MathQ-Verify:數學問題驗證的五步流水線,為大模型推理筑牢數據基石
大語言模型在數學推理領域進展顯著,但現有研究多聚焦于生成正確推理路徑和答案,卻忽視了數學問題本身的有效性。MathQ-Verify,通過五階段流水線嚴格過濾 ill-posed 或描述不明確的數學問題,為構建可靠的數學數據集提供了可擴展且準確的解決方案,一起來了解這一創新方法吧!
論文標題
Let’s Verify Math Questions Step by Step
來源
arXiv:2505.13903v1 [cs.CL] + https://arxiv.org/abs/2505.13903
PS: 整理了LLM、量化投資、機器學習方向的學習資料,關注同名公眾號 「 亞里隨筆」 即刻免費解鎖
文章核心
研究背景
大語言模型(LLMs)在數學推理方面取得了顯著進步,其推理能力在很大程度上歸功于高質量的數據源和高效的訓練框架。然而,大多數現有的大規模數學問答數據集主要由合成的問答對組成,若問題本身存在缺陷,答案也不可能正確,因此問題的正確性至關重要。
研究問題
1. 缺乏全面的問題驗證方法:雖然最近有幾項研究開始關注數學問題的有效性,但它們的重點通常局限于諸如假設缺失或前提模糊等狹窄的錯誤類型,未能建立一個系統而全面的框架來識別 ill-posed 或有缺陷的問題,導致許多數據集仍包含存在內部不一致、邏輯矛盾或違反基本數學原理的問題。
