工業場景漏洞檢測新突破:CodeBERT跨領域泛化能力評估與AI-DO工具開發
論文信息
- 論文原標題:Cross-Domain Evaluation of Transformer-Based Vulnerability Detection: Open-Source vs. Industrial Data
- 引文格式(APA):[作者]. (年份). Cross-Domain Evaluation of Transformer-Based Vulnerability Detection: Open-Source vs. Industrial Data. [期刊/會議名稱, 卷(期), 頁碼]. https://arxiv.org/pdf/2509.09313
一段話總結
該論文聚焦學術領域漏洞檢測深度學習方案在工業場景應用的痛點,構建了覆蓋開源與工業的PHP函數漏洞標注數據集,通過不同數據平衡策略微調CodeBERT模型,評估其在跨領域(開源與工業數據)的漏洞檢測性能,開發了集成于CI/CD流程的漏洞檢測推薦系統AI-DO,并結合企業IT專業人員調查評估工具實用性,最終明確了CodeBERT在工業漏洞檢測中的可行性及跨領域泛化能力,為學術技術向工業落地提供參考。
研究背景
在當下的軟件安全領域,漏洞檢測就像給軟件“體檢”,目的是找出潛在的“健康隱患”(漏洞),避免后續被黑客利用造成損失。然而,目前學術研究中提出的很多基于深度學習的漏洞檢測方案,卻像“實驗室里的精密儀器”,在實際工業場景中“水土不服”。
一方面,這些學術方案的開發者可訪問性低,工業界的開發團隊想用上并不容易;另一方面,它們在工業場景的適用性沒被充分驗證,就像一款新藥沒在廣泛的患者群體中測試,無法確定在實際治療中的效果。從學術到工業的技術遷移,還面臨著不少“攔路虎”:比如方案的可信度,工業界擔心學術方案在真實復雜的工業環境中不靠譜;還有遺留系統問題,很多企業還在使用舊系統,學術方案可能無法兼容;同時,工業界部分人員數字素養有限,專業知識也和學術界存在差距,導致難以有效使用學術方案;另外,深度學習模型的性能以及和現有工作流的集成度,也是工業界非常顧慮的問題,畢竟如果模型性能差,或者和現有工作流程不契合,會嚴重影響工作效率。
舉個例子,某制造企業使用基于PHP開發的ERP系統來管理生產、庫存等核心業務,這個系統已經運行了十幾年,屬于遺留系統。之前嘗試引入一款學術界提出的漏洞檢測工具,結果要么因為工具無法適配舊系統的代碼結構,要么檢測出的漏洞和實際工業場景中的漏洞類型偏差大,還經常出現漏檢或誤檢的情況,最終不得不放棄使用,還是依靠人工代碼審查來檢測漏洞,不僅效率低,還容易因為人為疏忽漏掉關鍵漏洞。
正是這些問題的存在,使得工業界對高效、適配的漏洞檢測方案需求迫切,這也正是該論文研究的出發點。
創新點
- 構建獨特數據集:填補了同時覆蓋開源與工業PHP函數漏洞標注數據集的空白,且嚴格遵循數據集質量框架,保證了數據的準確性、唯一性、一致性、完整性和時效性,為后續跨領域評估提供了可靠的數據基礎。
- 多維度跨領域評估:不僅評估CodeBERT在單一數據集(開源或工業)上的漏洞檢測性能,更重點分析了模型在開源數據上微調后測試工業數據(反之亦然)的跨領域泛化能力,還對比了不同數據平衡策略對跨領域性能的影響,視角更全面。
