編碼器
以下部分引用臺灣大學李宏毅教授的ppt 自己理解解釋一遍(在youtobe 上可以搜索李宏毅即可)
首先先來看transformer的架構圖
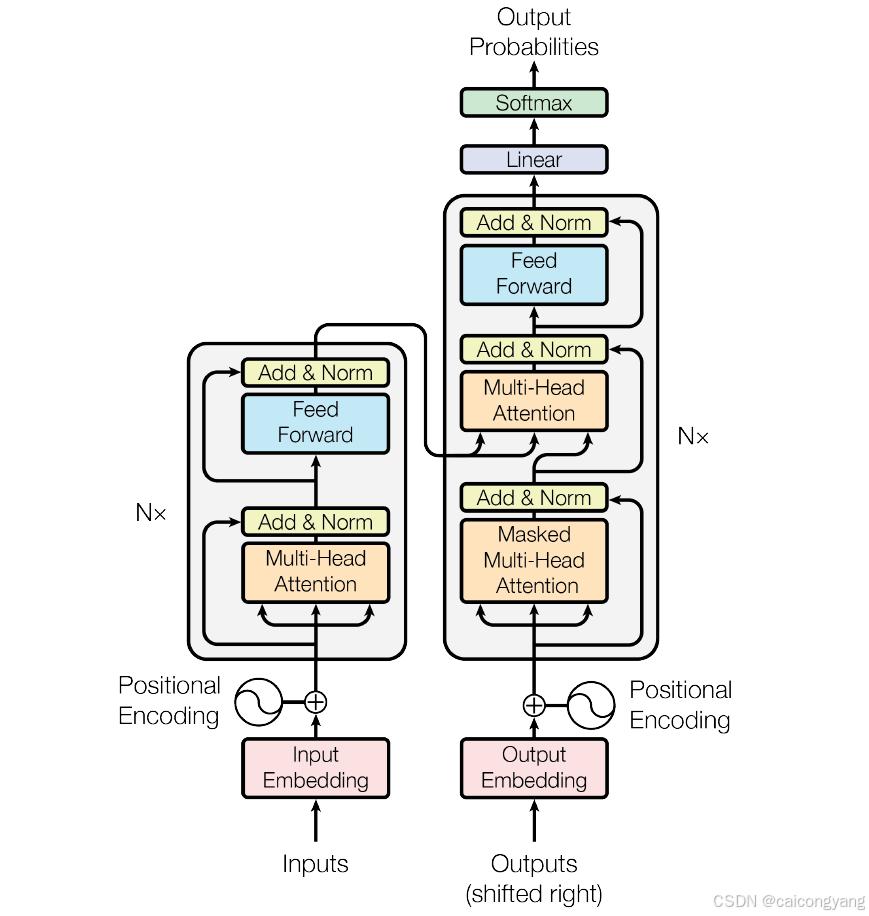
Embedding
我們先從Imput Embedding 跟 OutPutEmbedding 開始,讓我們用 bert 模型來做一個解釋
從huggingface上下載的bert-base-chinese模型中 有一個vocab.txt 放的是這個模型所有能認識的字;
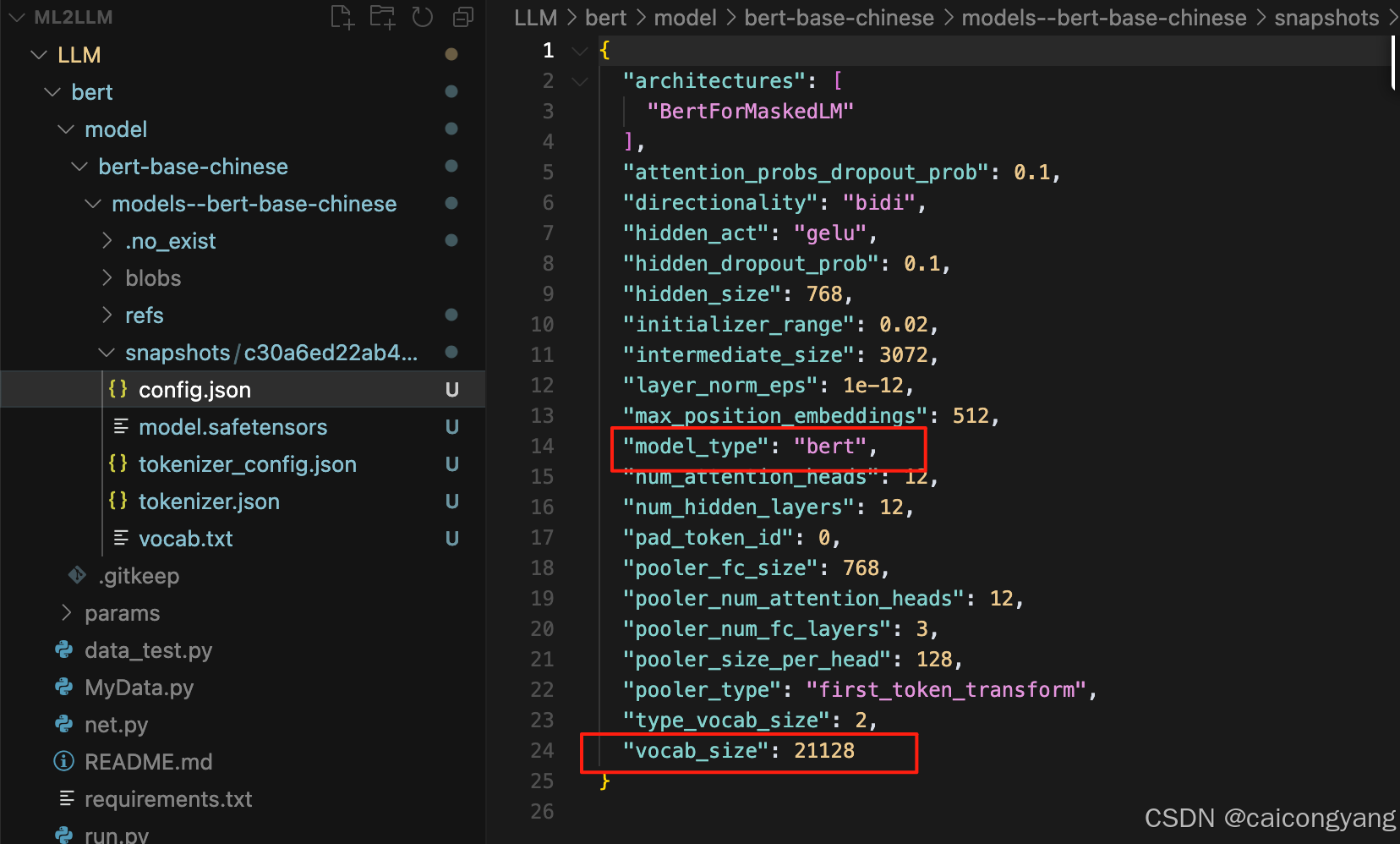
