
隨著 GenAI 技術不斷的發展和演進,人工智能技術廣泛地被應用在呼叫中心服務領域,主要包括虛擬坐席(即自助服務)、坐席助手和呼叫中心運營的數據洞察和智能分析。本博客主要針對自助服務應用場景的實現。

1. 傳統自助服務系統瓶頸
1.1 交互方式僵化
-
交按鍵導航依賴:用戶需通過固定數字按鍵選擇菜單,操作路徑冗長且容錯率低,易因誤操作重復流程。
-
缺乏自然語言理解:無法解析口語化表達或多輪對話,用戶需嚴格遵循預設選項,靈活性差。
-
單向輸出為主:信息傳遞多為語音播報,難以整合圖文、鏈接等多媒體形式,信息接收效率低。
1.2 智能化能力缺失
-
無主動學習與迭代:傳統系統依賴人工規則配置,無法通過用戶行為數據優化流程,服務模式靜態化。
-
個性化服務不足:無法基于用戶歷史記錄、偏好或實時情境(如位置、設備)提供定制化解決方案。
-
意圖識別能力弱:對復雜或模糊需求(如“我要改套餐但保留原號碼”)難以精準定位,導致頻繁轉人工。
1.3 數據處理與洞察力薄弱
-
數據分析表層化:僅能統計基礎指標(如接通率、平均處理時長),缺乏用戶情緒分析、需求聚類等深度洞察。
-
實時反饋缺失:無法動態監測用戶不滿信號(如語音急促、重復詢問)并觸發干預策略(如優先轉接人工)。
1.4 運營效率與成本瓶頸
-
維護復雜度高:菜單結構調整需專業技術支持,更新周期長,難以快速響應業務變化。
-
人力依賴性強:簡單問題無法有效分流,導致人工坐席負擔過重,運營成本居高不下。
2. 基于 GenAI 的智能客服自助系統設計需要考慮的因素
-
首先要綜合考慮智能客服接入的渠道有哪些,如電話,文字聊天,短信,社交媒體,郵件等。這些渠道可以分成兩個大類,一是語音,二是文本。
