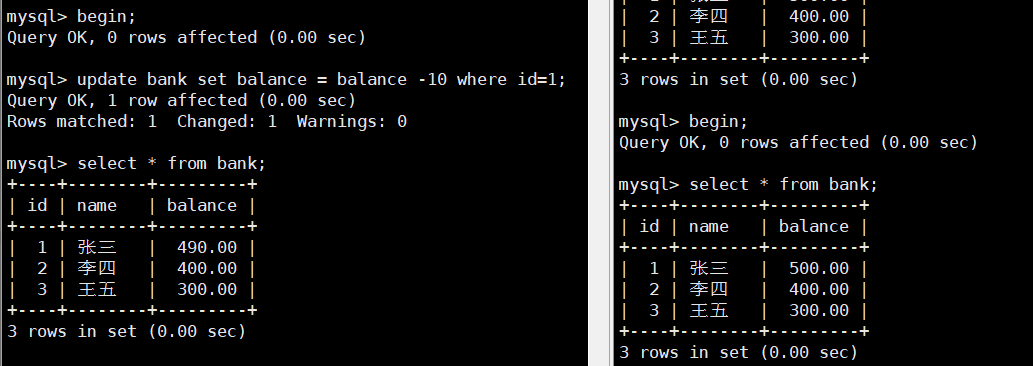
事務回滾
?開兩個窗口,在左窗口begin;后執行更改數據,右窗口此時查看的是舊數據。
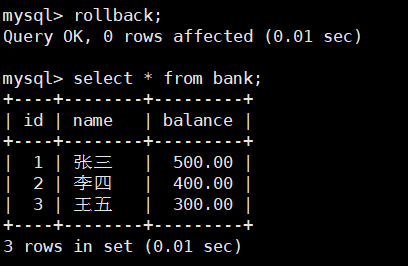
隨后左窗口執行rollback;事務回滾到begin;現在數據沒有進行更改。
事務完成
同樣使用兩個窗口
在左窗口執行begin;后,執行數據更改,此時右窗口查看到的依然是舊數據。
左窗口隨后執行commit;完成事務,這時候右窗口再進行查看,查看到的為更改完成后的數據。?
事務的隔離性
不同的事務彼此之間是獨立的
多個事務同時執行,有可能會操作同一份數據,會產生競爭條件。若是像進程線程一樣采用鎖,會導致粒度過大,因為數據庫的數據存在磁盤上,對鎖的操作時間過長。在數據庫領域,訪問共享資源(磁盤數據)的時間很長,我們需要對鎖機制做更加精細的管理,我們希望盡量讓同時運行的時間越長越好。
首先需要做的是對并發帶來的問題,按嚴重程度進行分級。
并發帶來的問題
最嚴重 --> 最不嚴重問題:臟寫 -> 臟讀 ->? 不可重復讀? ->? 幻讀
臟寫
?對于t2來說沒有實現隔離性,在任何情況下,臟寫都是不可接受的。
解決方案:讓第二次write操作會阻塞,直到第一次事務結束。

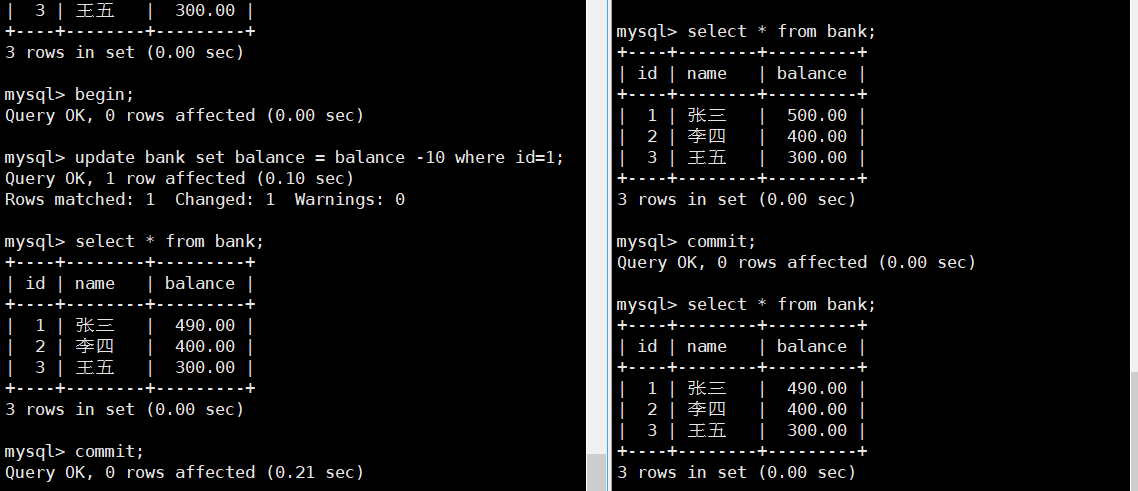
臟讀
整個過程順利完成了,但是在事務進行中某個過程t2讀出的數據不滿足一致性。 在一致性要求不高的場景下是可以接受的。
解決問題:只能讀到已經提交的舊數據,不能讀到最新還未提交的數據。
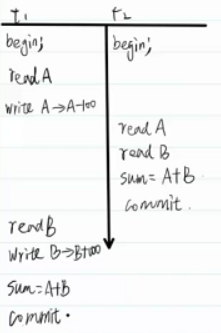
不可重復讀
一個事務內部先后兩次讀取,數據不一致。不會造成嚴重后果,在t2看起開很奇怪。
解決方案:只要進行讀就加鎖,不讓別人更改。
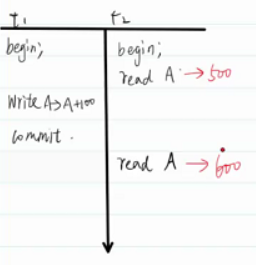
幻讀
?
在一個事務當中連續讀取多次數據,第一次讀取到的內容在第二次讀取中保持不變,但是會讀取到其他數據。
隔離級別
為了實現隔離性,我們需要解決并發帶來的問題。
- 讀未提交(READ UNCOMMITTED)
- 讀已提交(READ COMMITTED)
- 可重復讀? (REPEATABLE READ)
- 串行化? (SERIALIZABLE)
查看隔離級別(注:每個窗口的隔離級別是不一樣的,若要更改,每個窗口都要單獨執行更改隔離級別的指令)@@開頭的為系統變量。
?
讀未提交
更改隔離級別為讀未提交
當右一方提交新數據時,其他方對該數據的updata會被阻塞。
解決了臟寫問題
沒有解決臟讀問題
讀已提交
更改隔離級別為讀已提交
?解決了臟讀問題,沒有解決不可重復讀問題

