目錄
一.背景描述
二.理論部分
三.程序設計
編程思路
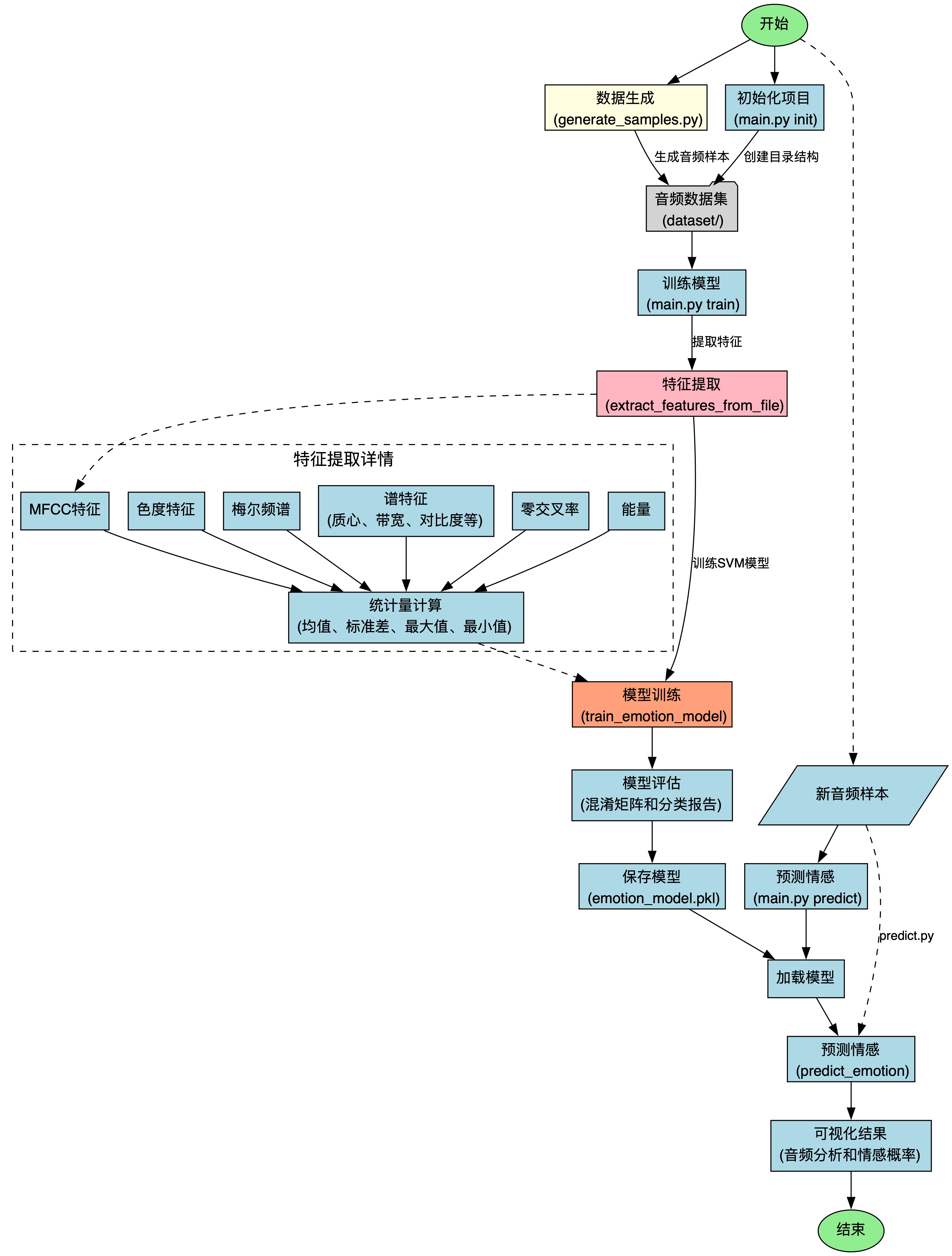
流程圖
1.信號部分 創建數據 generate_samples.py
頭文件
生成函數 generate_emotion_sample
傳入參數
存儲路徑
生成參數
創建基礎正弦波信號
調制基礎正弦波
對于憤怒可以增加噪聲
歸一化信號
存儲
主函數 main
2.交叉部分 特征提取 audio_emotion.py
頭文件
提取單個文件的特征?extract_features_from_file
傳入參數
提取特征向量
計算統計值并返回矩陣
提取各情感的特征?extract_features_from_directory
傳入參數
初始化
提取文件 & 識別特征
訓練情感識別模型?train_emotion_model
傳入參數
劃分訓練集和測試集
訓練SVM模型
評估測試集
計算混淆矩陣
返回
保存模型
加載模型
預測單個音頻的情感
混淆矩陣可視化
音頻特征可視化
傳入參數
處理音頻
特征提取
可視化并保存
返回
3.機器學習部分 train_model.py
為何要獨立出一個訓練腳本
頭文件
主函數 main
4.封裝部分 main.py
創建項目目錄
提取特征并訓練模型
預測單個文件情感
顯示
主邏輯
5.預測部分 predict.py
頭文件
可視化音頻特征
主邏輯?
