創作的初心:
我們在學習kafka時,都是基于大數據的開發而進行的講解,這篇文章為java程序員為核心,助力大家掌握kafka實現。
什么是kafka:
歷史:
- 誕生與開源(2010 - 2011 年)
- 2010 年,Kafka 由 LinkedIn 公司的工程師團隊開發,用于處理公司內部的大規模實時數據,如用戶活動、系統日志等。
- 2011 年,Kafka 開源并成為 Apache 軟件基金會的孵化項目,吸引了社區的廣泛關注和參與。
- 成為頂級項目(2012 - 2013 年)
- 2012 年,Kafka 從 Apache 孵化項目畢業,成為 Apache 頂級項目,標志著它在開源社區中獲得了廣泛認可。
- 這一時期,Kafka 的功能不斷豐富,性能也得到了進一步提升,逐漸被越來越多的公司用于構建實時數據處理系統。
- 蓬勃發展(2014 - 2017 年)
- 2014 年,Confluent 公司成立,專注于 Kafka 的商業化推廣和技術支持,為 Kafka 的發展提供了強大的商業推動力量。
- 隨著大數據和云計算技術的興起,Kafka 作為高性能的消息隊列和流處理平臺,在數據處理領域的應用越來越廣泛,許多公司開始將 Kafka 作為其數據基礎設施的重要組成部分。
- 2017 年,Kafka 發布了 0.11.0 版本,引入了冪等性和事務支持,進一步提升了 Kafka 在處理精確一次語義(Exactly - once Semantics)場景下的能力,使其更適合用于對數據一致性要求較高的業務場景。
- 持續創新(2018 - 2022 年)
- 2018 年,Kafka 發布了 2.0.0 版本,對 Kafka 的架構進行了一些重大改進,如引入了 Kafka Connect 用于數據集成,Kafka Streams 用于流處理等,使 Kafka 不僅僅是一個消息隊列,還成為了一個功能強大的流計算平臺。
- 2020 年,Kafka 發布了 2.8.0 版本,開始引入 KIP - 500,即 Kafka Raft(KRaft),逐步實現不依賴 Zookeeper 的目標,開啟了 Kafka 架構的重大變革。
- 2022 年,Kafka 持續推進 KRaft 的發展,不斷完善其功能和性能,為 Kafka 的未來發展奠定了堅實的基礎。
- 成熟與拓展(2023 年 - 至今)
- 2023 年,Kafka 在 KRaft 模式下不斷成熟,社區繼續致力于提升 Kafka 的性能、穩定性和安全性,同時拓展其在更多領域的應用,如物聯網、金融科技等。
- 隨著技術的不斷發展,Kafka 將繼續適應新的業務需求和技術趨勢,不斷演進和完善,保持其在分布式消息隊列和流處理領域的領先地位。
總結:Kafka 是一個分布式的、高吞吐量的消息隊列系統,由 Apache 軟件基金會開發,最初是由 LinkedIn 公司開發并開源。
核心特點
- 高吞吐量:Kafka 能夠處理大量的消息,每秒可以處理數千甚至數百萬條消息,這得益于其分布式架構和高效的存儲機制。它采用了順序讀寫磁盤、零拷貝等技術,大大提高了數據的讀寫速度。
- 可擴展性:Kafka 集群可以很容易地擴展,通過添加新的節點(broker)可以線性地增加集群的處理能力和存儲容量。同時,它支持自動的負載均衡,能夠將數據和請求均勻地分布在各個節點上。
- 持久性和可靠性:Kafka 將消息持久化到磁盤上,并通過副本機制來保證數據的可靠性。每個消息在多個節點上有副本,當某個節點出現故障時,其他副本可以繼續提供服務,確保數據不會丟失。
- 高并發:它能夠支持大量的生產者和消費者同時并發地讀寫消息,通過分區和多副本機制,可以實現對消息的并行處理,提高系統的整體性能。
主要組件
- 生產者(Producer):負責將消息發送到 Kafka 集群。生產者可以將消息發送到指定的主題(Topic),并可以指定消息的鍵(Key)和值(Value)。根據消息的鍵,Kafka 可以將消息分區,以便更好地進行數據的存儲和處理。
- 消費者(Consumer):從 Kafka 集群中讀取消息進行消費。消費者屬于一個消費者組(Consumer Group),每個消費者組可以有多個消費者實例。同一消費者組中的消費者會均衡地消費主題中的各個分區,不同消費者組之間相互獨立,每個消費者組都會獨立地從 Kafka 中獲取消息。
- 主題(Topic):是 Kafka 中消息的邏輯分類,類似于數據庫中的表。每個主題可以分為多個分區(Partition),每個分區是一個有序的、不可變的消息序列。消息在分區中按照順序進行存儲,并且每個消息都有一個唯一的偏移量(Offset)來標識其在分區中的位置。
- 代理(Broker):Kafka 集群中的服務器節點稱為代理。每個代理負責處理一部分主題的分區,并將消息持久化到本地磁盤。代理之間通過網絡進行通信,共同組成一個分布式的集群,實現數據的復制、備份和負載均衡等功能。
下載Kafka及命令行使用:
下載地址:
大家可以自行在官網下載:Apache Kafka
啟動的方式:
kafka本身是不區分操作系統的,他的目錄中我們可以發現它提供了Windows下的啟動方式,
小編的版本是kafka_2.13-3.3.1
依賴 ZooKeeper(Kafka 2.8 之前)
1. 啟動 ZooKeeper
ZooKeeper 是一個分布式協調服務,Kafka 依賴它來存儲元數據。
在 Kafka 安裝目錄下,使用命令行工具執行以下命令啟動 ZooKeeper:
# Windows 系統
.\bin\windows\zookeeper-server-start.bat ../../config/zookeeper.properties
# Linux 或 macOS 系統
bin/zookeeper-server-start.sh config/zookeeper.properties
2. 啟動 Kafka 服務
在 ZooKeeper 成功啟動后,你可以啟動 Kafka 服務。同樣在 Kafka 安裝目錄下,使用以下命令啟動:
# Windows 系統
.\bin\windows\kafka-server-start.bat ../../config/server.properties
# Linux 或 macOS 系統
bin/kafka-server-start.sh config/server.properties
不依賴 ZooKeeper(Kafka 2.8 及之后)
在 Kafka 2.8 及更高版本中,可以不依賴 ZooKeeper 啟動 Kafka,使用 KRaft 模式。步驟如下:
但是這種方式在windows上不好用,產生錯誤,沒有官方的解決方式(但是有一位大神寫了一個補丁版本的kafka,大家可以搜索著下載一下)。還是使用Linux操作系統吧。
1. 生成集群 ID
# Windows 系統
.\bin\windows\kafka-storage.bat random-uuid
# Linux 或 macOS 系統
./kafka-storage.sh random-uuid
執行上述命令后,會生成一個隨機的 UUID,你需要記住這個 UUID,后續步驟會用到。
2. 格式化存儲目錄
使用上一步生成的 UUID 來格式化存儲目錄,在命令行中執行以下命令:
# Windows 系統
D:\soft_setup\kafka_2.13-3.3.1\bin\windows>kafka-storage.bat format -t ZlDD6NrNQk2fiMxF4-iB8w -c ../../config/kraft/server.properties
# Linux 或 macOS 系統
./kafka-storage.sh format -t svPXC5N-SIiymvhRKPwZ3g -c ../config/kraft/server.properties
請將?<your-uuid>?替換為第一步中生成的實際 UUID。
3. 啟動 Kafka 服務
格式化完成后,就可以啟動 Kafka 服務了:
# Windows 系統
.\bin\windows\kafka-server-start.bat .\config\kraft\server.properties
# Linux 或 macOS 系統
./kafka-server-start.sh ../config/kraft/server.properties4.關閉kafka
# Windows 系統
# Linux 或 macOS 系統./kafka-server-stop.sh ../config/kraft/server.properties早期版本的kafka和zookeeper的關系:
- Kafka 依賴 Zookeeper 進行元數據管理
- Kafka 的集群信息、主題信息、分區信息以及消費者組的偏移量等元數據都存儲在 Zookeeper 中。例如,當創建一個新的主題時,相關的主題配置和分區分配信息會被寫入 Zookeeper。
- Zookeeper 以樹形結構存儲這些元數據,使得 Kafka 能夠方便地進行查詢和更新操作,從而讓 Kafka broker 可以快速獲取到所需的元數據信息來處理客戶端的請求。
- Zookeeper 為 Kafka 提供集群管理功能
- Kafka 集群中的 broker 節點會在 Zookeeper 上進行注冊,通過 Zookeeper 的節點創建和觀察機制,Kafka 可以實時感知到集群中 broker 節點的動態變化,如節點的加入或退出。
- 當有新的 broker 節點加入集群時,它會向 Zookeeper 注冊自己的信息,其他 broker 節點通過監聽 Zookeeper 上的相關節點變化,就能及時發現新節點的加入,并進行相應的協調和數據分配操作。
- Zookeeper 協助 Kafka 進行分區 leader 選舉
- 在 Kafka 中,每個分區都有一個 leader 副本和多個 follower 副本。當 leader 副本所在的 broker 節點出現故障時,需要選舉出一個新的 leader。
- Zookeeper 通過其選舉機制,能夠快速確定哪個 follower 副本可以成為新的 leader,確保分區的讀寫操作能夠盡快恢復,保證了 Kafka 集群的高可用性和數據的一致性。
- Zookeeper 幫助 Kafka 實現消費者組管理
- 消費者組的成員信息、消費偏移量以及消費者組的協調等工作都依賴于 Zookeeper。消費者在啟動時會向 Zookeeper 注冊自己所屬的消費者組和相關信息。
- Zookeeper 會監控消費者組中各個消費者的狀態,當有消費者加入或離開組時,會觸發重新平衡操作,確保每個分區能夠被合理地分配給消費者組中的消費者進行消費,從而實現了消費者組對主題分區的負載均衡消費
發展進程:
Kafka 從 2.8.0 版本開始引入 KIP-500,實現了 Raft 分布式一致性機制,開啟了不依賴 Zookeeper 的進程1。但在 2.8.0 版本中,Zookeeper - less Kafka 還屬于早期版本,并不完善1。
到 3.3 版本時,Kafka Raft(KRaft)被標記為生產就緒,具備了生產環境使用的條件3。3.4 版本提供了從 Zookeeper 模式到 KRaft 模式的早期訪問遷移功能,3.5 版本中遷移腳本正式生產就緒,同時棄用了 Zookeeper 支持。
直至 4.0 版本,Zookeeper 被徹底移除,所有版本完全基于 KRaft 模式運行,Kafka 不再依賴 Zookeeper,這標志著 Kafka 在擺脫 Zookeeper 依賴方面的工作基本完成。
注意:下面小編的操作是基于Linux系統
kafka的主題Topic和事件Event
主題(Topic)
定義:
主題是 Kafka 中消息的邏輯分類,類似于數據庫中的表或者文件系統中的文件夾,用于對消息進行歸類和管理。每個主題可以有多個生產者向其發送消息,也可以有多個消費者從其讀取消息。
特點
可分區:一個主題可以被劃分為多個分區(Partition),每個分區是一個有序的、不可變的消息序列。分區可以分布在不同的服務器上,從而實現數據的分布式存儲和并行處理,提高系統的吞吐量和可擴展性。
多副本:為了保證數據的可靠性和高可用性,每個分區可以有多個副本(Replica),這些副本分布在不同的 Broker 上。其中一個副本被指定為領導者(Leader),負責處理讀寫請求,其他副本作為追隨者(Follower),與領導者保持數據同步。
消息持久化:Kafka 將消息持久化到磁盤上,即使服務器重啟,消息也不會丟失。消息會根據一定的保留策略在磁盤上保留一段時間,過期的消息將被自動刪除,以釋放磁盤空間。
創建主題:
通過kafka-topics.sh腳本語言創建主題,直接運行這個腳本就會告訴你如何使用這個腳本。
命令:
//使用腳本創建主題
?./kafka-topics.sh --create --topic hello --bootstrap-server localhost:9092
//-creat? 創建一個主題
//--topic 后面的hello是我們的topic的名字
// bootstrap-server localhost:9092? 這個是必須的后面指定的是我們當前節點的主機地址
查找主題:
./kafka-topics.sh --list --bootstrap-server localhost:9092
刪除主題
?./kafka-topics.sh --delete --topic hello --bootstrap-server localhost:9092
顯示主題詳細信息:
?./kafka-topics.sh --describe --topic hello --bootstrap-server localhost:9092
修改分區數:
?./kafka-topics.sh --alter --topic hello --partitions 5 --bootstrap-server localhost:9092
事件(Event)
- 定義:在 Kafka 的語境中,事件通常指的是生產者發送到主題中的一條具體的消息(Message)。它是 Kafka 中數據傳輸和處理的基本單元,包含了消息的內容、鍵(Key)、時間戳等元數據。
- 特點
- 不可變性:一旦事件被發布到 Kafka 主題中,它就是不可變的,不能被修改或刪除。這確保了消息的一致性和可追溯性。
- 有序性:在同一個分區內,事件是按照它們被生產的順序進行存儲和消費的,保證了消息的順序性。但不同分區之間的事件順序是不確定的。
- 靈活性:事件的內容可以是任何格式的數據,如 JSON、XML、二進制數據等,生產者和消費者可以根據自己的需求對消息進行編碼和解碼。
事件的發送和接收:
事件的發送:
時間發送的命令
./kafka-console-producer.sh --topic hello --bootstrap-server localhost:9092
在之后的每次換行就是一條消息
![]()
?事件讀取:
從頭開始讀:
./kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic hello --from-beginning
--from-beginning? 添加這個參數就是在日志文件中的第一個消息開始讀,如果不添加這個就是監聽當前消息,之后生產者發送消息,消費者才會監聽。?
小技巧:我們在學習時,總是依靠記憶是不對的,因為總會忘記的,最好的方式就是依靠我們的管官方文檔和開發手冊,對于kafka的命令,我們還是依靠他的幫助來實現。
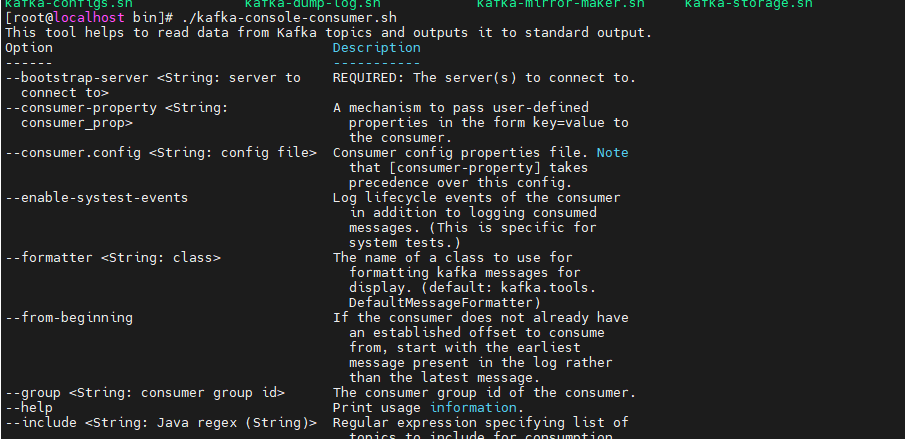
kafka的遠程連接:
下載kafka插件:
插件是:
 免費插件
免費插件
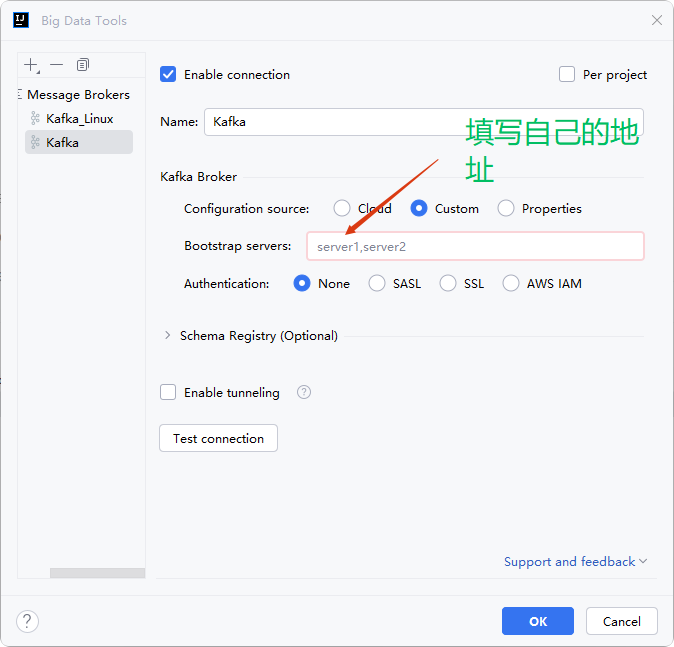
連接kafka:
解決無法遠程連接問題:
課程地址:042 Docker容器Kafka配置文件修改_嗶哩嗶哩_bilibili?
