概述
目標檢測領域取得了巨大進步,其中 YOLOv12、YOLOv11 和基于 Darknet 的 YOLOv7 在實時檢測方面表現出色。盡管這些模型在通用目標檢測數據集上表現卓越,但在 HRSC2016-MS(高分辨率艦船數據集) 上對 YOLOv12 進行微調時,卻面臨著獨特的挑戰。
本文提供了一個詳細的端到端流程,用于在 HRSC2016-MS 上微調 YOLOv12、YOLOv11 和基于 Darknet 的 YOLOv7。它涵蓋了數據集預處理(基本的洗牌和將數據集劃分為訓練集、測試集和驗證集)、訓練、評估以及對它們性能的對比分析。重點關注領域包括:
- 處理數據集偏差以提高小目標檢測能力。
- 洗牌數據集以確保適當的泛化能力。
- 在驗證集 / 測試集上對比 YOLOv12、YOLOv11 和基于 Darknet 的 YOLOv7。
- 可視化檢測結果以比較模型性能。
此外,本文強調了理解數據集結構和偏差的重要性。研究人員花費大量時間進行數據集準備和適當的訓練 - 驗證 - 測試劃分,以增強模型的泛化能力并避免誤導性結果。通過解決 HRSC2016-MS 中的這些挑戰,我們展示了適當的數據準備和結構化如何直接提高模型的準確性。
一、HRSC2016-MS 數據集
HRSC2016-MS 是一個海上目標檢測數據集,包含艦船的航拍圖像。該數據集僅有一個類別,即 艦船。它包含各種艦船大小、密度和方向,使其成為目標檢測模型的一個具有挑戰性的數據集。

1.1 為何引入 HRSC2016-MS?
在 HRSC2016-MS 之前,已經存在 HRSC2016 數據集,其中包含用于檢測任務的艦船圖像。然而,HRSC2016-MS 的作者引入了這個修改后的數據集,以解決原始數據集的幾個關鍵限制:
增強多尺度表示
- 原始 HRSC2016 數據集中的艦船尺度相對相似,未能充分表示 多尺度變化。
- HRSC2016-MS 引入了更廣泛的艦船尺寸,確保在實際應用中具有更好的泛化能力。
提高數據集多樣性
- 原始 HRSC2016 數據集缺乏 艦船雜亂程度和尺度過渡的足夠變化。
- HRSC2016-MS 引入了 更密集的艦船,提高了數據集在小目標檢測方面的實用性。
更具挑戰性的目標分布
- 原始數據集在每張圖像中的艦船方向和密度變化較少。
- HRSC2016-MS 旨在 增加數據集的復雜性,使其成為高級目標檢測模型的一個更好的基準。
1.2 原始數據集結構
首次下載時,數據集具有以下結構:
HRSC2016-MS/
├── AllImages/ # 包含所有圖像(未按訓練 / 驗證 / 測試劃分)
├── Annotations/ # 每張圖像的 VOC XML 注釋
└── ImageSets/├── train.txt # 訓練圖像文件名列表├── val.txt # 驗證圖像文件名列表├── test.txt # 測試圖像文件名列表└── trainval.txt # 開發者測試的訓練和驗證圖像組合列表
1.3 原始數據集的問題
非 YOLO 兼容的注釋
- 數據集使用 VOC 風格的 XML 注釋,需要轉換為 YOLO 格式。
非 YOLO 兼容的目錄結構
- 所有圖像都存儲在 AllImages/ 而不是按訓練集、驗證集和測試集劃分。