應用
四.運行展示
初始化目錄
生成樣本
訓練模型
查看結果并分析
應用模型
查看分析圖
一.背景描述
智能識別不同情景下的聲音信號體現的情感,比如客戶接電話時的語音情感,還可以用于智能手表、人工智能助手(比如豆包的聊天過程中的人類情感反饋,提高豆包“情商”)等等
二.理論部分
1.首先分析了不同情感聲音信號的特征,用于下面的構造信號
2.構造不同情感的聲音信號(通過將時間序列代入基準正弦信號,接著進行加、乘操作進行調制)用于訓練SVM模型
3.對信號進行時頻域變換,比如傅立葉變換
chroma = librosa.feature.chroma_stft(y=y, sr=sr)4.進行特征提取,捕捉譜質心、譜帶寬、譜對比度等等
5.進行特征的統計,計算了四種統計量:均值、標準差、最小值、最大值
6.通過均方根計算能量,這是情感表達的重要指標
7.特征空間降維,通過統計的方式進行了隱式降維
三.程序設計
編程思路
整體框架是:
1.信號生成?generate_samples.py
2.特征提取?audio_emotion.py
3.訓練模型?train_model.py
4.封裝模塊 main.py
5.應用模型?predict.py
流程圖
1.信號部分 創建數據 generate_samples.py
頭文件
import os
import numpy as np
import librosa
import soundfile as sf
from scipy.io import wavfile生成函數 generate_emotion_sample
傳入參數
emotion ????????????????情感
freq_range? ? ????????生成音頻信號的頻率范圍
duration_range? ? ? 生成信號的持續時間范圍
num_samples? ? ? ? 生成的音頻樣本數量
存儲路徑
emotion_dir = os.path.join("dataset", emotion)os.makedirs(emotion_dir, exist_ok=True)dataset 是數據集的根目錄,在根目錄下創建名為傳入參數emotion的子目錄
第二句的作用是保證文件夾存在
生成參數
首先我們得明確各情感聲音特色
"happy":高頻、短持續時間,模擬快樂情感。"sad":低頻、長持續時間,模擬悲傷情感。"angry":中高頻、短脈沖,模擬憤怒情感。"neutral":中等頻率和持續時間,模擬中性情感。
那么我們只需要判斷,然后分支為各情感創建獨特的參數就好
以“happy”為例
首先我們要從指定的頻率中隨機選擇頻率值,對應下面的np.random.uniform(freq_range[0], freq_range[1])語句,里面的freq_range[ 0 ] 和 freq_range[1] 分別代表頻率范圍的上下限,我們會在主函數中提前定義
(注意:我們這里得用numpy的random,而不是python自帶的random函數,因為np的支持數組高效操作)
然后我們還需要持續時間,和頻率同理也是np.random.uniform
接著我們設置了音頻信號的振幅頻率(音量),快樂的聲音為0.6中等偏高來模擬
最后我們設置振幅調制的頻率,快樂的是8.0:快速的變化,模擬快樂的活潑
其他的感情和快樂同理
for i in range(num_samples):if emotion == "happy":# 高頻和短持續時間freq = np.random.uniform(freq_range[0], freq_range[1])duration = np.random.uniform(duration_range[0], duration_range[1])amplitude = 0.6modulation_freq = 8.0elif emotion == "sad":# 低頻和長持續時間freq = np.random.uniform(freq_range[0]/2, freq_range[1]/2)duration = np.random.uniform(duration_range[0]*1.5, duration_range[1]*1.5)amplitude = 0.4modulation_freq = 2.0elif emotion == "angry":# 中高頻和短脈沖freq = np.random.uniform(freq_range[0]*1.2, freq_range[1]*1.2)duration = np.random.uniform(duration_range[0], duration_range[1])amplitude = 0.8modulation_freq = 12.0else: # neutral# 中等頻率和持續時間freq = np.random.uniform(freq_range[0]*0.8, freq_range[1]*0.8)duration = np.random.uniform(duration_range[0]*1.2, duration_range[1]*1.2)amplitude = 0.5modulation_freq = 4.0
創建基礎正弦波信號
sample_rate = 22050t = np.linspace(0, duration, int(sample_rate * duration), endpoint=False)signal = amplitude * np.sin(2 * np.pi * freq * t)