可重復讀
這是默認的隔離級別
?
解決了不可重復讀問題,第一次和第二次讀到的內容一定是一樣的。這是一種比較高的隔離級別。
如果一邊insert into ,看上去沒有幻讀,但是緊接著insert into,觸發約束,說明幻讀依舊存在。

串行化
等價于mutex
解決了幻讀問題,但是可能導致效率低。做任何讀或者寫都可能卡住。
性能
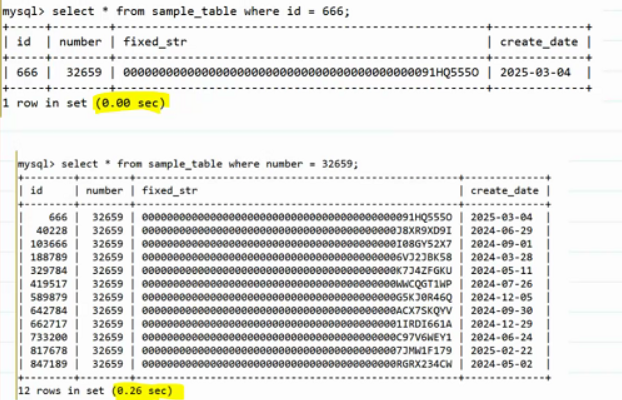
查詢條件不一樣導致查詢時間相差很多倍。
?
數據在數據庫中的存儲方式
磁盤IO頁大小一般為16KB
可使用select? @@innodb_page_size查看
數據在磁盤當中按行存儲的,在同一個磁盤頁中,數據是有序的,按照主鍵排序。
特點:
- 數據按行存儲
- 多行可以串聯成一個鏈表
- 行是有順序的,按主鍵排序的(可以使用二分查找定位,時間復雜度O(logN))?
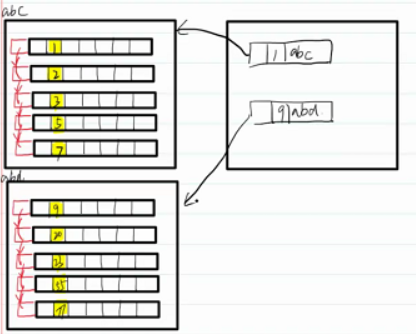
?數據存儲在多個磁盤頁時,需要再分配磁盤頁用來存儲其他磁盤頁的位置。
?左側稱為數據IO頁,右側稱為索引IO頁。
現在數據量進一步增大,一個索引頁不夠存儲,此時需要新的索引頁。同時為這一級的索引頁再添加索引頁。此時的結構稱為B+樹。
?
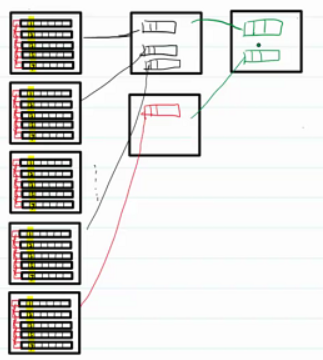
?B+樹
- 所有的非葉子節點都是索引頁,所有的葉子節點都是數據頁
- 數據是有序的
- 查詢次數(將數據從磁盤加載到內存中的次數)由樹的高度決定
主鍵自帶B+樹的索引,查找速度很快,因為B+樹按照主鍵排序。按照其他查找,只能通過遍歷樹來實現,速度很慢。
索引項的大小一般是固定的,一般一個索引頁可以放1600個索引項。一個表中的數據最好不要超過兩千萬,此時樹的高度可能增長到四層,導致所有的查詢操作變慢。
索引
額外的數據結構,用來做快速查找,可以由以下幾種數據結構考慮:
線性表 O(N)
哈希表 O(1)
- 消耗空間大
- 適合做等值查詢,不適合做范圍查詢
排序樹 O(logN)
- 二叉排序樹 樹的高度容易過高
- 多叉排序樹 B(B-)樹、B+樹
LSM tree
- 是一種專門為寫入密集型場景優化的分層存儲結構,將隨機寫入轉換為順序寫入,顯著提升系統寫入效率
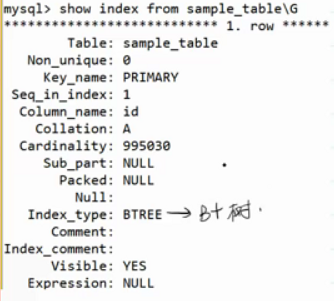
查看當前索引
這里的BTREE實際上是B+樹。
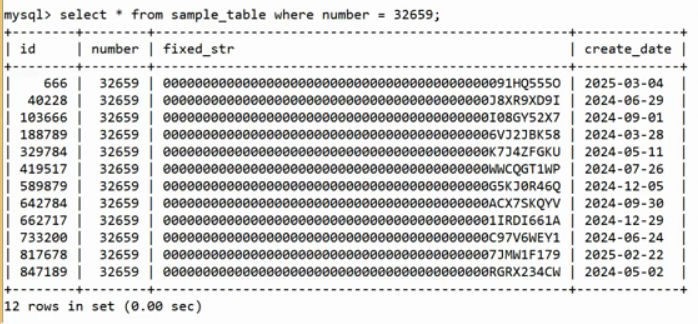
新建索引
建立一個索引,number_idx是索引名,(number)是索引的依據
?引入索引之后速度變快
新建索引 的葉子節點不存放所有數據,里面只存放新索引和主鍵,消耗的磁盤空間小。根據新索引找到查找內容的主鍵,再通過主鍵在舊索引中查找。
- 聚簇索引:主鍵是聚簇的,把行的值放入索引結構內部
- 非聚簇索引: 新建的索引,把行的地址或主鍵放入索引結構內部
mysql只有一個聚簇索引。非聚簇索引要經過兩次索引查找擦能找到查詢的內容,速度比聚簇索引略慢。