- 數據集包含 文本文件(train.txt、val.txt、test.txt、trainval.txt),其中僅包含 圖像文件名,使其 與 YOLO 和 DarkNet 不兼容。
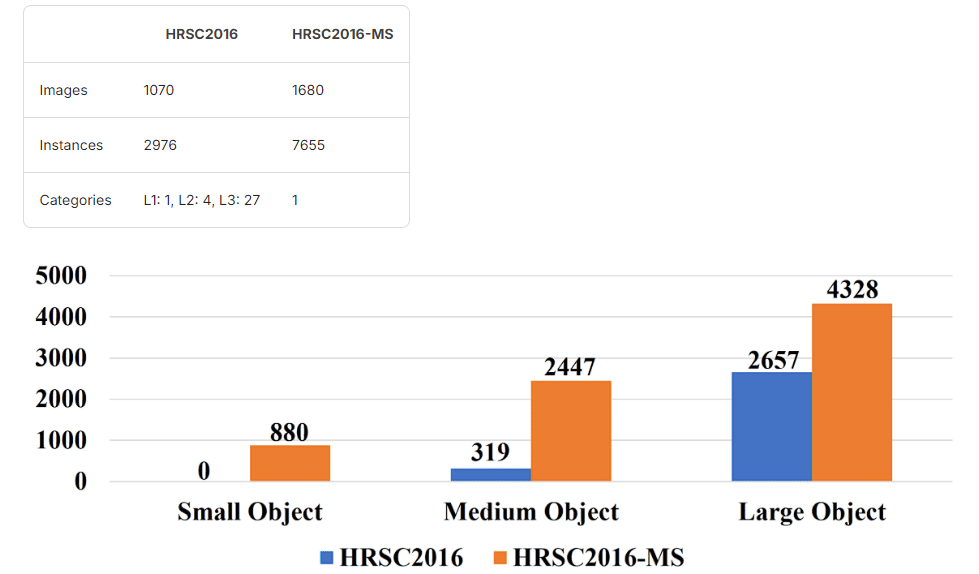
有偏的訓練 - 測試劃分
- 數據集總共包含 1680 張圖像,理想情況下,測試集應包含文件名為 1-1680 范圍內的圖像。然而,在分析原始 HRSC2016-MS 數據集中的標簽文件名后,我們發現 測試集包含文件名為大約 1-650 范圍內的連續圖像。這表明 圖像在訓練集、測試集和驗證集之間的分布不當,可能會導致潛在的偏差并影響模型性能。
- 測試集包含較小、密集的艦船,與訓練集和驗證集相比。
- 這導致了 泛化能力差,模型在 檢測小艦船 方面存在困難。
二、數據集轉換與預處理
為了解決原始數據集的問題,我們手動將數據集轉換并重新構建為 YOLO 和 DarkNet 兼容的格式。所有數據集轉換和預處理代碼都可以直接下載。
2.1 將注釋從 XML 轉換為 YOLO(.txt)格式
- 從 XML 文件中提取邊界框坐標(xmin、ymin、xmax、ymax),并將其轉換為 YOLO(.txt)格式:<class_id> <x_center> <y_center>
- 我們沒有使用旋轉邊界框注釋,只是為了使評估過程更簡單一些。
2.2 洗牌整個數據集以實現泛化
- 由于測試集主要包含小而密集的艦船,使用原始數據集進行訓練會導致泛化能力差。
- 我們 合并、洗牌并重新劃分 數據集,以確保以下幾點:
- 在訓練集、驗證集和測試集中平衡分布小艦船和大艦船。
- 防止對特定目標尺寸產生過擬合。
- 這里呈現的結果只是一個 基線。鑒于數據集劃分的固有隨機性,其他研究人員可能會觀察到 略有不同的結果;有些人可能會取得 更好的結果,而另一些人可能會得到 略差的結果。為了確保透明度和可重復性,我們還將提供我們在實驗中使用的 確切數據集劃分,它將以 zip 文件 的形式提供參考。
2.3 為 YOLO 重新構建數據集
經過處理后,數據集被構建并轉換為 YOLO 特定的格式,如下所示:
HRSC-YOLO/
├── train/
│ ├── images/ # 訓練圖像
│ └── labels/ # 訓練標簽,以 YOLO 格式
├── val/
│ ├── images/ # 驗證圖像
│ └── labels/ # 驗證標簽,以 YOLO 格式
└── test/├── images/ # 測試圖像└── labels/ # 測試標簽,以 YOLO 格式
2.4 為 DarkNet 重新構建數據集
DarkNet 需要不同的結構,其中 每個圖像及其對應的標簽文件存儲在一起。格式如下:
darknet_dataset/
├── train/
│ ├── image1.JPG
│ └── image1.txt
├── valid/
│ ├── image2.JPG
│ └── image2.txt
└── test/├── image3.JPG└── image3.txt
三、在 HRSC2016-MS 數據集上微調 YOLOv12
3.1 模型配置
- 使用 YOLOv12(Ultralytics 實現)。
- 設置 圖像大小為 640×640,以實現最佳性能。
3.2 訓練流程
- 設置 批量大小為 8,訓練周期數為 100。
