摘要:網絡延遲在AI開發中常被忽視,卻嚴重影響效率。GpuGeek通過技術創新,提供學術資源訪問和跨國數據交互的加速服務,助力開發者突破瓶頸。
目錄
一、引言:當算力不再稀缺,網絡瓶頸如何破局?
二、GpuGeek 網絡加速核心優勢解析
2.1 學術資源加速引擎:20 + 核心站點一鍵直達
2.2 全球節點布局:構建低延遲算力網絡
2.3 彈性計費與智能調度:成本效率雙平衡
三、網絡加速實戰指南:從配置到調優全流程
3.1 快速上手:3 步激活加速服務
3.2 高級技巧:定制化加速策略
3.3 典型場景優化方案
3.4?網絡加速的重要性
四、網絡加速賦能多元 AI 場景
4.1 高校科研:讓文獻與代碼觸手可及
4.2 企業開發:突破跨境協作壁壘
4.3 個人開發者:輕量化加速體驗
?五、經典代碼案例及解釋
5.1 代碼案例1:使用TensorFlow構建簡單的卷積神經網絡(CNN)進行圖像分類
5.2 代碼案例2:使用PyTorch進行模型微調
5.3 代碼案例3:使用OpenCV進行圖像預處理
5.4 代碼案例4:使用TensorFlow構建并訓練一個循環神經網絡(RNN)進行文本生成
5.5 代碼案例5:使用PyTorch進行Transformer模型的微調
5.6 代碼案例6:使用OpenCV和TensorFlow進行實時圖像識別
六、總結:重新定義 AI 開發的 “網絡效率”
6.1?附錄:常見問題解答(FAQ)
6.2?寫在最后
一、引言:當算力不再稀缺,網絡瓶頸如何破局?
在 AI 開發的全流程中,算力資源的重要性已被廣泛認知,但網絡延遲導致的效率損耗卻常被忽視。從 GitHub 代碼拉取的龜速加載,到 Hugging Face 模型下載的反復中斷,再到跨國協作時的鏡像傳輸卡頓,網絡問題正成為開發者的 “隱性成本黑洞”。GpuGeek 平臺針對這一痛點推出的網絡加速功能,通過技術創新實現了學術資源訪問、跨國數據交互的效率躍升,成為 AI 開發者突破瓶頸的關鍵利器。

二、GpuGeek 網絡加速核心優勢解析
2.1 學術資源加速引擎:20 + 核心站點一鍵直達
GpuGeek 專為 AI 研發場景優化網絡鏈路,內置的學術加速通道覆蓋 Google Scholar、GitHub、Hugging Face、ArXiv 等 20 + 國際核心學術站點。開發者無需復雜配置,通過 SSH 命令即可激活加速服務:
# 臨時加速通道(24小時有效)
ssh -L 8080:github.com:443 speedup.gpugeek.com
# 永久加速配置(控制臺提交工單添加目標域名)
平臺采用智能路由算法,動態選擇最優節點,實測 GitHub 代碼克隆速度提升 300%,Hugging Face 模型下載耗時縮短 60%。支持按需購買流量包,未使用流量自動凍結,避免資源浪費。

2.2 全球節點布局:構建低延遲算力網絡
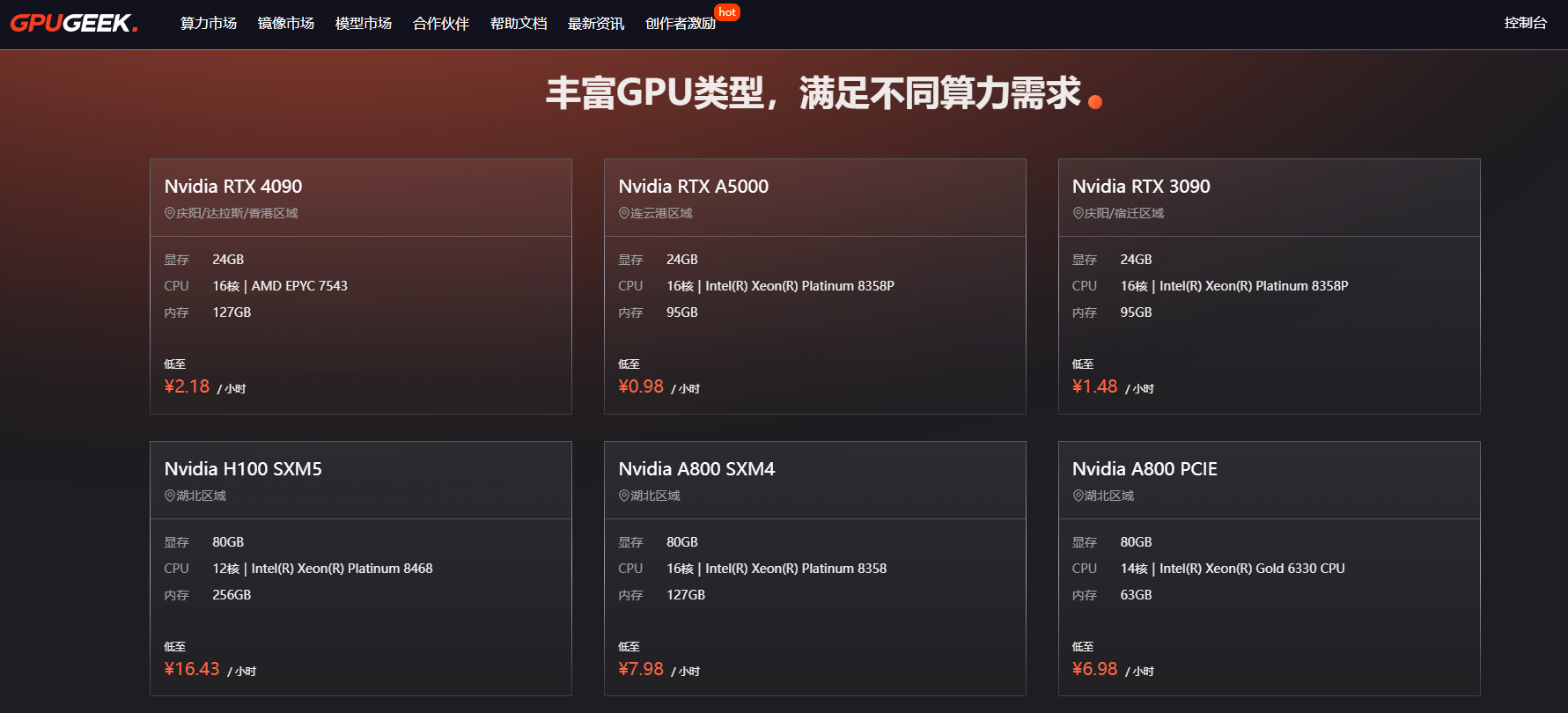
