RayS:一種用于硬標簽對抗攻擊的光線搜索方法
Jinghui Chen
University of California, Los Angeles
jhchen@cs.ucla.edu
Quanquan Gu
University of California, Los Angeles
qgu@cs.ucla.edu
原文鏈接:https://arxiv.org/pdf/2006.12792
摘要
深度神經網絡(DNNs)易受對抗攻擊。在不同的攻擊設置中,最具挑戰性但也最實用的是硬標簽設置(hard-label setting),其中攻擊者只能訪問目標模型的硬標簽輸出(預測標簽)。在廣泛使用的 (L_{\infty}) 范數威脅模型下,之前的嘗試在攻擊成功率方面不夠有效,在查詢復雜度方面也不夠高效。本文中,我們提出了光線搜索攻擊(Ray Searching attack, RayS),它極大地提高了硬標簽攻擊的有效性和效率。與之前的工作不同,我們將尋找最近決策邊界的連續問題重新表述為一個離散問題,該問題不需要任何零階梯度估計。同時,通過一個快速檢查步驟(fast check step)消除了所有不必要的搜索。這顯著減少了我們的硬標簽攻擊所需的查詢次數。此外,有趣的是,我們發現所提出的 RayS 攻擊也可以用作檢測可能的“虛假魯棒”(falsely robust)模型的健全性檢查(sanity check)。在幾個最近提出的聲稱達到最先進(state-of-the-art)魯棒精度的防御方法上,我們的攻擊方法表明,當前的白盒/黑盒攻擊可能仍然會給人一種錯誤的安全感,最流行的 PGD 攻擊與 RayS 攻擊之間的魯棒精度下降可能高達 28%。我們相信,我們提出的 RayS 攻擊可以幫助識別那些擊敗了大多數白盒/黑盒攻擊的虛假魯棒模型。
關鍵詞: 魯棒性 (robustness), 深度神經網絡 (deep neural networks), 硬標簽攻擊 (hard-label attacks)
CCS 概念: ? 計算理論 → 機器學習理論;? 計算方法學 → 離散空間搜索;目標識別
1. 引言
在過去十年中,深度神經網絡(DNNs)在計算機視覺[15, 36]和語音識別[17]等許多機器學習任務上取得了顯著成功。盡管取得了巨大成功,但最近的研究表明 DNNs 容易受到對抗樣本(adversarial examples)的攻擊,即即使人眼不可察覺的(專門設計而非隨機的)擾動也可能導致最先進的分類器做出錯誤預測[13, 38]。這種有趣的現象很快引發了對抗攻擊[3, 5, 7](試圖用這種微小擾動破壞 DNN 模型)與對抗防御方法[27, 33, 40, 41, 46](試圖防御現有攻擊)之間的軍備競賽。在這場軍備競賽中,許多啟發式防御方法[12, 14, 26, 33, 34, 35, 42]后來被證明在更強大的攻擊下無效。一個例外是對抗訓練(adversarial training)[13, 27],它被證明是一種有效的防御方法。
在這場軍備競賽中,人們提出了大量的對抗攻擊方法。根據攻擊者可以訪問的信息量不同,對抗攻擊通常分為三類:白盒攻擊(white-box attacks)、黑盒攻擊(black-box attacks)和硬標簽攻擊(hard-label attacks)。白盒攻擊[5, 27]是指攻擊者可以訪問有關目標模型的所有信息,包括模型權重、結構、參數以及可能的防御機制。由于白盒攻擊者可以訪問所有模型細節,它可以高效地在目標模型上執行反向傳播并計算梯度。在黑盒攻擊中,攻擊者只能訪問目標模型的查詢軟標簽輸出(不同類別的 logits 或概率分布),其他部分被視為黑盒。與白盒情況相比,黑盒設置實用得多,然而,在這種設置下,攻擊者無法執行反向傳播和直接梯度計算。因此,許多人轉向從已知模型遷移梯度[30]或通過零階優化方法(zeroth-order optimization methods)估計真實梯度[1, 7, 19, 20]。
另一方面,硬標簽攻擊(hard-label attacks),也稱為基于決策的攻擊(decision-based attacks),只允許攻擊者查詢目標模型并獲得硬標簽輸出(預測標簽)。顯然,硬標簽設置是最具挑戰性的,但也是最實用的,因為在現實中,攻擊者事先知道目標模型的所有信息或獲得所有類別的概率預測的可能性很小。僅能訪問硬標簽也意味著攻擊者無法辨別在輸入一個輕微擾動的輸入樣本時(假設這種輕微擾動不會改變模型預測),目標模型輸出的細微變化。因此,攻擊者只能在目標模型的決策邊界(decision boundary)附近找到信息線索,在那里微小的擾動可能導致模型產生不同的預測標簽。之前的工作[4, 6, 9, 10]大多遵循這一思路來解決硬標簽對抗攻擊問題。然而,[4, 6, 9, 10] 最初都是針對 L2L_{2}L2? 范數威脅模型提出的,而 L∞L_{\infty}L∞? 范數威脅模型[21, 27, 44, 45, 46]目前是最流行和廣泛使用的。盡管[6, 9, 10]提供了對 L∞L_{\infty}L∞? 范數情況的擴展,但沒有一個是為 L∞L_{\infty}L∞? 范數情況優化的,因此,它們的攻擊性能在很大程度上落后于傳統的基于 L∞L_{\infty}L∞? 范數的白盒和黑盒攻擊,使得
它們在現實世界場景中不適用。這就引出了一個自然的問題:
我們能否設計一種硬標簽攻擊,能夠極大地改進之前的硬標簽攻擊,并為最廣泛使用的 L∞L_{\infty}L∞?范數威脅模型提供實用的攻擊?