- 使用 馬賽克增強,使模型能夠接觸到 不同尺度下的小目標。
- 自適應學習率調度 有助于防止過擬合。
def train_yolov12(epochs=100, batch_size=8):model = YOLO(yolov12_model_path)model.train(data=data_yaml, epochs=epochs, batch=batch_size, imgsz=640, device='cuda', workers=4, save=True, save_period=10)model.val()print(model)print("YOLOv12 訓練在 HRSC2016-MS 上完成。")
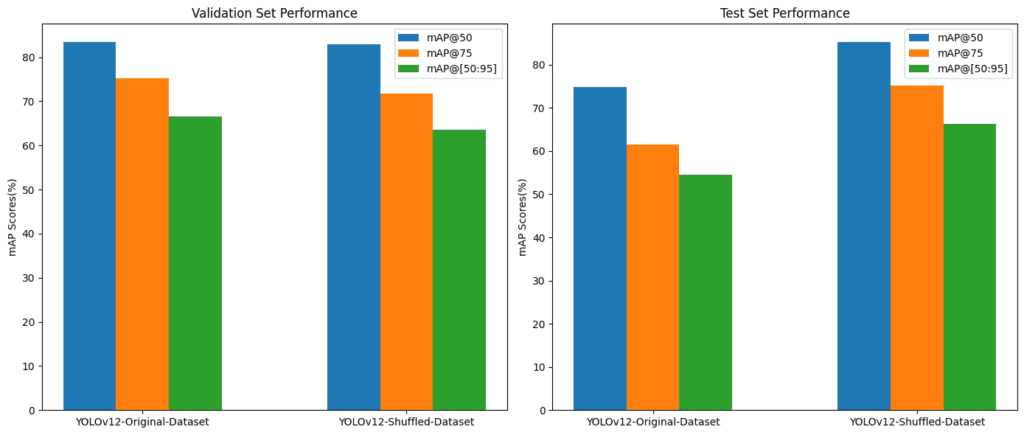
3.3 評估指標
- 跟蹤 mAP@50、mAP@75 和 mAP@[50:95]。
- 對比了在原始數據集和預處理數據集上訓練后的性能,觀察結果如下。
| 模型 - YOLOv12 | mAP@50 | mAP@75 | mAP@[50:95] |
|---|---|---|---|
| 在原始數據集上訓練 | 74.9% | 61.5% | 54.5% |
| 在洗牌后的數據集上訓練 | 85.2% | 75.1% | 66.3% |
四、在 HRSC2016-MS 數據集上微調 YOLOv11
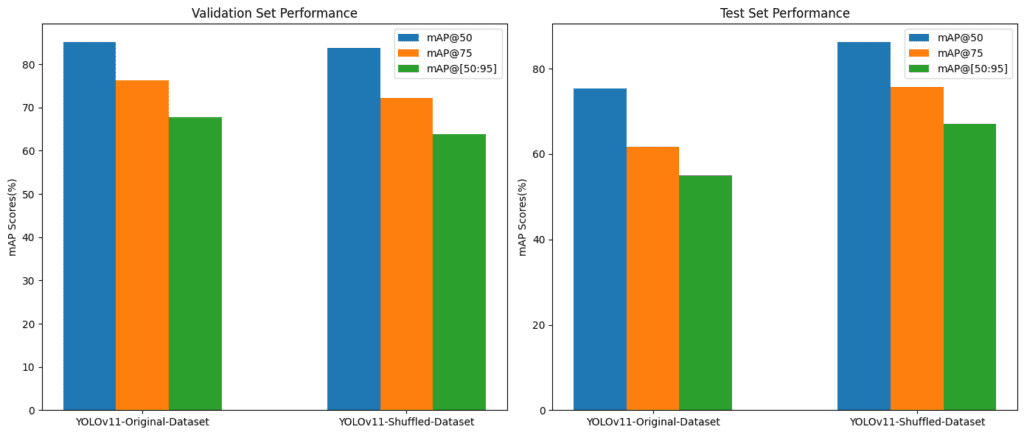
- 采用了與 YOLOv12 相同的訓練流程。
- 對比了 YOLOv11 在原始數據集和預處理數據集上的性能。
- 使用條形圖對比了 mAP 分數,觀察結果如下。
| 模型 - YOLOv11 | mAP@50 | mAP@75 | mAP@[50:95] |
|---|---|---|---|
| 在原始數據集上訓練 | 75.3% | 61.6% | 55.0% |
| 在洗牌后的數據集上訓練 | 86.2% | 75.8% | 67.0% |
五、在 HRSC2016-MS 上微調基于 Darknet 的 YOLOv7
DarkNet 是開發 YOLO(You Only Look Once)目標檢測模型家族的原始框架。與 Ultralytics 的 YOLO 模型實現不同,基于 Darknet 的 YOLOv7 需要特定的目錄結構、配置文件以及手動定義的數據集路徑。本節詳細介紹了如何在 HRSC2016-MS 數據集上設置、訓練和評估基于 Darknet 的 YOLOv7。
我們將提供一個 Jupyter 筆記本,可以在 VS Code 編輯器 中輕松執行。該筆記本將指導您完成 數據準備、預處理以及生成 DarkNet 所需的配置和文本文件,以啟動訓練過程。然而,需要注意的是,對于實際訓練部分,不建議在代碼編輯器中啟動 DarkNet 訓練。這是由于訓練過程中產生的 大量輸出 可能會導致 代碼編輯器窗口崩潰。
因此,僅對于訓練和評估部分,建議在終端中執行訓練和評估命令,而不是在任何代碼編輯器中執行它們。筆記本中已提供了適當的操作說明。在實際應用中,建議仔細遵循這些說明。
5.1 設置 DarkNet
-
克隆 DarkNet 倉庫
克隆 DarkNet 倉庫到本地目錄。git clone https://github.com/AlexeyAB/darknet.git -