-
如果接入渠道支持語音,則在整體實現過程中增加 NLP 語音轉文字的組件,未來可以通過支持語音的大語言模型,本次設計采用 AWS Lex 服務作為 NLP模塊。
-
考慮大語言模型延時對客戶體驗的影響,盡量采用延時低的模型。
-
考慮多種語音混合的場景及需要。
-
由于語音內容寬泛需要制定策略來做意圖識別,更精準地捕獲客戶的實際意圖。
3. 基于 Amazon Bedrock 的智能客服自助系統架構設計
3.1 需求拆解
首先需要對客戶需求進行分析并確定不同要求采用不同的對應方式。可以采用大語言模型 LLM 實現智能識別,代替傳統 IVR 按鍵式意圖分類,確定意圖后根據不同的意圖采用不同的應對模式。
如果是咨詢類問題,可以采用 RAG 知識庫方式通過 GenAI 模式來實現智能應答,如客戶問題不在知識范圍內可以再轉人工坐席服務,這樣可以大大減輕坐席的壓力;如果是操作類的問題,比如賬戶余額查詢,修改密碼等可以利用基于大語言模型 LLM 的 Agent 代理服務來提供智能服務;如果需要人工服務,可以直接轉接 Amazon Connect 系統并有空閑的坐席提供服務;如果識別到是閑聊或敏感話題,則可以按照客戶策略進行警告提醒或直接終止服務。
當然,在服務過程中往往需要實現多輪問答,為更好地理解客戶的問題,并結合上下文,可以啟用 Prompt Catching 功能實現緩存。這些都可以通過智能 LLM 編排來實現,見圖 1。

圖 1. 客戶自助服務需求分析
3.2 解決方案 High Level 設計