首先我們設置了音頻信號的采樣頻率,單位是“樣本/秒”
然后我們用 numpy 的 linspace 創建了一個時間序列,用于表示信號的時間軸,第一個參數0表示時間序列起點,duration是時間序列的終點(也就是我們在上面生成的持續時間),第三個參數是時間序列的點數(計算方式:采樣率乘以持續時間),endpoint保證時間序列不包含終點
然后我們生成一個正弦波信號,amplitude表示正弦波的振幅(音量),freq時頻率(音調),t是上面生成的時間序列,通過?2 * np.pi * freq * t 將頻率轉為角頻率,計算正弦波的相位
調制基礎正弦波
我們還需要根據我們的情感對基礎波進行處理
modulation = 1.0 + 0.3 * np.sin(2 * np.pi * modulation_freq * t)signal = signal * modulation
modulation是生成的調制信號,用于改變原始信號的振幅,其中 1.0 是基礎振幅(乘法的初元), 0.3表示調制強度(影響程度)
第二句代碼也就是將調制信號作用在原正弦波signal上
對于憤怒可以增加噪聲
對于“angry”:加上信號
if emotion == "angry":noise = np.random.normal(0, 0.1, signal.shape)signal = signal + noise歸一化信號
進行歸一化:除以max乘以1
限制信號在 [ -1,1 ] 中,確保生成的音頻信號符合音頻文件格式的要求,防止信號溢出
signal = signal / np.max(np.abs(signal))
存儲
file_path = os.path.join(emotion_dir, f"{emotion}_sample_{i+1}.wav")sf.write(file_path, signal, sample_rate)print(f"生成樣本: {file_path}")emotion_dir 在函數剛進來一開始就定義了
然后我加了一句print方便調試看報錯
主函數 main
def main():freq_range = (220, 880)duration_range = (2.0, 4.0)emotions = ["happy", "sad", "angry", "neutral"]for emotion in emotions:generate_emotion_sample(emotion, freq_range, duration_range, num_samples=50)print("所有測試樣本生成完成!")if __name__ == "__main__":main()freq_range 是頻率范圍
duration_range 是持續時間
num是生成數據集的個數,我先設置為50(多多益善)
然后用 for 遍歷感情
2.交叉部分 特征提取 audio_emotion.py
頭文件
import os
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
import joblib
import glob提取單個文件的特征?extract_features_from_file
傳入參數
file_path? ? ? ? 文件的路徑
win? ? ? ? ? ? ? ? 計算特征的時間窗口長度
step? ? ? ? ? ? ? ?步長
提取特征向量
先讀取音頻文件
y, sr = librosa.load(file_path, sr=None)
讀取MFCC特征
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
提取色度特征
chroma = librosa.feature.chroma_stft(y=y, sr=sr)
提取梅爾頻譜
mel = librosa.feature.melspectrogram(y=y, sr=sr)
提取譜質心
spectral_centroid = librosa.feature.spectral_centroid(y=y, sr=sr)
提取譜帶寬
spectral_bandwidth = librosa.feature.spectral_bandwidth(y=y, sr=sr)
提取譜對比度
spectral_contrast = librosa.feature.spectral_contrast(y=y, sr=sr)
提取譜平坦度
spectral_flatness = librosa.feature.spectral_flatness(y=y)
提取零交叉率
zcr = librosa.feature.zero_crossing_rate(y)
提取能量
energy = np.mean(librosa.feature.rms(y=y))
計算統計值并返回矩陣
features.append(energy)feature_names = []for name in ['mfccs', 'chroma', 'mel', 'spectral_centroid', 'spectral_bandwidth', 'spectral_contrast', 'spectral_flatness', 'zcr']:for stat in ['mean', 'std', 'min', 'max']:feature_names.append(f"{name}_{stat}")feature_names.append('energy')return np.array(features), feature_names