編譯 DarkNet
使用 CUDA 和 OpenCV 支持編譯 DarkNet。可以參考我們關于 YOLOv4 和 Darknet 用于坑洼檢測 的文章中的逐步過程,以構建 Darknet。文章鏈接如下:構建 Darknet 參考文章
5.2 下載基于 YOLOv7 的 DarkNet 預訓練權重
為了在 HRSC2016-MS 上微調基于 Darknet 的 YOLOv7,我們使用預訓練權重作為起點。使用以下命令下載 YOLOv7 DarkNet 權重:
cd /path/to/darknet
wget https://github.com/AlexeyAB/darknet/releases/download/yolov4/yolov7x.conv.147
wget https://github.com/AlexeyAB/darknet/releases/download/yolov4/yolov7x.weights
將權重保存在 darknet/ 目錄中。實際上,從現在開始,所有命令都必須在克隆的 Darknet 目錄中的 darknet 子目錄中執行。
5.3 Darknet 所需的文本文件
DarkNet 需要 明確的文本文件 指定圖像的路徑。
- train.txt → 包含用于訓練的圖像的絕對路徑。
- valid.txt → 包含用于驗證的圖像的絕對路徑。
- test.txt → 包含用于評估的圖像的絕對路徑。
為了生成這些文本文件,我們將編寫一個 Python 腳本,然后執行該腳本。腳本如下:
# prepare_darknet_image_txt_paths.py
import os# 設置數據集路徑
DATA_ROOT_TRAIN = '/path/to/train/directory'
DATA_ROOT_VALID = '/path/to/valid/directory'
DATA_ROOT_TEST = '/path/to/test/directory'# 獲取圖像文件名
train_image_files = [f for f in os.listdir(DATA_ROOT_TRAIN) if f.endswith('.jpg') or f.endswith('.png')]
valid_image_files = [f for f in os.listdir(DATA_ROOT_VALID) if f.endswith('.jpg') or f.endswith('.png')]
test_image_files = [f for f in os.listdir(DATA_ROOT_TEST) if f.endswith('.jpg') or f.endswith('.png')]# 寫入 train.txt
with open('train.txt', 'w') as f:for file_name in train_image_files:f.write(os.path.join(DATA_ROOT_TRAIN, file_name) + '\n')# 寫入 valid.txt
