之前的神經網絡訓練中,為了幫助理解借用了很多的組件,比如訓練進度條、可視化的loss下降曲線、權重分布圖,運行結束后還可以查看單張圖的推理效果。
如果現在有一個交互工具可以很簡單的通過按鈕完成這些輔助功能那就好了,他就是可視化工具tensorboard
tensorboard的基本操作
1.1 發展歷史
TensorBoard 是 TensorFlow 生態中的官方可視化工具,用于實時監控訓練過程、可視化模型結構、分析數據分布、對比實驗結果等。它通過網頁端交互界面,將枯燥的訓練日志轉化為直觀的圖表和圖像,幫助開發者快速定位問題、優化模型,就像給機器學習模型訓練過程裝了一個「監控屏幕」。你可以用它直觀看到訓練過程中的數據變化(比如損失值、準確率)、模型結構、數據分布等,不用盯著一堆枯燥的數字看,對新手非常友好。2019 年后與 PyTorch 兼容,變得更通用了。功能進一步豐富,比如支持3D 可視化、模型參數調試等。我們目前只需要要用到最經典的幾個功能即可
- 保存模型結構圖
- 保存訓練集和驗證集的loss變化曲線,不需要手動打印了
- 保存每一個層結構權重分布
- 保存預測圖片的預測信息
1.2 tensorboard的原理
TensorBoard 的核心原理就是在訓練過程中,把訓練過程中的數據(比如損失、準確率、圖片等)先記錄到日志文件里,再通過工具把這些日志文件可視化成圖表,這樣就不用自己手動打印數據或者用其他工具畫圖。
所以核心就是2個步驟:
- 數據怎么存?—— 先寫日志文件
訓練模型時,TensorBoard 會讓程序把訓練數據(比如損失值、準確率)和模型結構等信息,寫入一個特殊的日志文件(.tfevents 文件)
- 數據怎么看?—— 用網頁展示日志
寫完日志后,TensorBoard 會啟動一個本地網頁服務,自動讀取日志文件里的數據,用圖表、圖像、文本等形式展示出來。如果只用 print(損失值) 或者自己用 matplotlib 畫圖,不僅麻煩,還得手動保存數據、寫代碼。而 TensorBoard 能自動把這些數據 “存下來 + 畫出來”,還能生成網頁版的可視化界面,隨時刷新查看!
下面是tensorboard的核心代碼解析,無需運行 看懂大概在做什么即可
1.3 日志目錄自動管理
log_dir = 'runs/cifar10_mlp_experiment'
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}" #一個編號有了就趕緊生成下一個
writer = SummaryWriter(log_dir) #關鍵入口,用于寫入數據到日志目錄自動避免日志目錄重復。若 runs/cifar10_mlp_experiment 已存在,會生成 runs/cifar10_mlp_experiment_1、_2 等新目錄,確保每次訓練的日志獨立存儲。
方便對比不同訓練任務的結果(如不同超參數實驗)
1.4 記錄標量數據(Scalar)
# 記錄每個 Batch 的損失和準確率
writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)
writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 記錄每個 Epoch 的訓練指標
writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)
writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)在 tensorboard的SCALARS 選項卡中查看曲線,支持多 run 對比?。
1.5 可視化模型結構(Graph)
dataiter = iter(train_loader)
images, labels = next(dataiter)
images = images.to(device)
writer.add_graph(model, images) # 通過真實輸入樣本生成模型計算圖TensorBoard 界面:在 GRAPHS 選項卡中查看模型層次結構(卷積層、全連接層等)。
1.6 可視化圖像(Image)
# 可視化原始訓練圖像
img_grid = torchvision.utils.make_grid(images[:8].cpu()) # 將多張圖像拼接成網格狀(方便可視化),將前8張圖像拼接成一個網格
writer.add_image('原始訓練圖像', img_grid)# 可視化錯誤預測樣本(訓練結束后)
wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])
writer.add_image('錯誤預測樣本', wrong_img_grid)展示原始圖像、數據增強效果、錯誤預測樣本等。
1.7 記錄權重和梯度直方圖(Histogram)
if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step) # 權重分布if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step) # 梯度分布在 HISTOGRAMS 選項卡中查看不同層的參數分布隨訓練的變化。監控模型參數(如權重 weights)和梯度(grads)的分布變化,診斷訓練問題(如梯度消失 / 爆炸)。
1.8 啟動tensorboard
運行代碼后,會在指定目錄(如 runs/cifar10_mlp_experiment_1)生成 .tfevents 文件,存儲所有 TensorBoard 數據。
在終端執行(需進入項目根目錄):
tensorboard --logdir=runs # 假設日志目錄在 runs/ 下
打開瀏覽器,輸入終端提示的 URL(通常為?http://localhost:6006)。
二、tensorboard實戰
2.1 cifar-10 MLP實戰?