鑒于目前 Amazon Connect 服務的原理及設計規則,采用 Amazon Lex 作為 NLP 語音轉文字的模塊,首先由 Lex 語音轉文字并在 Lex 中通過調用 Lambda 來實現調用 Amazon Bedrock 上的 Claude 3 Haiku 模型實現意圖分類,不同的意圖會對應不同的處理流程,詳見圖 2。
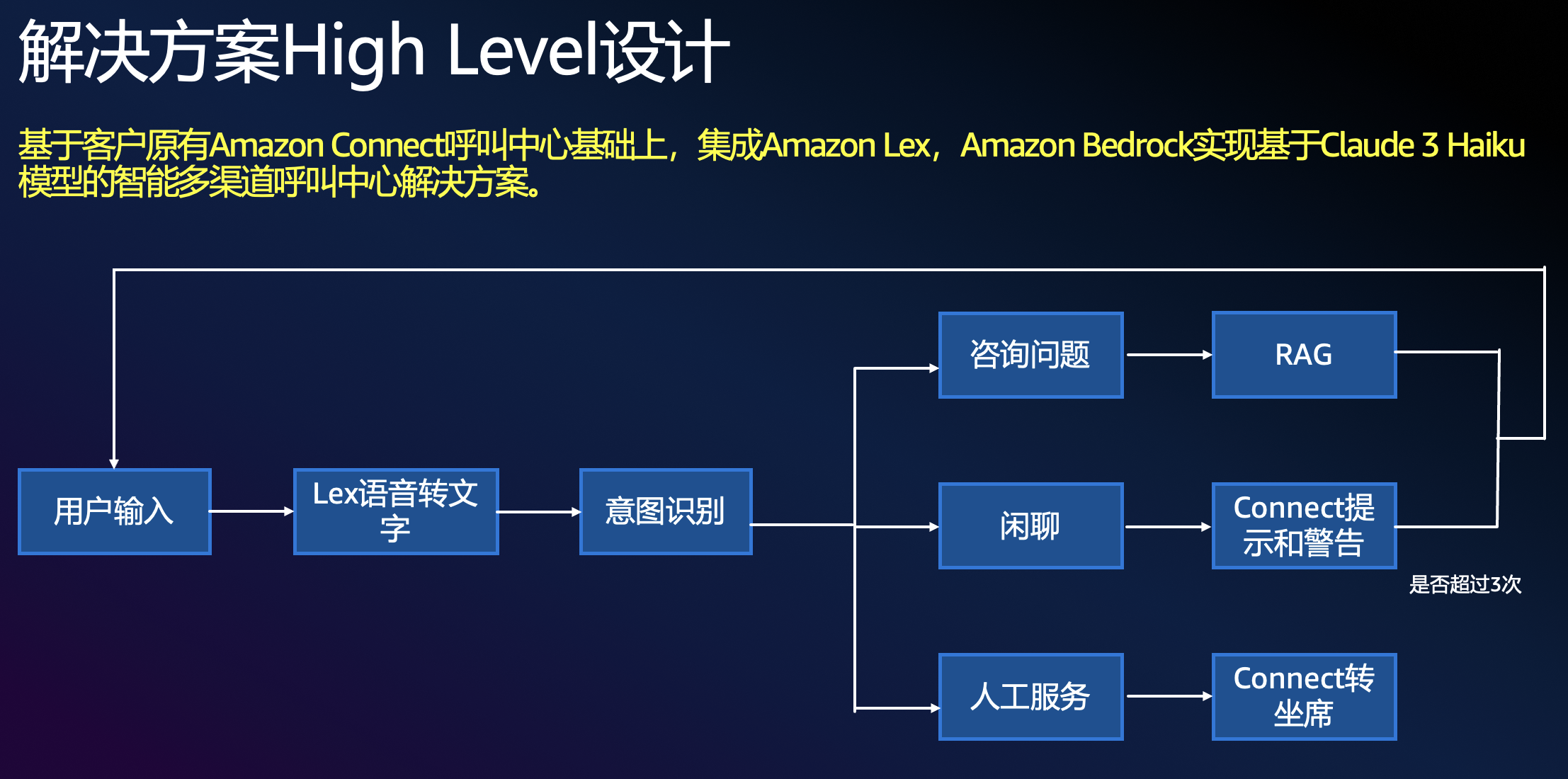
圖 2. 解決方案 High Level 設計
3.3 系統架構設計
整個解決方案可以同時支持電話及文字聊天等多渠道呼叫中心解決方案,不同的接入渠道采用統一的流程管理。整體方案設計中以 Amazon Connect 作為呼叫中心平臺核心服務平臺,同時采用 Amazon Lex 作為自主服務組件,Amazon Lex 以及 Amazon Connect Content Flow 通過調用 Lambda 來實現對 Claude 模型的調用以及 Amazon Bedrock 知識庫的調用。詳細流程見圖 3。
業務流程說明:
1、 通過內部 CRM 系統整理知識庫文件并放入 S3,采用 Amazon Bedrock 知識庫服務并同步 S3 數據源。
2、客戶通過電話或文字撥打熱線進入 Amazon Connect 服務。
3、Amazon Connect 調用 Lex 做自動機器人實現 ASR 語音識別。
4、Amazon Lex 把識別到的客戶意圖通過 Lambda 調用 Amazon Bedrock。
5、通過 Amazon Bedrock 調用 Claude 3 Haiku 并返回客戶意圖。
-
如果轉人工直接轉坐席如果閑聊提示三次后掛機;
-
如果是知識庫問題,Connect 調用 Lambda。