with open('valid.txt', 'w') as f:for file_name in valid_image_files:f.write(os.path.join(DATA_ROOT_VALID, file_name) + '\n')# 寫入 test.txt
with open('test.txt', 'w') as f:for file_name in test_image_files:f.write(os.path.join(DATA_ROOT_TEST, file_name) + '\n')
在 darknet 目錄中運行以下命令以執行腳本:
python prepare_darknet_image_txt_paths.py
5.4 DarkNet 配置文件
DarkNet 還需要 三個自定義配置文件:
- obj.names(ship.names)→ 類別名稱文件
- obj.data(hrsc2016-ms-yolov7.data)→ 訓練數據文件
- 自定義.cfg文件(yolov7-darknet-hrsc2016-ms.cfg)→ 用于定義特定于該數據集的基于 YOLOv7 的 Darknet 架構
5.4.1 準備自定義基于 Darknet 的 YOLOv7 類別名稱文件
echo "ship" > build/darknet/x64/data/ship.names
5.4.2 準備自定義基于 Darknet 的 YOLOv7 訓練數據文件
在開始訓練過程之前,確保已經創建了一個名為 backup_2000 的目錄。
echo "classes = 1" > build/darknet/x64/data/hrsc2016-ms-yolov7.data
echo "train = train.txt" >> build/darknet/x64/data/hrsc2016-ms-yolov7.data
echo "valid = valid.txt" >> build/darknet/x64/data/hrsc2016-ms-yolov7.data
echo "names = build/darknet/x64/data/ship.names" >> build/darknet/x64/data/hrsc2016-ms-yolov7.data
echo "backup = backup_2000" >> build/darknet/x64/data/hrsc2016-ms-yolov7.data
5.4.3 準備自定義基于 Darknet 的 YOLOv7 測試數據文件
在開始推理和測試過程之前,建議創建一個名為 backup_test_2000 的目錄。
echo "classes = 1" > build/darknet/x64/data/ship_test.data
echo "train = train.txt" >> build/darknet/x64/data/ship_test.data
echo "valid = test.txt" >> build/darknet/x64/data/ship_test.data
echo "names = build/darknet/x64/data/ship.names" >> build/darknet/x64/data/ship_test.data
echo "backup = backup_test_2000" >> build/darknet/x64/data/ship_test.data
