目標檢測系列文章
第一章 R-CNN
目錄
- 目標檢測系列文章
- 📄 論文標題
- 🧠 論文邏輯梳理
- 1. 引言部分梳理 (動機與思想)
- 📝 三句話總結
- 🔍 方法邏輯梳理
- 🚀 關鍵創新點
- 🔗 方法流程圖
- 補充
- 邊界框回歸 (BBR)
- 1. BBR 的目標與核心思想
- 2. BBR 實現細節
- 輸入 (Input)
- 目標變換 (Target Transformation)
- 模型 (Model)
- 訓練 (Training)
- 推理/應用 (Inference/Application)
- 3. 關鍵疑問解答
- Q1: 為什么預測“變換” ( t ? t_* t??) 而不是直接預測坐標 ( G x , G y , G w , G h G_x, G_y, G_w, G_h Gx?,Gy?,Gw?,Gh?)?
- Q2: 邊界框回歸器權重 w ? \mathbf{w}_* w?? 是什么以及如何工作?
- Q3: 為什么還要單獨訓練一個SVM用作分類器呢?直接把CNN網絡微調最后一層分類成21類(1類背景)作為分類器不更直接么
- 一些常見技術:
- 難例挖掘 (Hard Negative Mining):
- 非極大值抑制 Non-Maximum Suppression:
📄 論文標題
R-CNN: Rich feature hierarchies for accurate object detection and semantic segmentation (CVPR 2014)
作者:Ross Girshick ;Jeff Donahue;Trevor Darrell;Jitendra Malik
團隊:UC Berkeley
🧠 論文邏輯梳理
1. 引言部分梳理 (動機與思想)
| Aspect | Description (Motivation / Core Idea) |
|---|---|
| 問題背景 (Problem) | 2012 年之前,基于傳統手工特征(如 SIFT, HOG)結合機器學習模型(如 SVM, DPM)的目標檢測方法性能趨于飽和,遇到了瓶頸。 |
| 機遇 (Opportunity) | 與此同時,深度卷積神經網絡 (CNN) 在大規模圖像分類任務(如 ImageNet LSVRC)上取得了突破性進展,展現了強大的特征學習和表達能力。 |
| 挑戰 (Challenge) | 如何將 CNN 強大的分類能力有效地應用于需要精確定位的目標檢測任務?CNN 通常處理固定大小的輸入圖像,而檢測需要在圖像不同位置識別不同大小的物體。 |
| 核心思想 (Core Idea) | “Regions with CNN features” (R-CNN):將目標檢測任務分解為兩個階段:首先使用某種機制(如 Selective Search)生成與類別無關的候選區域 (Region Proposals),然后對每個區域獨立地使用 CNN 提取特征并進行分類和位置修正。 |
| 核心假設 (Hypothesis) | 應用深度 CNN 從候選區域中提取的豐富、有層次的特征,將顯著提升目標檢測的準確率,遠超傳統方法。 |
📝 三句話總結
| 方面 | 內容 |
|---|---|
| ?發現的老問題 |
|
| 💡提出的新方法 (R-CNN) |
|
| ?新方法的局限性 |
|
🔍 方法邏輯梳理
R-CNN 本身不是一個單一的端到端模型,而是一個處理流水線 (Pipeline)。
-
模型輸入:
- 一張
RGB圖像。
- 一張
-
處理流程:
- 候選區域生成 (Region Proposal - 外部模塊):
- 輸入: 原始圖像。
- 處理: 運行
