1. 引言
傳統的語音處理系統(如OpenAI的Whisper)在ASR任務上取得了巨大成功,能將語音高精度地轉換為文本。但這只是第一步。真正的“語音理解”意味著:
- 內容推理:不僅知道說了什么,還能理解話語背后的含義、情感和意圖。
- 長篇摘要:能夠聽完一段長達數十分鐘的播客或會議,并總結其核心要點。
- 問答交互 (Audio QA):能回答關于音頻內容細節的具體問題。
- 多語言能力:不僅能轉錄和翻譯,還能理解不同語言的音頻內容。
Voxtral正是為了實現這一從“轉錄”到“理解”的飛躍而設計的。它是一個端到端的音頻對話模型,能夠直接接收語音或文本輸入,并生成文本回答,其32K的上下文窗口使其能處理長達40分鐘的音頻文件。
2. Voxtral架構設計:Whisper與Mistral的“強強聯合”
Voxtral的架構清晰而優雅,由三個核心組件構成,巧妙地將SOTA的音頻編碼能力和語言建模能力結合在一起。
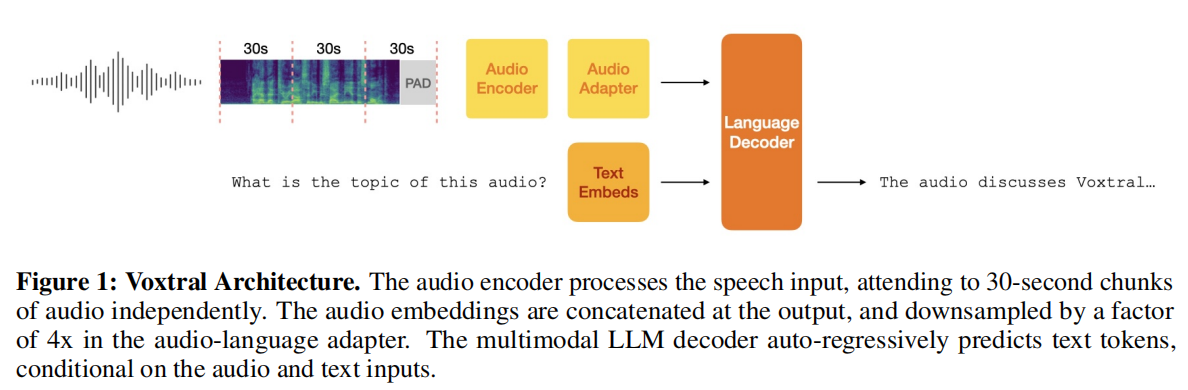
(Voxtral的整體架構:語音輸入被Whisper編碼器分塊處理,輸出的音頻嵌入序列經過Adap






)





)

)

)


)