AI圖像生成是一個非常有趣且前沿的領域,結合了深度學習和計算機視覺技術。以下是一些使用Python和相關庫進行AI圖像生成的創意和實現思路:
1. 使用GAN(生成對抗網絡)
基本概念:GAN由兩個神經網絡組成:生成器和判別器。生成器嘗試生成逼真的圖像,而判別器則試圖區分真實圖像和生成圖像。
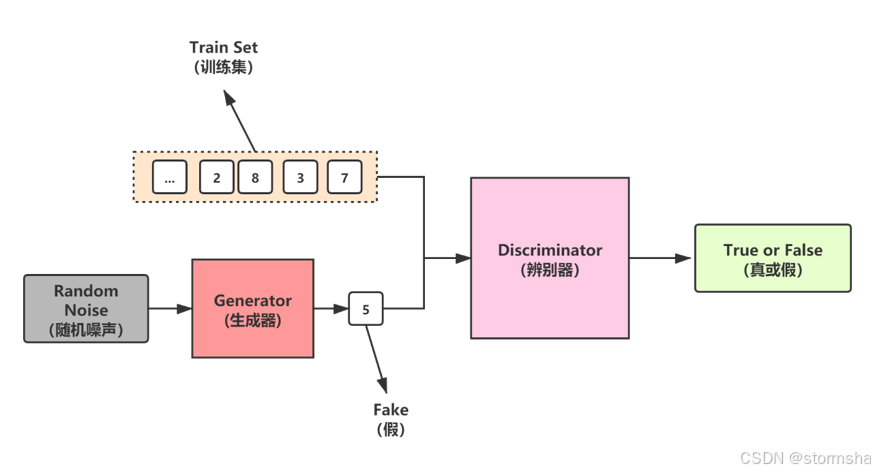
實現步驟:
-
安裝必要的庫:
pip install tensorflow keras matplotlib -
訓練一個簡單的GAN模型。例如,可以使用MNIST數據集來生成手寫數字。
-
代碼示例:
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Reshape, Flatten, Dropout from keras.optimizers import Adam# 加載數據集 (X_train, _), (_, _) = mnist.load_data() X_train = X_train / 255.0 X_train = X_train.reshape(X_train.shape[0], 784) # 將圖片展平# 創建生成器 def create_generator():model = Sequential()model.add(Dense(256, input_dim=100, activation='relu'))model.add(Dense(512, activation='relu'))model.add(Dense(1024, activation='relu'))model.add(Dense(784, activation='sigmoid'))model.add(Reshape((28, 28)))return model# 創建判別器 def create_discriminator():model = Sequential()model.add(Flatten(input_shape=(28, 28)))model.add(Dense(512, activation='relu'))model.add(Dropout(0.3))model.add(Dense(256, activation='relu'))model.add(Dense(1, activation='sigmoid'))return model# 構建GAN generator = create_generator() discriminator = create_discriminator() discriminator.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy'])discriminator.trainable = False gan_input = Input(shape=(100,)) generated_image = generator(gan_input) gan_output = discriminator(generated_image) gan = Model(gan_input, gan_output) gan.compile(loss='binary_crossentropy', optimizer=Adam())# 訓練GAN for epoch in range(10000):noise = np.random.normal(0, 1, size=[128, 100])generated_images = generator.predict(noise)X_fake_vs_real = np.concatenate([generated_images, X_train[:128]])y1 = np.zeros(128) # 假數據y2 = np.ones(128) # 真實數據y_combined = np.concatenate([y1, y2])discriminator.trainable = Trued_loss = discriminator.train_on_batch(X_fake_vs_real, y_combined)noise = np.random.normal(0, 1, size=[128, 100])y_mislabeled = np.ones(128) # 將所有的假圖像標記為真實discriminator.trainable = Falseg_loss = gan.train_on_batch(noise, y_mislabeled)if epoch % 1000 == 0:print(f"Epoch {epoch}, D Loss: {d_loss[0]}, G Loss: {g_loss}")# 生成圖像 noise = np.random.normal(0, 1, size=[25, 100]) generated_images = generator.predict(noise) plt.figure(figsize=(10, 10)) for i in range(25):plt.subplot(5, 5, i + 1)plt.imshow(generated_images[i], cmap='gray')plt.axis('off') plt.show()
2. 使用預訓練的模型
基本概念:可以使用像StyleGAN、BigGAN或DALL-E這樣的預訓練模型,直接生成高質量的圖像。

實現步驟:
-
使用Hugging Face的Transformers庫加載預訓練模型。
-
安裝必要的庫:
pip install transformers torch torchvision -
代碼示例(使用DALL-E):
from transformers import DallEProcessor, DallETokenizer, DallEModel import torch# 加載模型和處理器 processor = DallEProcessor.from_pretrained("dalle-mini/dalle-mini") model = DallEModel.from_pretrained("dalle-mini/dalle-mini")# 生成圖像 text = "A futuristic city skyline" inputs = processor(text, return_tensors="pt") outputs = model.generate(**inputs)# 顯示結果 image = outputs.images[0] image.show()
3. 圖像風格遷移
基本概念:通過將一幅圖像的風格應用到另一幅圖像上,生成新的藝術作品。
實現步驟:
-
使用TensorFlow或PyTorch實現風格遷移。
-
代碼示例(使用TensorFlow):
import tensorflow as tf import matplotlib.pyplot as plt# 加載內容圖像和風格圖像 content_image = load_image("content.jpg") style_image = load_image("style.jpg")# 使用預訓練的VGG模型進行風格遷移 model = tf.keras.applications.VGG19(include_top=False, weights='imagenet')# 定義風格和內容層 content_layers = ['block5_conv2'] style_layers = ['block1_conv1', 'block2_conv1', 'block3_conv1', 'block4_conv1', 'block5_conv1']# 風格遷移函數 def style_transfer(content, style):# 進行風格遷移的步驟# ...return generated_imagegenerated_image = style_transfer(content_image, style_image)# 顯示結果 plt.imshow(generated_image) plt.axis('off') plt.show()
總結
以上是一些使用Python進行AI圖像生成的創意與實現方法。這些項目既可以作為學習深度學習的實踐,也可以作為開發創意圖像生成應用的基礎。希望這些想法能激發你的創造力,幫助你在AI圖像生成領域探索更多可能性!
![P10413 [藍橋杯 2023 國 A] 圓上的連線](http://pic.xiahunao.cn/P10413 [藍橋杯 2023 國 A] 圓上的連線)

:架構優化與安全增強)
,內核的CPUFreq(DVFS)和ARM的SCPI)

)


配置入門指南)


)