Selective Search算法。 - 輸出: 約 2000 個候選區域的坐標 [ P 1 , P 2 , . . . , P 2 k ] [P_1, P_2, ..., P_{2k}] [P1?,P2?,...,P2k?]。
- 特征提取 (CNN Feature Extractor):
- 輸入: 圖像和所有候選區域 P i P_i Pi?。
- 處理 (Encoder 角色):
- 對每個 P i P_i Pi?,從原圖中裁剪出對應區域的圖像塊。
- 將圖像塊強制
變形 (warp)到 CNN 輸入尺寸 (e.g., 227x227)。 - 將變形后的圖像塊送入微調后的
AlexNet進行前向傳播。 - 提取特定層的激活值作為特征(如
pool5層特征 ? p o o l 5 ( P i ) \phi_{pool5}(P_i) ?pool5?(Pi?) 或fc7層 4096 維向量 ? f c 7 ( P i ) \phi_{fc7}(P_i) ?fc7?(Pi?) )。
- 輸出: 每個候選區域 P i P_i Pi? 對應的高維特征向量 ? ( P i ) \phi(P_i) ?(Pi?)。
- 分類 (Classifier - SVMs):
- 輸入: 特征向量 ? f c 7 ( P i ) \phi_{fc7}(P_i) ?fc7?(Pi?)。
- 處理: 將特征向量輸入到 N + 1 N+1 N+1 個(N 個物體類別 +
1 個背景類別)獨立訓練好的線性SVM中。 - 輸出: P i P_i Pi? 屬于每個類別的置信度得分。
- 定位精修 (Localizer - BBRs):
- 輸入:
pool5特征向量 ? p o o l 5 ( P i ) \phi_{pool5}(P_i) ?pool5?(Pi?)(對于被SVM判為非背景的 P i P_i Pi?)。 - 處理: 根據 P i P_i Pi? 被判定的類別 c c c,使用該類別專屬的
BBR線性模型,基于 ? p o o l 5 ( P i ) \phi_{pool5}(P_i) ?pool5?(Pi?) 預測一個 ( d x , d y , d w , d h ) (d_x, d_y, d_w, d_h) (dx?,dy?,dw?,dh?) 變換。 - 輸出: 經過變換修正后的更精確的邊界框 G ^ i \hat{G}_i G^i?。
- 輸入:
- 后處理 (Post-processing - NMS):
- 輸入: 所有帶有類別、分數和(可能修正后)邊界框的候選區域。
- 處理: 對每個類別,應用非極大值抑制 (
NMS) 算法,去除重疊度高且分數較低的冗余檢測框。 - 輸出: 最終的檢測結果列表,每個結果包含類別、置信度和最終邊界框。
- 候選區域生成 (Region Proposal - 外部模塊):
-
模型輸出:
- 圖像中檢測到的物體列表,每個物體包含:類別標簽、置信度分數、精修后的邊界框坐標。
-
訓練過程 (Multi-stage):
- CNN 微調 (Fine-tuning):
- 使用
ImageNet預訓練的AlexNet作為起點。 - 用目標檢測數據集中的
warped region proposals進行微調。將與真實物體IoU> 0.5 的 proposal 視為對應類別的正樣本,其余視為負樣本(背景)。最后一層替換為 N+1 路 Softmax。
- 使用
- SVM 訓練:
- 使用微調后的 CNN 提取所有 proposals 的
fc7特征并存盤。 - 對每個類別,訓練一個二元線性
SVM。使用真實邊界框作為正樣本,與所有真實物體IoU< 0.3的 proposals 作為負樣本。使用難例挖掘 (Hard Negative Mining)。
- 使用微調后的 CNN 提取所有 proposals 的