5.4.4 準備自定義基于 Darknet 的 YOLOv7 配置文件
我們將創建一個自定義配置文件,其中大部分內容與默認的 yolov7x.cfg 相同(因為我們正在比較大型 YOLO 模型),但需要根據我們的數據集修改一些參數。
# yolov7-darknet-hrsc2016-ms.cfg
[net]
# Testing
# batch=64
# subdivisions=64
# Training
batch=64
subdivisions=64
width=640
height=640
channels=3
momentum=0.9
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.00261
burn_in=1000
max_batches = 2000
policy=steps
steps=1600,1800
scales=.1,.1# 其他層的配置保持不變,僅修改以下部分
[convolutional]
size=1
stride=1
pad=1
filters=18
activation=logistic[yolo]
mask = 6,7,8
anchors = 12,16, 19,36, 40,28, 36,75, 76,55, 72,146, 142,110, 192,243, 459,401
classes=1
5.5 訓練基于 Darknet 的 YOLOv7
提醒:僅在終端中運行以下命令。
以下終端命令啟動基于 Darknet 的 YOLOv7 模型的訓練過程,并在訓練結束后計算 mAP@50 分數。
./darknet detector train build/darknet/x64/data/hrsc2016-ms-yolov7.data cfg/yolov7-darknet-hrsc2016-ms.cfg yolov7x.conv.147 -map -dont_show
5.6 評估指標:基于 YOLOv7 的 Darknet
我們將使用以下終端命令在驗證集上獲得 mAP 分數,IoU 閾值為 0.75。我們只需在命令中更改 iou_thresh 值,即可根據需要設置 IoU 閾值。
./darknet detector map build/darknet/x64/data/ship_test.data cfg/yolov7-darknet-hrsc2016-ms.cfg backup_2000/yolov7-darknet-hrsc2016-ms_final.weights -iou_thresh 0.75
如果需要在測試集上計算 mAP 分數,我們只需修改 ship_test.data 配置文件。只需將 “valid” 參數值從 “valid.txt” 更改為 “test.txt”。
使用以下命令生成訓練模型對提供的圖像的檢測結果。注意在命令中指定包含要檢測圖像的目錄路徑。輸出將包含模型為傳遞的圖像預測的邊界框的位置。
./darknet detector test build/darknet/x64/data/hrsc2016-ms-yolov7.data cfg/yolov7-darknet-hrsc2016-ms.cfg backup_2000/yolov7-darknet-hrsc2016-ms_final.weights -dont_show -ext_output < test.txt > results_darknet_test.txt