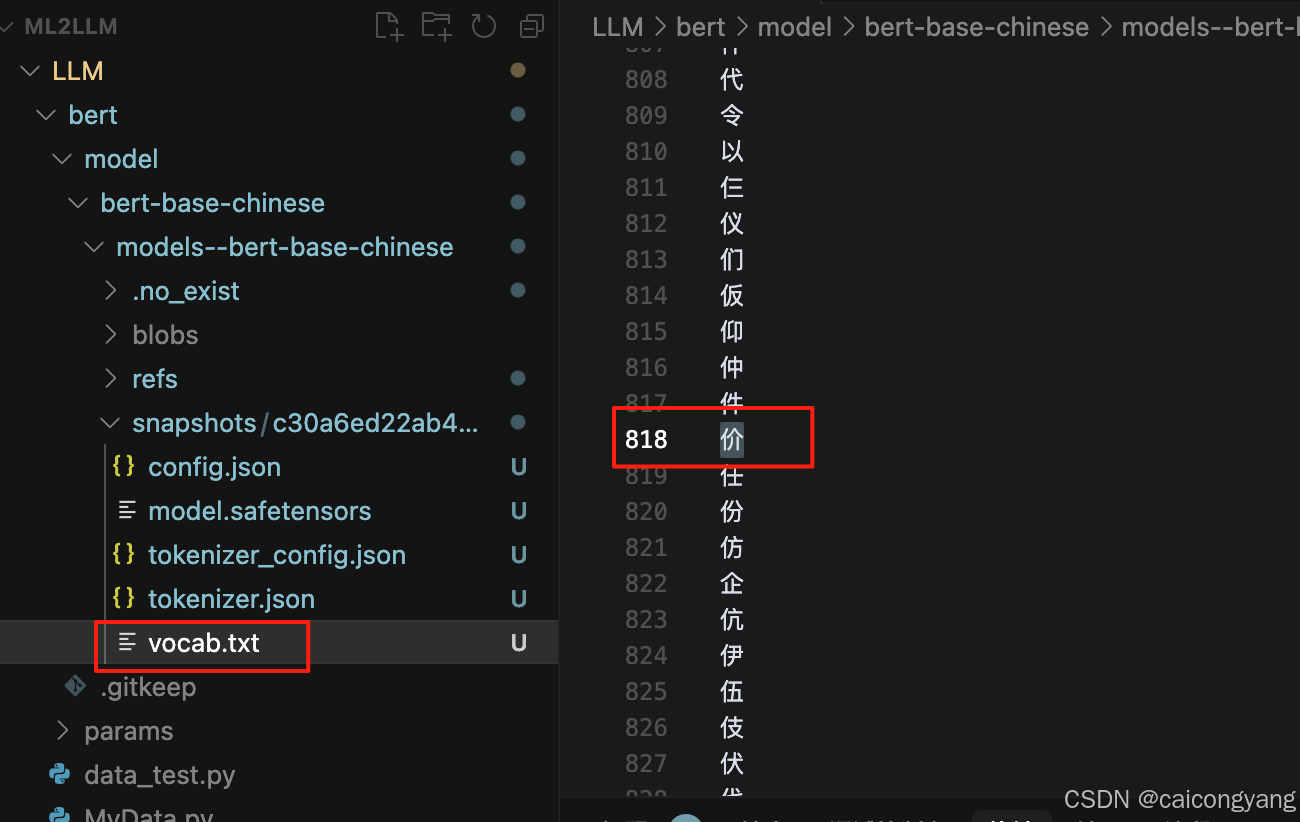 在config.json 中可以看到這個模型最大做事的vocab 是21128?
在config.json 中可以看到這個模型最大做事的vocab 是21128?
 讓我們來寫個py測試類來驗證編碼的過程
讓我們來寫個py測試類來驗證編碼的過程
from transformers import AutoTokenizer, BertTokenizer#加載字典和分詞器
token = BertTokenizer.from_pretrained("bert-base-chinese")
# print(token)sents = ["價格在這個地段屬于適中, 附近有早餐店,小飯店, 比較方便,無早也無所"]#批量編碼句子
out = token.batch_encode_plus(batch_text_or_text_pairs=[sents[0]],add_special_tokens=True,#當句子長度大于max_length時,截斷truncation=True,max_length=50,#一律補0到max_length長度padding="max_length",#可取值為tf,pt,np,默認為listreturn_tensors=None,#返回attention_maskreturn_attention_mask=True,return_token_type_ids=True,return_special_tokens_mask=True,#返回length長度return_length=True
)
#input_ids 就是編碼后的詞
#token_type_ids第一個句子和特殊符號的位置是0,第二個句子的位置1()只針對于上下文編碼
#special_tokens_mask 特殊符號的位置是1,其他位置是0
print(out)
for k,v in out.items():print(k,";",v)#解碼文本數據
# print(token.decode(out["input_ids"][0]),token.decode(out["input_ids"][1]))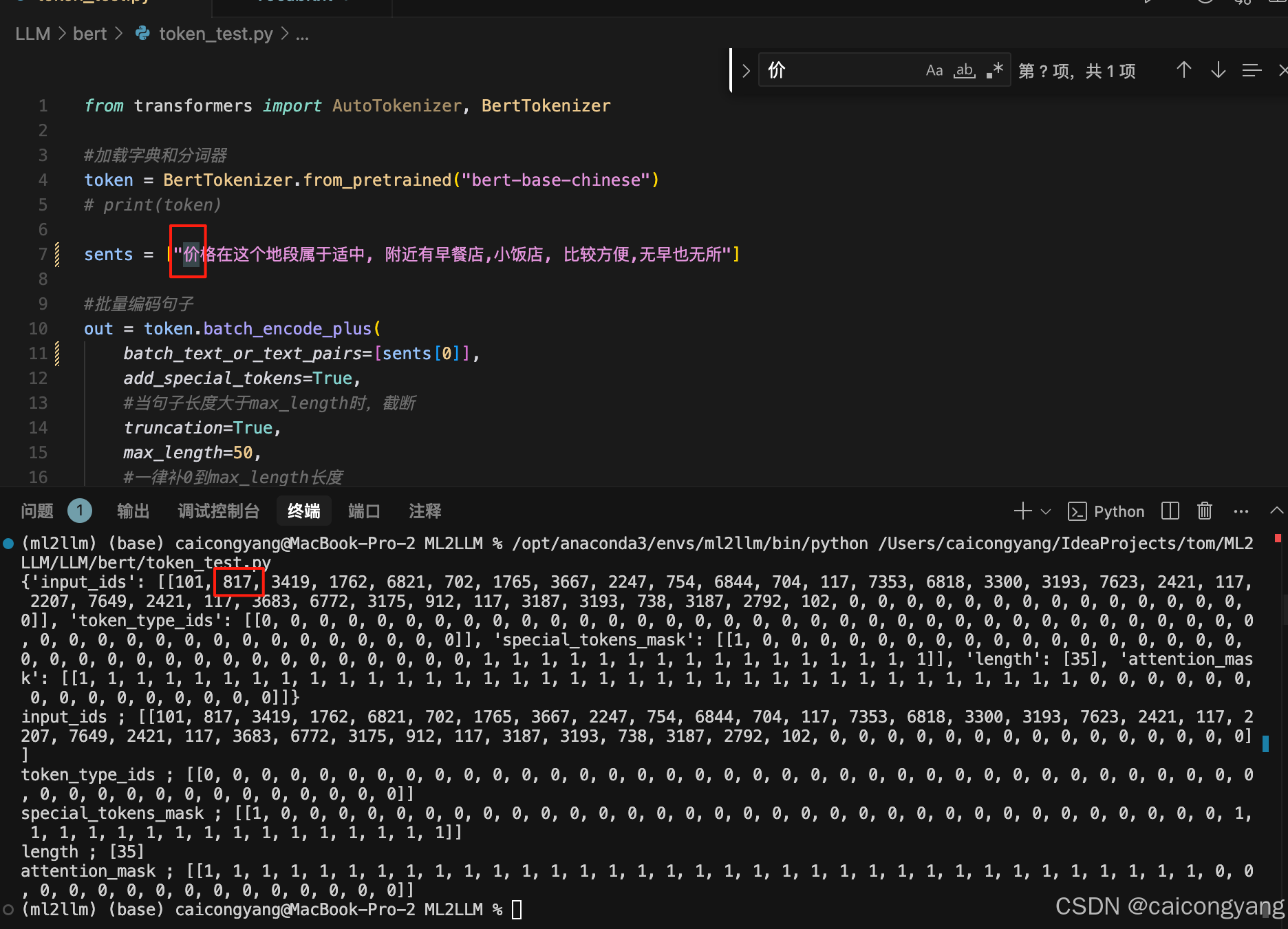
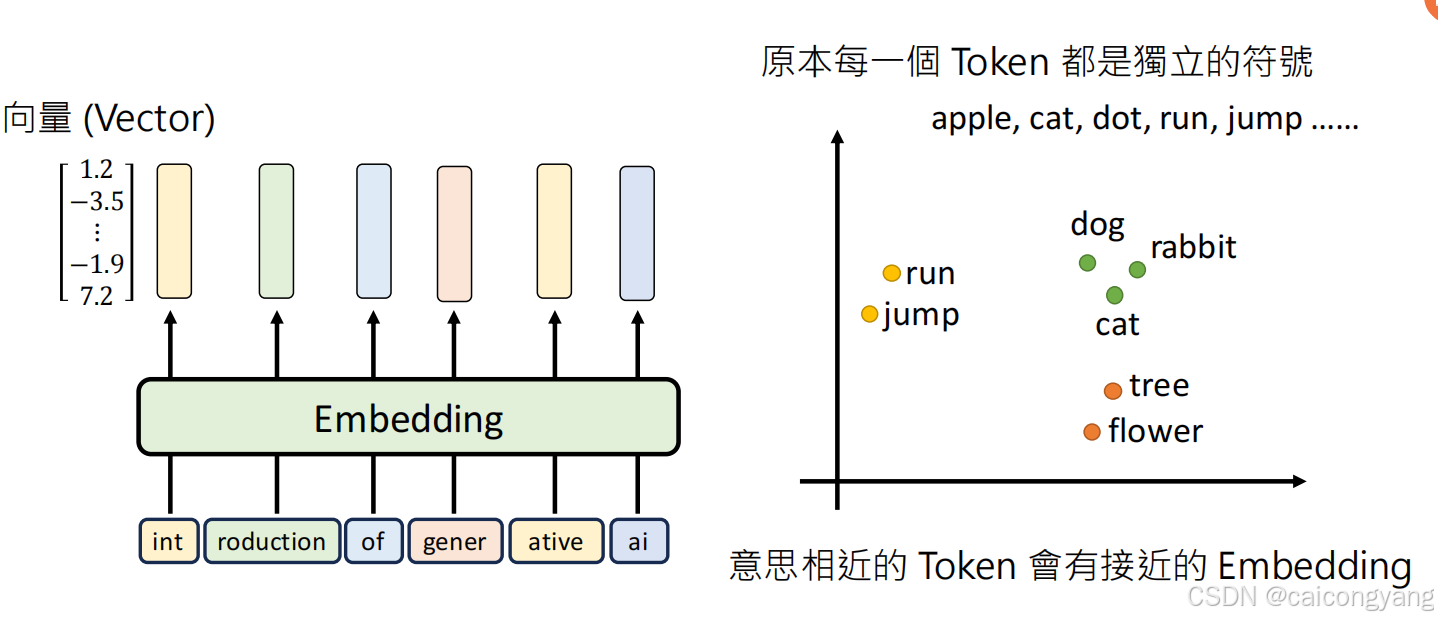