提取各情感的特征?extract_features_from_directory
傳入參數
directory????????數據集根目錄
emotions???????情感類別
初始化
features = []labels = []feature_names = None其中
feature? ? ? ? ????????????????特征向量
labels? ? ? ? ? ????????????????情感標簽
feature_names? ? ? ? ? ? 特征的名稱列表
提取文件 & 識別特征
首先我加了一句 print 方便調試
print(f"開始從以下類別提取特征: {emotions}")for emotion in emotions:emotion_dir = os.path.join(directory, emotion)if not os.path.isdir(emotion_dir):continuefor file_name in glob.glob(os.path.join(emotion_dir, "*.wav")):print(f"處理文件: {file_name}")feature_vector, names = extract_features_from_file(file_name)if feature_vector is not None:features.append(feature_vector)labels.append(emotion)if feature_names is None:feature_names = names然后我們開始
遍歷情感類別?for emotion in emotions(如果子目錄不存在那就continue跳過)
遍歷音頻文件?for file_name in glob.glob(os.path.join(emotion_dir, "*.wav"))
提取音頻特征 對于提取到的單個文件開始調用extract_features_from_file
存儲特征和標簽 append
最后我們返回
return np.array(features), np.array(labels), feature_names
后面的就是機器學習部分
訓練情感識別模型?train_emotion_model
傳入參數
feature? ? ? ? ?特征矩陣,每一行都是一個音頻的特征向量,包含提取到的各種統計特征
labels? ? ? ? ? ?標簽數組
test_size? ? ? 測試集的比例,一般正常訓練都是占比20%到30%,本次項目中設為0.2
劃分訓練集和測試集
X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=test_size, random_state=42)
訓練SVM模型
model = SVC(kernel='rbf', probability=True)model.fit(X_train, y_train)評估測試集
y_pred = model.predict(X_test)report = classification_report(y_test, y_pred, output_dict=True)
計算混淆矩陣
cm = confusion_matrix(y_test, y_pred)返回
model????????SVM模型
report? ? ? ? 分類報告
cm? ? ? ? ? ? ?混淆矩陣
X_test? ? ? ? 測試集的特征矩陣,來評估模型性能
y_test? ? ? ? ?測試集的真實標簽,用于對比
y_pred? ? ? ? 模型在測試集的預測標簽,用于對比
return model, report, cm, X_test, y_test, y_pred
保存模型
def save_model(model, output_path="emotion_model.pkl"):joblib.dump(model, output_path)print(f"模型已保存到 {output_path}")加載模型
def load_model(model_path="emotion_model.pkl"):return joblib.load(model_path)預測單個音頻的情感
調用extract_features_from_file函數從指定file_path里面提取特征向量,然后特征預處理,將特征向量轉換為模型可以接受的二維數組形狀,接著調用model模型進行情感預測,返回每個情感類別的預測概率,便于分析模型的信心程度。這個函數在audio腳本中并沒有被使用,而是在后面的main.py文件中被調用了
def predict_emotion(model, file_path):features, _ = extract_features_from_file(file_path)if features is not None:features = features.reshape(1, -1)prediction = model.predict(features)[0]probabilities = model.predict_proba(features)[0]return prediction, probabilitiesreturn None, None混淆矩陣可視化