- BBR 訓練:
- 對每個類別,篩選出與該類某個真實邊界框
IoU較高的 proposals P P P。 - 提取這些 P P P 的
pool5特征 ? p o o l 5 ( P ) \phi_{pool5}(P) ?pool5?(P)。 - 訓練線性回歸模型,預測從 P P P 到其對應真實邊界框 G G G 的變換參數 ( t x , t y , t w , t h ) (t_x, t_y, t_w, t_h) (tx?,ty?,tw?,th?)。
- 對每個類別,篩選出與該類某個真實邊界框
- CNN 微調 (Fine-tuning):
🚀 關鍵創新點
-
創新點 1: CNN 特征用于檢測 (CNN Features for Detection)
- 為什么要這樣做? 傳統手工特征表達能力有限,無法很好地應對物體的多樣性。CNN 被證明能學習到更魯棒、更具判別力的層次化特征。
- 不用它會怎樣? 檢測精度會停留在 DPM 等方法的水平,難以大幅提升,無法充分利用深度學習帶來的紅利。
-
創新點 2: 區域提議 + CNN 結合 (Region Proposals + CNN)
- 為什么要這樣做? CNN 需要固定尺寸輸入,而檢測需要在圖像各處定位物體。區域提議提供了物體可能位置的“候選”,將檢測問題轉化為對大量候選區域的“分類”問題,使得 CNN 可以被應用。
- 不用它會怎樣? 如果直接在整圖上用 CNN 滑窗,計算量巨大且難以處理不同尺寸和長寬比的物體;如果直接讓 CNN 輸出坐標,在當時的技術條件下難以實現精確且魯棒的定位。這種結合是當時應用 CNN 進行檢測的關鍵橋梁。
-
創新點 3: 遷移學習 (Transfer Learning: Pre-training + Fine-tuning)
- 為什么要這樣做? 目標檢測數據集通常比大型分類數據集(如
ImageNet)小得多。直接在小數據集上訓練深度 CNN 容易過擬合。預訓練讓模型學習通用的視覺模式,微調則使其適應特定檢測任務。 - 不用它會怎樣? 在有限的檢測數據上從頭訓練深度 CNN 效果會差很多,難以收斂到好的性能,無法有效利用
ImageNet等大規模數據集蘊含的知識。
- 為什么要這樣做? 目標檢測數據集通常比大型分類數據集(如
-
創新點 4: 邊界框回歸 (Bounding Box Regression)
- 為什么要這樣做?
Selective Search等區域提議方法產生的候選框定位通常不夠精確。 - 不用它會怎樣? 檢測框的定位精度會受限于區域提議的質量,即使分類正確,框的位置也可能不夠準,導致在需要高
IoU匹配的應用或評估指標下性能下降。BBR進一步提升了定位精度。
- 為什么要這樣做?
總而言之,R-CNN 通過巧妙地結合區域提議和強大的 CNN 特征,并利用遷移學習,成功地將深度學習引入目標檢測領域,極大地提升了檢測精度,開啟了后續一系列基于深度學習的檢測算法(Fast R-CNN, Faster R-CNN 等)的發展。
🔗 方法流程圖
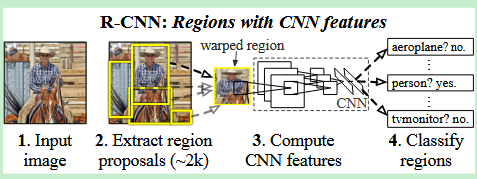
補充
邊界框回歸 (BBR)
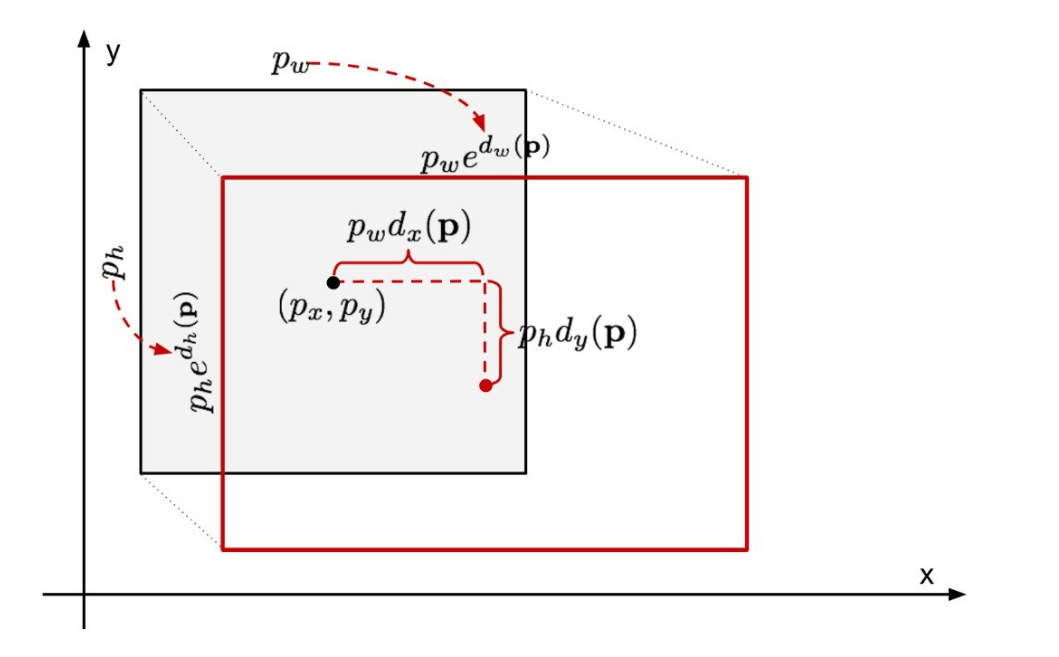
1. BBR 的目標與核心思想
- 目標: 解決由
Selective Search等方法產生的候選區域框 P P P (Proposal) 定位不夠精確的問題。【相當于有了先驗候選區域P,進一步利用先驗】 - 核心思想: 學習一個映射關系,根據從候選區域 P P P 提取的 CNN 特征,預測出將 P P P 調整到更接近真實邊界框 G G G (Ground Truth) 所需的變換參數,從而得到一個更精確的預測框 G ^ \hat{G} G^