- 實用工具開發與反饋收集:并非只停留在理論研究和模型評估,而是開發了可集成于CI/CD流程的漏洞檢測推薦系統AI-DO,能自動在代碼審查階段檢測并標記漏洞函數,還通過企業IT專業人員調查,收集真實使用反饋,為工具優化和工業落地提供依據,實現了從理論到實踐的落地。
- 優先考慮工業場景需求:在評估指標中,充分考慮到工業漏洞檢測中漏檢可能導致嚴重安全風險的特點,優先關注召回率,使研究更貼合工業實際需求,而不是單純追求綜合性能指標。
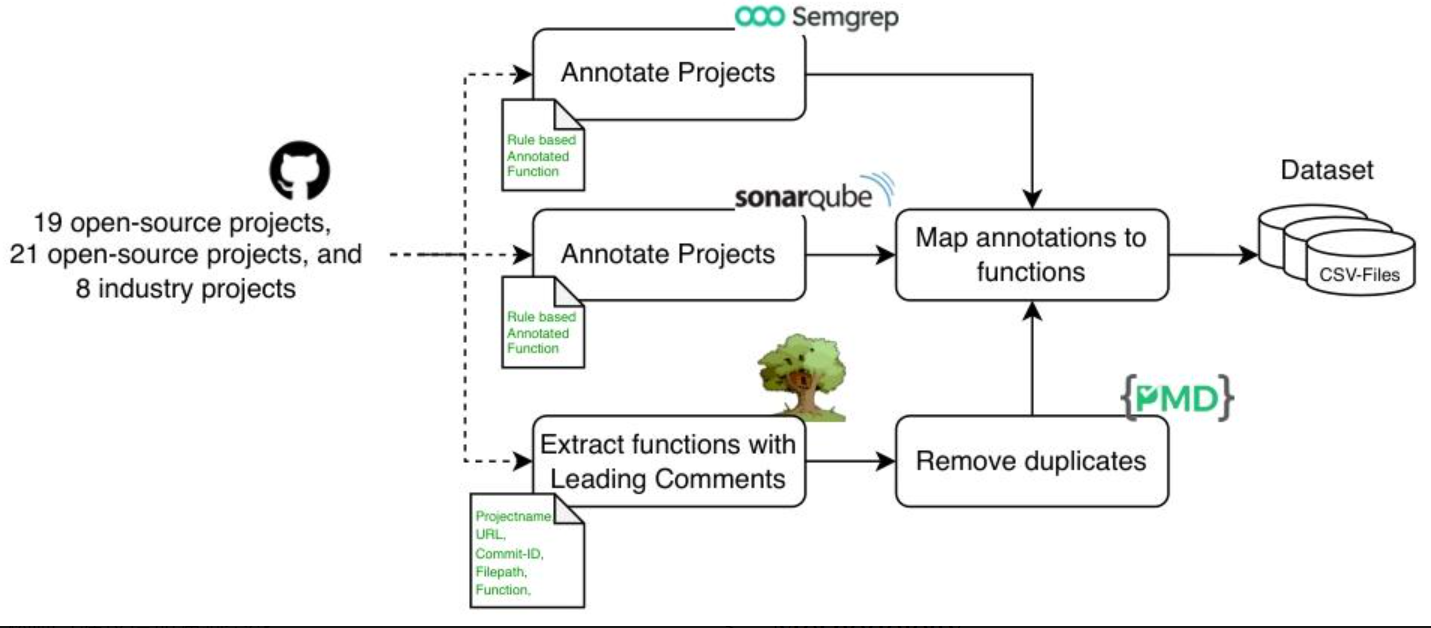
研究方法和思路、實驗方法
(一)數據集構建與標注(分4步)
- 確定數據集類型與來源:明確構建三類數據集,分別是工業數據集(ID,來自合作企業8個ERP項目)、通用開源數據集(GOD,選取21個熱門PHP開源項目)、技術相似開源數據集(TOD,來自GitHub上19個PHP開發的頂級ERP工具),確保數據覆蓋不同場景。
- 函數提取與去重:使用TreeSitter工具提取PHP函數,再用PMD-CPD工具,通過滑動窗口(窗口大小30)和99%杰卡德指數閾值檢測重復代碼,去除重復函數,保證數據唯一性,避免重復數據對模型訓練的干擾。
- 統一標注方式:結合SemGrep(0.73.0版本)和SonarQube(9.4版本)兩款主流靜態分析工具進行函數級標注,并且排除SemGrep的“Info/Minor”標簽和SonarQube的“Warning”標簽作為漏洞指標,一個函數即使有多個漏洞也僅計為一次標注,確保標注標準一致。
- 質量保障:遵循Croft等人提出的數據集質量框架,從準確性(依賴主流SAST工具標注)、唯一性(去重處理)、一致性(統一工具版本與配置)、完整性(包含函數定位信息)和時效性(所有數據集同時構建,時間對齊)五個方面保障數據集質量。
(二)CodeBERT微調(分3步)
- 確定模型基礎與參數:選擇由微軟研究院開發的CodeBERT模型,該模型預訓練涵蓋Python、Java、PHP等6種編程語言,在代碼相關任務上性能較優;設置塊大小為512,批次大小16,學習率2e-5,訓練10個epoch,若5個epoch內F1分數提升不超過0.001則手動早停,同時將數據集按80%/10%/10%隨機劃分為訓練集、驗證集和測試集,僅訓練集采用平衡策略。
- 設計4種數據平衡策略:
- 無平衡(NB):直接保留數據集自然分布,不做任何處理。
- 全局欠采樣(USC):以所有數據集中最小類別(ID的漏洞實例,共4,934個)為基準,對其他類別進行欠采樣,平衡類別數量。
- 數據集內欠采樣(URSC):在每個數據集內部,以較小類別(漏洞類)的規模來確定非漏洞類樣本量,實現單個數據集內的類別平衡。
- 加權損失函數(WLF):保持數據集自然分布不變,通過調整損失函數的權重,讓模型在訓練時更多關注重要的樣本(漏洞樣本),區分兩類樣本的重要性。
- 模型訓練與評估準備:按照上述參數和平衡策略對CodeBERT進行微調訓練,為后續跨領域性能評估做好準備。
(三)跨領域評估與工具開發(分2步)
- 確定評估指標與評估邏輯:采用精確率(P)、召回率(R)和F1分數作為評估指標,因漏洞檢測中漏檢可能導致嚴重安全風險,評估時優先考慮召回率;分別評估模型在同域(同一數據集微調并測試)和跨域(一個數據集微調,另一個數據集測試)的性能,分析平衡策略和數據集類型對模型性能的影響。