在本文中,我們肯定地回答了這個問題。我們將我們的主要貢獻總結如下:
- 我們提出了光線搜索攻擊(Ray Searching attack),它僅依賴于目標模型的硬標簽輸出。我們表明,在 L∞L_{\infty}L∞? 范數威脅模型下,所提出的硬標簽攻擊比之前的硬標簽攻擊更有效和高效。
- 與之前大多數通過零階優化方法解決硬標簽攻擊問題的工作不同,我們將尋找最近決策邊界的連續優化問題重新表述為一個離散問題,并直接在一組離散的光線方向(ray directions)上搜索最近的決策邊界。還利用一個快速檢查步驟來跳過不必要的搜索。這顯著節省了硬標簽攻擊所需的查詢次數。我們提出的攻擊也不需要調整超參數,如步長或有限差分常數,使其非常穩定且易于應用。
- 此外,我們提出的 RayS 攻擊也可以用作一種強大的攻擊來檢測可能的“虛假魯棒”模型。通過用 RayS 攻擊評估幾個最近提出的聲稱達到最先進魯棒精度的防御方法,我們表明當前的白盒/黑盒攻擊可能會被欺騙,給人一種錯誤的安全感。具體來說,RayS 攻擊顯著降低了最流行的 PGD 攻擊在幾個魯棒模型上的魯棒精度,差異可能高達 28%。我們相信,我們提出的 RayS 攻擊可以幫助識別那些欺騙當前白盒/黑盒攻擊的虛假魯棒模型。
本文的其余部分組織如下:在第 2 節中,我們簡要回顧了關于對抗攻擊的現有文獻。我們在第 3 節中介紹我們提出的光線搜索攻擊(RayS)。在第 4 節中,我們通過評估幾個最近提出的防御方法,展示了所提出的 RayS 攻擊比其他硬標簽攻擊更高效,并且可以用作檢測虛假魯棒模型的健全性檢查。最后,我們在第 5 節總結本文并提供討論。
符號說明。 對于一個 ddd 維向量 x=[x1,...,xd]?\mathbf{x}=[\mathbf{x}_{1},...,\mathbf{x}_{d}]^{\top}x=[x1?,...,xd?]?,我們使用∥x∥0=∑i1{xi≠0}\|\mathbf{x}\|_{0}=\sum_{i}1\{\mathbf{x}_{i}\neq 0\}∥x∥0?=∑i?1{xi?=0}表示其 ?0\ell_{0}?0?-范數,使用∥x∥2=(∑l=1d∣xl∣2)1/2\|\mathbf{x}\|_{2}=(\sum_{l=1}^{d}|\mathbf{x}_{l}|^{2})^{1/2}∥x∥2?=(∑l=1d?∣xl?∣2)1/2 表示其 ?2\ell_{2}?2?-范數,使用 ∥x∥∞=max?i∣xl∣\|\mathbf{x}\|_{\infty}=\max_{i}|\mathbf{x}_{l}|∥x∥∞?=maxi?∣xl?∣ 表示其?∞\ell_{\infty}?∞?-范數,其中 1(?)1(\cdot)1(?) 表示指示函數。
2. 相關工作
有大量關于評估模型魯棒性和生成對抗樣本的工作。在本節中,我們回顧與我們的工作最相關的工作。
白盒攻擊: Szegedy 等人 [38] 首先提出了對抗樣本的概念,并采用 L-BFGS 算法進行攻擊。Goodfellow 等人 [13] 通過線性化網絡損失函數提出了快速梯度符號法(Fast Gradient Sign Method, FGSM)。Kurakin 等人 [23] 提出迭代執行 FGSM 然后進行投影,這等價于投影梯度下降(Projected Gradient Descent, PGD)[27]。Papernot 等人 [32] 提出了基于 Jacobian 顯著圖(Jacobian saliency map)的 JSMA 方法。Moosavi-Dezfooli 等人 [29] 通過將數據投影到最近的分離超平面提出了 DeepFool 攻擊。Carlini 和 Wagner [5] 引入了基于邊界損失函數(margin-based loss function)的 CW 攻擊,并表明防御性蒸餾(defensive distillation)[33] 并非真正魯棒。Chen 等人 [7] 提出了一種基于 Frank-Wolfe 方法和動量的無投影攻擊(projection-free attack)。Athalye 等人 [3] 指出了混淆梯度(obfuscated gradients)的影響,并提出了 BPDA 攻擊來打破那些混淆梯度的防御。