為了方便查看混淆矩陣,我用matplotlib來進行數據的可視化(由于我之前在數模比賽中做過斯皮爾曼相關矩陣的可視化,所以還是感覺輕車熟路的)
def visualize_confusion_matrix(cm, classes):plt.figure(figsize=(10, 8))plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)plt.title('混淆矩陣')plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i in range(cm.shape[0]):for j in range(cm.shape[1]):plt.text(j, i, format(cm[i, j], 'd'),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('真實標簽')plt.xlabel('預測標簽')plt.tight_layout()plt.savefig('confusion_matrix.png')plt.show()效果展示
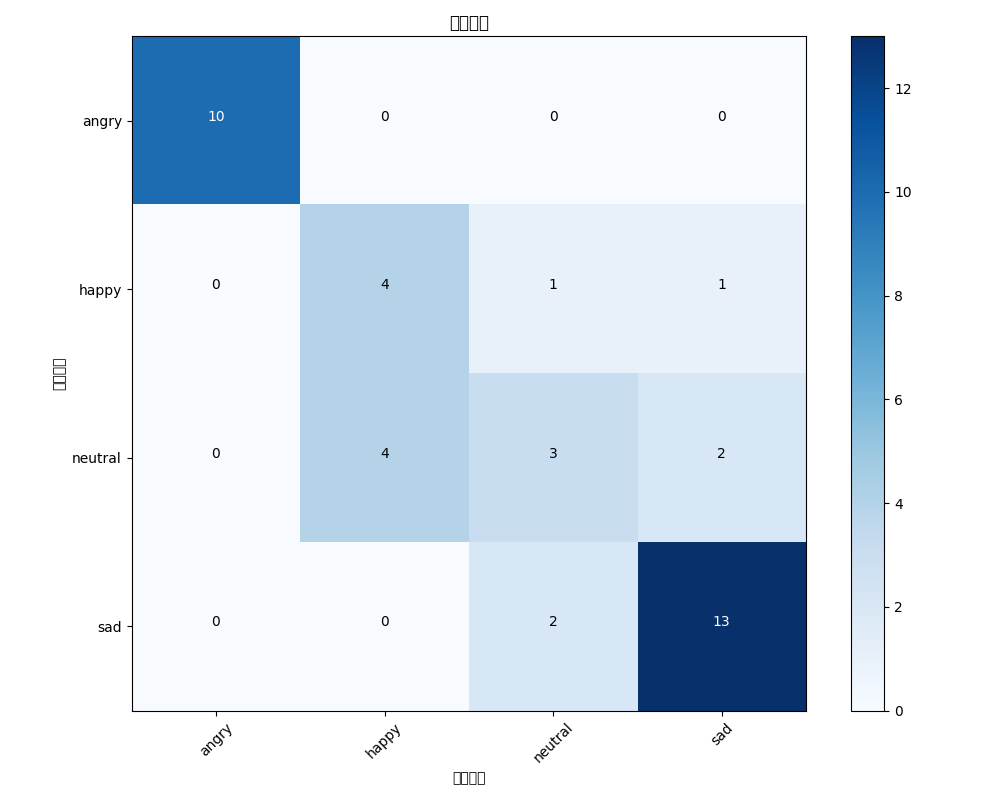
從圖中可以直觀的看到我們的模型準確率是不錯的,具體的結論在后面分析
音頻特征可視化
傳入參數
audio_file? ? ? ? 待分析的音頻文件路徑
處理音頻
音頻加載
y, sr = librosa.load(audio_file, sr=None)音頻持續時間計算
duration = librosa.get_duration(y=y, sr=sr)特征提取
梅爾頻譜
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr)
mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)MFCC(梅爾頻譜倒譜系數)?
mfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)色度圖
chroma = librosa.feature.chroma_stft(y=y, sr=sr)可視化并保存
plt.figure(figsize=(12, 10))# 波形plt.subplot(4, 1, 1)librosa.display.waveshow(y, sr=sr)plt.title('音頻波形')# 梅爾頻譜plt.subplot(4, 1, 2)librosa.display.specshow(mel_spec_db, sr=sr, x_axis='time', y_axis='mel')plt.colorbar(format='%+2.0f dB')plt.title('梅爾頻譜')# MFCCplt.subplot(4, 1, 3)librosa.display.specshow(mfccs, sr=sr, x_axis='time')plt.colorbar()plt.title('MFCC')# 色度圖plt.subplot(4, 1, 4)librosa.display.specshow(chroma, sr=sr, x_axis='time', y_axis='chroma')plt.colorbar()plt.title('色度圖')plt.tight_layout()plt.savefig('audio_analysis.png')plt.show()效果展現
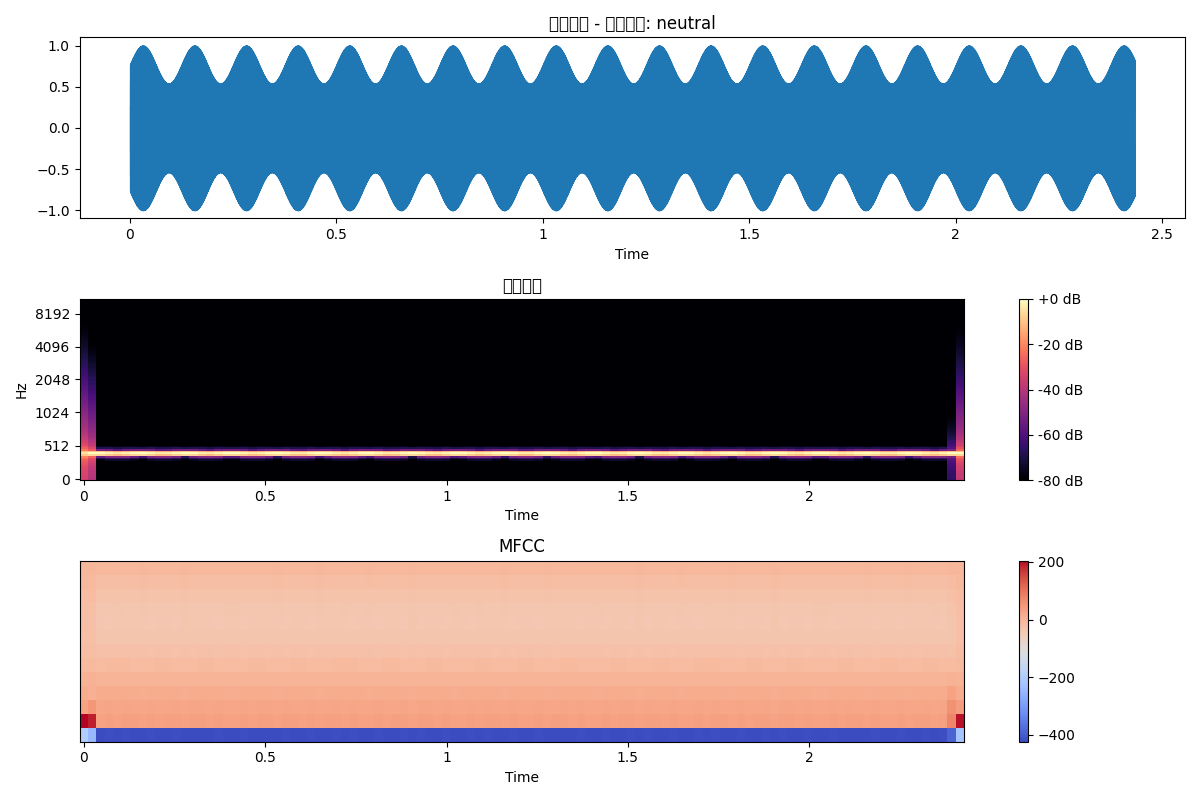
返回
將特征數據和原始數據返回,便于后面分析
return mel_spec, mfccs, chroma, sr, y3.機器學習部分 train_model.py
為何要獨立出一個訓練腳本
可以看到我們之前在audio_emotion.py中包含了一系列功能,但是它只是一個功能庫,并不會執行,只是定義了如何訓練
那么我們就需要新寫一個執行腳本來調用,他就是我們的train_model.py,這種模塊化的設計方便我們更換不同的訓練方法
頭文件
import os
import numpy as np
import librosa
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
import joblib
import glob
import time
from audio_emotion import extract_features_from_file設置輸出日志
LOG_FILE = "training_log.txt"寫入輸出日志
def log_message(message):print(message)with open(LOG_FILE, "a") as f:timestamp = time.strftime("%Y-%m-%d %H:%M:%S")f.write(f"[{timestamp}] {message}\n")主函數 main
獲取情感類別
emotions = [d for d in os.listdir("dataset") if os.path.isdir(os.path.join("dataset", d))]
初始化特征和標簽