視頻中演示的是docker的配置,但是實際上那種方式都是這種修改方式
我們在遠程連接kafka是,按著默認的配置文件是無法遠程連接的,但是我們可以通過修改配置文件的方式達到遠程連接的要求。
配置文件修改的位置是:
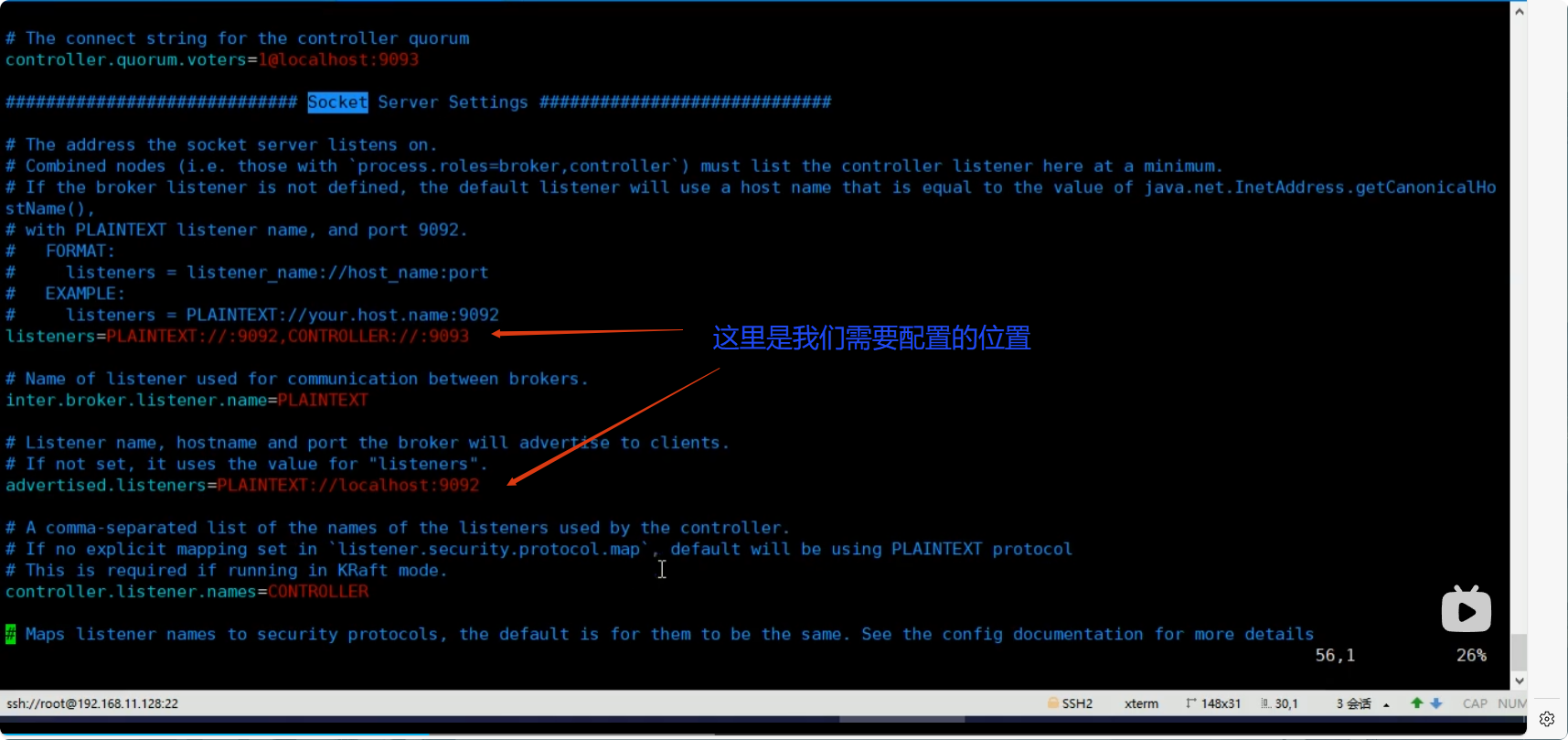
我們需要將配置文件修改為:
?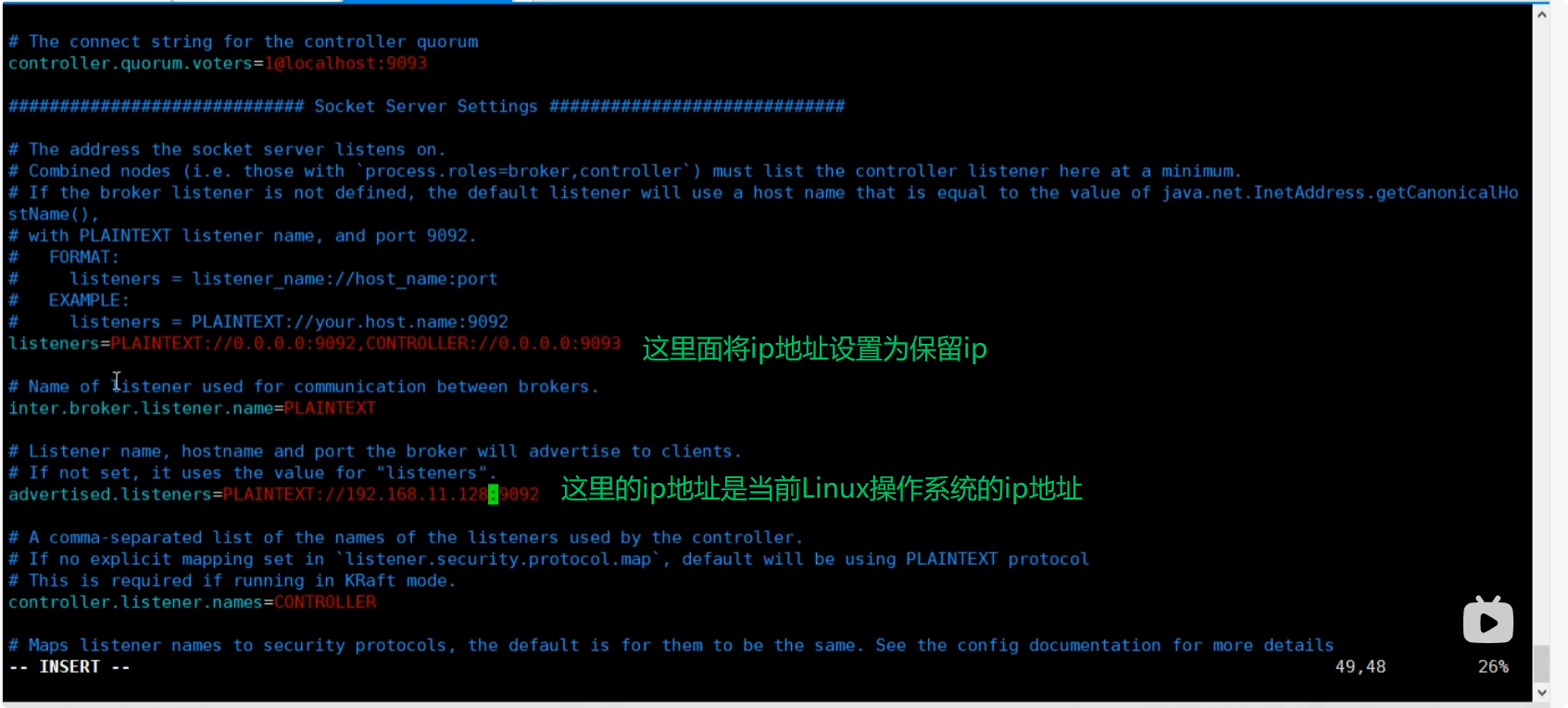
修改之后我們可以遠程連接kafka.?

顯示我們的topic,證明連接成功。?
Spring-boot集成Kafka?
快速開始
導入的依賴:
//他的版本是2.8.10 原因是因為我的jdk版本是1.8,如果是3.X的kafka,集成的boot版本是3.X,JDK版本是17,小編不再升級JDK版本了,所以直接使用2.8.10 <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId> </dependency>
編寫配置文件:?