6、Lambda 調用 Amazon Bedrock 知識庫做 RAG 查詢,然后把查詢結果再交給 Claude 3 Haiku 生成問題結果,并返回給客戶。
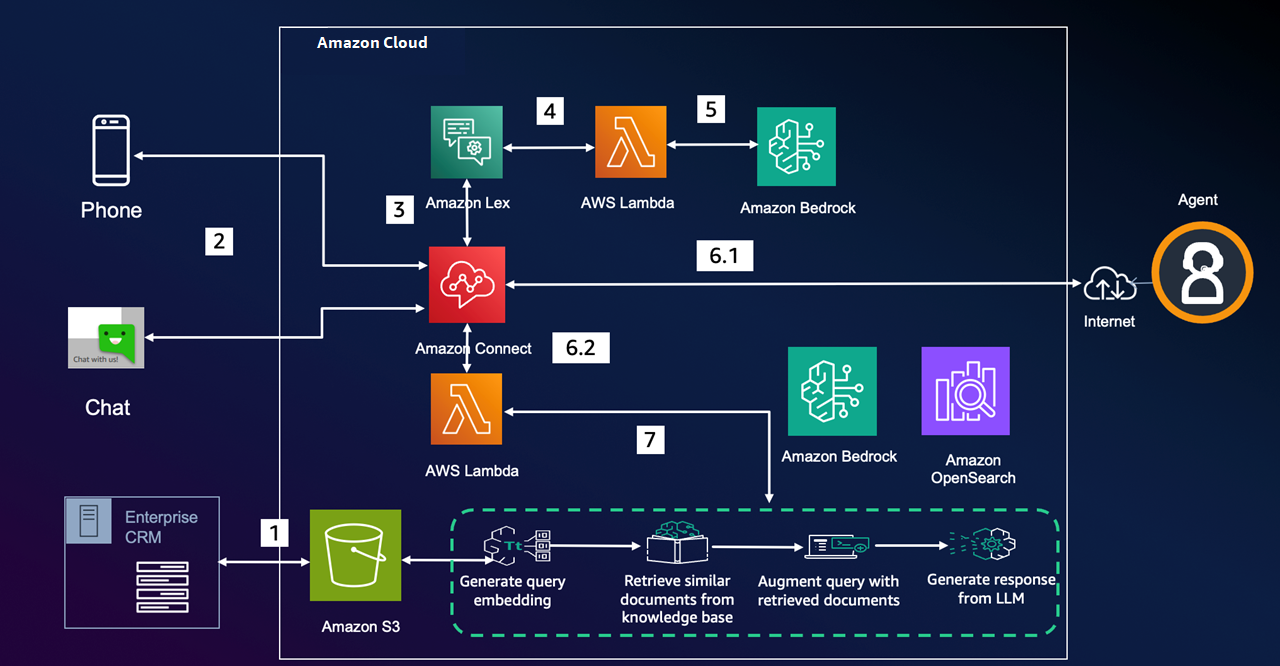
圖 3. 詳細系統架構設計圖
3.4 意圖識別實現解析
實現意圖識別可以采用提示詞工程來實現,可以采用專用的意圖識別小模型來實現,也可以通過微調來實現,也可以用一個 RAG 知識庫來實現。選擇實現方法取決于意圖的復雜度以及是否是有多級別的意圖識別。如果比較簡單的就可以采用提示詞工程直接實現。如圖 4 所示是本次實踐的意圖識別,分為咨詢、人工、閑聊三種類型,因此采用的是提示詞來直接實現。
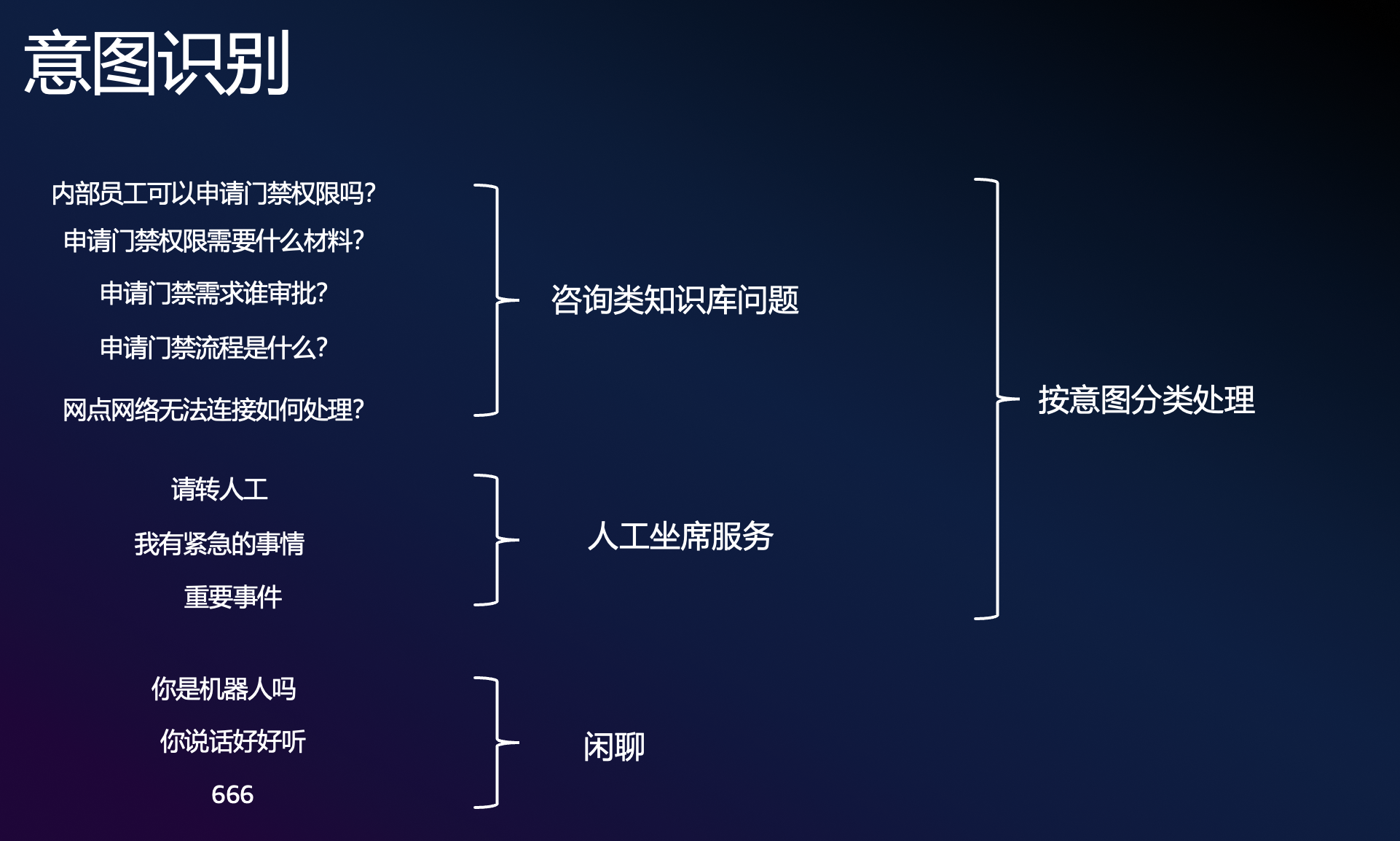
圖 4. 客戶意圖 Sample
以上是對上述 3 類模型進行意圖識別的提示詞,具體如下:
classification_prompt = """You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question. Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.Here are the search results in numbered order:<content>{{CUSTOMER_CONTENT}}</content>The following is the previous conversation history (between the customer and you). If there is no conversation history, it