黑盒攻擊: 除了上述白盒攻擊算法外,還有大量文獻[18, 18, 19, 20, 31, 7, 8, 25]關注黑盒攻擊情況,其中信息僅限于模型的 logits 輸出,而不是模型的每個細節。基于遷移的黑盒攻擊[31, 30, 18]試圖將梯度從已知模型遷移到黑盒目標模型,然后應用與白盒情況相同的技術。然而,它們的攻擊效果通常不太令人滿意。基于優化的黑盒攻擊旨在通過零階優化方法估計真實梯度。Chen 等人 [8] 提出通過對每個維度進行有限差分(finite-difference)來估計梯度。Ilyas 等人 [19] 提出通過自然進化策略(Natural Evolutionary Strategies)改進 [8] 的查詢效率。Ilyas 等人 [20] 通過利用梯度先驗(gradient priors)進一步改進了 [19]。Uesato 等人 [39] 提出使用 SPSA 方法構建一種無梯度攻擊(gradient-free attack),可以打破梯度消失防御(vanishing gradient defenses)。Al-Dujaili 和 O’Reilly [1] 提出直接估計梯度的符號而不是真實梯度本身。Moon 等人 [28] 將連續優化問題重新表述為離散問題,并提出了一種基于組合搜索(combinatorial search)的算法以提高攻擊效率。Andriushchenko 等人 [2] 提出了一種隨機搜索方案,迭代地將小方塊(squares)修補(patch)到測試樣本上。
硬標簽攻擊: Brendel 等人 [4] 首先研究了硬標簽攻擊問題,并提議通過在決策邊界附近進行隨機游走(random walks)來解決。Ilyas 等人 [19] 展示了一種將硬標簽攻擊問題轉化為軟標簽攻擊問題的方法。Cheng 等人 [9] 將對偶優化問題轉化為尋找導致到決策邊界距離最短(L2L_{2}L2? 距離)的最佳方向的問題,并通過零階優化方法優化這個新問題。Cheng 等人 [10] 通過估計梯度符號而不是真實梯度,進一步改進了 [9] 的查詢復雜度。Chen 等人 [6] 也應用零階符號預言機(zeroth-order sign oracle)來改進 [4],通過搜索步長并保持迭代點沿決策邊界移動。
3. 提出的方法
在本節中,我們介紹我們提出的光線搜索攻擊(Ray Searching attack, RayS)。在我們詳細介紹我們提出的方法之前,我們首先概述一下之前的對抗攻擊問題表述。
3.1 先前問題表述概述
我們用 fff 表示 DNN 模型,測試數據樣本為 {x,y}\{\mathbf{x},y\}{x,y}。對抗攻擊的目標是解決以下優化
問題:
min?x′1{f(x′)=y}s.t.,?∥x′?x∥∞≤?,(3.1)\min_{\mathbf{x}^{\prime}}\mathbb{1}\{f(\mathbf{x}^{\prime})=y\} \text{ s.t., }\|\mathbf{x}^{\prime}-\mathbf{x}\|_{\infty}\leq\epsilon,\quad (3.1)x′min?1{f(x′)=y}?s.t.,?∥x′?x∥∞?≤?,(3.1)