我們可以看到第一字價是字典的817的位置,第一張圖已經展示了;整個流程簡單的說明了transfomer的Embedding 過程,就是把文字變成?Token的過程;
當然后面的GPT3 這些其他的transfomer 都把這個詞典vocab.txt 給隱藏起來了;
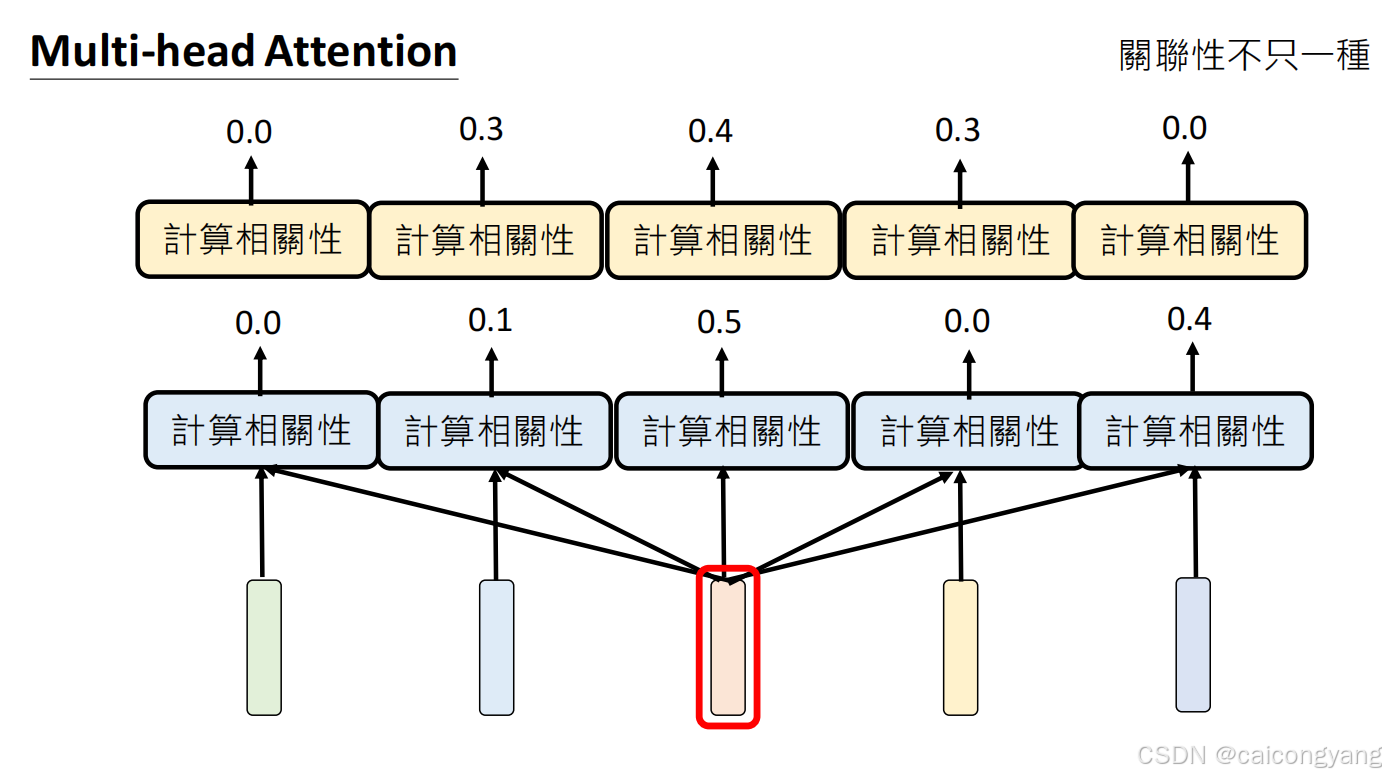
多頭注意力機制
第一步 embding完后把相近的token 放到一個多維矩陣里面了;這樣相近的詞就靠的更近了
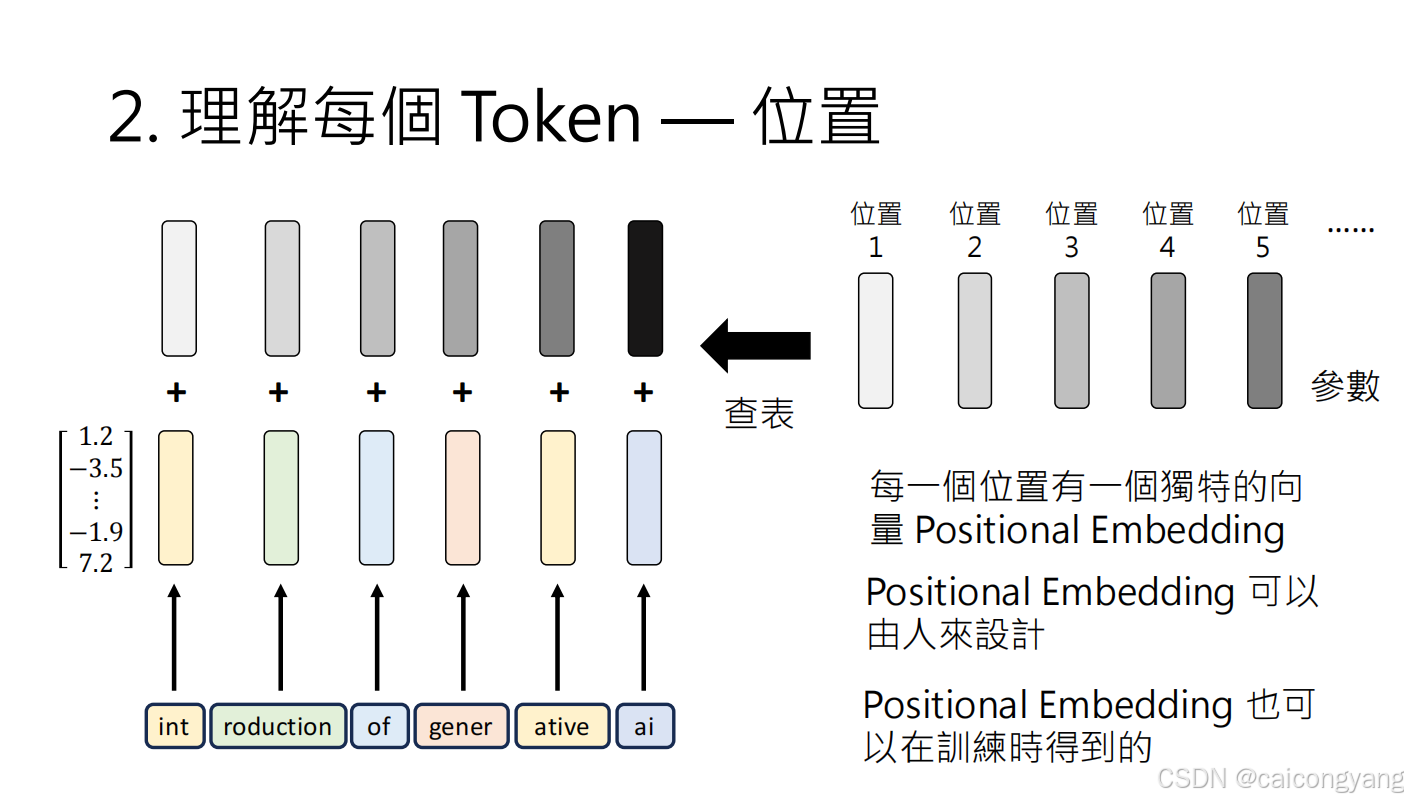
需要加入位置編碼,這樣矩陣才能感知句子的詞的前后順序