will be empty:<customer_history>{{CUSTOMER_HISTORY}}</customer_history>Here is the customer query:<customer_query>{{CUSTOMER_QUERY}}</customer_query>Your job is to answer the user's question as concisely as possible.You must answer the question in Chinese.You must output your answer in the following format. Place your answer within <answer> tags"""
3.5 模型選擇解析
基于呼叫中心服務的特殊性,如何選擇最佳的模型對客戶體驗至關重要。呼叫中心實時性是最重要的指標,如果延時太長或通話中抖動嚴重會大大影響客戶體驗,同時呼叫中心業務場景相當明確,大部分模型都能符合要求。鑒于這些需求,選擇模型最重要的指標為以下 3 個:
-
模型延時性能指標
-
模型速度性能指標
-
模型的價格指標
本次實現采用的是 Claude 3 Haiku。Amazon Nova Micro、Amazon Nova Lite 模型也非常適合這個場景,大家可以根據需要自行選擇。
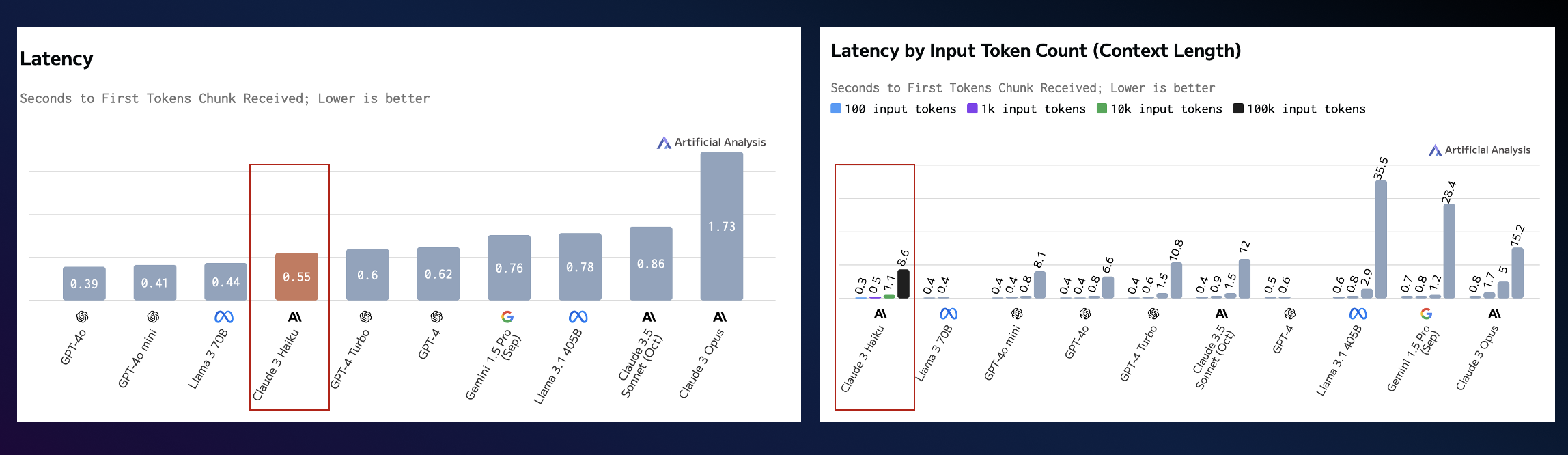
圖 5. 模型延時性能比較
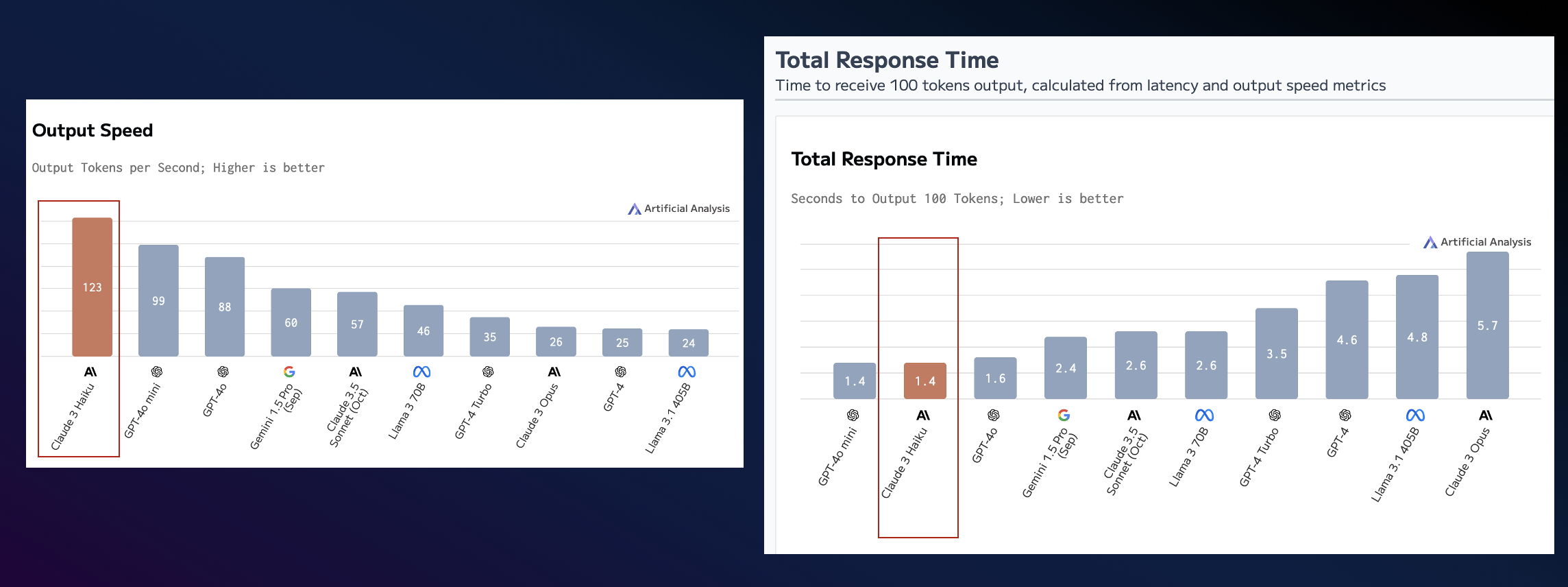
圖 6. 模型速度性能比較