依托香港、達拉斯、慶陽、宿遷四大核心數據中心,GpuGeek 形成 “本地接入 + 跨境優化” 的全球算力網絡:
- 就近接入:國內用戶訪問海外站點時,流量經香港節點中轉,延遲從平均 300ms 降至 80ms 以下;
- 跨境加速:海外節點與國內集群通過專屬鏈路互聯,跨國模型鏡像拉取速度提升 5 倍,10GB 級數據集傳輸耗時從 2 小時壓縮至 20 分鐘;
- 合規性保障:內置數據加密與訪問審計模塊,支持跨境數據權限可視化配置,滿足科研數據合規傳輸要求。
2.3 彈性計費與智能調度:成本效率雙平衡
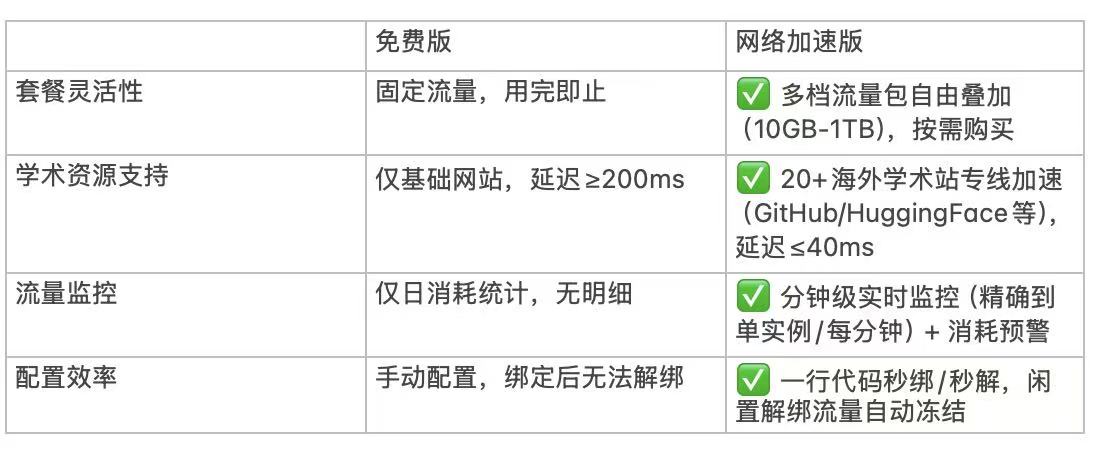
區別于傳統云平臺的固定帶寬收費模式,GpuGeek 提供動態加速策略:
- 按實際加速流量計費,單價低至 0.1 元 / GB,無保底消費;
- 支持競價模式獲取閑置加速資源,成本最高可降低 70%;
- 智能識別訪問峰值,自動擴容帶寬資源,避免突發流量導致的鏈路擁塞。
三、網絡加速實戰指南:從配置到調優全流程
3.1 快速上手:3 步激活加速服務
- 控制臺配置:進入 GpuGeek 管理后臺(GpuGeek官網注冊入口),在 “網絡加速” 模塊選擇目標站點(如github.com),勾選 “啟用學術加速”;
- 實例關聯:在創建 GPU 實例時,選擇已配置加速策略的網絡模板,支持批量綁定多實例;
 選擇需要的計費模式、配置、卡、數據盤大小以及鏡像等,核查配置后點擊【創建實例】
選擇需要的計費模式、配置、卡、數據盤大小以及鏡像等,核查配置后點擊【創建實例】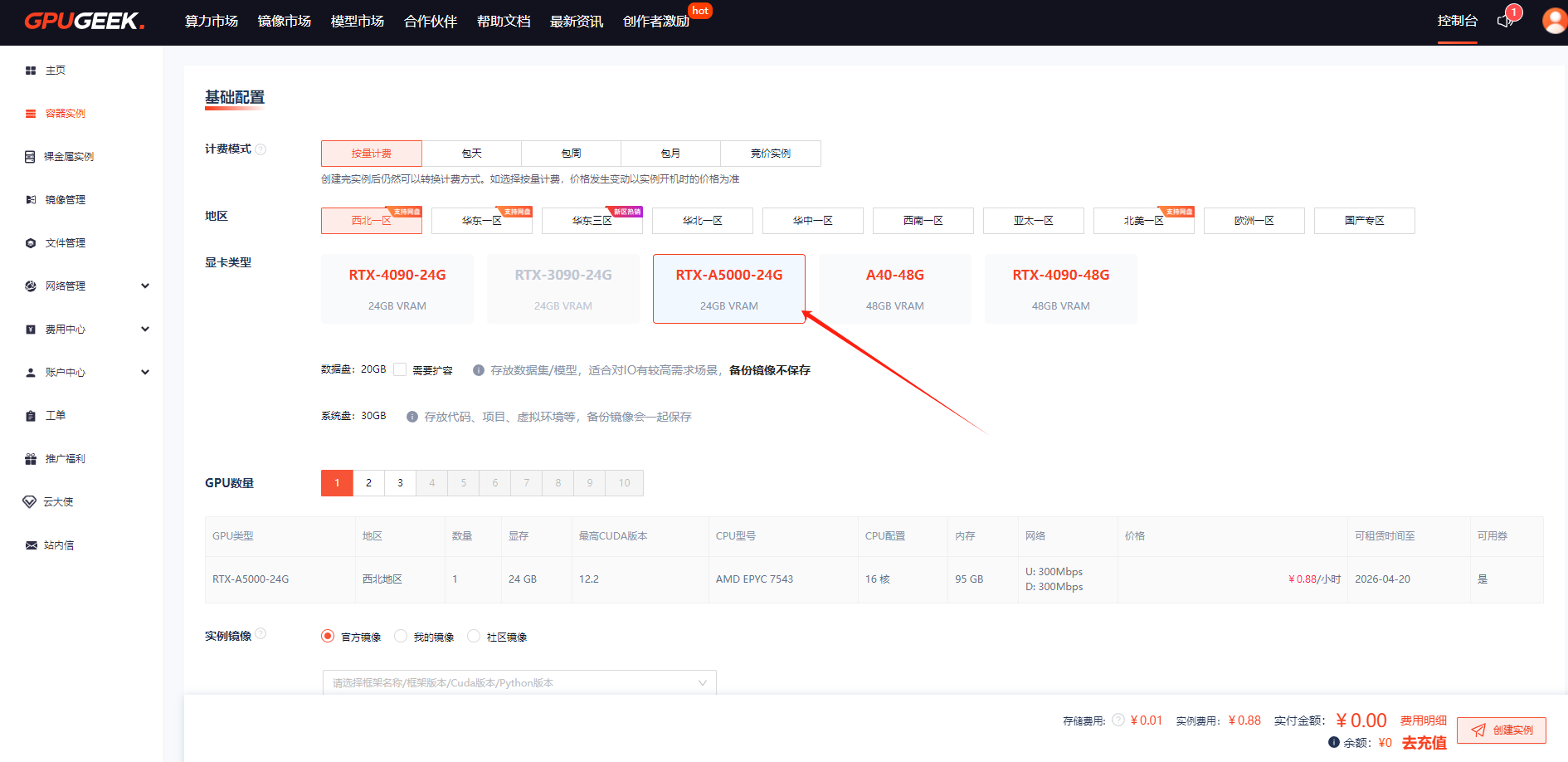
- 效果驗證:通過
speedtest.gpugeek.com實時監測下載速度,對比加速前后的 Ping 值與吞吐量。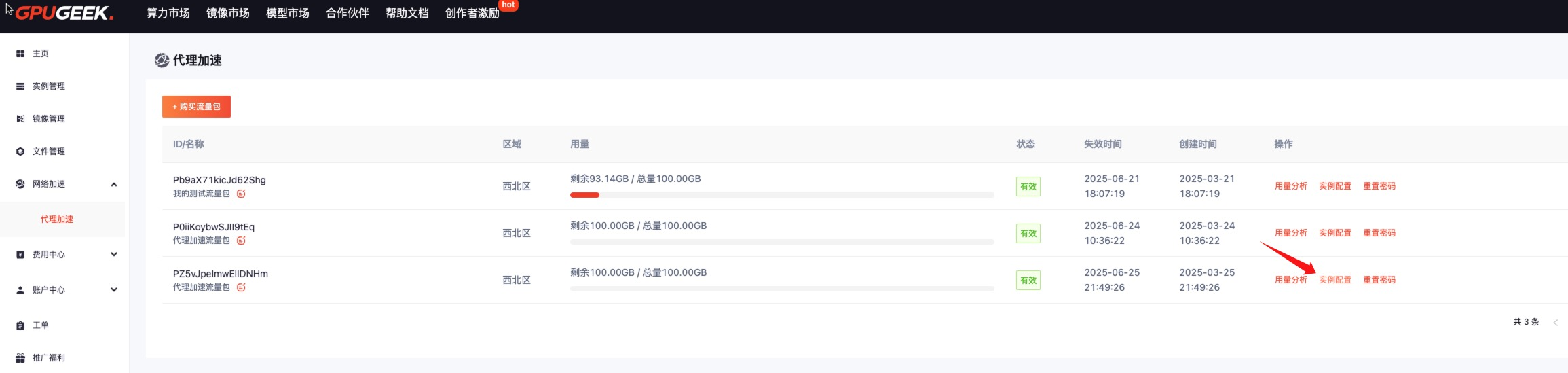
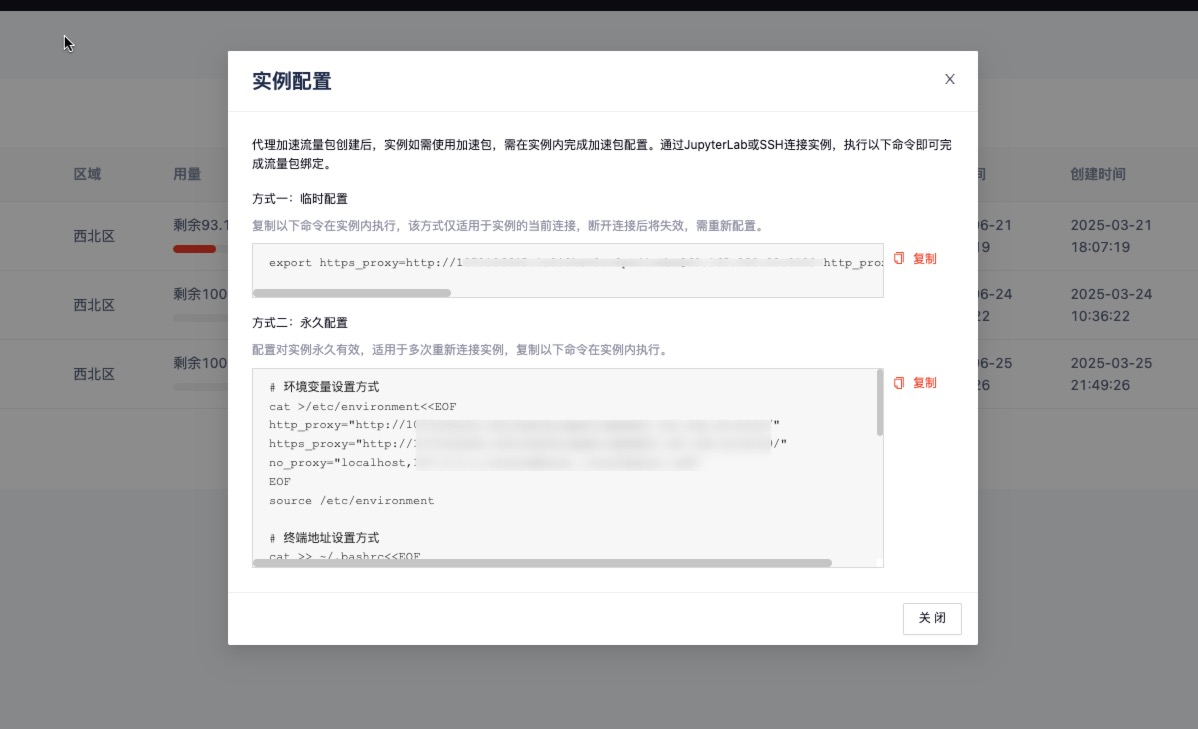
-
提示:當前可用加速地址如下,若如下地址中若存在您所需的加速地址,可在GpuGeek控制臺?提交工單,內容填寫需要新增加速的域名或者地址后,平臺評估域名或地址合規后將進行新增加速地址。
3.2 高級技巧:定制化加速策略
- 多站點分組管理:按 “代碼托管”“模型倉庫”“文獻數據庫” 創建加速分組,針對性分配帶寬資源;
- 本地 DNS 優化:在實例內修改
/etc/resolv.conf,指向 GpuGeek 專屬 DNS 服務器(223.5.5.5),提升域名解析效率; - 流量監控與預警:通過 API 接口獲取實時流量數據,設置閾值觸發郵件預警,避免超量消費。
3.3 典型場景優化方案
| 應用場景 | 加速配置建議 | 實測效果 |
|---|---|---|
| 大規模代碼拉取 | 啟用 GitHub 專屬加速通道 | 1GB 代碼庫拉取耗時 < 3 分鐘 |