- 開發AI-DO工具并收集反饋:將微調后的CodeBERT模型集成于GitHub Action,開發AI-DO工具,該工具能利用git和TreeSitter自動提取拉取請求(PR)中新增/修改的函數,檢測漏洞并自動標記,在PR頁面反饋結果;同時設計調查,收集13名企業IT專業人員對工具的使用反饋,評估工具感知實用性。
主要成果和貢獻
(一)核心成果(表格形式)
| 類別 | 具體內容 |
|---|---|
| RQ1答案 | CodeBERT能用于工業源代碼漏洞檢測。基于企業數據微調的CodeBERT在工業未見過數據上表現良好,F1分數較開源未見過數據(同模型微調測試)最多下降10%,加權損失函數可縮小差距;欠采樣技術能有效減少漏檢,但在工業DevOps環境推廣需應對安全專家等高度專業人員的抵觸情緒 |
| RQ2答案 | 基于開源漏洞數據微調的CodeBERT,對工業技術特定數據的泛化能力受開源數據類型和平衡策略影響。技術無關開源數據(GOD)結合URSC欠采樣微調,能更好控制工業未見過數據的漏檢(因開源數據漏洞類型和編碼風格更多樣),但會增加假陽性,可能降低開發團隊對工具的信任 |
| 平衡策略效果 | 1. 最大化召回率(減少漏檢):欠采樣技術(USC/URSC)更優;優化F1分數(綜合性能):無平衡(NB)或加權損失函數(WLF)更合適 2. 同域場景:NB或WLF帶來更高F1分數和精確率,欠采樣提升召回率 3. 跨域場景:欠采樣提升F1分數和召回率,NB或WLF更利于精確率提升 |
| 數據集影響 | 1. 同域優勢:模型在微調數據集上測試性能最佳 2. TOD微調模型:在ID上測試的召回率優于GOD 3. GOD微調模型:在ID上測試的召回率與GOD測試結果相近甚至更優 4. ID微調模型:在開源數據上測試召回率顯著下降 5. GOD+URSC:對工業數據漏洞漏檢控制效果優于ID任何平衡策略微調結果,但假陽性增加 |
| AI-DO工具反饋 | 1. 積極態度群體:頻繁遭遇漏洞的DevOps專家(認為加速開發)、資深軟件工程師、軟件架構師(建議增加漏洞詳情)、初級開發者(滿意度中等) 2. 謹慎/負面態度群體:安全專家(擔憂崗位價值)、極少遭遇漏洞的DevOps專家(建議擴展檢測規則)、團隊負責人(認為精度不足,漏洞常跨多行/類) 3. 規律:接受度與自身漏洞檢測經驗及工具滿足需求度高度相關 |
(二)核心貢獻
- 數據貢獻:完成了工業與開源數據集的跨領域性能評估,并且公開了構建的三類PHP函數漏洞標注數據集,填補了該領域同時覆蓋開源與工業數據的空白,為后續相關研究提供了可靠的數據支持。
- 工具貢獻:開發了可集成于CI/CD流程的漏洞檢測推薦系統AI-DO,該工具能在代碼審查階段自動檢測并定位漏洞函數,不干擾現有開發流程,還支持模型離線微調與更新,為工業界提供了實用的漏洞檢測工具,提升了漏洞檢測效率。
- 實踐參考貢獻:通過企業IT專業人員調查,明確了漏洞檢測工具在工業場景的接受度影響因素(如使用者自身漏洞檢測經驗、工具對需求的滿足度等),為學術技術向工業落地提供了寶貴的實踐參考,幫助后續研究更好地貼合工業實際需求。
(三)開源資源
- 數據集:論文中構建的工業數據集(ID)、通用開源數據集(GOD)、技術相似開源數據集(TOD)已公開(具體地址需參考論文補充信息)。
- 代碼:AI-DO工具及CodeBERT微調相關代碼(具體地址需參考論文補充信息)。
關鍵問題(問答形式)
- 問題:CodeBERT模型是否能夠有效應用于工業源代碼的漏洞檢測工作?
