目錄
1、索引
1.1 查看索引
1.2 創建索引
1.3 刪除索引
1.4 索引的實現
2、事務
1、索引
索引等同于目錄,屬于針對查詢操作的一個優化手段,可以通過索引來加快查詢的速度,避免針對表進行遍歷。
主鍵、unique和外鍵都是會自動生成索引的。
索引能提高查詢的速度,但也是有代價的。
1、占用更多的空間,生成索引是需要一系列的數據結構,以及一系列的額外的數據來存儲到硬盤空間。
2、可能會降低插入、修改、刪除的速度。
1.1 查看索引
使用 show index from 表名; 來查看索引
例如:

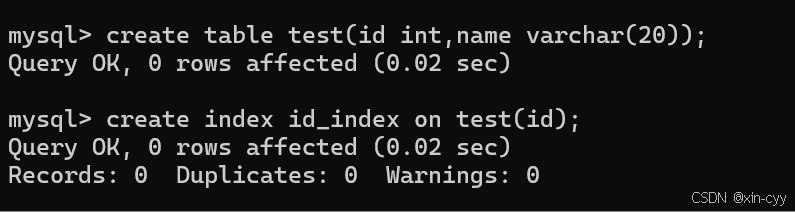
1.2 創建索引
使用 create index 索引名 on 表名(列名);?來創建索引
例如:

注意:
創建索引時,如果表中的數據很多,創建索引容易使服務器卡住,就需要另一臺機器,在MySQL中部署相同的表,創建所需要的索引,然后導入數據替換。
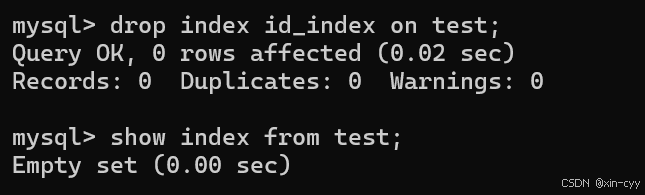
1.3 刪除索引
使用 drop index 索引名 on 表名;來刪除索引
自己創建的索引可以刪除,如果是自動創建的索引,不能刪除。
例如:
1.4 索引的實現
索引也是通過一定的數據結構實現的,MySQL的索引是一個改進的樹形結構 B+樹(N叉搜索樹)。
B樹
B樹是通過區間來進行分支的,每個節點的度都是不確定的,一個節點保存N個key,就可以劃分出N+1個區間,每個區間都可以衍生一系列的子樹。
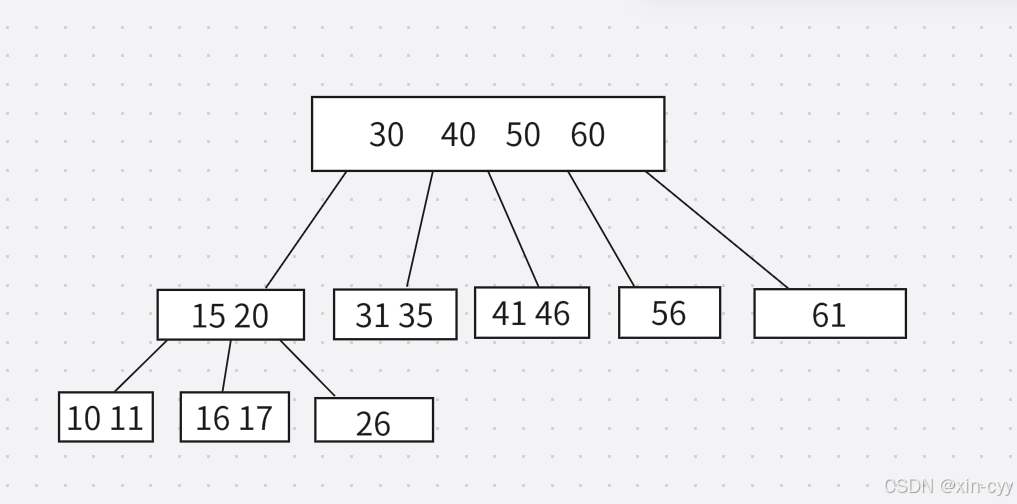
一個節點中,雖然可以保存N個key,但不是無限制的,達到一定的規模,就會觸發節點的分裂,當刪除元素達到一定的數目,也會觸發節點的合并。
B樹(N叉搜索樹)
特點:
1、每個節點上有M個key,劃分出M+1個區間。
2、進行查詢的時候,根據根節點出發,判定當前要查的數據在節點的哪個區間內,再決定下一步往哪走。
3、進行添加和刪除元素時,可以涉及到節點的拆分和合并。
B+樹
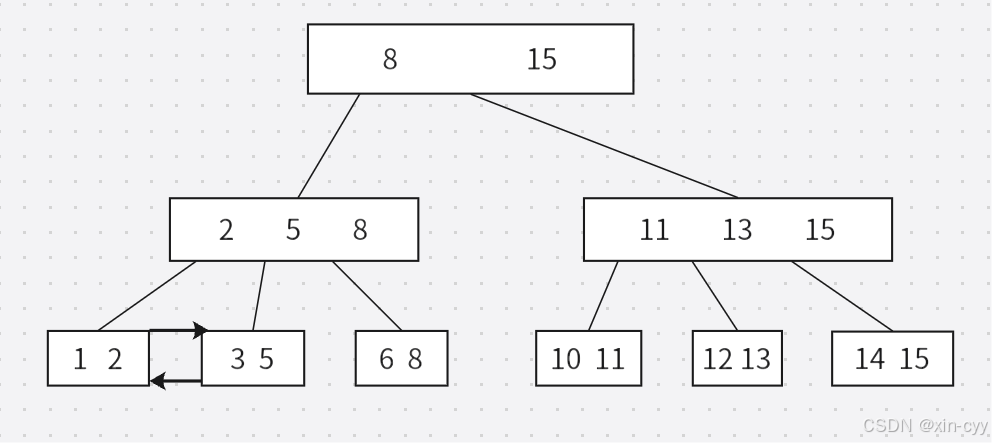
B+樹的特點:
1、B+樹也是一個N叉搜索樹,一個節點上存在N個key,就劃分成N個區間。
2、每個節點上N個key中,最后一個就相當于當前子樹的最大值。
3、父節點上的每個key都會以最大值的身份在子節點的對應區間中存在,葉子節點這一層,包含整個樹的數據全集。
4、B+樹會使用鏈表這樣的結構,把葉子節點串起來,此時就可以非常方便的完成數據集合的遍歷,并且方便的從數據中按照范圍取出一個“子集”。
優點:
1、N叉搜索樹,樹的高度是有限的。
2、非常擅長范圍查詢
3、所有的查詢都是落在葉子節點上,查詢之間的開銷是穩定的。
4、由于葉子節點是全集,會把數據只存儲在葉子節點上,非葉子節點只存儲一個用來排序的key,所以非葉子節點用不了多少空間,就可以緩存在內存中,提升訪問的速度。
2、事務
事務可以把多個SQL語句打包成一個整體,可以保證這些SQL語句要么全部執行,要么一個都不執行,具有原子性的特點。
事務的執行過程:
開始事務:start transaction;
執行各種SQL語句
主動觸發回滾:rollback;
事務結束:commit;
事務的原理:
回滾:以日志的方式,記錄事務中的關鍵操作,這樣的記錄是回滾的依據。然后以打印的方式,將內容放在文件中,即使主機掉電,也不會影響,一旦啟動主機,MySQL也會重新啟動,發生回滾操作。
事務的特點:
1、原子性:回滾的方式,保證操作都能執行正確。
2、一致性:事務執行前后,數據不能產生特別大的差異。
3、持久性:事務做出的修改,都是在硬盤上持久保存的,重啟服務器,修改仍然有效。
4、隔離性:數據并發執行多個事務時,并發程度越高,整體的效率就越高。
提高并發執行的程度,對提高效率,但也會產生一些問題。
1、臟讀問題
一個事務A正在寫數據的過程中,另一個事務B讀取了同一個數據,接下來事務A修改了數據,導致事務B讀到的數據是一個無效數據。
解決方法:
針對寫加鎖,等寫的操作完全執行結束,并且不再修改之后再讀,并發性降低了,隔離性提高了,效率降低了,準確性提高了。
2、不可重復讀
并發執行事務的過程中,如果事務A多次讀取同一個數據,出現不同的情況,就是不可重復讀,事務A再讀的過程中,事務B修改了數據并提交了數據。
解決方法:
針對讀操作進行加鎖,讀的時候不能再修改數據。
3、幻讀
一個事務A執行的過程中,兩次讀取操作,數據內容沒有改變,但是結果集變了,就稱為“幻讀”。
解決方法:
保持決定的串行執行事務,完全沒有并發,效率最低,隔離最高,內容最準確。
)



基礎命令和操作)

)



![[Linux]從零開始的STM32MP157 Buildroot根文件系統構建](http://pic.xiahunao.cn/[Linux]從零開始的STM32MP157 Buildroot根文件系統構建)



:LeetCode 239. 滑動窗口最大值(Sliding Window Maximum)詳解)
轉為 pdf)