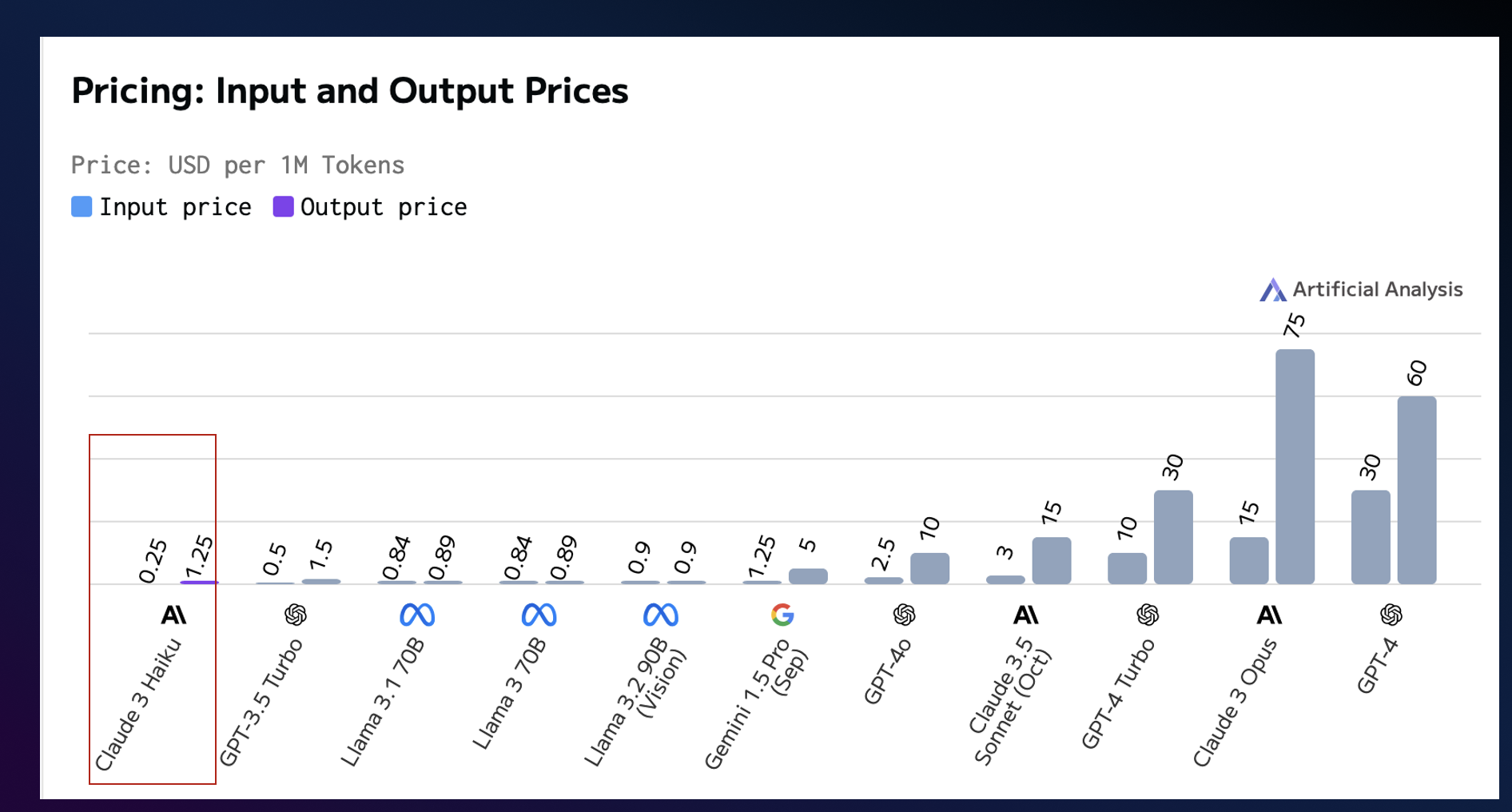
圖 7. 模型價格比較
*以上信息來源自:AI Model & API Providers Analysis | Artificial Analysis
3.6 如何實現 Prompt Catching 解析
目前 Amazon Bedrock 已經發表了 Prompt Catching 功能,原則上優先采用該功能。如果該功能不符合客戶目標或在客戶所在的 Region 沒有發布可以采用如下方式來實現并簡化 Prompt Catching 的實現。
常規的實現方式是通過 DynamoDB 來存儲上下文對話,通過代碼來實現 Prompt 存儲 DynamoDB,并在下一次調用時來讀取,通過一個唯一 ID 來標識 Session。整個過程需要額外的 DynamoDB 服務費用,同時需要編寫代碼來控制,同時要維護 Session 的生命周期。
針對 Amazon Connect 在其 Contact Flow 設計過程中支持隨路數據,用來保存當前 Session 的信息,比如主角號碼、被叫號碼等,這個隨路數據也是 Amazon Connect 與 Amazon Lex、Amazon Lambda 等服務傳遞和返回參數的實現原理,該隨路數據的數據格式和內容支持自定義,且完全基于 Session 來控制,當前會話結束后會自動清除數據。
這和 Prompt Catching 實現機制完全匹配,因此通過隨路數據自定義一個字段來存放 Prompt 即可,且這部分不會產生任何的額外費用,同時 Session 生命周期也不用自己管理,由 Amazon Connect 服務來自動維護,大大節省了成本,并簡化了實現的難度。