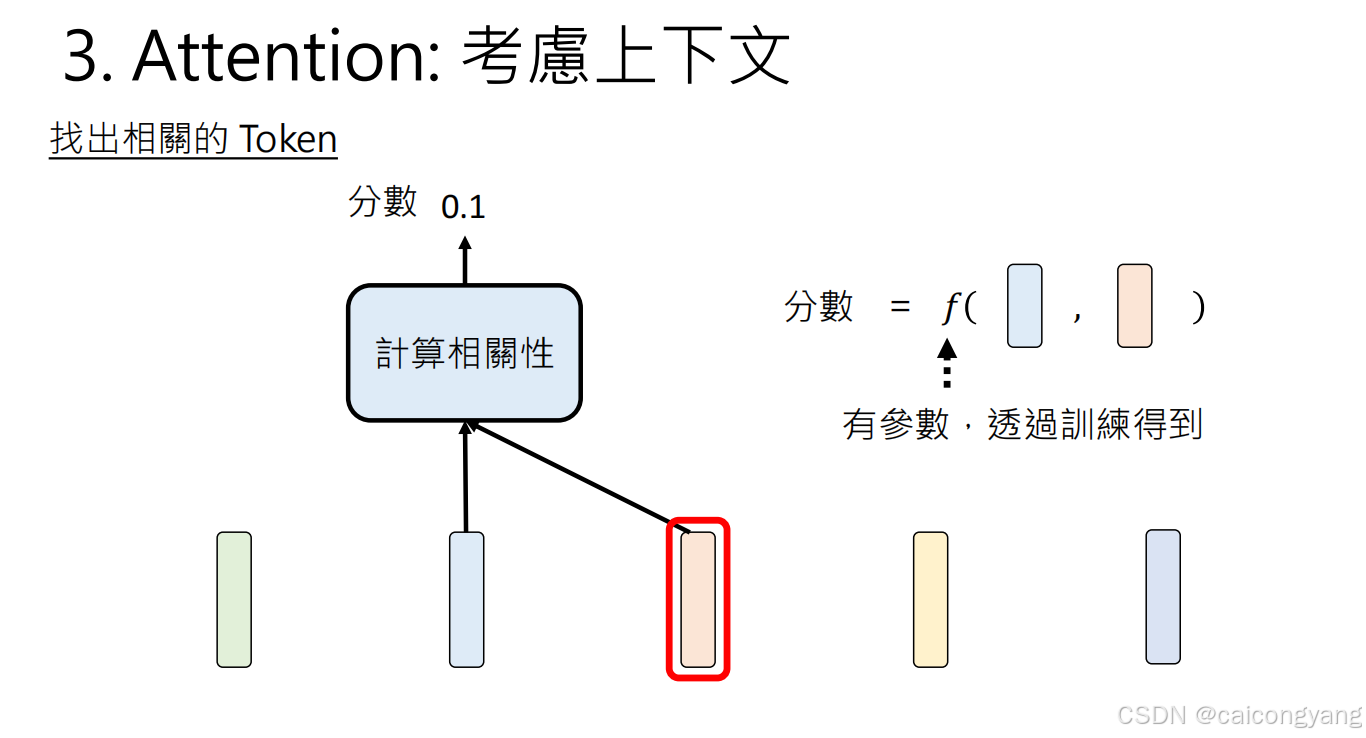
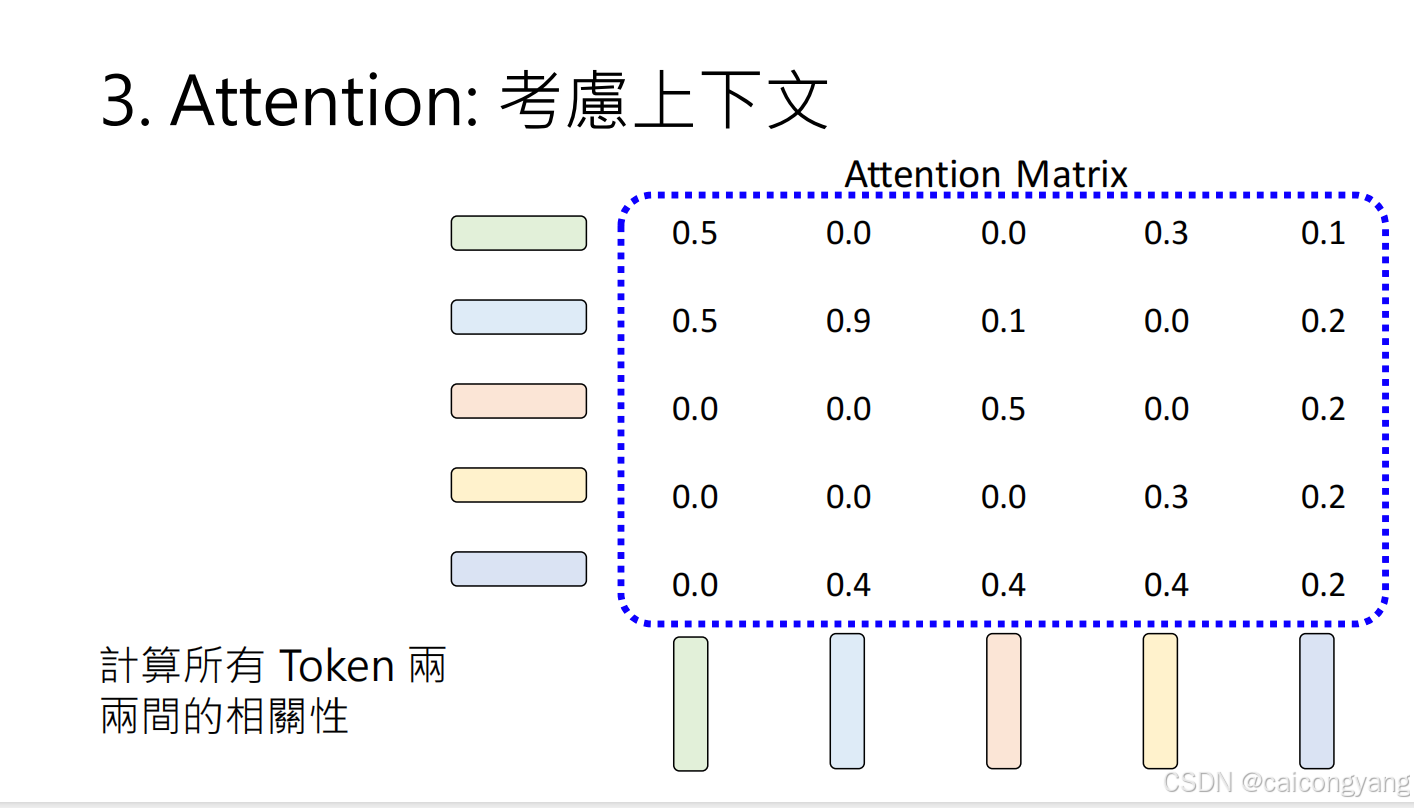
自注意力計算過程:
- 對每個輸入token,GPT計算三個向量:查詢(Q)、鍵(K)和值(V)
- 這些向量通過輸入與學習到的權重矩陣相乘得到
- 然后計算Q與K的點積來確定注意力分數
- 最后將注意力分數用于對V進行加權求和
?這塊其實理解的不是很好
Feed Forward
前向傳播是模型預測/推理的過程,如圖右側所示。它的步驟非常直觀:
- 將數據輸入到神經網絡
- 數據在網絡內部經過一系列數學計算
- 網絡輸出預測結果
這就像人類的思考過程:接收信息 → 思考處理 → 得出結論。