對于我們所有的MQ產品,配置文件幾乎都是三個部分構成,服務器連接配置,生產者配置,消費之配置。三個部分生成。
對于我們現在常見的三個中間件分別是:RabbitMQ,RocketMQ,kafka.如果大家想學習其他的中間件的話,可以看小編的其他文章。為大家帶來了詳細的消息中間件實戰。
兩小時拿下RocketMQ實戰_rocketmq使用案例-CSDN博客
快速上手RabbitMQ_逸Y 仙X的博客-CSDN博客
spring:kafka:#kafka連接地址bootstrap-servers: 192.168.0.169:9092#配置生產者 (24個配置,我們在這個基礎班的base中全部使用默認配置)#producer:#配置消費者,27個配置#consumer:?編寫生產者:
@Component
public class EventProduce {//加入spring-kafka依賴之后,自動配置好了kafkaTemplate@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sentEvent(){ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send("hello", "這是使用java發送的第一條消息");}}//使用test進行測試的代碼
@SpringBootTest
public class EventProduceTest {@Autowiredprivate EventProduce eventProduce;@Testpublic void produceEventTest(){eventProduce.sentEvent();}
}編寫消費者:
注意點:使用@KafkaListener注解監聽時,必須雨哦的兩個參數是 topics 和 groupId
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/4/29 20:36*/
@Component
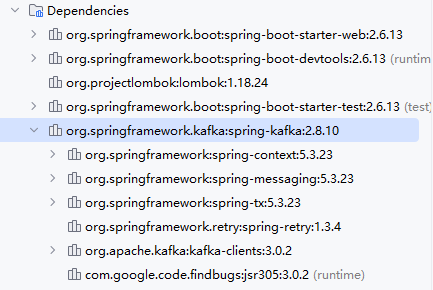
public class EventConsumer {//監聽的方式@KafkaListener(topics = "hello",groupId ="hello-group" )//必須有的兩個參數是topics 和 groupIdpublic void eventConsumer(String event){//默認是知識監聽最新的消息System.out.println("讀取的事件是"+event);}
}展示結果:
詳細解釋配置文件:
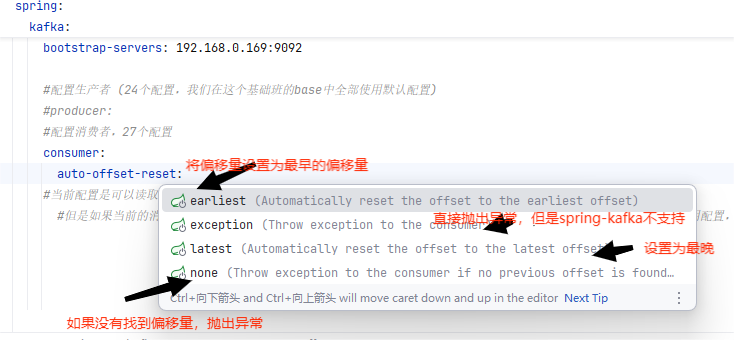
consumer中的配置:auto-offset-reset: earliest
當前配置是可以讀取更早的信息,也就是讀取以簽的信息 ,但是如果當前的消費組id已經消費過的話,kafka會記住偏移量,配置就不會生效,Kafka只會在中不到偏移量時,使用配置,可以手動重置偏移量,或者是使用新的id
spring:kafka:#kafka連接地址bootstrap-servers: 192.168.0.169:9092#配置生產者 (24個配置,我們在這個基礎班的base中全部使用默認配置)#producer:#配置消費者,27個配置consumer:#當前配置是可以讀取更早的信息,也就是讀取以簽的信息#但是如果當前的消費組id已經消費過的話,kafka會記住偏移量,配置就不會生效,Kafka只會在中不到偏移量時,使用配置,可以手動重置偏移量,或者是使用新的idauto-offset-reset: earliest
使用?新的id讓配置生效:
@Component
public class EventConsumer {//監聽的方式@KafkaListener(topics = "hello",groupId ="hello-group-02" )//必須有的兩個參數是topics 和 groupIdpublic void eventConsumer(String event){//默認是知識監聽最新的消息System.out.println("讀取的事件是"+event);}
}
結果展示:

方式二:重置偏移量:
?命令:
將偏移量設置為最早開始位置
./kafka-consumer-groups.sh --bootstrap-server localhost:9092 ?--topic hello --group hello-group-02 ?--reset-offsets --to-earliest --execute
//設置為最后的偏移量位置
?./kafka-consumer-groups.sh --bootstrap-server localhost:9092 ?--topic hello --group hello-group-02 ?--reset-offsets --to-latest --execute

發送消息:
發送Message消息:
/*** 發送Message消息*/public void sentMessgeEvent(){//todo 使用這種方式創建時,將topic的名字放在header中,這個方式的來與時在KafkaOperations這個類中Message<String> message = MessageBuilder.withPayload("使用message發送消息到hello topic").setHeader(KafkaHeaders.TOPIC,"hello-Message").build();kafkaTemplate.send(message);System.out.println("消息發送成功");}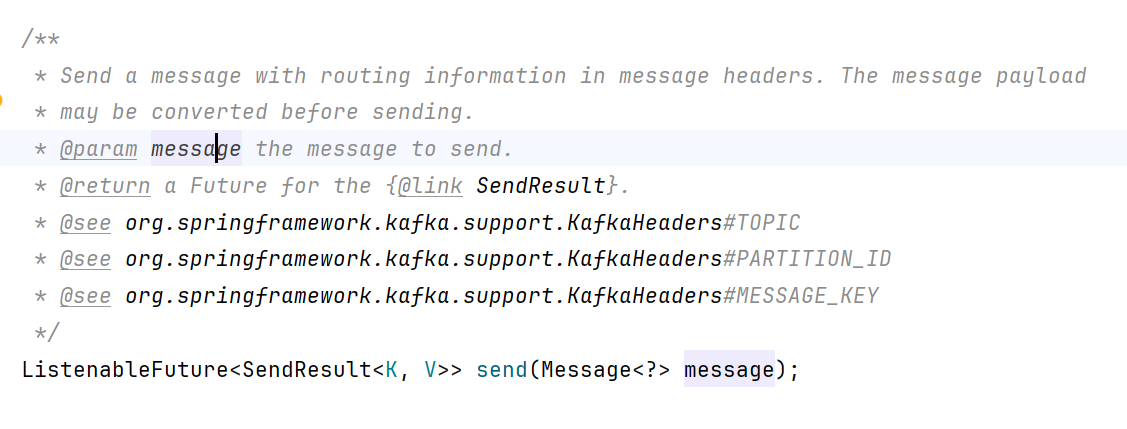
發送ProducerRecord消息?
/*** 發送ProducerRecord對象*/public void sendProducerRecord(){//使用headers,傳遞數據,消費者可以獲得我們傳輸的數據Headers header = new RecordHeaders();header.add("phone","11111111111".getBytes(StandardCharsets.UTF_8));//public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)ProducerRecord<String,String> producerRecord = new ProducerRecord<>("hello",0, Instant.now().toEpochMilli(),"key1" ,"kafka value1",header);ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send(producerRecord);System.out.println("發送成功");}sent的重載方式:
/*** sent的重載方式*/public void sentLong(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", 0, Instant.now().toEpochMilli(), "key2", "value2");}sendDefault方式:
他是一種通過配置文件,省略我們在發送是指定topic的返送方式,對于我們每次只是發送到相同的topic中可以采用的方式
/*** 測試sendDefault方式*/public void sentDefault(){//大家可以看一下,這里面是不是沒有指定我們的topic,如果直接發送的話就會出現錯誤//需要配置配置文件ListenableFuture<SendResult<String, String>> sendResultListenableFuture = kafkaTemplate.sendDefault( 0, Instant.now().toEpochMilli(), "key2", "value2");System.out.println("消息發送成功");}配置文件:?
spring:kafka:template:#配置模板的默認的主題,使用sendDefault時,直接發送到hello中default-topic: hello
發送對象:
通過序列化的方式發送對象:
spring:kafka:#kafka連接地址bootstrap-servers: 192.168.0.169:9092#配置生產者 (24個配置,我們在這個基礎班的base中全部使用默認配置)#producer:#配置消費者,27個配置producer:value-serializer: org.springframework.kafka.support.serializer.JsonSerializer#key-serializer: 鍵序列化,默認是StringSerializer
/*** 發送對象* 直接序列化的時候出現異常,異常是StringSerializer,需要配置序列化方式*/public void sendObj(){//其實如果是發送對象的話,就是將對象進行序列化User user = User.builder().id(1).name("lihua").phone("13464299018").build();//如果分區是null,kafka自己選擇放置到那個分區中template.send("hello",null,Instant.now().toEpochMilli(),"key3",user);}發送狀態接受:
同步方式:
/*** 發送之后獲取結果,阻塞的方式獲取結果*/public void resultSent(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "這是使用java發送的第一條消息");try {//這個方法是阻塞的SendResult<String, String> sendResult = result.get();//RecordMetadata 如果是空就是沒有接受到消息if(sendResult.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = sendResult.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}} catch (InterruptedException e) {throw new RuntimeException(e);} catch (ExecutionException e) {throw new RuntimeException(e);}}異步方式:
spring-kafka 2.X
/*** 發送之后使用異步的方式獲取結果* 使用回調函數在ListenableFuture(kafka2.X),* 使用thenAccept() thenApply() thenRun() 等方式來注冊回調函數, CompletableFuture(kafka3.X)完成時執行*/public void sendAsynchronous(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "這是使用java發送的第一條消息");result.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println(ex.getMessage());}@Overridepublic void onSuccess(SendResult<String, String> result) {if(result.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = result.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}}});}/*** 當前操作時將我們的返回值轉化為CompletableFuture類型進行操作 結合了我們的3.X的方式實現* 發送之后使用異步的方式獲取結果* 使用回調函數在ListenableFuture(kafka2.X),* 使用thenAccept() thenApply() thenRun() 等方式來注冊回調函數, CompletableFuture(kafka3.X)完成時執行*/public void sendAsynchronous2(){ListenableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "這是使用java發送的第一條消息");CompletableFuture<SendResult<String, String>> completable = result.completable();try{completable.thenAccept((sendResult)->{if(sendResult.getRecordMetadata()!=null){//kafka接受消息成功System.out.println("kafka接受消息成功");ProducerRecord<String, String> producerRecord = sendResult.getProducerRecord();String value = producerRecord.value();System.out.println("value = "+value);}}).exceptionally((ex)->{ex.printStackTrace();//如果失敗,進行處理return null;});}catch (RuntimeException e){throw new RuntimeException();}}spring-kafka 3.X
?下面是一個案例代碼,我們的上面2.X中的代碼第二種方式,刪除轉化的部分,3.X可以直接使用。
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;import java.util.concurrent.CompletableFuture;public class KafkaSender3x {private final KafkaTemplate<String, String> kafkaTemplate;public KafkaSender3x(KafkaTemplate<String, String> kafkaTemplate) {this.kafkaTemplate = kafkaTemplate;}/*** 發送之后使用異步的方式獲取結果* 使用 CompletableFuture 的 thenAccept 方法來處理結果*/public void sendAsynchronous() {CompletableFuture<SendResult<String, String>> result = kafkaTemplate.send("hello", "這是使用java發送的第一條消息");result.thenAccept(sendResult -> {System.out.println("消息發送成功,分區: " + sendResult.getRecordMetadata().partition() +", 偏移量: " + sendResult.getRecordMetadata().offset());}).exceptionally(ex -> {System.err.println("消息發送失敗: " + ex.getMessage());return null;});}
} Spring-boot創建主題指定分區和副本:?