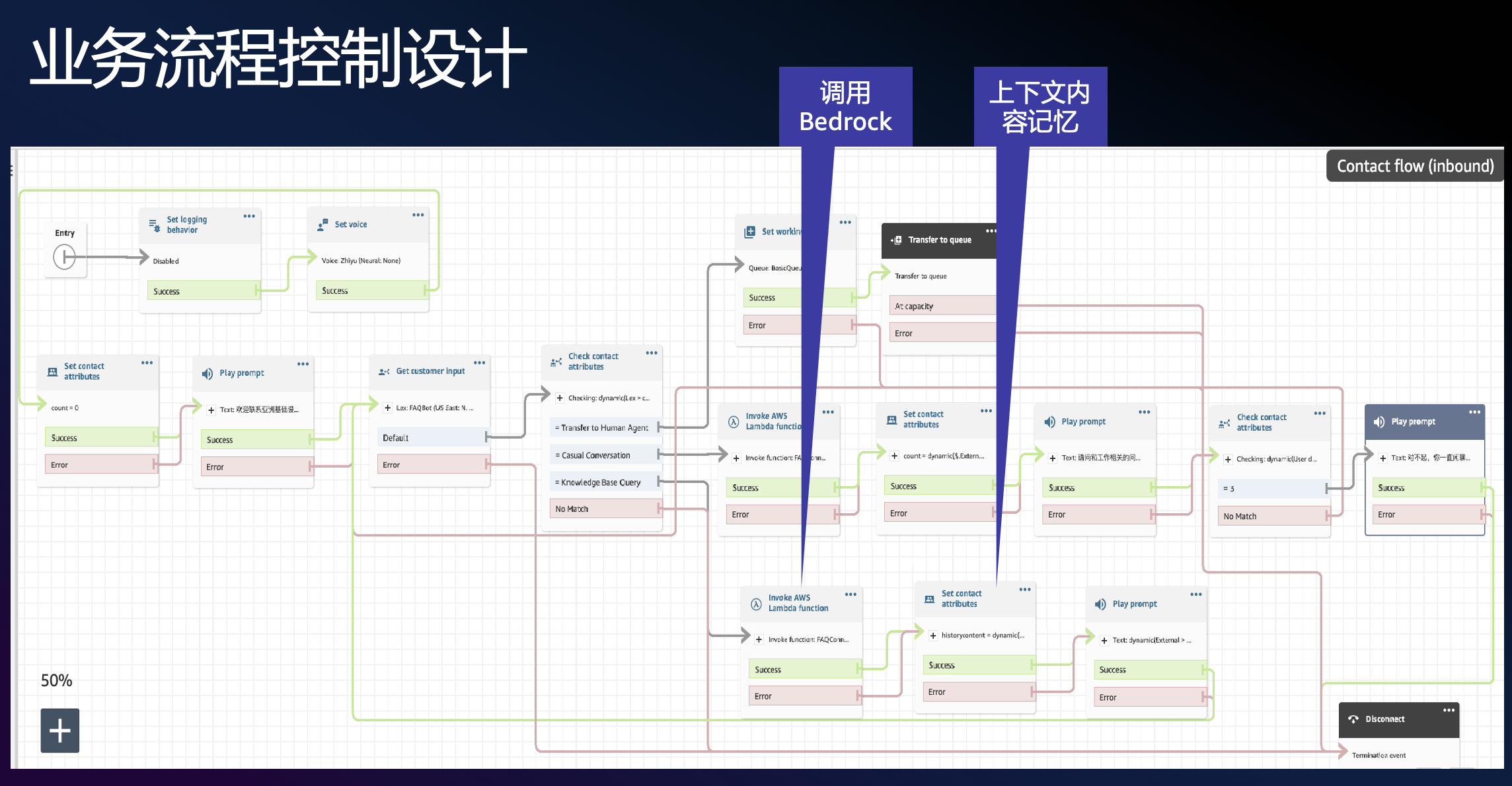
圖 8. 采用 Amazon Connect 隨路數據實現上下文記憶
4. 解決方案成本分析
針對采用傳統 IVR 及人工的呼叫中心以及采用基于 GenAI 的智能解決方案做了詳細的成本分析。
傳統解決方案主要成本:
-
大量的人工費用,包括人員費用、人員對應的場地、設備等費用,這部分費用及其昂貴。
-
通信費用,由于人工服務或者傳統 IVR 模式的自助服務效率比較低,解決一個客戶問題需要更長的通話時長來完成一個業務,同時也會因為重復的提示和引導導致通話時長過長,這將產生大量的通話費用。
基于 GenAI 智能客服解決方案優勢:
-
由于 AI 的引入,更多的業務類型可以采用自助的服務來提供服務,只有非常緊急或復雜的業務才轉由人工來服務。這可以大大節省人工費用支出,也可以大大提升人工坐席效率。
-
可以大大降低每個通話的平均通話時長,通過智能意圖識別快速捕捉客戶意圖,大大減少通信費用開支。
-
雖然增加了 GenAI 服務費用,但由于亞馬遜云科技 GenAI 成本優勢,可以減少這部分開支,同時相對于采用 GenAI 技術節省的通信費用和人力成本,這些費用不是一個數量級,可以大大節省整體費用。
-
可以提升客戶體驗和滿意度,同時提升處理速度。
以下是一個呼叫中心調用 Amazon Bedrock 上的 Claude 3 Haiku 的成本分析。
-
假設每個通話需要 8 輪,1 輪需要 2 次對話,每天 2000 通通話
-
第一輪意圖識別輸入 Token 平均 500,輸出 Token 為 50
-
第二輪 RAG 輸入 Token 平均 500,輸出 Token 為 200