| 預訓練模型下載 | 綁定 Hugging Face 節點集群 | 10GB 模型下載速度 > 50MB/s |
| 跨國協同開發 | 選擇 “香港 + 達拉斯” 雙節點鏈路 | 遠程調試延遲 < 50ms |
3.4?網絡加速的重要性
在深度學習和模型開發過程中,網絡如同連接各個環節的橋梁,其速度和穩定性對整個流程的效率有著深遠的影響。在數據傳輸方面,無論是將海量的訓練數據從存儲設備傳輸到計算節點,還是將訓練好的模型部署到推理服務器,數據傳輸速度都至關重要。假設在訓練一個大型的自然語言處理模型時,訓練數據量達到數 TB 甚至更大,若網絡傳輸速度緩慢,僅數據傳輸這一環節就可能耗費數天的時間,大大延長了模型的訓練周期。而在模型推理階段,實時性要求較高的應用場景,如自動駕駛中的實時目標檢測、智能客服的即時響應等,快速的數據傳輸能夠確保模型及時獲取輸入數據并返回準確的推理結果,提升用戶體驗。如果網絡延遲過高,數據傳輸出現卡頓,可能導致自動駕駛系統的決策延遲,增加交通事故的風險;對于智能客服來說,延遲的響應可能會讓用戶感到不滿,影響用戶對服務的滿意度。此外,在與外部資源交互時,如從 Github 獲取開源代碼、從學術數據庫下載相關文獻等,網絡速度也直接影響著開發的進度和效率。如果網絡不穩定,頻繁出現連接中斷或下載失敗的情況,會嚴重干擾開發者的工作節奏,降低開發效率 。

四、網絡加速賦能多元 AI 場景
4.1 高校科研:讓文獻與代碼觸手可及
某 985 高校 AI 實驗室使用 GpuGeek 加速后,師生訪問 Google Scholar 的文獻下載速度從 10KB/s 提升至 2MB/s,GitHub 上的協同代碼提交沖突率下降 40%。通過課程專屬鏡像與加速策略綁定,實驗環境部署時間從 4 小時縮短至 20 分鐘,算力資源利用率提升 65%。
4.2 企業開發:突破跨境協作壁壘
某金融科技公司在開發智能風控模型時,通過 GpuGeek 海外節點加速訪問彭博終端數據接口,實時數據流延遲從 1.2 秒降至 0.3 秒,模型推理響應時間優化 30%。結合競價實例的彈性加速方案,月度網絡成本降低 55%。
4.3 個人開發者:輕量化加速體驗
獨立開發者通過 GpuGeek 的免費加速額度(新用戶贈送 5GB 流量),可快速完成 Stable Diffusion 模型下載與調試,避免因網絡問題導致的開發中斷。平臺支持的本地環境鏡像(如 PyTorch 2.3+CUDA 12.4 預配置),進一步將環境搭建時間壓縮至 5 分鐘以內。
?五、經典代碼案例及解釋

5.1 代碼案例1:使用TensorFlow構建簡單的卷積神經網絡(CNN)進行圖像分類
import tensorflow as tf
from tensorflow.keras import layers, models# 構建CNN模型