其中 ?\epsilon? 表示允許的最大擾動強度。指示函數 1{f(x′)=y}\mathbb{1}\{f(\mathbf{x}^{\prime})=y\}1{f(x′)=y} 難以優化,因此,[1, 7, 19, 20, 27, 46] 將 (3.1) 松弛為:
max?x′?(f(x′),y)s.t.,?∥x′?x∥∞≤?,(3.2)\max_{\mathbf{x}^{\prime}}\ell(f(\mathbf{x}^{\prime}),y)\text{ s.t., }\|\mathbf{x}^{\prime}-\mathbf{x}\|_{\infty}\leq\epsilon,\quad (3.2)x′max??(f(x′),y)?s.t.,?∥x′?x∥∞?≤?,(3.2)
其中 ?\ell? 表示替代損失函數(surrogate loss function),例如交叉熵損失(CrossEntropy loss)。另一方面,傳統的硬標簽攻擊 [9, 10] 將 (3.1) 重新表述為:
min?dg(d)其中?g(d)=argmin?r1{f(x+rd/∥d∥2)≠y}.(3.3)\min_{\mathbf{d}}g(\mathbf{d})\text{ 其中 }\;g(\mathbf{d})=\operatorname*{argmin}_{r}\mathbb{1}\{f(\mathbf{x}+r\mathbf{d}/\|\mathbf{d}\|_{2})\neq y\}.\quad (3.3)dmin?g(d)?其中?g(d)=rargmin?1{f(x+rd/∥d∥2?)=y}.(3.3)
這里 g(d)g(\mathbf{d})g(d) 表示從原始樣本 x\mathbf{x}x 沿光線方向 d\mathbf{d}d 到決策邊界的半徑(decision boundary radius),目標是找到關于原始樣本 x\mathbf{x}x 的最小決策邊界半徑。令 (r^,d^)(\widehat{\mathcal{r}},\widehat{\mathbf{d}})(r,d) 表示最小決策邊界半徑及其對應的光線方向。如果最小決策邊界半徑滿足 ∣r^d^/∥d^∥2∥∞≤?|\widehat{\mathcal{r}}\widehat{\mathbf{d}}/\|\widehat{\mathbf{d}}\|_{2}\|_{\infty }\leq\epsilon∣rd/∥d∥2?∥∞?≤?,它將被計為一次成功的攻擊。
雖然之前的工作 [9, 10] 試圖通過零階優化方法估計 g(d)g(\mathbf{d})g(d) 的梯度以連續方式解決問題 (3.3),但僅能訪問硬標簽的限制給解決 (3.3) 帶來了巨大挑戰。具體來說,估計決策邊界半徑 g(d)g(\mathbf{d})g(d) 通常需要一個二分搜索過程,而通過有限差分(finite difference)估計 g(d)g(\mathbf{d})g(d)的信息梯度需要多輪 g(d)g(\mathbf{d})g(d) 計算。此外,由于零階梯度估計過程中的方差很大,優化 (3.3) 通常需要大量的梯度步驟。這些因素加在一起,使得解決 (3.3) 比黑盒攻擊效率低得多,更不用說白盒攻擊了。
鑒于上述所有問題,我們轉向直接搜索最近的決策邊界,而無需估計任何梯度。
3.2 光線搜索方向