分區(Partition)和副本(Replica)概念講解:
- 分區(Partition)
- 定義:可以將其看作是一個主題(Topic)的物理細分。如果把主題類比為一個文件夾,那么分區就像是文件夾中的不同子文件夾。每個分區都是一個獨立的、有序的消息序列,消息在分區內按照順序進行存儲和處理。
- 作用:通過分區,可以實現數據的并行處理和存儲,提高系統的吞吐量和可擴展性。不同的分區可以分布在不同的服務器上,這樣多個消費者可以同時從不同的分區讀取消息進行處理,從而加快消息處理的速度。例如,在一個處理大量訂單消息的系統中,將訂單主題分為多個分區,每個分區可以由不同的消費者組進行處理,從而提高訂單處理的整體效率。
- 副本(Replica)
- 定義:是分區的一個拷貝,它包含了與原始分區相同的消息數據。副本可以存在于不同的服務器上,用于提供數據的冗余和容錯能力。
- 作用:當某個分區所在的服務器出現故障時,副本可以替代故障分區繼續提供服務,保證數據的可用性和系統的穩定性。例如,在一個分布式消息隊列系統中,如果一個分區的主副本所在服務器崩潰了,那么系統可以自動切換到該分區的其他副本所在服務器上,繼續處理消息,而不會導致數據丟失或服務中斷。同時,副本也可以用于負載均衡,多個副本可以分擔讀取請求的壓力,提高系統的整體性能。
-
細節點:replica:副本 他是為了放置我們partition數據不丟失,且kafka可以繼續工作,kafka的每個節點可以有1個或者是多個副本 .副本分為Leader Replica 和 Follower Replica副本。?副本最少是1個,最多不能超果節點數(kafka服務器數),否則將不能創建Topic。?我們主副本可讀可寫,從副本只能讀不能寫?
-
命令行方式創建副本:
-
./kafka-topics.sh --create ?--topic mytopic --partitions 3 --replication-factor 2 --bootstrap-server localhost:9092

我們當前是單節點的kafka,創建兩個副本的話,就會出現錯誤,現實的錯誤信息是:?only 1 broker(s) are registered.
?使用spring-kafka創建主題分區和副本
?如果我們直接使用kafkaTemplate的send(String topic,String event);這種方式的話,就是創建了以topic,但是他只有一個分區和一個副本(主副本,可讀可寫);
通過編寫配置文件設置分區個數和副本個數:
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.KafkaResourceFactory;
import org.springframework.kafka.core.KafkaTemplate;import java.util.Optional;/*** @Author HanDK* @CreateTime: 2025/5/1 09:18*/
@Configuration
public class KafkaConfig {/*** 我們再次啟動時,當前的消息不會丟失,也不會將我們以簽有的topic覆蓋掉* 也就是如果存在的話就不會創建,只有不存在才會創建* @return*/@Beanpublic NewTopic newTopic(){
// 構造函數
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//創建一個topic 5個分區 1個副本NewTopic newTopic = new NewTopic("myTopic",5,(short)1 );return newTopic;}//但是現在將我們的myTopic的分區改為9個分區//在創建時如果有一摸一樣的topic,不會創建。但是如果有改變的話,就會修改@Beanpublic NewTopic updateNewTopic(){
// 構造函數
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//創建一個topic 5個分區 1個副本NewTopic newTopic = new NewTopic("myTopic",9,(short)1 );return newTopic;}}
消息發送策略:
我們的一個topic中有很多的分區,但是我們在發送時使用的是什么策略呢?
默認的隨機策略:
指定key:使用key生成hash值,之后在計算獲取我們的partition的分區數值。如果我們的key值是不變的,他就會一直放置在一個分區中。
沒有key:但是如果在發送消息時沒有指定key值,他會隨機發送到那個partition中。使用隨機數算法獲取隨機的分區數。
輪詢分配策略:
kafka的類:RoundRobinPartitioner implements Partitioner
如何使用輪詢策略:(代碼的方式獲取)
我們發現直接使用配置文件的形式是不可以配置輪詢策略的,使用代碼的方式將策略設置為輪詢策略。
編寫配置文件:
@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.producer.value-serializer}")private String valueSerializer;@Beanpublic Map<String,Object> producerConfigs(){//使用map的形式填寫配置文件Map<String,Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializer);props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);return props;}@Beanpublic ProducerFactory<String,Object> producerFactory(){//創建生產者工廠return new DefaultKafkaProducerFactory<>(producerConfigs());}//@Beanpublic KafkaTemplate<String,Object> kafkaTemplate(){KafkaTemplate<String, Object> kafkaTemplate = new KafkaTemplate<>(producerFactory());return kafkaTemplate;}當前我們的每個分區都沒有事件,現在我發送9條消息,展示是不是輪詢策略。
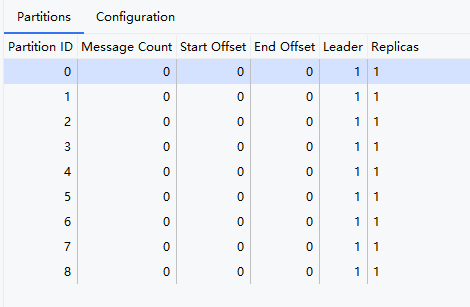
我們可以看到他確實時進入了輪詢的策略,大家可以使用這個代碼去Debug?
?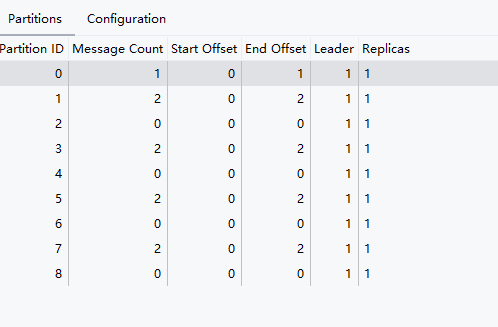
我們對于partition方法調用兩次,他的放置文件時就是間隔一份放置。
自定義分配策略:
按著上面的思路,我們可以知道,其實如果自定一分區策略的話,自己去實現我們的Partitioner接口,實現分區策略就可以了。
生產者消息發送的流程:
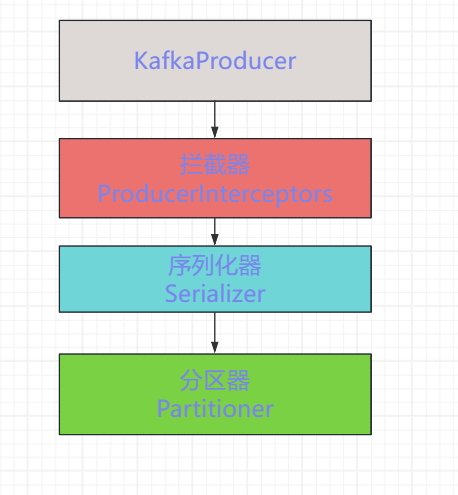
編寫攔截器:
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.producer.ProducerInterceptor;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;import java.util.Map;/*** @Author H* @CreateTime: 2025/5/1 17:04*/
public class CustomerProducerInterceptor implements ProducerInterceptor<String,Object> {/*** 發送消息是,對于消息進行攔截* @param record the record from client or the record returned by the previous interceptor in the chain of interceptors.* @return*/@Overridepublic ProducerRecord<String, Object> onSend(ProducerRecord<String, Object> record) {System.out.println("獲取到內容是:"+record.value());return record;}/*** 消息確認機制* @param metadata The metadata for the record that was sent (i.e. the partition and offset).* If an error occurred, metadata will contain only valid topic and maybe* partition. If partition is not given in ProducerRecord and an error occurs* before partition gets assigned, then partition will be set to RecordMetadata.NO_PARTITION.* The metadata may be null if the client passed null record to* {@link org.apache.kafka.clients.producer.KafkaProducer#send(ProducerRecord)}.* @param exception The exception thrown during processing of this record. Null if no error occurred.*/@Overridepublic void onAcknowledgement(RecordMetadata metadata, Exception exception) {if(metadata!=null){System.out.println("發送成功");}else{System.out.println("出現異常");exception.printStackTrace();}}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
配置攔截器
直接在配置文件中還是不能直接獲取到配置項,使用編碼實現
package com.hdk.springbootkafkabase01.config;import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.RoundRobinPartitioner;
import org.apache.kafka.common.serialization.StringSerializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaResourceFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory;import java.util.HashMap;
import java.util.Map;
import java.util.Optional;/*** @Author HanDK* @CreateTime: 2025/5/1 09:18*/
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.producer.value-serializer}")private String valueSerializer;@Beanpublic Map<String,Object> producerConfigs(){//使用map的形式填寫配置文件Map<String,Object> props = new HashMap<>();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,valueSerializer);props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,StringSerializer.class);props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, RoundRobinPartitioner.class);//配置攔截器,默認是沒有攔截器的props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomerProducerInterceptor.class.getName());return props;}@Beanpublic ProducerFactory<String,?> producerFactory(){//創建生產者工廠return new DefaultKafkaProducerFactory<>(producerConfigs());}//@Beanpublic KafkaTemplate<String,?> kafkaTemplate(){KafkaTemplate<String,?> kafkaTemplate = new KafkaTemplate<>(producerFactory());return kafkaTemplate;}/*** 我們再次啟動時,當前的消息不會丟失,也不會將我們以簽有的topic覆蓋掉* 也就是如果存在的話就不會創建,只有不存在才會創建* @return*/@Beanpublic NewTopic newTopic(){
// 構造函數
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//創建一個topic 5個分區 1個副本NewTopic newTopic = new NewTopic("myTopic",5,(short)1 );return newTopic;}//但是現在將我們的myTopic的分區改為9個分區//在創建時如果有一摸一樣的topic,不會創建。但是如果有改變的話,就會修改@Beanpublic NewTopic updateNewTopic(){
// 構造函數
// public NewTopic(String name, int numPartitions, short replicationFactor) {
// this(name, Optional.of(numPartitions), Optional.of(replicationFactor));
// }//創建一個topic 5個分區 1個副本NewTopic newTopic = new NewTopic("myTopic",9,(short)1 );return newTopic;}}
?props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomerProducerInterceptor.class.getName());//這里不可以直接.class??