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 設置隨機種子以確保結果可復現
torch.manual_seed(42)
np.random.seed(42)# 1. 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 轉換為張量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 標準化處理
])# 2. 加載CIFAR-10數據集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 創建數據加載器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的類別名稱
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定義MLP模型(適應CIFAR-10的輸入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 將3x32x32的圖像展平為3072維向量self.layer1 = nn.Linear(3072, 512) # 第一層:3072個輸入,512個神經元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止過擬合self.layer2 = nn.Linear(512, 256) # 第二層:512個輸入,256個神經元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 輸出層:10個類別def forward(self, x):# 第一步:將輸入圖像展平為一維向量x = self.flatten(x) # 輸入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一層全連接 + 激活 + Dropoutx = self.layer1(x) # 線性變換: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 應用ReLU激活函數x = self.dropout1(x) # 訓練時隨機丟棄部分神經元輸出# 第二層全連接 + 激活 + Dropoutx = self.layer2(x) # 線性變換: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 應用ReLU激活函數x = self.dropout2(x) # 訓練時隨機丟棄部分神經元輸出# 第三層(輸出層)全連接x = self.layer3(x) # 線性變換: [batch_size, 256] → [batch_size, 10]return x # 返回未經過Softmax的logits# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 將模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam優化器# 創建TensorBoard的SummaryWriter,指定日志保存目錄
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目錄已存在,添加后綴避免覆蓋
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 訓練模型(使用TensorBoard記錄各種信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 設置為訓練模式# 記錄訓練開始時間,用于計算訓練速度global_step = 0# 可視化模型結構dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型圖# 可視化原始圖像樣本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始訓練圖像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數# 統計準確率和損失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100個批次記錄一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 記錄標量數據(損失、準確率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 記錄學習率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500個批次記錄一次直方圖(權重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 單Batch損失: {batch_loss:.4f} | 累計平均損失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 計算當前epoch的平均訓練損失和準確率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 記錄每個epoch的訓練損失和準確率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 測試階段model.eval() # 設置為評估模式test_loss = 0correct_test = 0total_test = 0# 用于存儲預測錯誤的樣本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集預測錯誤的樣本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 記錄每個epoch的測試損失和準確率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 計算并記錄訓練速度(每秒處理的樣本數)# 這里簡化處理,假設每個epoch的時間相同samples_per_epoch = len(train_loader.dataset)# 實際應用中應該使用time.time()來計算真實時間print(f'Epoch {epoch+1}/{epochs} 完成 | 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%')# 可視化預測錯誤的樣本(只在最后一個epoch進行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多顯示8個錯誤樣本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 創建錯誤預測的標簽文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('錯誤預測樣本', wrong_img_grid)writer.add_text('錯誤預測標簽', '\n'.join(wrong_text), epoch)# 關閉TensorBoard寫入器writer.close()return epoch_test_acc # 返回最終測試準確率# 6. 執行訓練和測試