在有限次查詢下,不可能搜索整個連續的光線方向空間。因此,我們需要將搜索空間限制在一個離散的光線方向集合上,以使直接搜索成為可能。請注意,對 (3.2) 應用 FGSM 會在 L∞L_{\infty}L∞? 范數球的頂點(vertex)處產生最優解 [7, 28],這表明這些頂點可能為 (3.2) 提供可能的解。 [28] 中的經驗發現也表明,從 PGD 攻擊獲得的 (3.2) 的解大多位于 L∞L_{\infty}L∞? 范數球的頂點上。受此啟發,Moon 等人 [28] 將可行解集限制為 L∞L_{\infty}L∞? 范數球的頂點。遵循這一思路,由于我們的目標是獲得決策邊界半徑,我們考慮指向 L∞L_{\infty}L∞? 范數球頂點的光線方向,即 d∈{?1,1}d\mathbf{d}\in\{-1,1\}^{d}d∈{?1,1}d,其中 ddd 表示原始數據樣本x?\mathbf{x}^{\dagger}x? 的維度。因此,我們不解決 (3.3),而是轉向解決一個離散問題:
min?d∈{?1,1}dg(d)其中?g(d)=argmin?r1{f(x+rd/∥d∥2)≠y}.(3.4)\min_{\mathbf{d}\in\{-1,1\}^{d}}g(\mathbf{d})\text{ 其中 }\;g(\mathbf{d})=\operatorname*{argmin}_{r}\mathbb{1}\{f(\mathbf{x}+r\mathbf{d}/\|\mathbf{d}\|_{2})\neq y\}.\quad (3.4)d∈{?1,1}dmin?g(d)?其中?g(d)=rargmin?1{f(x+rd/∥d∥2?)=y}.(3.4)
在問題 (3.4) 中,我們將搜索空間從 Rd\mathbb{R}^{d}Rd 減少到 {?1,1}d\{-1,1\}^{d}{?1,1}d,它包含 2d2^{d}2d 個可能的搜索方向。
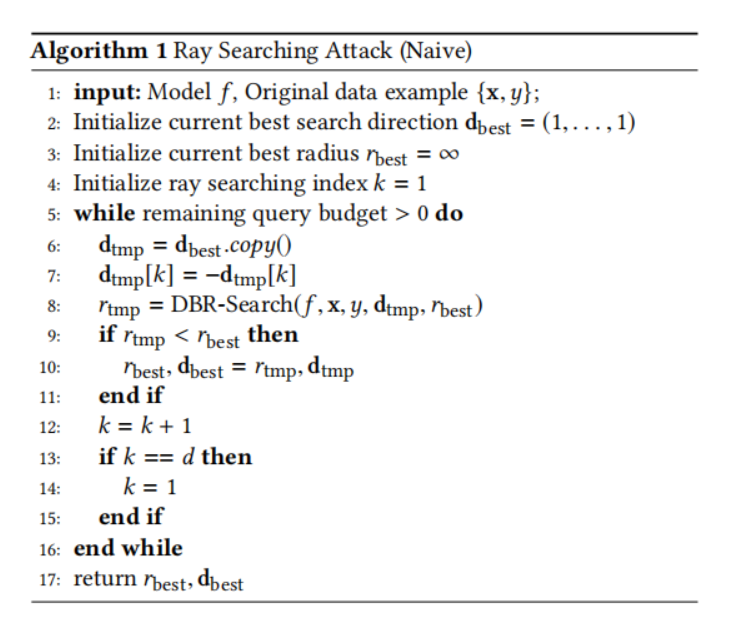
現在我們開始介紹我們提出的光線搜索攻擊。我們首先介紹光線搜索攻擊的樸素版本,總結在算法 1 中。具體來說,給定一個模型 fff 和一個測試樣本 {x,y}\{\mathbf{x},y\}{x,y},我們首先將最佳搜索方向初始化為一個全 1 向量,并將初始最佳半徑設置為無窮大。然后我們迭代地改變當前最佳光線方向每個維度的符號,并通過算法 2(稍后描述)測試這個修改后的光線方向是否能產生更好的決策邊界半徑。如果可以,我們就更新最佳搜索方向和最佳半徑;否則,它們保持不變。算法 1 是一個貪婪搜索算法(greedy search algorithm),用于尋找決策邊界半徑的局部最優值(local optima),其定義如下。
定義 3.1 (決策邊界半徑的局部最優). 一個光線方向d∈{?1,1}d\mathbf{d}\in\{-1,1\}^{d}d∈{?1,1}d 是關于 (3.4) 的決策邊界半徑的局部最優,如果對于所有滿足∥d′?d∥0≤1\|\mathbf{d}^{\prime}-\mathbf{d}\|_{0}\leq 1∥d′?d∥0?≤1 的d′∈{?1,1}d\mathbf{d}^{\prime}\in\{-1,1\}^{d}d′∈{?1,1}d,我們有 g(d)≤g(d′)g(\mathbf{d})\leq g(\mathbf{d}^{\prime})g(d)≤g(d′)。
定理 3.2. 給定足夠的查詢預算,令 (r^,d^)(\widehat{\mathcal{r}},\widehat{\mathbf{d}})(r,d) 是算法 1 的輸出,則 d^\widehat{\mathbf{d}}d 是決策邊界半徑問題 (3.4) 的局部最優解。
證明. 我們通過反證法證明。假設 d^\widehat{\mathbf{d}}d 不是局部最優解,那么一定存在某個d′\mathbf{d}^{\prime}d′ 滿足 ∥d′?d^∥0≤1\|\mathbf{d}^{\prime}-\widehat{\mathbf{d}}\|_{0}\leq 1∥d′?d∥0?≤1(即 d′\mathbf{d}^{\prime}d′ 與 d^\widehat{\mathbf{d}}d 最多在一個維度上不同),使得 g(d^)>g(d′)g(\mathbf{\widehat{d}})>g(\mathbf{d}^{\prime})g(d)>g(d′)。這意味著算法 1 仍然可以通過遍歷所有維度找到比 g(d^)g(\mathbf{\widehat{d}})g(d) 更好的解,因此 d^\widehat{\mathbf{d}}d 不會是算法 1 的輸出。這就導致了矛盾。