features = []labels = []feature_names = None
開始訓練
for emotion in emotions:emotion_dir = os.path.join("dataset", emotion)audio_files = glob.glob(os.path.join(emotion_dir, "*.wav"))if not audio_files:log_message(f"警告: {emotion} 類別中沒有發現WAV文件。")continuelog_message(f"處理 {len(audio_files)} 個 {emotion} 類別的文件...")for audio_file in audio_files:log_message(f"提取特征: {audio_file}")feature_vector, names = extract_features_from_file(audio_file) # 使用原始函數if feature_vector is not None:features.append(feature_vector)labels.append(emotion)if feature_names is None:feature_names = namesif not features:log_message("錯誤: 沒有成功提取任何特征,請檢查音頻文件格式。")return# 轉換為numpy數組features = np.array(features)labels = np.array(labels)log_message(f"成功提取 {len(features)} 個樣本的特征,每個樣本 {features.shape[1]} 個特征。")# 劃分訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(features, labels, test_size=0.2, random_state=42)log_message(f"訓練集: {X_train.shape[0]} 個樣本,測試集: {X_test.shape[0]} 個樣本。")# 訓練SVM模型log_message("開始訓練SVM模型...")model = SVC(kernel='rbf', probability=True)model.fit(X_train, y_train)log_message("SVM模型訓練完成。")# 在測試集上評估y_pred = model.predict(X_test)# 計算分類報告report = classification_report(y_test, y_pred, output_dict=True)# 輸出分類報告log_message("\n分類報告:")for emotion in sorted(report.keys()):if emotion != "accuracy" and emotion != "macro avg" and emotion != "weighted avg":precision = report[emotion]['precision']recall = report[emotion]['recall']f1 = report[emotion]['f1-score']support = report[emotion]['support']log_message(f"{emotion}:\t精確率: {precision:.2f}, 召回率: {recall:.2f}, F1: {f1:.2f}, 樣本數: {support}")log_message(f"\n整體準確率: {report['accuracy']:.2f}")# 保存混淆矩陣log_message("生成混淆矩陣...")cm = confusion_matrix(y_test, y_pred)plt.figure(figsize=(10, 8))plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)plt.title('混淆矩陣')plt.colorbar()# 添加標簽classes = sorted(np.unique(labels))tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)# 在格子中添加數字thresh = cm.max() / 2.for i in range(cm.shape[0]):for j in range(cm.shape[1]):plt.text(j, i, format(cm[i, j], 'd'),horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('真實標簽')plt.xlabel('預測標簽')plt.tight_layout()# 保存混淆矩陣圖像plt.savefig('confusion_matrix.png')log_message("混淆矩陣已保存為 confusion_matrix.png")# 保存模型joblib.dump(model, 'emotion_model.pkl')log_message("模型已保存到 emotion_model.pkl")log_message("模型訓練和評估完成!")
4.封裝部分 main.py
最后我們還需要一個命令行界面用于調用模塊、封裝框架,他就是main文件