5.7 可視化檢測結果
為了可視化檢測結果,我們需要修改 Darknet 內部的 Python 腳本 darknet_images.py。打開該文件并添加以下兩行代碼,以便將標注后的圖像保存到目錄中。
output_image_path = os.path.join("yolov7_darknet_test_results", image_name.split(os.path.sep)[-1])
cv2.imwrite(output_image_path, image)
修改后的 darknet_images.py 文件如下:
# 修改后的 darknet_images.py
import cv2
import os# 添加這兩行代碼
output_image_path = os.path.join("yolov7_darknet_test_results", image_name.split(os.path.sep)[-1])
cv2.imwrite(output_image_path, image)
運行以下命令以執行腳本并保存檢測結果:
python darknet_images.py --data_file build/darknet/x64/data/ship_test.data --input /path/to/test/images --config_file cfg/yolov7-darknet-hrsc2016-ms.cfg --weights backup_2000/yolov7-darknet-hrsc2016-ms_final.weights --thresh 0.25 --ext_output --save_labels --dont_show
現在,我們已經完成了所有實驗。是時候比較微調模型的性能了。
六、比較 YOLOv12、YOLOv11 和基于 Darknet 的 YOLOv7 的 mAP 分數
預處理后的數據集上的 mAP 分數明顯高于原始數據集,如本文前面所示。基于評估指標 mAP@50、mAP@75 和 mAP@[50:95],在預處理后的數據集上的最終比較如下。
在驗證集上
| 模型 | mAP@50 | mAP@75 | mAP@[50:95] |
|---|---|---|---|
| YOLOv7 (DarkNet) | 85.6% | 71.9% | 61.56% |
| YOLOv11 | 83.7% | 72.2% | 63.8% |
| YOLOv12 | 83% | 71.8% | 63.5% |
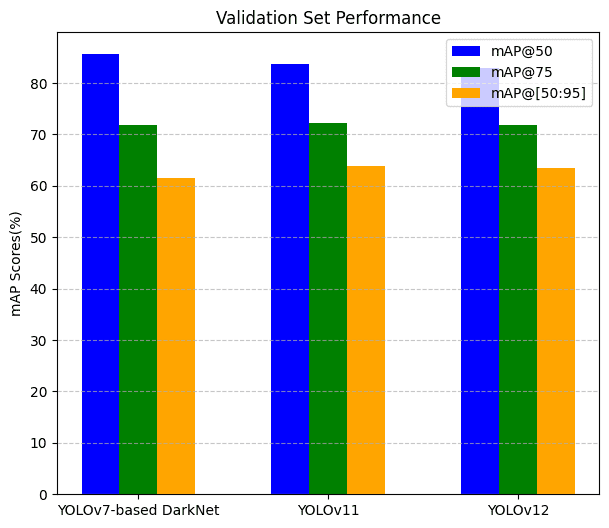
在測試集上
| 模型 | mAP@50 | mAP@75 | mAP@[50:95] |
|---|---|---|---|
| YOLOv7 (DarkNet) | 88.2% | 75.6% | 65.5% |
| YOLOv11 | 86.2% | 75.8% | 67.0% |
| YOLOv12 | 85.2% | 75.1% | 66.3% |
