考慮到目前市面上的向量數據庫眾多,每個數據庫的操作方式也無統一標準,但是仍然存在著一些公共特征,LangChain 基于這些通用的特征封裝了 VectorStore 基類,在這個基類下,可以將方法劃分成 6 種:
- 相似性搜索
- 最大邊際相關性搜索
- 通用搜索
- 添加刪除精確查找數據
- 檢索器
- 創建數據庫
類圖如下: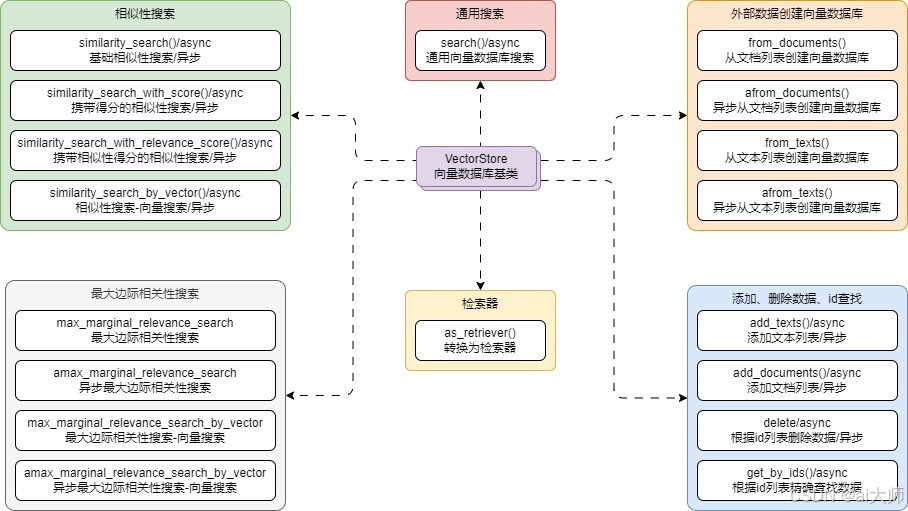
1. 帶得分閾值的相似性搜索
在 LangChain 的相似性搜索中,無論結果多不匹配,只要向量數據庫中存在數據,一定會查找出相應的結果,在 RAG 應用開發中,一般是將高相似文檔插入到 Prompt 中,所以可以考慮添加一個 相似性得分閾值,超過該數值的部分才等同于有相似性。
資料推薦
- 💡大模型中轉API推薦
- ?中轉使用教程
- ?模型優惠查詢
在 similarity_search_with_relevance_scores() 函數中,可以傳遞 score_threshold 閾值參數,過濾低于該得分的文檔。
例如沒有添加閾值檢索 我養了一只貓,叫笨笨,示例與輸出如下:
import dotenv
from langchain_community.vectorstores import FAISS
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddingsdotenv.load_dotenv()embedding = OpenAIEmbeddings(model="text-embedding-3-small")documents = [Document(page_content="笨笨是一只很喜歡睡覺的貓咪", metadata={"page": 1}),Document(page_content="我喜歡在夜晚聽音樂,這讓我感到放松。", metadata={"page": 2}),Document(page_content="貓咪在窗臺上打盹,看起來非常可愛。", metadata={"page": 3}),Document(page_content="學習新技能是每個人都應該追求的目標。", metadata={"page": 4}),Document(page_content="我最喜歡的食物是意大利面,尤其是番茄醬的那種。", metadata={"page": 5}),Document(page_content="昨晚我做了一個奇怪的夢,夢見自己在太空飛行。", metadata={"page": 6}),Document(page_content="我的手機突然關機了,讓我有些焦慮。", metadata={"page": 7}),Document(page_content="閱讀是我每天都會做的事情,我覺得很充實。", metadata={"page": 8}),Document(page_content="他們一起計劃了一次周末的野餐,希望天氣能好。", metadata={"page": 9}),Document(page_content="我的狗喜歡追逐球,看起來非常開心。", metadata={"page": 10}),
]
db = FAISS.from_documents(documents, embedding)print(db.similarity_search_with_relevance_scores("我養了一只貓,叫笨笨"))# 輸出內容
[(Document(metadata={'page': 1}, page_content='笨笨是一只很喜歡睡覺的貓咪'), 0.4592331743070337), (Document(metadata={'page': 3}, page_content='貓咪在窗臺上打盹,看起來非常可愛。'), 0.22960424668403867), (Document(metadata={'page': 10}, page_content='我的狗喜歡追逐球,看起來非常開心。'), 0.02157827632118159), (Document(metadata={'page': 7}, page_content='我的手機突然關機了,讓我有些焦慮。'), -0.09838758604956)]
添加閾值 0.4,搜索輸出示例如下:
print(db.similarity_search_with_relevance_scores("我養了一只貓,叫笨笨", score_threshold=0.4))# 輸出[(Document(metadata={'page': 1}, page_content='笨笨是一只很喜歡睡覺的貓咪'), 0.45919389344422157)]
對于 score_threshold 的具體數值,要看相似性搜索方法使用的邏輯、計算相似性得分的邏輯進行設置,并沒有統一的標準,并且與向量數據庫的數據大小也存在間接關系,數據集越大,檢索出來的準確度相比少量數據會更準確。
2. as_retriever() 檢索器