那么:
-
每天輸入 Token 數量 = (500+500)82000=16000K
-
每天輸出 Token 數量 = (50+200)82000=4000K
-
每天 Haiku 輸入費用 = 0.00025*16000K/1000=$4
-
每天 Haiku 輸出費用 = 0.00125*4000K/1000=$5
5. 總結
本篇文章討論了基于亞馬遜云科技 Amazon Connect 和 Amazon Bedrock 的智能化呼叫中心架構的設計及成本分析。文章從用戶實際需求出發,提供了一個可行的解決方案,并結合技術和成本綜合考慮提供了最佳實踐。本設計充分考慮了呼叫中心的特殊性,采用提示詞工程結合 RAG 知識庫等不同技術方式,提供最佳的客戶體驗;采用 Amazon Connect 特有的隨路數據作為 Prompt 提示詞的緩存機制,簡化了提示詞緩存的實現機制;還對模型選擇和成本做了詳細的分析,讓讀者可以清楚了解成本和費用的細節。
*前述特定亞馬遜云科技生成式人工智能相關的服務僅在亞馬遜云科技海外區域可用,亞馬遜云科技中國僅為幫助您了解行業前沿技術和發展海外業務選擇推介該服務。
本篇作者

本期最新實驗《多模一站通 —— Amazon Bedrock 上的基礎模型初體驗》
? 精心設計,旨在引導您深入探索Amazon Bedrock的模型選擇與調用、模型自動化評估以及安全圍欄(Guardrail)等重要功能。無需管理基礎設施,利用亞馬遜技術與生態,快速集成與部署生成式AI模型能力。
??[點擊進入實驗] 即刻開啟 AI 開發之旅
構建無限, 探索啟程!

















)