model = models.Sequential([layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.MaxPooling2D((2, 2)),layers.Conv2D(64, (3, 3), activation='relu'),layers.Flatten(),layers.Dense(64, activation='relu'),layers.Dense(10, activation='softmax')
])# 編譯模型
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['accuracy'])# 打印模型結構
model.summary()解釋:此代碼使用TensorFlow構建了一個簡單的卷積神經網絡(CNN),適用于圖像分類任務。模型包含多個卷積層和池化層,用于提取圖像特征,最后通過全連接層輸出分類結果。model.compile用于配置模型的優化器、損失函數和評估指標,model.summary打印模型的結構和參數信息。
5.2 代碼案例2:使用PyTorch進行模型微調
import torch
import torchvision
import torchvision.transforms as transforms
from torchvision.models import resnet50# 加載預訓練的ResNet50模型
model = resnet50(pretrained=True)# 凍結所有參數
for param in model.parameters():param.requires_grad = False# 替換最后的全連接層以適應新的分類任務
num_classes = 10
model.fc = torch.nn.Linear(model.fc.in_features, num_classes)# 定義損失函數和優化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.fc.parameters(), lr=0.001)# 數據加載和預處理
transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=32, shuffle=True)# 訓練模型
for epoch in range(5):model.train()for images, labels in train_loader:optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()解釋:此代碼展示了如何使用PyTorch對預訓練的ResNet50模型進行微調。首先加載預訓練模型并凍結其所有參數,然后替換最后的全連接層以適應新的分類任務。定義損失函數和優化器后,對模型進行訓練。通過微調,可以在特定數據集上快速獲得性能較好的模型。
5.3 代碼案例3:使用OpenCV進行圖像預處理
import cv2
import numpy as np# 讀取圖像