2. 缺乏用于問題驗證的分步高難度基準:現有的基準,如 MathClean,沒有提供足夠有挑戰性的問題,也沒有包含評估多步問題驗證流水線每個階段所需的細粒度、分步注釋,這限制了嚴格評估模型檢測和推理數學問題表述中復雜缺陷的能力。
主要貢獻
1. 構建新數據集 ValiMath:通過整合 NuminaMath 中的合成問題并為其豐富結構化的分步標簽,專門設計用于支持對數學問題正確性的全面評估。該數據集包含 2,147 個問題(1,299 個正確,848 個錯誤),覆蓋五種不同的錯誤類型,為模型評估提供了更全面的支持。
2. 提出 MathQ-Verify 流水線:通過將數學問題分解為結構化組件,并根據形式化標準檢查每個部分,逐步驗證數學問題的正確性。該流水線在 MathClean 的兩個評估集上取得了最先進的結果,與直接驗證基線相比,在 ValiMath 上 F1 提高了近 15%。
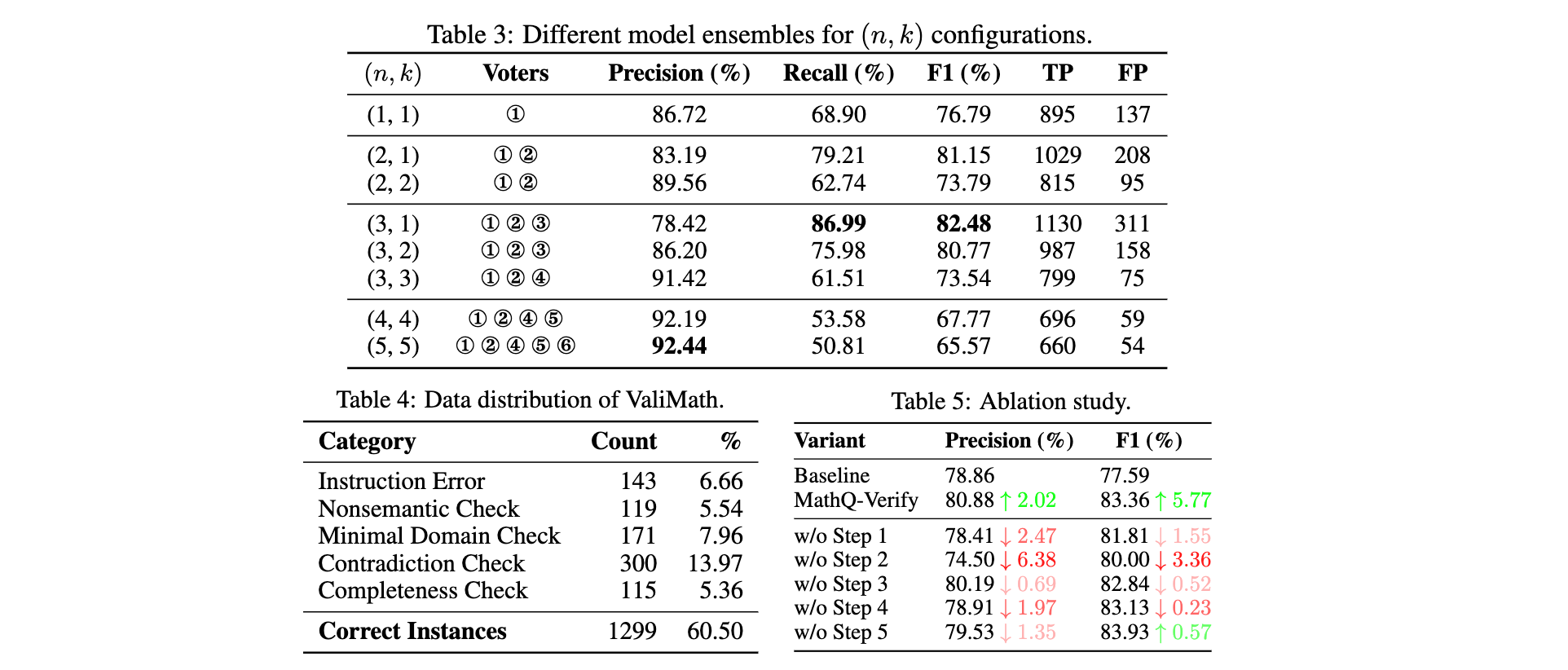
3. 驗證各組件有效性:通過消融研究,系統地驗證了 MathQ-Verify 流水線中每個驗證階段對整體性能的單獨貢獻。此外,證明了在驗證輸出中加入多數投票策略可顯著提高精度,達到 90% 以上,突顯了該方法的穩健性和可靠性。
方法論精要