創建項目目錄
def create_project_structure():print("開始創建項目目錄結構...")os.makedirs("dataset", exist_ok=True)emotions = ["happy", "sad", "angry", "neutral"]for emotion in emotions:os.makedirs(os.path.join("dataset", emotion), exist_ok=True)print("項目目錄結構已創建,請將音頻文件放入相應的情感文件夾中:")print(" - dataset/happy/")print(" - dataset/sad/")print(" - dataset/angry/")print(" - dataset/neutral/")提取特征并訓練模型
def extract_and_train():if not os.path.exists("dataset"):print("數據集目錄不存在,請先運行 'python main.py init'")returnprint("開始提取特征...")try:features, labels, feature_names = extract_features_from_directory("dataset")if len(features) == 0:print("未找到有效的特征數據,請確保數據集中包含.wav文件")returnprint(f"共提取了 {len(features)} 個樣本的特征")# 訓練模型print("開始訓練模型...")model, report, cm, X_test, y_test, y_pred = train_emotion_model(features, labels)# 保存模型save_model(model)# 輸出分類報告print("\n分類報告:")for emotion in report.keys():if emotion != "accuracy" and emotion != "macro avg" and emotion != "weighted avg":precision = report[emotion]['precision']recall = report[emotion]['recall']f1 = report[emotion]['f1-score']support = report[emotion]['support']print(f"{emotion}:\t精確率: {precision:.2f}, 召回率: {recall:.2f}, F1: {f1:.2f}, 樣本數: {support}")print(f"\n整體準確率: {report['accuracy']:.2f}")# 可視化混淆矩陣classes = np.unique(labels)visualize_confusion_matrix(cm, classes)return modelexcept Exception as e:import tracebackprint(f"訓練過程中出錯: {str(e)}")traceback.print_exc()return None
預測單個文件情感
def predict_single_file(audio_file):if not os.path.exists("emotion_model.pkl"):print("模型文件不存在,請先訓練模型")returnmodel = load_model()prediction, probabilities = predict_emotion(model, audio_file)if prediction is not None:print(f"預測情感: {prediction}")# 獲取類別列表classes = model.classes_# 顯示各情感的概率print("\n各情感的概率:")for i, emotion in enumerate(classes):print(f"{emotion}: {probabilities[i]:.2f}")# 可視化音頻特征process_audio_features(audio_file)else:print("預測失敗")
顯示
def display_help():print("使用方法:")print(" python main.py init - 創建項目目錄結構")print(" python main.py train - 提取特征并訓練模型")print(" python main.py predict <audio_file> - 預測單個音頻文件的情感")print(" python main.py help - 顯示此幫助信息")
主邏輯
if __name__ == "__main__":if len(sys.argv) < 2:display_help()sys.exit(1)command = sys.argv[1].lower()if command == "init":create_project_structure()elif command == "train":extract_and_train()elif command == "predict" and len(sys.argv) >= 3:predict_single_file(sys.argv[2])elif command == "help":display_help()else:print("無效的命令")display_help()sys.exit(1)5.預測部分 predict.py