image = cv2.imread('example.jpg')# 調整圖像大小
resized_image = cv2.resize(image, (224, 224))# 轉換顏色空間為灰度
gray_image = cv2.cvtColor(resized_image, cv2.COLOR_BGR2GRAY)# 對圖像進行歸一化
normalized_image = gray_image / 255.0# 顯示處理后的圖像
cv2.imshow('Processed Image', normalized_image)
cv2.waitKey(0)
cv2.destroyAllWindows()解釋:此代碼使用OpenCV庫對圖像進行預處理。首先讀取圖像,然后調整其大小為224×224像素,接著將圖像轉換為灰度圖像,并對像素值進行歸一化處理,使其范圍在[0,1]之間。這些預處理步驟有助于提高圖像數據的質量,為后續的深度學習模型訓練做好準備。
5.4 代碼案例4:使用TensorFlow構建并訓練一個循環神經網絡(RNN)進行文本生成
import tensorflow as tf
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, SimpleRNN, Dense# 示例文本數據
text = "Hello, this is a sample text for training an RNN model. It will generate new text based on the training data."# 文本預處理
tokenizer = Tokenizer()
tokenizer.fit_on_texts([text])
total_words = len(tokenizer.word_index) + 1# 創建輸入序列
input_sequences = []
for line in text.split('.'):token_list = tokenizer.texts_to_sequences([line])[0]for i in range(1, len(token_list)):n_gram_sequence = token_list[:i+1]input_sequences.append(n_gram_sequence)# 填充序列
max_sequence_len = max([len(x) for x in input_sequences])
input_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# 創建輸入和標簽
X, y = input_sequences[:,:-1], input_sequences[:,-1]
y = tf.keras.utils.to_categorical(y, num_classes=total_words)# 構建RNN模型