接下來我們介紹算法 2,它執行決策邊界半徑搜索。算法 2 的主體(第 7 行到第 12 行)是一個二分搜索算法(binary search algorithm),用于高精度定位決策邊界半徑。另一方面,第 7 行之前的步驟側重于決定搜索范圍以及我們是否需要搜索它(這是實現高效攻擊的關鍵)。具體來說,我們首先通過其 L2L_{2}L2? 范數對搜索方向進行歸一化。然后在第 3 行,我們在點 x+ηbest?dη2\mathbf{x}+\eta_{\mathrm{best}}\cdot\mathbf{d}_{\eta}{}^{2}x+ηbest??dη?2 處進行快速檢查,并決定是否需要對當前方向進一步執行二分搜索。為了幫助更好地理解底層機制,圖 1 提供了算法 2 第 3 行快速檢查步驟的二維示意圖。假設我們首先在當前最佳方向 dbest\mathbf{d}_{\mathrm{best}}dbest? 的第 1 維度改變符號,得到修改方向 dtmp1\mathbf{d}_{\mathrm{tmp1}}dtmp1?。快速檢查表明它是一個有效的攻擊,并且有潛力進一步減小決策邊界半徑。另一方面,如果我們改變 dbest\mathbf{d}_{\mathrm{best}}dbest? 在第 2 維度的符號,得到修改方向 dtmp2\mathbf{d}_{\mathrm{tmp2}}dtmp2?。快速檢查表明它不再是一個有效的攻擊,方向 dtmp2\mathbf{d}_{\mathrm{tmp2}}dtmp2? 的決策邊界半徑只能比當前的 ηbest\eta_{\mathrm{best}}ηbest? 更差。因此,我們跳過所有旨在估計更差決策邊界半徑的不必要查詢。請注意,在 Cheng 等人 [10] 中,也為輕微擾動的方向提出了類似的檢查。然而,他們將其用作梯度估計的符號,而我們根據檢查結果簡單地丟棄所有不滿足條件的半徑,從而獲得更好的效率。最后,我們解釋算法 2 中的第 6 行。
選擇min?(rbest,∣∣d∣∣2)\min(r_{\textup{best}},||\mathbf{d}||_{2})min(rbest?,∣∣d∣∣2?) 是因為初始 rbestr_{\textup{best}}rbest? 是 ∞\infty∞,在快速檢查通過的情況下,我們應該確保二分搜索范圍是有限的。


3.3 分層搜索
最近關于黑盒攻擊的工作[20, 28]發現,梯度的不同維度之間存在一定的空間相關性(spatial correlation),利用這種先驗知識可以幫助提高黑盒攻擊的效率。因此,他們在原始數據樣本上的小塊或圖像塊(tiles or image blocks)上添加相同的擾動以提高效率。受此發現的啟發,我們也通過設計光線搜索攻擊的分層搜索(hierarchical search)版本來利用這些空間相關性,如算法 3 所示。具體來說,我們添加一個新的階段變量 sss。在每個階段,我們將當前的搜索方向切割成2s2^{s}2s 個小塊,并在每次迭代中同時改變整個塊的符號作為修改后的光線搜索方向進行決策邊界半徑搜索。遍歷所有塊后,我們移動到下一階段并重復搜索過程。從經驗上講,算法 3 通過利用上述空間相關性極大地提高了搜索效率。我們在第 4 節中的所有實驗都是使用算法 3 進行的。注意,如果查詢預算足夠大,算法 3 最終會達到塊大小3等于 111 的情況,并最終退化為算法 1。3 為了完整性,當 2s2^{s}2s 大于數據維度 ddd 時,算法 3 將只將搜索方向向量 dtmp\mathbf{d}_{\textup{tmp}}dtmp? 劃分為 ddd 個塊,以確保每個塊至少包含一個維度。