epochs = 20 # 訓練輪次
print("開始訓練模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("訓練完成后,使用命令 `tensorboard --logdir=runs` 啟動TensorBoard查看可視化結果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")TensorBoard日志保存在: runs/cifar10_mlp_experiment_1 可以在命令行中進入目前的環境,然后通過tensorboard --logdir=xxxx(目錄)即可調出本地鏈接,點進去就是目前的訓練信息,可以不斷F5刷新來查看變化。
在TensorBoard界面中,你可以看到:
- SCALARS 選項卡:展示損失曲線、準確率變化、學習率等標量數據----Scalar意思是標量,指只有大小、沒有方向的量。
- IMAGES 選項卡:展示原始訓練圖像和錯誤預測的樣本
- GRAPHS 選項卡:展示模型的計算圖結構
- HISTOGRAMS 選項卡:展示模型參數和梯度的分布直方圖
2.2 cifar-10 CNN實戰
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import numpy as np
import matplotlib.pyplot as plt
import os# 設置隨機種子以確保結果可復現
torch.manual_seed(42)
np.random.seed(42)# 1. 數據預處理
transform = transforms.Compose([transforms.ToTensor(), # 轉換為張量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 標準化處理
])# 2. 加載CIFAR-10數據集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 創建數據加載器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# CIFAR-10的類別名稱
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 4. 定義MLP模型(適應CIFAR-10的輸入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 將3x32x32的圖像展平為3072維向量self.layer1 = nn.Linear(3072, 512) # 第一層:3072個輸入,512個神經元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止過擬合self.layer2 = nn.Linear(512, 256) # 第二層:512個輸入,256個神經元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 輸出層:10個類別def forward(self, x):# 第一步:將輸入圖像展平為一維向量x = self.flatten(x) # 輸入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一層全連接 + 激活 + Dropoutx = self.layer1(x) # 線性變換: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 應用ReLU激活函數x = self.dropout1(x) # 訓練時隨機丟棄部分神經元輸出# 第二層全連接 + 激活 + Dropoutx = self.layer2(x) # 線性變換: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 應用ReLU激活函數x = self.dropout2(x) # 訓練時隨機丟棄部分神經元輸出# 第三層(輸出層)全連接x = self.layer3(x) # 線性變換: [batch_size, 256] → [batch_size, 10]return x # 返回未經過Softmax的logits# 檢查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 將模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵損失函數
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam優化器# 創建TensorBoard的SummaryWriter,指定日志保存目錄
log_dir = 'runs/cifar10_mlp_experiment'
# 如果目錄已存在,添加后綴避免覆蓋
if os.path.exists(log_dir):i = 1while os.path.exists(f"{log_dir}_{i}"):i += 1log_dir = f"{log_dir}_{i}"
writer = SummaryWriter(log_dir)# 5. 訓練模型(使用TensorBoard記錄各種信息)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer):model.train() # 設置為訓練模式# 記錄訓練開始時間,用于計算訓練速度global_step = 0# 可視化模型結構dataiter = iter(train_loader)images, labels = next(dataiter)images = images.to(device)writer.add_graph(model, images) # 添加模型圖# 可視化原始圖像樣本img_grid = torchvision.utils.make_grid(images[:8].cpu())writer.add_image('原始訓練圖像', img_grid)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向傳播loss = criterion(output, target) # 計算損失loss.backward() # 反向傳播optimizer.step() # 更新參數# 統計準確率和損失running_loss += loss.item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100個批次記錄一次信息到TensorBoardif (batch_idx + 1) % 100 == 0:batch_loss = loss.item()batch_acc = 100. * correct / total# 記錄標量數據(損失、準確率)writer.add_scalar('Train/Batch_Loss', batch_loss, global_step)writer.add_scalar('Train/Batch_Accuracy', batch_acc, global_step)# 記錄學習率writer.add_scalar('Train/Learning_Rate', optimizer.param_groups[0]['lr'], global_step)# 每500個批次記錄一次直方圖(權重和梯度)if (batch_idx + 1) % 500 == 0:for name, param in model.named_parameters():writer.add_histogram(f'weights/{name}', param, global_step)if param.grad is not None:writer.add_histogram(f'grads/{name}', param.grad, global_step)print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 單Batch損失: {batch_loss:.4f} | 累計平均損失: {running_loss/(batch_idx+1):.4f}')global_step += 1# 計算當前epoch的平均訓練損失和準確率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 記錄每個epoch的訓練損失和準確率writer.add_scalar('Train/Epoch_Loss', epoch_train_loss, epoch)writer.add_scalar('Train/Epoch_Accuracy', epoch_train_acc, epoch)# 測試階段model.eval() # 設置為評估模式test_loss = 0correct_test = 0total_test = 0# 用于存儲預測錯誤的樣本wrong_images = []wrong_labels = []wrong_preds = []with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()# 收集預測錯誤的樣本wrong_mask = (predicted != target).cpu()if wrong_mask.sum() > 0:wrong_batch_images = data[wrong_mask].cpu()wrong_batch_labels = target[wrong_mask].cpu()wrong_batch_preds = predicted[wrong_mask].cpu()wrong_images.extend(wrong_batch_images)wrong_labels.extend(wrong_batch_labels)wrong_preds.extend(wrong_batch_preds)epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 記錄每個epoch的測試損失和準確率writer.add_scalar('Test/Loss', epoch_test_loss, epoch)writer.add_scalar('Test/Accuracy', epoch_test_acc, epoch)# 計算并記錄訓練速度(每秒處理的樣本數)# 這里簡化處理,假設每個epoch的時間相同samples_per_epoch = len(train_loader.dataset)# 實際應用中應該使用time.time()來計算真實時間print(f'Epoch {epoch+1}/{epochs} 完成 | 訓練準確率: {epoch_train_acc:.2f}% | 測試準確率: {epoch_test_acc:.2f}%')# 可視化預測錯誤的樣本(只在最后一個epoch進行)if epoch == epochs - 1 and len(wrong_images) > 0:# 最多顯示8個錯誤樣本display_count = min(8, len(wrong_images))wrong_img_grid = torchvision.utils.make_grid(wrong_images[:display_count])# 創建錯誤預測的標簽文本wrong_text = []for i in range(display_count):true_label = classes[wrong_labels[i]]pred_label = classes[wrong_preds[i]]wrong_text.append(f'True: {true_label}, Pred: {pred_label}')writer.add_image('錯誤預測樣本', wrong_img_grid)writer.add_text('錯誤預測標簽', '\n'.join(wrong_text), epoch)# 關閉TensorBoard寫入器writer.close()return epoch_test_acc # 返回最終測試準確率# 6. 執行訓練和測試
epochs = 20 # 訓練輪次
print("開始訓練模型...")
print(f"TensorBoard日志保存在: {log_dir}")
print("訓練完成后,使用命令 `tensorboard --logdir=runs` 啟動TensorBoard查看可視化結果")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs, writer)
print(f"訓練完成!最終測試準確率: {final_accuracy:.2f}%")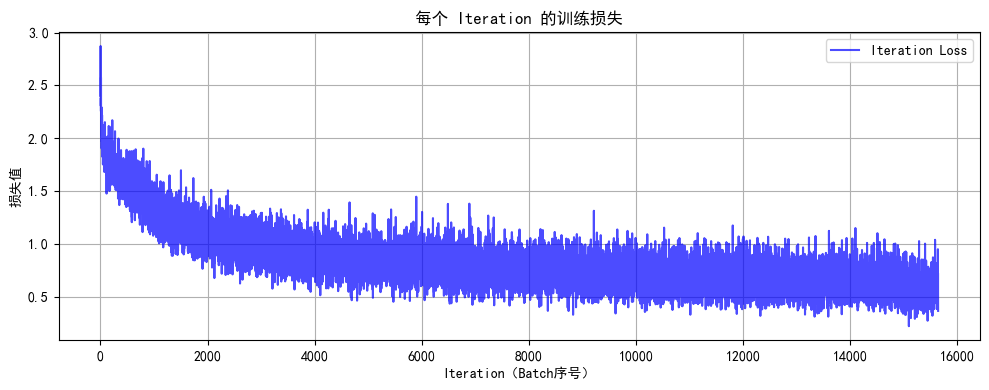
由于已近搭載了tensorboard,上述代碼中一些之前可視化的冗余部分可以刪除了。
tensorboard的代碼還有有一定的記憶量,實際上深度學習的經典代碼都是類似于八股文,看多了就習慣了,難度遠遠小于考研數學等需要思考的內容
實際上對目前的ai而言,你只需要先完成最簡單的demo,然后讓他給你加上tensorboard需要打印的部分即可。---核心是弄懂tensorboard可以打印什么信息,以及如何看可視化后的結果,把ai當成記憶大師用到的時候通過它來調取對應的代碼即可。






——云存儲RDS)






)





)