輸出線性層與Softmax:
? ? ? ? 將解碼器輸出轉換為概率分布
完整流程:
在完整的處理流程中:
- 輸入經過嵌入層、位置編碼和多層?Transformer 塊處理
- 最終的隱藏狀態通過一個線性層(通常是與輸入嵌入共享權重的)
- 線性層輸出經過?softmax 函數轉換為概率分布
- 這個概率分布就是最終的輸出,表示下一個 token 可能是詞表中每個詞的概率
對于像 GPT 這樣的自回歸模型,在每個位置上模型輸出的是詞表中所有可能 token 的概率分布,最高概率的?token 通常被選為該位置的預測結果。
這些概率是模型對"下一個 token 應該是什么"的預測,是用于實際生成文本或計算損失函數的關鍵輸出。 注意GPT 只使用transformer 中的解碼器部分
更多神經網絡相關的學習筆記見我的github:?https://github.com/caicongyang/ML2LLM/blob/main/LLM/neural_network_fundamentals_simplified.md

)
![[吾愛出品][Windows] 產品銷售管理系統2.0](http://pic.xiahunao.cn/[吾愛出品][Windows] 產品銷售管理系統2.0)
詳細方案與部署教程)


)

)




![[藍橋杯 2025 省 B] 水質檢測(暴力 )](http://pic.xiahunao.cn/[藍橋杯 2025 省 B] 水質檢測(暴力 ))