1. 核心算法/框架:MathQ-Verify 是一個五階段的驗證流水線,包括污染指令檢測、語言錯誤檢測、原子條件錯誤檢測、跨條件沖突檢測和條件完整性驗證。該框架通過逐步分解和驗證數學問題的各個組成部分,確保對問題質量進行全面評估。
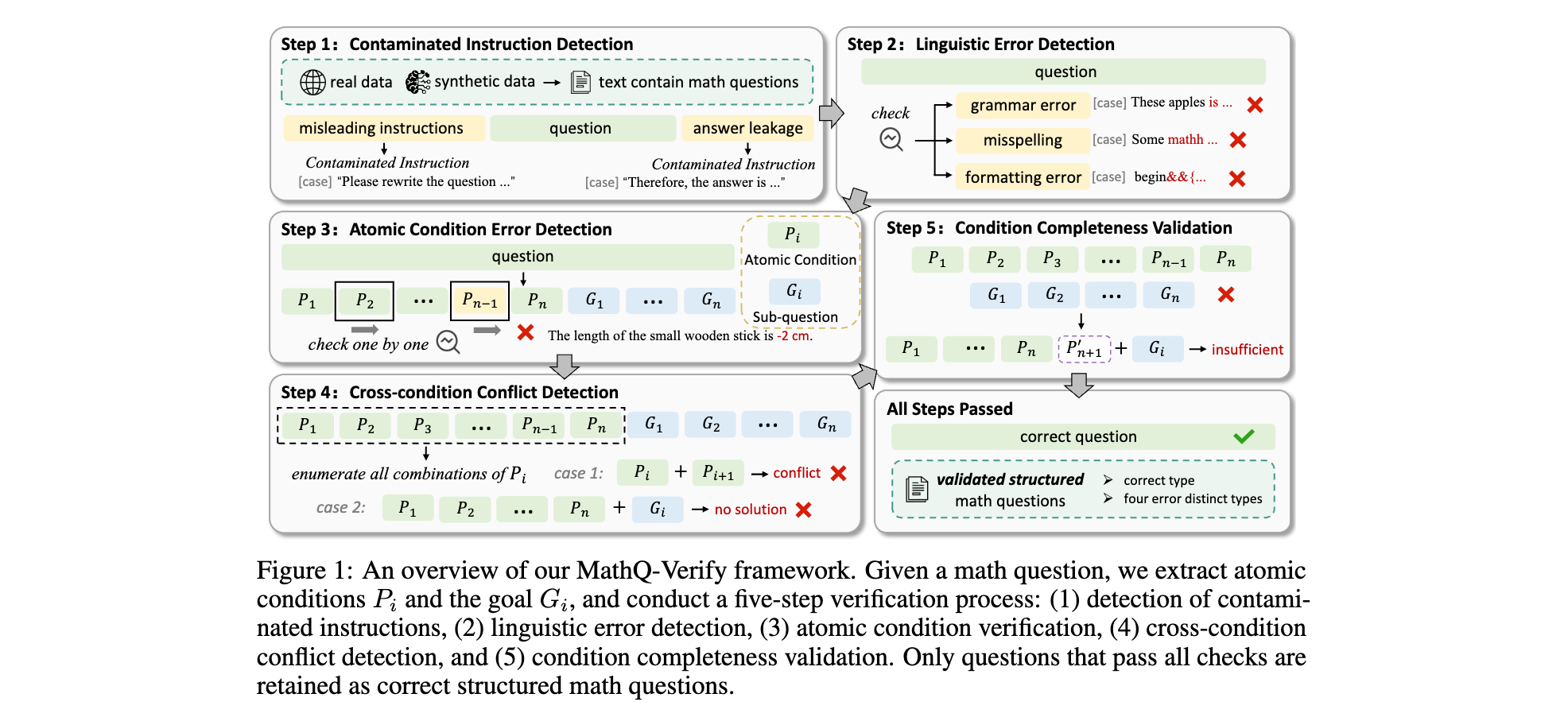
2. 關鍵參數設計原理:在污染指令檢測中,通過定義二進制指令有效性指標,確保問題是真正的數學問題,沒有誤導性語言模式和明確的答案泄露。在語言錯誤檢測中,采用 Qwen-2.5-7B-Instruct 模型檢測拼寫錯誤、語法錯誤和 LaTeX 格式異常等語言層面的問題。在原子條件錯誤檢測中,嚴格驗證每個原子條件是否符合相應數學領域的規則,任何與基本定義矛盾的條件都被嚴格拒絕。
3. 創新性技術組合:將問題分解為原子條件和目標目標兩個結構化組件,作為驗證的基礎。采用多模型投票策略,通過聚合多個獨立訓練模型的預測來增強條件驗證的穩健性,通過調整投票閾值來平衡精度和召回率。

4. 實驗驗證方式:使用 MathClean 基準的 GSM8K 和 MATH 合成注釋版本作為主要評估數據集,同時納入 ValiMath 數據集進行全面評估。對比基線為直接評估每個輸入問題正確性的方法,不采用 MathQ-Verify 框架的分解或多步驗證程序。通過準確率、精確率、召回率、F1 分數、無效輸出數量和分步準確率等標準評估指標來衡量模型性能。
實驗洞察
