保存自定義層
在編寫自定義層時,一定要實現get_config()方法:這樣我們可以利用config字典將該層重新實例化,這對保存和加載模型很有用。該方法返回一個Python字典,其中包含用于創建該層的構造函數的參數值。所有Keras層都可以被序列化(serialize)和反序列化(deserialize)?,如下所示。
config = layer.get_config()
new_layer = layer.__class__.from_config(config) ←---- config不包含權重值,因此該層的所有權重都是從頭初始化的
來看下面這個例子。
layer = PositionalEmbedding(sequence_length, input_dim, output_dim)
config = layer.get_config()
new_layer = PositionalEmbedding.from_config(config)
在保存包含自定義層的模型時,保存文件中會包含這些config字典。從文件中加載模型時,你應該在加載過程中提供自定義層的類,以便其理解config對象,如下所示。
model = keras.models.load_model(filename, custom_objects={"PositionalEmbedding": PositionalEmbedding})
你會注意到,這里使用的規范化層并不是之前在圖像模型中使用的BatchNormalization層。這是因為BatchNormalization層處理序列數據的效果并不好。相反,我們使用的是LayerNormalization層,它對每個序列分別進行規范化,與批量中的其他序列無關。它類似NumPy的偽代碼如下
def layer_normalization(batch_of_sequences): ←----輸入形狀:(batch_size, sequence_length, embedding_dim)mean = np.mean(batch_of_sequences, keepdims=True, axis=-1) ←---- (本行及以下1行)計算均值和方差,僅在最后一個軸(?1軸)上匯聚數據variance = np.var(batch_of_sequences, keepdims=True, axis=-1)return (batch_of_sequences - mean) / variance
下面是訓練過程中的BatchNormalization的偽代碼,你可以將二者對比一下。
def batch_normalization(batch_of_images): ←----輸入形狀:(batch_size, height, width, channels)mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2)) ←---- (本行及以下1行)在批量軸(0軸)上匯聚數據,這會在一個批量的樣本之間形成相互作用variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2))return (batch_of_images - mean) / variance