2. BBR 實現細節
輸入 (Input)
- 候選區域框 P = ( P x , P y , P w , P h ) P = (P_x, P_y, P_w, P_h) P=(Px?,Py?,Pw?,Ph?),其中 ( P x , P y ) (P_x, P_y) (Px?,Py?) 是中心坐標, P w , P h P_w, P_h Pw?,Ph? 是寬高。
- 從該區域提取的 CNN 特征向量,R-CNN 中特指
pool5層特征 ? 5 ( P ) \phi_5(P) ?5?(P)。
目標變換 (Target Transformation)
BBR 不直接預測 G G G 的坐標,而是預測從 P P P 到 G G G 的相對變換量 t ? t_* t?? ( ? * ? 代表 x , y , w , h x, y, w, h x,y,w,h):
- t x = ( G x ? P x ) / P w t_x = (G_x - P_x) / P_w tx?=(Gx??Px?)/Pw? (中心 x 平移量,寬度歸一化)
- t y = ( G y ? P y ) / P h t_y = (G_y - P_y) / P_h ty?=(Gy??Py?)/Ph? (中心 y 平移量,高度歸一化)
- t w = log ? ( G w / P w ) t_w = \log(G_w / P_w) tw?=log(Gw?/Pw?) (寬度對數縮放)
- t h = log ? ( G h / P h ) t_h = \log(G_h / P_h) th?=log(Gh?/Ph?) (高度對數縮放)
這些 t ? t_* t?? 是模型訓練時的真實標簽。
模型 (Model)
- 對每個物體類別訓練一組獨立的線性回歸模型。
- 模型以
pool5特征 ? 5 ( P ) \phi_5(P) ?5?(P) 為輸入,預測變換參數 d ? ( P ) d_*(P) d??(P):
d ? ( P ) = w ? T ? 5 ( P ) d_*(P) = \mathbf{w}_*^T \phi_5(P) d??(P)=w?T??5?(P)
其中 w ? \mathbf{w}_* w?? 是對應類別、對應變換維度 ( ? ) (*) (?) 的學習到的權重向量。
訓練 (Training)
- 數據選擇: 只選用與某個真實框 G G G 重疊度高 (e.g., I o U ≥ 0.6 IoU \ge 0.6 IoU≥0.6) 的候選框 P P P 進行訓練。
- 標簽計算: 對每個訓練樣本 ( P i , G i ) (P^i, G^i) (Pi,Gi),計算真實的變換目標 t ? i t_*^i t?i?。
- 模型學習: 使用帶 L 2 L_2 L2? 正則化的最小二乘法 (嶺回歸) 尋找最優權重 w ? \mathbf{w}_* w??,最小化預測誤差:
w ? = arg ? min ? w ^ ? ∑ i = 1 N ( t ? i ? w ^ ? T ? 5 ( P i ) ) 2 + λ ∥ w ^ ? ∥ 2 \mathbf{w}_* = \arg\min_{\hat{\mathbf{w}}_*} \sum_{i=1}^N (t_*^i - \hat{\mathbf{w}}_*^T \phi_5(P^i))^2 + \lambda \|\hat{\mathbf{w}}_*\|^2 w??=argw^??min?i=1∑N?(t?i??w^?T??5?(Pi))2+λ∥w^??∥2
推理/應用 (Inference/Application)
- 對于一個通過 SVM 分類器判定為某類別 c c c 的候選框 P P P,提取其 ? 5 ( P ) \phi_5(P) ?5?(P) 特征。