在 LangChain 中,VectorStore 可以通過 as_retriever() 方法轉換成檢索器,在 as_retriever() 中可以傳遞一下參數:
search_type:搜索類型,支持 similarity(基礎相似性搜索)、similarity_score_threshold(攜帶相似性得分+閾值判斷的相似性搜索)、mmr(最大邊際相關性搜索)。
search_kwargs:其他鍵值對搜索參數,類型為字典,例如:k、filter、score_threshold、fetch_k、lambda_mult 等,當搜索類型配置為 similarity_score_threshold 后,必須添加 score_threshold 配置選項,否則會報錯,參數的具體信息要看 search_type 類型對應的函數配合使用。
并且由于檢索器是 Runnable 可運行組件,所以可以使用 Runnable 組件的所有功能(組件替換、參數配置、重試、回退、并行等)。
例如將向量數據庫轉換成 攜帶得分+閾值判斷的相似性搜索,并設置得分閾值為0.5,數據條數為10條,代碼示例如下:
import dotenv
import weaviate
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_weaviate import WeaviateVectorStore
from weaviate.auth import AuthApiKeydotenv.load_dotenv()# 1.構建加載器與分割器
loader = UnstructuredMarkdownLoader("./項目API文檔.md")
text_splitter = RecursiveCharacterTextSplitter(separators=["\n\n", "\n", "。|!|?", "\.\s|\!\s|\?\s", ";|;\s", ",|,\s", " ", "", ],is_separator_regex=True,chunk_size=500,chunk_overlap=50,add_start_index=True,
)# 2.加載文檔并分割
documents = loader.load()
chunks = text_splitter.split_documents(documents)# 3.將數據存儲到向量數據庫
db = WeaviateVectorStore(client=weaviate.connect_to_wcs(cluster_url="https://eftofnujtxqcsa0sn272jw.c0.us-west3.gcp.weaviate.cloud",auth_credentials=AuthApiKey("21pzYy0orl2dxH9xCoZG1O2b0euDeKJNEbB0"),),index_name="DatasetDemo",text_key="text",embedding=OpenAIEmbeddings(model="text-embedding-3-small"),
)# 4.轉換檢索器
retriever = db.as_retriever(search_type="similarity_score_threshold",search_kwargs={"k": 10, "score_threshold": 0.5},
)# 5.檢索結果
documents = retriever.invoke("關于配置接口的信息有哪些")print(list(document.page_content[:50] for document in documents))
print(len(documents))
輸出內容:
['接口說明:用于更新對應應用的調試長記憶內容,如果應用沒有開啟長記憶功能,則調用接口會發生報錯。\n\n接', '如果接口需要授權,需要在 headers 中添加 Authorization ,并附加 access', '接口示例:\n\njson\n{\n "code": "success",\n "data": {', '接口信息:授權+POST:/apps/:app_id/debug\n\n接口參數:\n\n請求參數:\n\nap', '1.2 [todo]更新應用草稿配置信息\n\n接口說明:更新應用的草稿配置信息,涵蓋:模型配置、長記憶', '請求參數:\n\napp_id -> uuid:路由參數,必填,需要獲取的應用 id。\n\n響應參數:\n\n', 'memory_mode -> string:記憶類型,涵蓋長記憶 long_term_memory ', '1.6 [todo]獲取應用調試歷史對話列表\n\n接口說明:用于獲取應用調試歷史對話列表信息,該接口支', 'LLMOps 項目 API 文檔\n\n應用 API 接口統一以 JSON 格式返回,并且包含 3 個字', '響應參數:\n\nsummary -> str:該應用最新調試會話的長記憶內容。\n\n響應示例:\n\njso']
10
資料推薦
- 💡大模型中轉API推薦
- ?中轉使用教程
- ?模型優惠查詢








)


)




)