BatchNormalization層從多個樣本中收集信息,以獲得特征均值和方差的準確統計信息,而LayerNormalization層則分別匯聚每個序列中的數據,更適用于序列數據。我們已經實現了TransformerEncoder,下面可以用它來構建一個文本分類模型,如代碼清單11-22所示,它與前面的基于GRU的模型類似。代碼清單11-22 將Transformer編碼器用于文本分類
vocab_size = 20000
embed_dim = 256
num_heads = 2
dense_dim = 32inputs = keras.Input(shape=(None,), dtype="int64")
x = layers.Embedding(vocab_size, embed_dim)(inputs)
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x) ←---- TransformerEncoder返回的是完整序列,所以我們需要用全局匯聚層將每個序列轉換為單個向量,以便進行分類
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",loss="binary_crossentropy",metrics=["accuracy"])
model.summary()
我們來訓練這個模型,如代碼清單11-23所示。模型的測試精度為87.5%,比GRU模型略低。代碼清單11-23 訓練并評估基于Transformer編碼器的模型
callbacks = [keras.callbacks.ModelCheckpoint("transformer_encoder.keras",save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,callbacks=callbacks)
model = keras.models.load_model("transformer_encoder.keras",custom_objects={"TransformerEncoder": TransformerEncoder}) ←----在模型加載過程中提供自定義的TransformerEncoder類
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
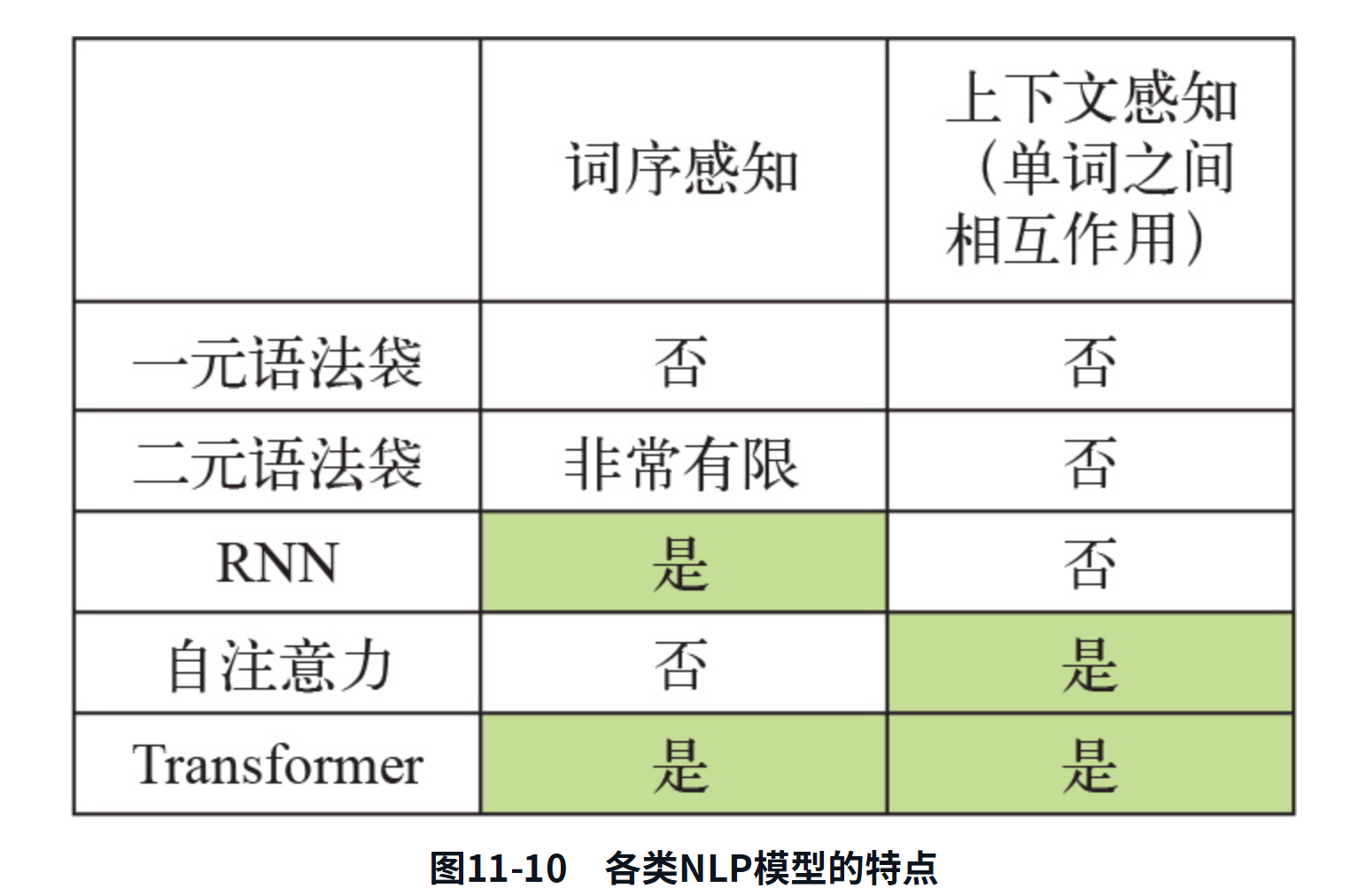
現在你應該已經開始感到有些不對勁了。你能看出是哪里不對勁嗎?本節的主題是“序列模型”?。我一開始就強調了詞序的重要性。我說過,Transformer是一種序列處理架構,最初是為機器翻譯而開發的。然而……你剛剛見到的Transformer編碼器根本就不是一個序列模型。你注意到了嗎?它由密集層和注意力層組成,前者獨立處理序列中的詞元,后者則將詞元視為一個集合。你可以改變序列中的詞元順序,并得到完全相同的成對注意力分數和完全相同的上下文感知表示。如果將每篇影評中的單詞完全打亂,模型也不會注意到,得到的精度也完全相同。自注意力是一種集合處理機制,它關注的是序列元素對之間的關系,如圖11-10所示,它并不知道這些元素出現在序列的開頭、結尾還是中間。既然是這樣,為什么說Transformer是序列模型呢?如果它不查看詞序,又怎么能很好地進行機器翻譯呢?