注意,所有三個算法(算法 1, 2 和 3)除了最大查詢次數(這通常是一個預定義的問題相關參數)外,不涉及任何超參數。與之形成鮮明對比的是,典型的白盒攻擊和基于零階優化的黑盒攻擊需要調整相當多的超參數才能獲得良好的攻擊性能。
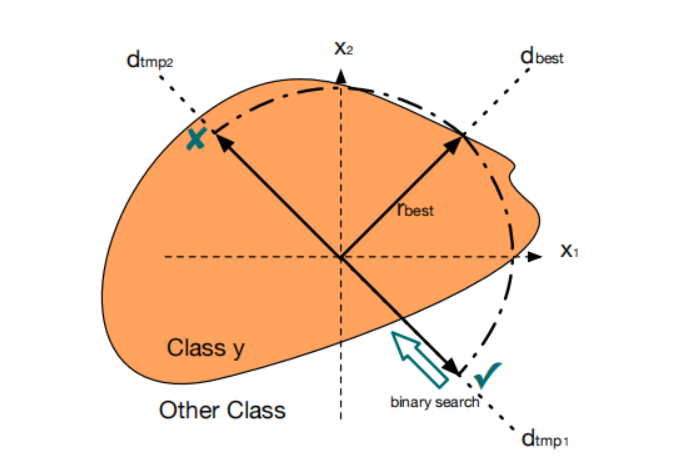
圖 1. 算法 2 中快速檢查步驟的二維示意圖。
4. 實驗
在本節中,我們展示了我們提出的光線搜索攻擊(RayS)的實驗結果。我們首先在自然訓練模型(naturally trained models)上使用其他硬標簽攻擊基線測試 RayS 攻擊,然后將 RayS 攻擊應用于最近提出的最先進的魯棒訓練模型(robust training models)以測試它們的性能。我們所有的實驗都是在 Python 3.6.9 平臺上使用 PyTorch 1.3.1 和 NVIDIA 2080 Ti GPU 進行的。
4.1 數據集和目標模型
我們在 MNIST [24]、CIFAR-10 [22] 和 ImageNet [11] 數據集上比較了所有攻擊算法的性能。遵循對抗樣本文獻[1, 19, 28],我們為 MNIST 數據集設置 ?=0.3\epsilon=0.3?=0.3,為 CIFAR-10 數據集設置?=0.031\epsilon=0.031?=0.031,為 ImageNet 數據集設置 ?=0.05\epsilon=0.05?=0.05。對于自然訓練模型,在 MNIST 數據集上,我們攻擊兩個預訓練的 7 層 CNN:4 個卷積層后接 3 個全連接層,每個卷積層后應用最大池化(Max-pooling)和 ReLU 激活。該 MNIST 預訓練模型在測試集上達到 99.5% 的準確率。在 CIFAR-10 數據集上,我們也使用一個 7 層 CNN 結構,包含 4 個卷積層和一個額外的 3 個全連接層,并帶有批歸一化(Batch-norm)和最大池化層。該 CIFAR-10 預訓練模型在測試集上達到 82.5% 的準確率。對于 ImageNet 實驗,我們攻擊預訓練的 ResNet-50 模型 [16] 和 Inception V3 模型 [37]。據報道,預訓練的 ResNet-50 模型具有 76.2% 的 top-1 準確率。預訓練的 Inception V3 模型據報道具有 78.0% 的 top-1 準確率。對于魯棒訓練模型,我們評估了兩個公認的防御方法:對抗訓練(Adversarial Training, AdvTraining)[27] 和 TRADES [46]。此外,我們還測試了另外三個最近提出的聲稱達到最先進魯棒精度的防御方法:Sensible Adversarial Training (SENSE) [21], Feature Scattering-based Adversarial Training (FeatureScattering) [44], Adversarial Interpolation Training (AdvInterpTraining) [45]。具體來說,對抗訓練[27]解決一個 min-max 優化問題以最小化對抗損失。Zhang 等人[46]研究了對抗訓練中魯棒性和準確性的權衡,并提出了一個經驗上更魯棒的模型。Kim 和 Wang [21] 提議在找到有效攻擊時停止攻擊生成。Zhang 和 Wang [44] 提出了一種無監督的特征散射(feature-scattering)方案用于攻擊生成。Zhang 和 Xu [45] 提出了一種對抗插值(adversarial interpolation)方案來生成對抗樣本以及對抗標簽(adversarial labels),并在這些樣本-標簽對上進行訓練。