- 使用該類別 c c c 對應的已訓練好的權重 w ? c \mathbf{w}_*^c w?c? 預測變換參數 d ? ( P ) d_*(P) d??(P):
d x ( P ) = ( w x c ) T ? 5 ( P ) d_x(P) = (\mathbf{w}_x^c)^T \phi_5(P) dx?(P)=(wxc?)T?5?(P), d y ( P ) = ( w y c ) T ? 5 ( P ) d_y(P) = (\mathbf{w}_y^c)^T \phi_5(P) dy?(P)=(wyc?)T?5?(P), … - 將預測的變換 d ? ( P ) d_*(P) d??(P) 應用于原始框 P P P,得到修正后的預測框 G ^ = ( G ^ x , G ^ y , G ^ w , G ^ h ) \hat{G} = (\hat{G}_x, \hat{G}_y, \hat{G}_w, \hat{G}_h) G^=(G^x?,G^y?,G^w?,G^h?):
- G ^ x = P w d x ( P ) + P x \hat{G}_x = P_w d_x(P) + P_x G^x?=Pw?dx?(P)+Px?
- G ^ y = P h d y ( P ) + P y \hat{G}_y = P_h d_y(P) + P_y G^y?=Ph?dy?(P)+Py?
- G ^ w = P w exp ? ( d w ( P ) ) \hat{G}_w = P_w \exp(d_w(P)) G^w?=Pw?exp(dw?(P))
- G ^ h = P h exp ? ( d h ( P ) ) \hat{G}_h = P_h \exp(d_h(P)) G^h?=Ph?exp(dh?(P))
3. 關鍵疑問解答
Q1: 為什么預測“變換” ( t ? t_* t??) 而不是直接預測坐標 ( G x , G y , G w , G h G_x, G_y, G_w, G_h Gx?,Gy?,Gw?,Gh?)?
- 簡化學習任務: 預測相對的、歸一化的“微調量”比預測絕對坐標更容易學習,尤其是對于線性模型。模型只需關注如何根據特征修正當前的 P P P。
- 尺度不變性: 變換 t ? t_* t?? 的定義(歸一化平移、對數縮放)使得
學習目標對物體的大小和位置不敏感,模型更魯棒。例如,無論 P P P 大小如何,只要物體中心在 P P P 中心右側 10% 寬度處, t x t_x tx? 就大約是 0.1。 - 避免困難的絕對映射: 直接預測絕對坐標需要模型處理非常大的輸出范圍,對輸入特征的微小變化可能導致輸出劇烈變化,學習不穩定。預測變換將問題約束在一個更合理、更易于學習的空間。
- 利用 P 的信息: 預測變換顯式地
利用了候選框 $P$ 作為“起點”或“參考點”。【先驗】
再提一點,預測“變換” ($t_*$) 是根據損失函數來定義的:
w ? = arg ? min ? w ^ ? ∑ i = 1 N ( t ? i ? w ^ ? T ? 5 ( P i ) ) 2 + λ ∥ w ^ ? ∥ 2 \mathbf{w}_* = \arg\min_{\hat{\mathbf{w}}_*} \sum_{i=1}^N (t_*^i - \hat{\mathbf{w}}_*^T \phi_5(P^i))^2 + \lambda \|\hat{\mathbf{w}}_*\|^2 w??=argw^??min?i=1∑N?(t?i??w^?T??5?(Pi))2+λ∥w^??∥2
Q2: 邊界框回歸器權重 w ? \mathbf{w}_* w?? 是什么以及如何工作?