Transformer是一種混合方法,它在技術上是不考慮順序的,但將順序信息手動注入數據表示中。這就是缺失的那部分,它叫作位置編碼(positional encoding)?。我們來看一下。
使用位置編碼重新注入順序信息
位置編碼背后的想法非常簡單:為了讓模型獲取詞序信息,我們將每個單詞在句子中的位置添加到詞嵌入中。這樣一來,輸入詞嵌入將包含兩部分:普通的詞向量,它表示與上下文無關的單詞;位置向量,它表示該單詞在當前句子中的位置。我們希望模型能夠充分利用這一額外信息。你能想到的最簡單的方法就是將單詞位置與它的嵌入向量拼接在一起。你可以向這個向量添加一個“位置”軸。在該軸上,序列中的第一個單詞對應的元素為0,第二個單詞為1,以此類推。然而,這種做法可能并不理想,因為位置可能是非常大的整數,這會破壞嵌入向量的取值范圍。如你所知,神經網絡不喜歡非常大的輸入值或離散的輸入分布。
在“Attention Is All You Need”這篇原始論文中,作者使用了一個有趣的技巧來編碼單詞位置:將詞嵌入加上一個向量,這個向量的取值范圍是[-1, 1],取值根據位置的不同而周期性變化(利用余弦函數來實現)?。這個技巧提供了一種思路,通過一個小數值向量來唯一地描述較大范圍內的任意整數。這種做法很聰明,但并不是本例中要用的。我們的方法更加簡單,也更加有效:我們將學習位置嵌入向量,其學習方式與學習嵌入詞索引相同。然后,我們將位置嵌入與相應的詞嵌入相加,得到位置感知的詞嵌入。這種方法叫作位置嵌入(positional embedding)?。我們來實現這種方法,如代碼清單11-24所示。代碼清單11-24 將位置嵌入實現為Layer子類
class PositionalEmbedding(layers.Layer):def __init__(self, sequence_length, input_dim, output_dim, **kwargs): ←----位置嵌入的一個缺點是,需要事先知道序列長度super().__init__(**kwargs)self.token_embeddings = layers.Embedding( ←----準備一個Embedding層,用于保存詞元索引input_dim=input_dim, output_dim=output_dim)self.position_embeddings = layers.Embedding(input_dim=sequence_length, output_dim=output_dim) ←----另準備一個Embedding層,用于保存詞元位置self.sequence_length = sequence_lengthself.input_dim = input_dimself.output_dim = output_dimdef call(self, inputs):length = tf.shape(inputs)[-1]positions = tf.range(start=0, limit=length, delta=1)embedded_tokens = self.token_embeddings(inputs)embedded_positions = self.position_embeddings(positions)return embedded_tokens + embedded_positions ←----將兩個嵌入向量相加def compute_mask(self, inputs, mask=None): ←---- (本行及以下1行)與Embedding層一樣,該層應該能夠生成掩碼,從而可以忽略輸入中填充的0。框架會自動調用compute_mask方法,并將掩碼傳遞給下一層return tf.math.not_equal(inputs, 0)def get_config(self): ←----實現序列化,以便保存模型config = super().get_config()config.update({"output_dim": self.output_dim,"sequence_length": self.sequence_length,"input_dim": self.input_dim,})return config
你可以像使用普通Embedding層一樣使用這個PositionEmbedding層。我們來看一下它的實際效果。



:從Dock窗口集成到功能菜單實現)