model = Sequential()
model.add(Embedding(total_words, 100, input_length=max_sequence_len-1))
model.add(SimpleRNN(150))
model.add(Dense(total_words, activation='softmax'))# 編譯模型
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# 訓練模型
model.fit(X, y, epochs=100, verbose=1)# 生成新文本
def generate_text(seed_text, next_words, max_sequence_len):for _ in range(next_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')predicted = model.predict(token_list, verbose=0)predicted_word_index = np.argmax(predicted, axis=1)[0]for word, index in tokenizer.word_index.items():if index == predicted_word_index:output_word = wordbreakseed_text += " " + output_wordreturn seed_textprint(generate_text("Hello", 5, max_sequence_len))解釋:
-
文本預處理:使用
Tokenizer將文本轉換為單詞索引序列,然后生成輸入序列。通過pad_sequences將所有序列填充到相同的長度。 -
模型構建:構建一個簡單的RNN模型,包含嵌入層、RNN層和全連接層。嵌入層將單詞索引映射到固定大小的密集向量,RNN層負責學習序列中的模式,全連接層輸出每個單詞的概率分布。
-
模型訓練:使用
categorical_crossentropy作為損失函數,adam作為優化器,訓練模型。 -
文本生成:通過給定的種子文本,模型預測下一個單詞,逐步生成新文本。
5.5 代碼案例5:使用PyTorch進行Transformer模型的微調
import torch
import torch.nn as nn
import torch.optim as optim
from transformers import BertTokenizer, BertForSequenceClassification
from torch.utils.data import DataLoader, Dataset# 示例數據
texts = ["This is a positive review.", "This is a negative review."]