- 來源: 權重向量 w ? \mathbf{w}_* w?? 不是預設的,而是通過監督學習訓練得到的。訓練過程通過最小化預測變換 d ? d_* d?? 與真實目標變換 t ? t_* t?? 之間的誤差(如上述嶺回歸損失函數),找到最優的 w ? \mathbf{w}_* w?? 數值。
- 本質: w ? \mathbf{w}_* w?? 是線性回歸模型的核心參數。對于特定類別、特定變換維度(如“貓”類別的 x 變換),就有一組對應的權重 w x c a t \mathbf{w}_x^{cat} wxcat?。
- 作用機制: 通過點積運算 ( d ? ( P ) = w ? T ? 5 ( P ) d_*(P) = \mathbf{w}_*^T \phi_5(P) d??(P)=w?T??5?(P)) 實現。這個運算本質上是一個加權求和:
d ? ( P ) = ∑ j = 1 K w j f j d_*(P) = \sum_{j=1}^K w_j f_j d??(P)=j=1∑K?wj?fj?
其中 f j f_j fj? 是 ? 5 ( P ) \phi_5(P) ?5?(P) 特征向量的第 j j j 維, w j w_j wj? 是 w ? \mathbf{w}_* w?? 向量的第 j j j 個權重。 - 意義: 每個權重 w j w_j wj? 代表了第 j j j 個 CNN 特征 f j f_j fj? 對于預測該特定變換 d ? d_* d?? 的重要性和影響方向。訓練好的 w ? \mathbf{w}_* w?? 編碼了從數據中學到的知識:即哪些視覺特征模式(體現在 ? 5 ( P ) \phi_5(P) ?5?(P) 中)指示了需要對邊界框進行何種幾何調整。它將高維的特征向量“翻譯”成一個代表調整量的標量值。
Q3: 為什么還要單獨訓練一個SVM用作分類器呢?直接把CNN網絡微調最后一層分類成21類(1類背景)作為分類器不更直接么
-
實證性能提升: R-CNN 論文的實驗結果表明,在提取了 CNN 特征(特別是 fc7 特征)之后,使用 線性 SVM 進行分類,其 mAP (mean Average Precision) 結果顯著優于直接使用微調后的 CNN 的 Softmax 輸出。
-
訓練策略和樣本定義的差異:
-
CNN微調通常相對寬松。例如,與真實邊界框 IoU 大于 0.5 的候選區域就被視為對應類別的正樣本,用于微調 Softmax。負樣本(背景)的選擇也相對簡單。
-
SVM 訓練,只有真實邊界框本身被視為對應類別的正樣本。對于負樣本,作者采用了
難例挖掘 (Hard Negative Mining) 策略
一些常見技術:
難例挖掘 (Hard Negative Mining):
先用一部分負樣本訓練 SVM,然后將訓練好的 SVM 應用到大量的、與任何真實物體 IoU 都很低的候選區域(這些都是“簡單”或“潛在困難”的背景樣本)上。找出那些被 SVM 錯誤地分為前景(即“難例” Hard Negatives)的背景樣本,將這些難例加入負樣本集中,重新訓練 SVM。 這個過程使得 SVM 特別擅長區分那些容易與真實物體混淆的背景區域,從而提高了分類的準確性。而 CNN 微調階段的 Softmax 通常沒有經過這樣專門針對難例的優化。
非極大值抑制 Non-Maximum Suppression:
對于一組指向同一物體的、相互重疊的邊界框,只保留那個置信度分數最高的框,并抑制(刪除)掉其他與它重疊度過高的框。



![[密碼學基礎]GB與GM國密標準深度解析:定位、差異與協同發展](http://pic.xiahunao.cn/[密碼學基礎]GB與GM國密標準深度解析:定位、差異與協同發展)





部署 BPMN XML 流程)







—— 無線網絡和移動網絡)