ProducerConfig.INTERCEPTOR_CLASSES_CONFIG?,該配置項期望的值是一個包含攔截器類全限定名(Fully Qualified Class Name)的字符串或者字符串列表。這是因為 Kafka 在啟動時需要根據這些類名,通過 Java 的反射機制來實例化對應的攔截器類。不能直接傳輸Class對象。
?消息消費細節:
@Payload注解
他修飾的變量是發送的內容
@Hearder注解
他標注請求頭的信息。但是需要指明獲取的是頭信息中的那個鍵值信息
ConsumerRecord<String,String> record? 使用他接受消息的全信息
package com.hdk.springbootkafkabase02.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/1 17:37*/
@Component
public class EventConsumer {//@Payload 這個注解證明他修飾的變量就是消息體的內容//@Header 這個注解接收請求頭的信息@KafkaListener(topics = {"helloTopic"},groupId="group1")public void listenerEvent(@Payload String message, @Header(value = KafkaHeaders.RECEIVED_TOPIC) String topic,ConsumerRecord<String,String> record){System.out.println("接收的信息是"+message);System.out.println("接收的topic是"+topic);System.out.println("record中獲取value:"+record.value());System.out.println("record中獲取偏移量:"+record.offset());System.out.println("打印record的所有信息"+record);}/*** ConsumerRecord<String,String> record 使用他接受消息*/
}
?接收的信息是hello topic
接收的topic是helloTopic
record中獲取value:hello topic
record中獲取偏移量:2
打印record的所有信息ConsumerRecord(topic = helloTopic, partition = 0, leaderEpoch = 0, offset = 2, CreateTime = 1746152401289, serialized key size = -1, serialized value size = 11, headers = RecordHeaders(headers = [], isReadOnly = false), key = null, value = hello topic)
消費對象信息:
在消費對象消息式,我們可以使用序列化和反序列化的方式,首先是想通過框架直接序列化和反序列化,但是出現了不信任的問題,所以我們將序列化和反序列化的工作交給我們程序員,編寫Json工具類,手動實現
#producer:#value-serializer: org.springframework.kafka.support.serializer.JsonSerializer#consumer:#這是需要jackson依賴,導入我們的spring-boot-stater-json 依賴#錯誤點二:如果需要反序列化的話。當前報必須是可信賴的,需要將這個類設置為可信賴#The class 'com.hdk.springbootkafkabase02.entity.User' is not in the trusted packages: [java.util, java.lang].#If you believe this class is safe to deserialize, please provide its name.#If the serialization is only done by a trusted source, you can also enable trust all (*).#value-deserializer: org.springframework.kafka.support.serializer.JsonDeserializer
?序列化工具類:
package com.hdk.springbootkafkabase02.util;import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;/*** @CreateTime: 2025/5/2 11:25* 這里的序列化方式大家可以選擇自己習慣的序列化方式*/
public class JsonUtils {//使用jackson方式序列化private static final ObjectMapper OBJECTJSON = new ObjectMapper();/*** 將自定義類型序列化* @param obj* @return*/public static String toJson(Object obj) {String ans = null;try {ans = OBJECTJSON.writeValueAsString(obj);} catch (JsonProcessingException e){e.printStackTrace();}return ans;}/*** json轉對象* @param json* @param clazz* @return* @param <T>*/public static <T> T toBean(String json,Class<T> clazz){T obj = null;try {obj = OBJECTJSON.readValue(json, clazz);} catch (JsonProcessingException e) {throw new RuntimeException(e);}return obj;}
}
生產者代碼:
public void sendObj(){/*** #這是需要jackson依賴,導入我們的spring-boot-stater-json 依賴* #錯誤點二:如果需要反序列化的話。當前報必須是可信賴的,需要將這個類設置為可信賴* #The class 'com.hdk.springbootkafkabase02.entity.User' is not in the trusted packages: [java.util, java.lang].* #If you believe this class is safe to deserialize, please provide its name.* #If the serialization is only done by a trusted source, you can also enable trust all (*).* 因為上面的原因,將我們的User類型轉化為Json字符串*/User user = new User("lihua", 15, "11155551111");/*** 這種方式不需要值的序列化,也不需要反序列化*/String userJson = JsonUtils.toJson(user);kafkaTemplate.send("helloTopic",userJson);}?消費者代碼:
//接收對象消息@KafkaListener(topics = {"helloTopic"},groupId="group1")public void listenerObj(@Payload String userJson){System.out.println(userJson);//再自行進行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);}?將監聽信息寫道配置文件中:
上面的消費者的topics,groupId寫死在我們的代碼中,這種方式的編碼修改不方便
可以采用${}的方式在配置文件中讀取
配置文件:
#自定義配置文件 kafka:topic:name: helloTopicconsumer:groupId: group1
代碼:
//接收對象消息@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerObj2(@Payload String userJson){System.out.println(userJson);//再自行進行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);}kafka消費手動確認:
kafka默認是自動確認,首先在配置文件中設置為手動確認
spring:kafka:bootstrap-servers: 192.168.0.168:9092#配置監聽器listener:ack-mode: manual
之后在接受參數是,添加上參數`` ``,代碼展示如下:
//手動確認下的消費者代碼@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerManual(@Payload String userJson, Acknowledgment acknowledgment){System.out.println(userJson);//再自行進行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);acknowledgment.acknowledge();}?但是如果我們沒有手動進行確認的化,會發生什么呢:
如果沒有確認消費的話,我們的偏移量不會更新,我們在重啟時,還會再之前的偏移量的位置開始消費。
我們再業務中可以這樣寫代碼:
//手動確認下的消費者代碼@KafkaListener(topics = {"${kafka.topic.name}"},groupId="${kafka.consumer.groupId}")public void listenerManual(@Payload String userJson, Acknowledgment acknowledgment){try {System.out.println(userJson);//再自行進行反序列化User user = JsonUtils.toBean(userJson, User.class);System.out.println(user);//沒有問題時,直接確認acknowledgment.acknowledge();} catch (Exception e) {//出現問題,沒有消費成功,拋出異常throw new RuntimeException(e);}}細化消費:如何指定消費的分區,偏移量
//細化消費,指定分區和偏移量@KafkaListener(groupId="${kafka.consumer.groupId}",topicPartitions = {@TopicPartition(topic ="${kafka.topic.name}",partitions = {"0","1","2"}, // 0 1 2 分區所有的數據都讀partitionOffsets = {//分區3 4 只是讀3之后的數據@PartitionOffset(partition = "3",initialOffset = "3"),@PartitionOffset(partition = "4",initialOffset = "1")})})public void consumerPartition(@Payload String jsonUser,Acknowledgment acknowledgment){System.out.println("獲取到的數據是"+jsonUser);acknowledgment.acknowledge();}偏移量細節:
1. Kafka 偏移量機制
Kafka 的偏移量是一個單調遞增的數字,用來標記消息在分區中的位置。當你指定一個初始偏移量時,Kafka 會嘗試從這個偏移量開始為你提供消息。要是指定的偏移量超過了分區中當前最大的偏移量,Kafka 會按照消費策略(例如從最早或者最新的消息開始消費)來處理。
2. 消費策略的影響
在 Kafka 里,當指定的偏移量超出了分區的范圍,就會依據?auto.offset.reset?配置項來決定從哪里開始消費。這個配置項有兩個常用的值:
earliest:從分區的最早消息開始消費。latest:從分區的最新消息開始消費。
所以,當分區中的消息數小于你設定的初始偏移量時,Kafka 會依據?auto.offset.reset?的值來決定起始消費位置,而不是從你指定的偏移量開始。
批量消費消息:
配置文件:
spring:kafka:bootstrap-servers: 192.168.0.168:9092listener:# 默認是single(單一的),這是消費方式是批量type: batchconsumer:#為消費之設置消費數量max-poll-records: 20
消費者代碼:
package com.hdk.springbootkafkabase03.consumer;import com.hdk.springbootkafkabase03.entity.User;
import com.hdk.springbootkafkabase03.utils.JsonUtils;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;import java.util.List;/*** @CreateTime: 2025/5/3 08:28*/
@Component
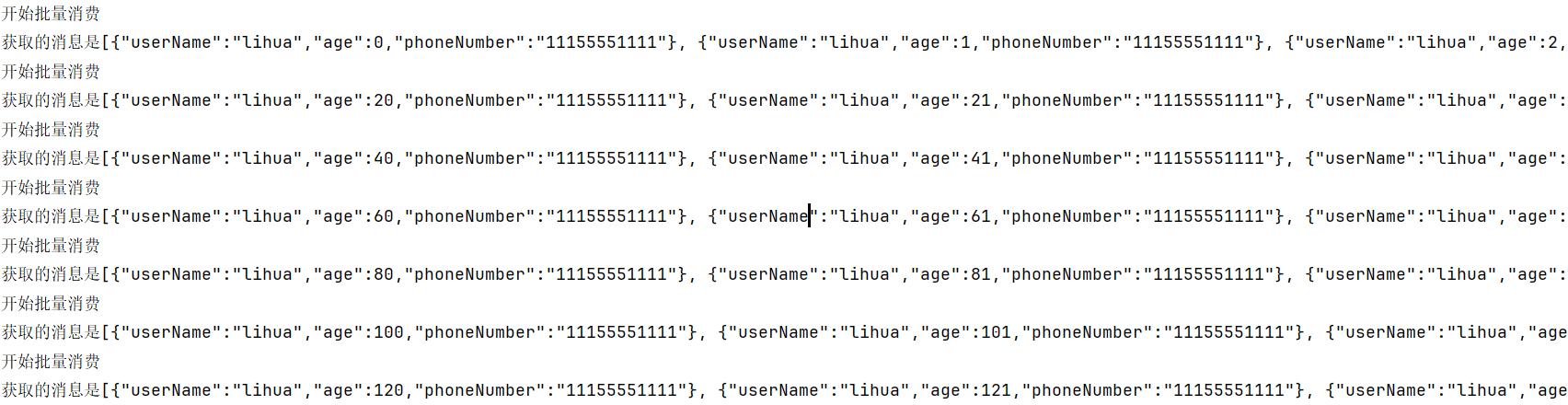
public class EventConsumer {/*** 對于批量的消費,接收時必須是集合形式接收* @param jsonUser* @param records*/@KafkaListener(groupId ="${kafka.consumer.group}",topics = "batchTopic")public void consumerBatchEvent(@Payload List<String> jsonUser, List<ConsumerRecord<String,String>> records){System.out.println("開始批量消費");System.out.println("獲取的消息是"+jsonUser);}
}
運行截圖:
?消息攔截:
在消息消費之前,我們可以設置攔截器,對消息進行一些符合業務的操作。例如記錄日志,修改消息內容或者執行一些安全檢查。
實現方式:
實現接口ConsumerIntercepter
package com.hdk.springbootkafkabase03.interceptor;import org.apache.kafka.clients.consumer.ConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.OffsetAndMetadata;
import org.apache.kafka.common.TopicPartition;import java.time.LocalDateTime;
import java.util.Map;/*** 自定義消息攔截器* @CreateTime: 2025/5/3 09:12*/public class CustomConsumerInterceptor implements ConsumerInterceptor<String,String> {//在消息消費之前@Overridepublic ConsumerRecords<String, String> onConsume(ConsumerRecords<String, String> records) {//記錄日志System.out.println("開始消費"+ LocalDateTime.now());return records; //返回的數據繼續執行}/*** 消費消費之后,提交offset之前的方法* @param offsets A map of offsets by partition with associated metadata*/@Overridepublic void onCommit(Map<TopicPartition, OffsetAndMetadata> offsets) {System.out.println("提交offset"+offsets);}@Overridepublic void close() {}@Overridepublic void configure(Map<String, ?> configs) {}
}
將過濾器配置到項目中:
配置消費者工廠,配置監聽器容器工廠
package com.hdk.springbootkafkabase03.config;import com.hdk.springbootkafkabase03.interceptor.CustomConsumerInterceptor;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;import java.util.HashMap;
import java.util.Map;/*** @CreateTime: 2025/5/3 08:37*/
@Configuration
public class KafkaConfig {@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;public Map<String,Object> consumerConfig(){Map<String,Object> props = new HashMap<>();props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializer);//添加一個消費者攔截器props.put(ConsumerConfig.INTERCEPTOR_CLASSES_CONFIG, CustomConsumerInterceptor.class.getName());return props;}/*** 配置消費者工廠* @return*/@Beanpublic ConsumerFactory<String,String> consumerFactory(){DefaultKafkaConsumerFactory defaultKafkaConsumerFactory = new DefaultKafkaConsumerFactory(consumerConfig());return defaultKafkaConsumerFactory;}/*** 創建消費者監聽期容器工廠*/@Beanpublic KafkaListenerContainerFactory kafkaListenerContainerFactory(){ConcurrentKafkaListenerContainerFactory concurrentKafkaListenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();concurrentKafkaListenerContainerFactory.setConsumerFactory(consumerFactory());return concurrentKafkaListenerContainerFactory;}}
消費者代碼:
/*** 對于批量的消費,接收時必須是集合形式接收* @param jsonUser* @param records* containerFactory 注意這個配置,指定一下*/@KafkaListener(groupId ="${kafka.consumer.group}",topics = "batchTopic",containerFactory = "kafkaListenerContainerFactory")public void consumerBatchEvent(@Payload List<String> jsonUser, List<ConsumerRecord<String,String>> records){System.out.println("開始批量消費");System.out.println("獲取的消息是"+jsonUser);}消息轉發:
情景模擬:
我們監聽TopicA的消息,經過處理之后發送給TopicB,使用業務b監聽TopicB的消息。實現了我們雄消息的轉發。
package com.hdk.springbootkafkabase05.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.messaging.handler.annotation.SendTo;
import org.springframework.stereotype.Component;/*** 消息轉發* @CreateTime: 2025/5/3 15:54*/
@Component
public class EventConsumer {/*** @param record 消息的信息* @return 將要轉發到topicB的信息*/@KafkaListener(topics = "topicA",groupId = "group1")@SendTo("topicB")public String consumerAndSendMessage(ConsumerRecord<String,String> record){System.out.println("當前的消息信息是:"+record.value());return record.value()+"forward-message";}@KafkaListener(topics = "topicB",groupId = "group1")public void consumerTopicB(ConsumerRecord<String,String> record){System.out.println("當前的消息信息是:"+record.value());}}
發送者代碼:
@Component
public class EventProducer {@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sendToTopicA(){kafkaTemplate.send("topicA","消息發送到kafkaA");}
}消息消費時的分區策略:
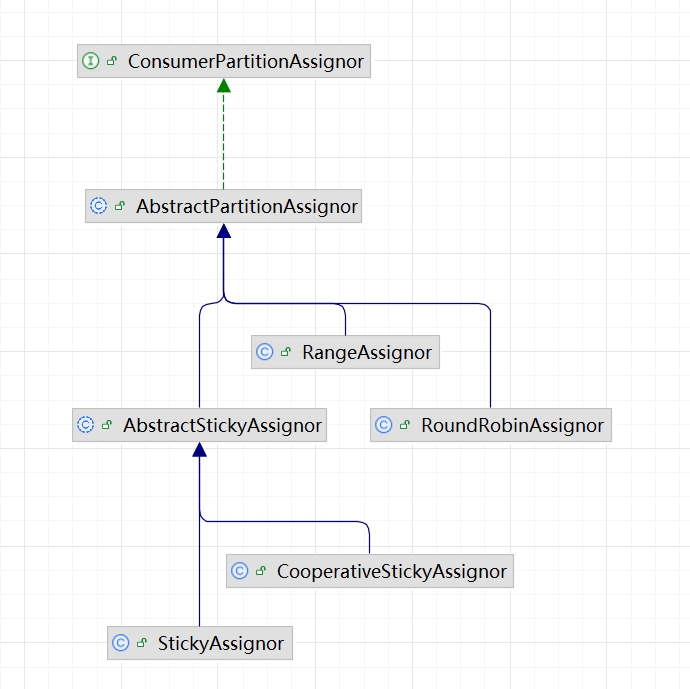
默認消費策略rangeAssignor:
我們debug啟動時,可以發現直接進入了我們的類:
package org.apache.kafka.clients.consumer 中的RangeAssignor
按著范圍分區:?
假設我們的myTopic主題中有10個分區,一個消費組中有三個消費者consumer1 ,consumer2,consunmer3。
他的分配策略是:
1.計算每個消費者應得的分區數:
分區總數/消費者數=3.......1;
但是有一個余數是1.這時第一個消費者會獲取到4個分區。consumer1的分區數是4;
2.具體分配是:
consumer1:0 1 2 3
consumer2:4 5 6
consumer3:7 8 9?