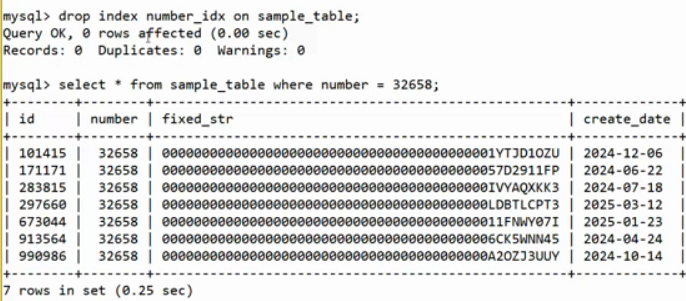
?移除索引
移除索引后,查找速度顯著變慢
?組合索引
索引關注多列。
?索引時遵循最左優先原則,如在上例中,先看c3、再看c2、最后看c1。
索引的分類
- 按數據結構分類:哈希/B樹/B+樹
- 聚簇索引:把行的值放入索引結構內部(主鍵是聚簇的)
- 非聚簇索引:把行的地址或主鍵放入索引結構內部
- 單列索引:看一個值
- 組合索引:看多個值,遵循最左優先原則
覆蓋索引
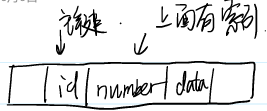
有下圖的表,主鍵為id,number是非聚簇索引
分析下列三種查找效率
- select? id,number? from? ……? where? number? = 123;
- select? data? ?from? ……? where? number? =? 123;
- select? *? from ……? where? number? =? 123;
非聚簇索引中僅存儲了行地址、主鍵以及number值,而第一次查找僅依賴非聚簇索引即可完成,稱之為覆蓋索引。
三次查找速度對比:
- 第一次操作速度最快
- 第二次、第三次要多做一次回表(到聚簇中去查詢)操作
索引的壞處
- 消耗額外的空間
- 查詢速度快,但是插入、修改、刪除時間變長
- 隨著時間的推移,索引的結構會產生碎片,索引是需要維護的
性能考慮
自動增長的整數作為主鍵比不會重復的隨機數做主鍵要好。因為自動增長的整數,每次會按序進入B+樹,即使需要節點合并、分裂操作也在偏向于葉子節點的位置,對B+樹更加友好。








![384_C++_unit是4字節大小,能存儲32位(bit)bool操作,[7][48]這里用于計劃表的時間節點內,二維數組中每一位代表一種AI功能的開關狀態](http://pic.xiahunao.cn/384_C++_unit是4字節大小,能存儲32位(bit)bool操作,[7][48]這里用于計劃表的時間節點內,二維數組中每一位代表一種AI功能的開關狀態)


之 【高級字符串函數 / 正則表達式 / 子句】· 上)

目錄建議)