答案:可以。基于企業數據微調后的CodeBERT模型,在工業未見過的數據上表現良好,其F1分數相較于在開源未見過數據(同模型微調測試)的結果最多下降10%,且采用加權損失函數還能進一步縮小這一差距;若重點關注減少漏檢情況,欠采樣技術會更有效。不過,在工業DevOps環境推廣時,需要應對安全專家等高度專業人員的抵觸情緒,因為他們可能認為該工具會降低自身崗位價值。 - 問題:基于開源漏洞數據微調的CodeBERT模型,對工業技術特定數據的跨領域泛化能力怎么樣?
答案:其泛化能力受開源數據類型和數據平衡策略的影響。其中,技術無關開源數據(GOD)結合數據集內欠采樣(URSC)策略進行微調后,能更好地控制工業未見過數據的漏檢情況,這是因為開源數據中包含的漏洞類型和編碼風格更加多樣,有助于提升模型識別真實漏洞的能力;但這種方式會伴隨假陽性的增加,可能導致開發團隊進行不必要的調查工作,進而降低對工具的信任度。 - 問題:在漏洞檢測中,不同的數據平衡策略分別能起到什么效果,該如何選擇?
答案:不同平衡策略效果不同,選擇需結合需求。若要最大化召回率(減少漏檢),欠采樣技術(USC/URSC)更優;若要優化F1分數(綜合性能),無平衡(NB)或加權損失函數(WLF)更合適。在同一數據集上微調與測試(同域)時,NB或WLF能帶來更高F1分數和精確率,欠采樣可提升召回率;在跨數據集場景中,欠采樣能提升F1分數和召回率,NB或WLF更利于精確率提升。 - 問題:開發的AI-DO工具在工業場景中的接受度如何,不同角色的IT專業人員對其態度有何差異?
答案:工具接受度與使用者自身漏洞檢測經驗及工具對其需求的滿足度高度相關。積極態度群體包括頻繁遭遇漏洞的DevOps專家(認為工具加速開發、提前發現問題)、資深軟件工程師、軟件架構師(建議增加漏洞類型詳情與推理說明)、初級開發者(滿意度中等);謹慎/負面態度群體包括安全專家(擔憂工具威脅自身崗位價值,態度中等)、極少遭遇漏洞的DevOps專家(認為需擴展檢測規則)、團隊負責人(認為工具精度不足,因漏洞常跨多行/類)。 - 問題:該研究在有效性方面存在哪些威脅,未來有哪些改進方向?
答案:有效性威脅包括構念有效性(已通過統一流程確保貼合目標)、內部有效性(PMD-CPD無法識別所有共享代碼)、外部有效性(結果受限于PHP語言和實驗數據集,調查可能有偏向性)、結論有效性(采用標準指標確保可靠)。未來工作方向包括擴展到多編程語言、多Transformer模型和多標注類型,利用新數據集(Madewic)優化方案,提升AI-DO工具精度,解決漏洞跨多行/類檢測問題,完善漏洞說明與推理邏輯。
總結
該論文針對學術領域漏洞檢測深度學習方案在工業場景應用的痛點,開展了全面且深入的研究。首先,構建了三類覆蓋開源與工業的PHP函數漏洞標注數據集,并嚴格保障數據質量;接著,通過四種不同的數據平衡策略對CodeBERT模型進行微調,系統評估了模型在同域和跨域場景下的漏洞檢測性能,明確了不同策略和數據集類型對模型性能的影響;然后,開發了可集成于CI/CD流程的AI-DO漏洞檢測工具,并結合企業IT專業人員反饋,分析了工具在工業場景的接受度及影響因素;最后,回答了研究提出的核心問題,指出了研究的有效性威脅并給出未來改進方向。
)
















)