?使用代碼測試一下:
消費者代碼:
package com.hdk.springbootkafkabase06.consumer;import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/5 18:26*/
@Component
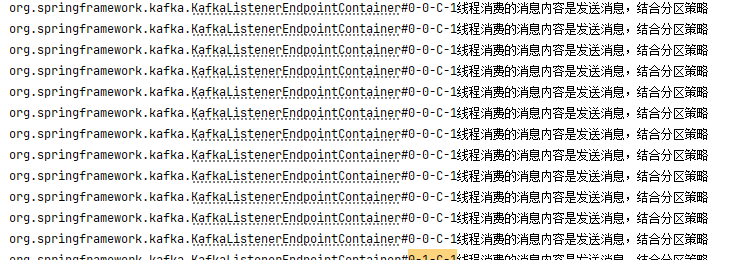
public class EventConsumer {/*** 默認策略RangeAssignor的結果:* org.springframework.kafka.KafkaListenerEndpointContainer#0-2-C-1 線程消費的消息內容是發送消息,結合分區策略* org.springframework.kafka.KafkaListenerEndpointContainer#0-1-C-1 線程消費的消息內容是發送消息,結合分區策略* org.springframework.kafka.KafkaListenerEndpointContainer#0-0-C-1 線程消費的消息內容是發送消息,結合分區策略* 發現是三個線程名在消費* 使用這個concurrency,后面的配置證明他的一個消費組中,有幾個消費者* 其實就是開啟了那幾個線程消費消息* 下面的代碼表示一個消費組中有三個消費者* @param record*/@KafkaListener(topics = "myTopic",groupId = "myGroup",concurrency ="3" )public void listener(ConsumerRecord<String,String> record){String value = record.value();//借助線程名查看不同的消費者消費消息System.out.println(Thread.currentThread().getName()+"線程消費的消息內容是"+value);}
}
生產者代碼:
package com.hdk.springbootkafkabase06.producer;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.support.SendResult;
import org.springframework.stereotype.Component;
import org.springframework.util.concurrent.ListenableFuture;
import org.springframework.util.concurrent.ListenableFutureCallback;/*** @Author HanDK* @CreateTime: 2025/5/5 18:29*/
@Component
public class EventProducer {@Autowiredprivate KafkaTemplate<String,String> kafkaTemplate;public void sendString(){for(int i=0;i<100;i++){String index=String.valueOf(i);ListenableFuture<SendResult<String, String>> send = kafkaTemplate.send("myTopic", index,"發送消息,結合分區策略");send.addCallback(new ListenableFutureCallback<SendResult<String, String>>() {@Overridepublic void onFailure(Throwable ex) {System.out.println("消息發送失敗,開始寫入數據庫");try {Thread.sleep(2000);} catch (InterruptedException e) {throw new RuntimeException(e);}System.out.println("寫如數據庫成功");}@Overridepublic void onSuccess(SendResult<String, String> result) {System.out.println("發送消息成功");}});}}
}
?創建主題和分區代碼:
package com.hdk.springbootkafkabase06.config;import org.apache.kafka.clients.admin.NewTopic;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.stereotype.Component;/*** @Author HanDK* @CreateTime: 2025/5/5 19:58*/
@Configuration
public class KafkaConfig {/*** 創建一個主題,里面有10個分區* @return*/@Beanpublic NewTopic newTopic(){return new NewTopic("myTopic",10,(short) 1);}
}
輪詢策略RoundRobinAssignor:
在配置文件中我們發現是無法直接通過配置文件的方式配置的,所以只能是代碼的形式編寫配置文件。
在輪詢的策略下,我們的消費的具體分配是:
consumer1:0 3? 6 9
consumer2:1 4 7?
consumer3:2 5 8
配置文件的編寫:
package com.hdk.springbootkafkabase06.config;import org.apache.kafka.clients.admin.NewTopic;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.RoundRobinAssignor;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.stereotype.Component;import java.util.HashMap;
import java.util.Map;import static org.apache.kafka.clients.consumer.RoundRobinAssignor.ROUNDROBIN_ASSIGNOR_NAME;/*** @Author HanDK* @CreateTime: 2025/5/5 19:58*/
@Configuration
public class KafkaConfig {/*** 創建一個主題,里面有10個分區* @return*/@Beanpublic NewTopic newTopic(){return new NewTopic("myTopic",10,(short) 1);}@Value("${spring.kafka.bootstrap-servers}")private String bootstrapServer;@Value("${spring.kafka.consumer.auto-offset-reset}")private String autoOffsetReset;@Value("${spring.kafka.consumer.key-deserializer}")private String keyDeserializer;@Value("${spring.kafka.consumer.value-deserializer}")private String valueDeserializer;/*** 自定義配置,返回Map類型的配置文件* @return*/@Beanpublic Map<String,Object> consumerConfig(){Map<String,Object> props = new HashMap<>();//設置主機和端口號props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,bootstrapServer);//設置序列化方式props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,keyDeserializer);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,valueDeserializer);//設置消費策略props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,autoOffsetReset);//設置消費分區策略為輪詢策略props.put(ConsumerConfig.PARTITION_ASSIGNMENT_STRATEGY_CONFIG, RoundRobinAssignor.class.getName() );return props;}/*** 創建消費者工廠* @return*/@Beanpublic ConsumerFactory consumerFactory(){ConsumerFactory<String, String> consumerFactory = new DefaultKafkaConsumerFactory<>(consumerConfig());return consumerFactory;}/*** 創建監聽器容器工廠* @return*/@Beanpublic KafkaListenerContainerFactory ourKafkaListenerContainerFactory(){ConcurrentKafkaListenerContainerFactory listenerContainerFactory = new ConcurrentKafkaListenerContainerFactory();listenerContainerFactory.setConsumerFactory(consumerFactory());return listenerContainerFactory;}
}
消費者代碼:
/*** 淪胥策略監聽* containerFactory = "ourKafkaListenerContainerFactory" 使用這個注解表明我們使用的監聽器容器工廠是哪個* 但是需要注意的是我們改變消費者的分區策略時,我們的消費組是不能有offset的* 我們將上面的myGroup改變為myGroup1* @param record*/@KafkaListener(topics = "myTopic",groupId = "myGroup1",concurrency ="3",containerFactory = "ourKafkaListenerContainerFactory")public void listenerRoundRobin(ConsumerRecord<String,String> record){System.out.println(Thread.currentThread().getName()+record);//借助線程名查看不同的消費者消費消息}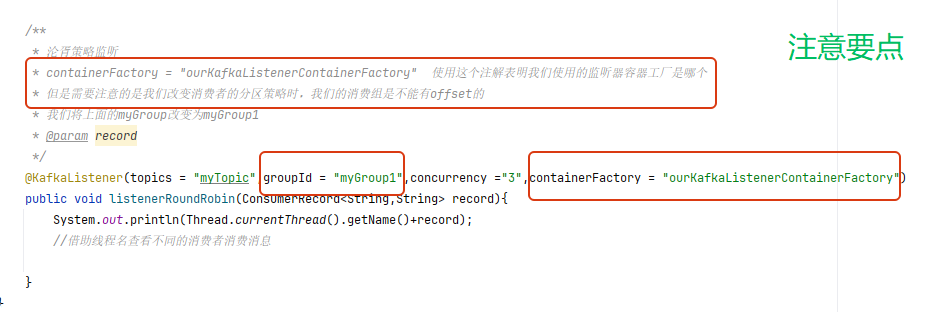
StickyAssignor:
盡可能的保持當前的消費者和分區的關系不變,即使我們的消費者的成員發生變話,也要減少不必要的分配。
僅僅只是對新的消費者或離開的消費者進行分區調整,大多數消費者還是繼續保持他的消費分區不變。只是少數的消費者處理額外的分區。是一種粘性的分配
CooperativeStickyAssignor:
?與StickyAssignor類似,但增加了對協作式重新分配的支持,消費者在他離開消費者之前通知協調器,以便協調器可以預先計劃分區遷移,而不是在消費者突然離開時進行分配。
Kafka事件(消息,數據)存儲:
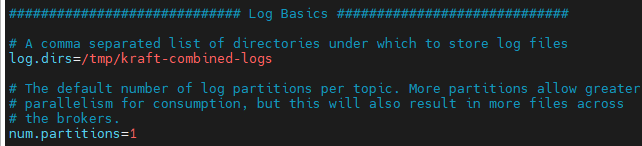
kafka的所有的事件消息都是以日志的形式保存的。他的配置方式是log.dir=****
kafka一般是海量的日志數據,避免日志文件過大,日志文件被放在多個目錄下,日志文件的命名規則是<topic_name>--<partition_id>;
 ?
?
 ?
?
Kafka的__consumer_offsets的主題:
這個主題記錄的每次消費完成之后,會保存當前消費到的最近的一個offset.,--consumer-offsets他保存了consumer_group某一時刻提交的offset信息。這個主題的默認有50個分區。
?
生產者的offset:
生產者發送一條消息到topic下的partition,kafka內部會為每條消息分配一個唯一的offset,該offset就是該消息在partition中的位置。
消費者的offset:
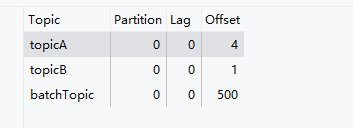
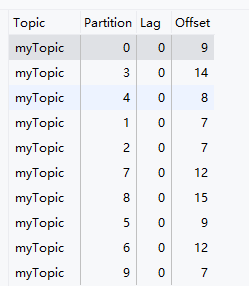
消費者的offset是消費者需要知道自己已經讀取到的位置,接下來需要從哪個位置開始讀取。
每個消費組中的消費者都會獨立的維護自己的offset,當消費者從某個partition讀取消息時,他會記錄當前讀到的offset,這樣即使是消費者宕機或重啟,也不會出現數據的丟失。(之后消息確認才會提交offset)









:在 Ubuntu 22.04 x64 系統中使用1Panel 部署 WordPress)






 --- Linux 內核基礎知識)


2025年第二十二屆五一數學建模競賽(五一杯/五一賽)解題思路|完整代碼論文集合)