labels = [1, 0] # 1 for positive, 0 for negative# 數據集類
class TextDataset(Dataset):def __init__(self, texts, labels, tokenizer, max_len):self.texts = textsself.labels = labelsself.tokenizer = tokenizerself.max_len = max_lendef __len__(self):return len(self.texts)def __getitem__(self, idx):text = self.texts[idx]label = self.labels[idx]encoding = self.tokenizer.encode_plus(text,max_length=self.max_len,padding='max_length',truncation=True,return_attention_mask=True,return_tensors='pt')return {'input_ids': encoding['input_ids'].flatten(),'attention_mask': encoding['attention_mask'].flatten(),'labels': torch.tensor(label, dtype=torch.long)}# 加載預訓練的BERT模型和分詞器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased')# 創建數據集和數據加載器
dataset = TextDataset(texts, labels, tokenizer, max_len=128)
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)# 定義優化器和損失函數
optimizer = optim.Adam(model.parameters(), lr=2e-5)
criterion = nn.CrossEntropyLoss()# 微調模型
model.train()
for epoch in range(3):for batch in dataloader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask, labels=labels)loss = outputs.lossoptimizer.zero_grad()loss.backward()optimizer.step()# 評估模型
model.eval()
with torch.no_grad():for batch in dataloader:input_ids = batch['input_ids']attention_mask = batch['attention_mask']labels = batch['labels']outputs = model(input_ids, attention_mask=attention_mask)logits = outputs.logitspredictions = torch.argmax(logits, dim=1)print(f"Predicted: {predictions}, Actual: {labels}")解釋:
-
數據預處理:使用
BertTokenizer對文本進行分詞和編碼,創建自定義的數據集類TextDataset,并使用DataLoader加載數據。 -
模型加載和配置:加載預訓練的BERT模型
BertForSequenceClassification,并定義優化器和損失函數。 -
微調模型:對模型進行訓練,通過反向傳播更新模型參數。
-
模型評估:在評估模式下,對模型進行評估,輸出預測結果和實際標簽。

5.6 代碼案例6:使用OpenCV和TensorFlow進行實時圖像識別
import cv2
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import load_model# 加載預訓練的模型
model = load_model('path_to_your_model.h5')# 定義圖像預處理函數
def preprocess_image(image):image = cv2.resize(image, (224, 224))image = image.astype('float32') / 255.0image = np.expand_dims(image, axis=0)return image# 打開攝像頭
cap = cv2.VideoCapture(0)# 循環讀取攝像頭幀
while True:ret, frame = cap.read()if not ret:break# 預處理圖像processed_frame = preprocess_image(frame)# 使用模型進行預測predictions = model.predict(processed_frame)predicted_class = np.argmax(predictions, axis=1)[0]# 在圖像上顯示預測結果cv2.putText(frame, f'Predicted Class: {predicted_class}', (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)# 顯示圖像cv2.imshow('Real-Time Image Recognition', frame)# 按下'q'鍵退出if cv2.waitKey(1) & 0xFF == ord('q'):break# 釋放攝像頭并關閉窗口
cap.release()
cv2.destroyAllWindows()解釋:
-
模型加載:加載預訓練的深度學習模型,用于圖像識別。
-
圖像預處理:定義一個函數
preprocess_image,對攝像頭捕獲的圖像進行預處理,包括調整大小、歸一化和擴展維度。 -
實時圖像捕獲:使用OpenCV打開攝像頭,循環讀取每一幀圖像。
-
模型預測:對每一幀圖像進行預處理后,使用模型進行預測,并將預測結果顯示在圖像上。
-
顯示和退出:使用OpenCV顯示圖像,并在按下'q'鍵時退出程序。
這些代碼案例涵蓋了從基礎到高級的深度學習應用,幫助你更好地理解和應用這些技術。
六、總結:重新定義 AI 開發的 “網絡效率”
GpuGeek 的網絡加速功能不僅解決了 “能不能訪問” 的基礎問題,更通過精細化的流量管理、全球化的節點布局、智能化的成本控制,構建了一套適配 AI 開發全流程的網絡解決方案。當算力與網絡效率形成協同,開發者得以徹底擺脫基礎設施的桎梏,將精力聚焦于算法創新與模型優化。
立即體驗 GpuGeek 網絡加速,注冊即享 20GB 免費加速流量,解鎖絲滑代碼拉取與模型下載體驗:
GpuGeek官網地址
在 AI 開發的競速賽中,網絡加速已成為決定勝負的關鍵賽道。GpuGeek 用技術創新證明:當每一個數據請求都能以最優路徑抵達,AI 的無限可能正從這里開始。
6.1?附錄:常見問題解答(FAQ)
Q1:如何避免訓練任務被競價實例中斷?
A1:使用--checkpoint-interval 300參數每5分鐘保存檢查點,任務中斷后可通過gpugeek job resume <job_id>自動恢復。
Q2:是否支持私有化部署?
A2:企業版支持本地化部署,最低配置為8卡A100集群。
Q3:如何優化跨國數據傳輸成本?
A3:啟用跨區域數據同步功能,香港與法蘭克福節點間傳輸免費,其他區域按0.01元/GB計費。
Q4:已經釋放的實例還能找回數據嗎??
您好,實例釋放后無法找回數據。
Q5:服務器CPU跑滿了怎么辦??
首先要查看是哪些進程/應用在消耗 CPU。
Q6:JupyterLab打不開是怎么回事??