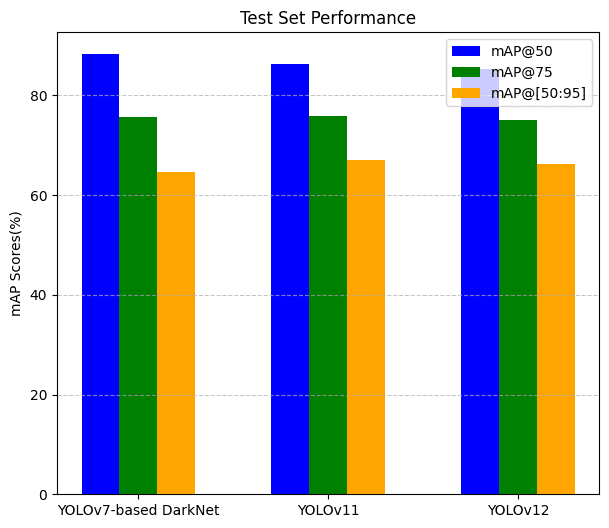
七、訓練和損失圖的可視化
YOLOv12
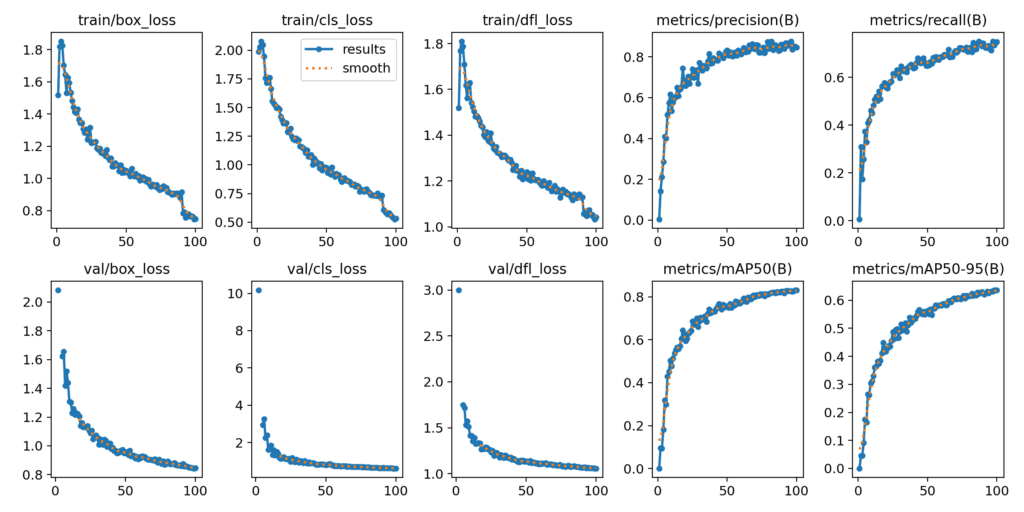
YOLOv11
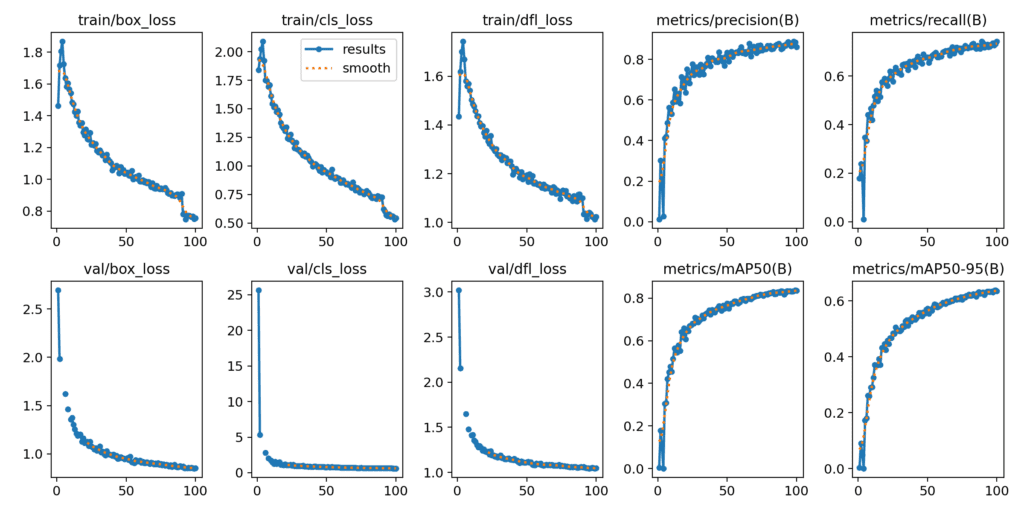
基于 Darknet 的 YOLOv7
八、在一些圖像上的推理結果

所有三個模型在給定的真實值圖像上表現出類似的性能。Darknet 在識別被其他模型遺漏或檢測不準確的小目標方面表現出更高的準確性。

所有評估的模型在檢測密集和小目標方面表現出色。然而,YOLOv11 出現了重疊檢測,這可能表明存在冗余或檢測精度較低。總體而言,這些模型在檢測任務中表現出不同程度的重疊和精度。

YOLOv12 是唯一能夠在真實值圖像中檢測到標記目標的模型。總體而言,所有模型在目標檢測方面表現出類似的性能。然而,YOLOv11 繼續產生重疊檢測,這表明可能存在冗余或檢測精度降低。

該圖像是一個理想的測試案例,特別是在密集和小目標場景中評估目標檢測模型。初步比較可能表明 YOLOv12 基于檢測數量優于其他模型。然而,詳細分析揭示了許多 YOLOv12 檢測是重疊的、冗余的或誤檢。基于 Darknet 的 YOLOv7 盡管檢測到的目標較少,但顯示出更高的準確性,誤檢和重疊最少。一個健全的評估必須考慮精度、召回率和誤檢率,而不僅僅是依賴于檢測數量。
關鍵要點
- mAP@50 分數表明基于 Darknet 的 YOLOv7 在基本目標定位(檢測艦船)方面表現出色,但在更嚴格的定位約束下可能表現不佳。
- YOLOv11 在高 IoU 閾值(mAP@75 和 mAP@[50:95])下表現優于其他模型。這意味著 YOLOv11 在目標定位和更精確的邊界框方面優于其他模型。
- YOLOv12 在 mAP 分數評估指標中從未超過其他模型,但它在實際推理性能方面表現出色,這可能是由于它在密集環境中對艦船特征提取能力更強。
- HRSC2016-MS 數據集從預處理(主要是洗牌)中受益。洗牌和重新構建數據集提高了泛化能力,使所有模型都能更有效地檢測到小艦船。
- 模型性能取決于數據集。盡管 YOLOv12 是最新的模型,但它在任何 mAP 分數評估指標中都沒有占據主導地位。基于 Darknet 的 YOLOv7 在 mAP@50 方面表現出色,表明舊架構在特定數據集中仍然具有競爭力。
結論
本研究對在 HRSC2016-MS 數據集上微調 YOLOv12、YOLOv11 和基于 Darknet 的 YOLOv7 進行了深入分析,重點關注提高航拍艦船圖像中小目標的檢測能力。原始數據集的洗牌和重新構建在提高模型性能方面發揮了關鍵作用,因為初始的訓練 - 測試劃分存在偏差,影響了泛化能力。
YOLOv11 在更嚴格的 IoU 閾值(mAP@75 和 mAP@[50:95])下表現優于所有模型,使其成為精確邊界框預測的最佳選擇。盡管 YOLOv12 在 mAP 分數評估指標中沒有占據主導地位,但它在實際推理性能方面表現出色,表明定性檢測有效性超出了數值 mAP 值的范圍。
原文地址:https://learnopencv.com/fine-tuning-yolov12/#circle=on








)





)


)