1. 性能優勢:在 MathClean-GSM8K 上,Qwen2.5-7B 基線的 F1 為 74.02%,MathQ-Verify 提升至 76.09%;在 MathClean-MATH 上,Llama-3.1-8B 基線的 F1 為 58.82%,MathQ-Verify 提升至 72.42%。在 ValiMath 上,GPT-o4-mini 基線的 F1 為 77.59%,MathQ-Verify 提升至 83.36%,且精確率達到 80.88%。
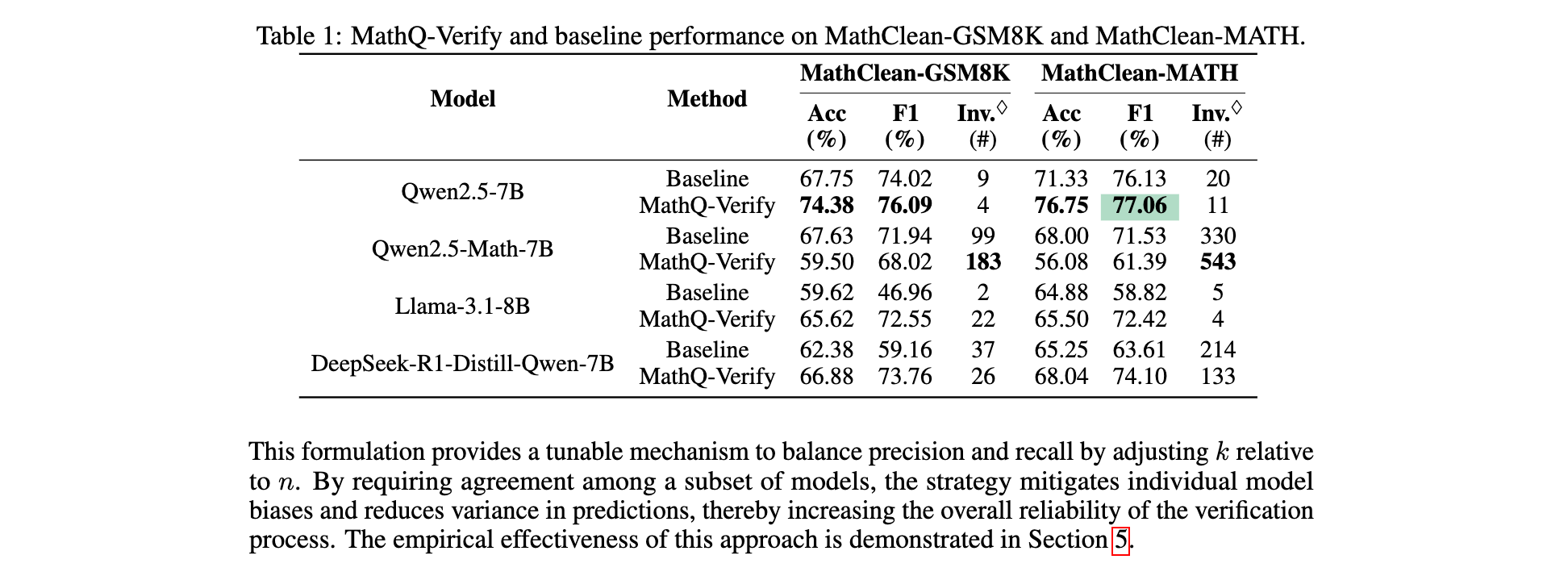
2. 效率突破:通過多模型投票策略,在 (3, 3) 配置下,雖然召回率有所下降,但精確率可達 91.42%;在 (3, 1) 配置下,F1 達到 82.48%,召回率為 86.99%,在保證一定召回率的同時有效提升了預測質量。
3. 消融研究:省略前兩個驗證步驟(污染指令檢測和語言錯誤檢測)導致精度和 F1 分別下降超過 6% 和 3%;移除矛盾檢測(第四步)使精度下降約 2%;移除條件完整性驗證(第五步)F1 略有提升但精度下降,表明各模塊均有獨特貢獻,組合使用可實現最佳的精確率 - 召回率平衡。




設計模式 軟考 享元 和 代理屬于結構型設計模式)

(2025A卷:200分)Java/python/JavaScript/C/C++/GO最佳實現)

-- C.年少的誓約(公式轉化)))








 寫前后端)