通過鏡像導入功能導入的鏡像,默認不會安裝 jupyterlab,如果需要安裝 jupyterlab,請自行安裝配置。
官方鏡像中默認吧?jupyterlab?安裝到了?base?虛擬環境中,如果您對?base?虛擬環境做了修改,比如修改?python?版本、安裝其它包導致與?jupyterlab?沖突,卸載?jupyter、誤操作等,會引起已安裝的?jupyter?損壞,從而導致無法訪問到?jupyter,下面給出排查和解決方法。
# 1. 先查看 base 環境中的 Python 版本是否與實例創建時,選擇的鏡像中的Python版本是否一致。
(base) root@492132307857413:/# python -V
Python 3.10.10# 2. 使用 `pip list | grep jupyter` 命令來查看當前安裝的 jupyter 是否缺少某個包,與下面做對比
(base) root@492132307857413:/# pip list | grep jupyter
jupyter_client 8.6.0
jupyter_core 5.5.0
jupyter-events 0.9.0
jupyter-lsp 2.2.0
jupyter_server 2.11.1
jupyter_server_terminals 0.4.4
jupyterlab 4.0.8
jupyterlab-language-pack-zh-CN 4.0.post3
jupyterlab-pygments 0.2.2
jupyterlab_server 2.25.0#3. 如果缺少某個包,則通過 pip install 包名 進行安裝,例如缺少 jupyter_core 組件,則使用如下命令進行安裝
(base) root@492132307857413:/# pip install jupyter_core#4. 安裝完成后使用如下命令重啟 jupyterlab
(base) root@492132307857413:/# supervisord ctl restart jupyterlab#5. 然后查看 jupyterlab 運行狀態,如果狀態為 Running 則正常,然后去控制臺進行訪問
(base) root@492132307857413:/# supervisord ctl status jupyterlab
jupyterlab Running pid 40, uptime 0:15:43#如果為其它狀態則提交工單讓技術進行排查
Q7:為什么我不能調用GPU??
在進行深度學習訓練時發現沒有使用?GPU,可以嘗試以下步驟進行故障排查和解決:
1.確保可以通過 nvidia-smi 命令看到 GPU 信息
nvidia-smi
2.檢查當前代碼運行的實例環境中已正確安裝了您代碼所使用的框架,(如TensorFlow、PyTorch等)支持GPU
TensorFlow框架檢查
import tensorflow as tf
print("Num GPUs Available: ", len(tf.config.experimental.list_physical_devices('GPU')))
PyTorch框架檢查
import torch
print(torch.cuda.is_available())
3.檢查安裝的CUDA版本是否與您的深度學習框架版本兼容
官方所提供的鏡像,包含了框架、CUDA、Python版本,并且都是框架官方所支持的版本)。
如果您在官方鏡像中又安裝了其它版本的框架,那么請檢查下對應框架的官方對于您所安裝的框架版本對當前的CUDA版本兼容性。
查看CUDA版本
nvcc -V
4.在訓練代碼中顯性指定GPU設備
TensorFlow框架
with tf.device('/GPU:0'):model.fit(...)
PyTorch框架
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 確保數據也被發送到GPU
inputs, labels = data[0].to(device), data[1].to(device)
5.設置環境變量?對于某些框架,可能需要設置環境變量來指示使用GPU;例如,對于CUDA,可以設置:
export CUDA_VISIBLE_DEVICES=0
Q8:實例通過鏡像還原后SSH、JupyterLab無法連接??
實例通過鏡像還原后,如果無法連接?SSH?或?JupyterLab,建議您先重啟下實例,重啟成功后再進行嘗試連接,重啟后如果還是無法連接,麻煩創建工單讓技術排查具體問題。
如果還原鏡像選擇的是導入的自定義鏡像,那么自定義鏡像中默認不會安裝?JupyterLab?,但是?SSH?應該正常使用,如果?SSH?也無法正常使用,同樣去創建工單讓技術排查具體問題。
Q9:HuggingFace緩存?
默認HuggingFace的緩存模型會保存在/root/.cache目錄,可以通過以下方式將模型的緩存保存到數據盤,具體方法為:
#終端中執行:
export HF_HOME=/gz-data/hf-cache/#或者Python代碼中執行:
import os
os.environ['HF_HOME'] = '/gz-data/hf-cache/'
6.2?寫在最后
如果你是一名 AI 開發者,或是正在從事與深度學習、大模型開發相關的工作,不妨嘗試使用 GpuGeek 平臺。相信它會為你的工作帶來全新的體驗和高效的解決方案,助力你在 AI 領域取得更大的突破和成就 。












超市管理系統 (正式版)(指針)(數據結構)(清屏操作)(文件讀寫))
![[服務器面板對比] 寶塔、aaPanel、Plesk、cPanel 哪家強?功能、性能與價格橫評 (2025)](http://pic.xiahunao.cn/[服務器面板對比] 寶塔、aaPanel、Plesk、cPanel 哪家強?功能、性能與價格橫評 (2025))

工業設備智能運維系統解決方案)