一般訓練要和預測(也就是使用)部分分離,這樣我們就不必每次都重新訓練
頭文件
import os
import sys
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
import joblib
import time可視化音頻特征
def visualize_audio(y, sr, emotion=None):plt.figure(figsize=(12, 8))# 波形plt.subplot(3, 1, 1)librosa.display.waveshow(y, sr=sr)plt.title(f'音頻波形 - 預測情感: {emotion}' if emotion else '音頻波形')# 梅爾頻譜mel_spec = librosa.feature.melspectrogram(y=y, sr=sr)mel_spec_db = librosa.power_to_db(mel_spec, ref=np.max)plt.subplot(3, 1, 2)librosa.display.specshow(mel_spec_db, sr=sr, x_axis='time', y_axis='mel')plt.colorbar(format='%+2.0f dB')plt.title('梅爾頻譜')# MFCCmfccs = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)plt.subplot(3, 1, 3)librosa.display.specshow(mfccs, sr=sr, x_axis='time')plt.colorbar()plt.title('MFCC')plt.tight_layout()plt.savefig('audio_analysis.png')plt.show()
主邏輯?
def main():# 檢查命令行參數if len(sys.argv) < 2:print("使用方法: python predict.py <音頻文件路徑>")returnaudio_file = sys.argv[1]# 檢查文件是否存在if not os.path.exists(audio_file):print(f"錯誤: 文件 {audio_file} 不存在")return# 檢查模型文件是否存在model_path = 'emotion_model.pkl'if not os.path.exists(model_path):print(f"錯誤: 模型文件 {model_path} 不存在,請先運行訓練腳本")return# 加載模型print("加載情感識別模型...")model = joblib.load(model_path)# 提取特征print(f"從 {audio_file} 提取特征...")features, feature_names = extract_features_from_file(audio_file) # 使用audio_emotion中的函數# 同時讀取音頻數據用于可視化y, sr = librosa.load(audio_file, sr=None)if features is None:print("特征提取失敗")return# 預測情感features = features.reshape(1, -1)prediction = model.predict(features)[0]probabilities = model.predict_proba(features)[0]print(f"\n預測結果: {prediction}")# 顯示各情感的概率print("\n各情感的概率:")for i, emotion in enumerate(model.classes_):print(f"{emotion}: {probabilities[i]:.2f}")# 可視化音頻及其特征print("\n生成音頻可視化分析...")visualize_audio(y, sr, prediction)print("可視化結果已保存為 audio_analysis.png")if __name__ == "__main__":main()應用
那么我們后面需要應用模型時只需要在終端執行
python predict.py <處理對象路徑>四.運行展示
下面我們從頭到尾執行
初始化目錄
python main.py init生成樣本
python generate_samples.py訓練模型
python main.py train查看結果并分析
open confusion_matrix.png可以看到模型準確度高達75%,在angry和sad方面尤其精準,說明我們后面需要優化的方面就集中在happy和neutral
應用模型
python predict.py <對象文件路徑>查看分析圖
open audio_analysis.png






)





![每日c/c++題 備戰藍橋杯(洛谷P1015 [NOIP 1999 普及組] 回文數)](http://pic.xiahunao.cn/每日c/c++題 備戰藍橋杯(洛谷P1015 [NOIP 1999 普及組] 回文數))

)
)