4.2 基線方法
我們將提出的算法與幾種最先進的攻擊算法進行比較。具體來說:
- 對于攻擊自然訓練模型,我們將提出的 RayS 攻擊與其他硬標簽攻擊基線進行比較:(i) OPT 攻擊 [9], (ii) SignOPT 攻擊 [10], 和 (iii) HSJA 攻擊 [6]。我們采用 OPT、SignOPT 和 HSJA 攻擊原始論文中的相同超參數設置。
- 對于攻擊魯棒訓練模型,我們額外與其他最先進的黑盒攻擊甚至白盒攻擊進行比較:(i) PGD 攻擊 [27] (白盒), (ii) CW 攻擊 [5]? (白盒), (iii) SignHunter [1] (黑盒), 和 (iv) Square 攻擊 [2] (黑盒)。對于 PGD 攻擊和 CW 攻擊,我們將步長設置為 0.007,并提供 20 步和 100 步的攻擊結果。對于 SignHunter 和 Square 攻擊,我們采用其原始論文中使用的相同超參數設置。
? 準確地說,這里的 CW 攻擊指的是使用 CW 損失 [5] 進行 PGD 更新。
4.3 在自然訓練模型上與硬標簽攻擊基線的比較
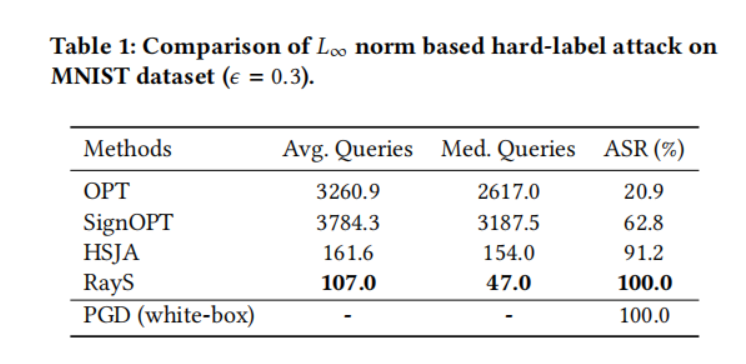
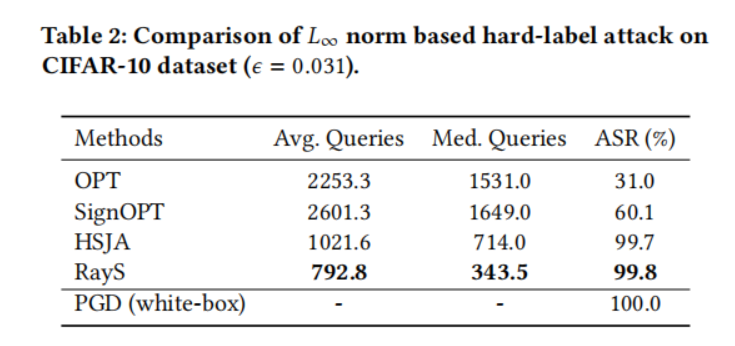
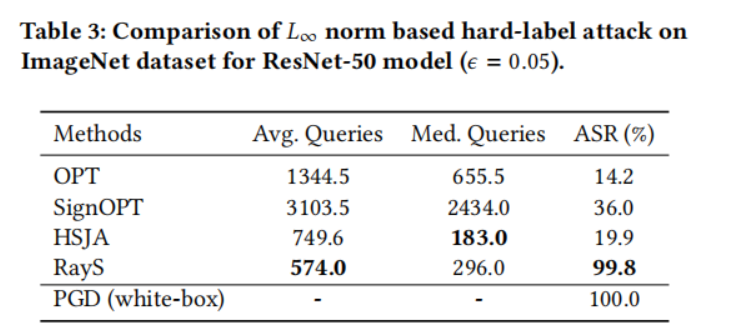
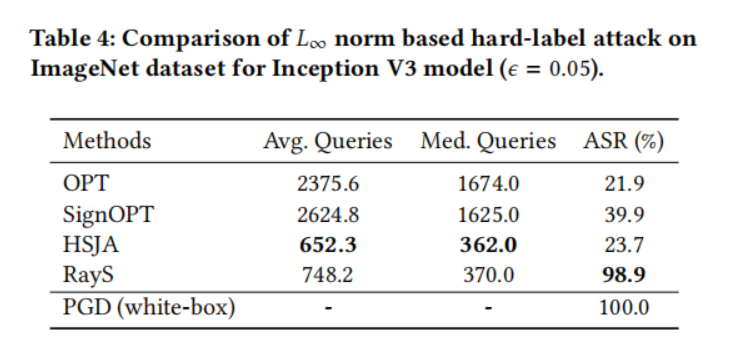
在本小節中,我們在自然訓練模型上將我們的光線搜索攻擊與其他硬標簽攻擊基線進行比較。對于每個數據集(MNIST、CIFAR-10 和 ImageNet),我們從其測試集中隨機選擇 1000 張被預訓練模型正確分類的圖片,并測試這些圖片中有多少張可以被硬標簽攻擊成功攻擊。對于每種方法,我們將最大查詢次數限制為 10000。為了提高查詢效率,一旦某個測試樣本被成功攻擊(即對抗樣本與原始樣本之間的 L∞L_{\infty}L∞? 范數距離小于預定義的擾動限制 ?\epsilon?),我們就停止對該樣本的攻擊。表 1、2、3 和 4 分別展示了所有硬標簽攻擊在 MNIST 模型、CIFAR-10 模型、ResNet-50 模型和 Inception V3 模型上的性能比較。對于每個實驗,我們報告每種攻擊成功所需的平均查詢次數(Avg. Queries)和中位數查詢次數(Med. Queries),以及最終攻擊成功率(ASR, Attack Success Rate),即成功攻擊次數占總攻擊嘗試次數的比例。具體來說:
- 在 MNIST 數據集上,我們觀察到我們提出的 RayS 攻擊在平均查詢次數和中位數查詢次數方面具有更好的查詢效率,并且比 OPT 和 SignOPT 方法具有更高的攻擊成功率。注意 SignOPT 的平均(中位數)查詢次數大于 OPT。然而,這并不意味著 SignOPT 比 OPT 表現更差。這個結果是由于 OPT 的攻擊成功率非常低,其平均(中位數)查詢次數是基于成功攻擊的樣本計算的,在這種情況下,這些樣本是最脆弱的樣本。HSJA 攻擊雖然比 SignOPT? 有所改進,但仍然落后于我們的 RayS 攻擊。
- 對于 CIFAR-10 模型,RayS 攻擊仍然達到了最高的攻擊成功率。盡管 HSJA 攻擊在攻擊成功率方面接近 RayS 攻擊,但其查詢效率仍然落后。
- 在 ResNet-50 和 Inception V3 模型上,只有 RayS 攻擊保持了較高的攻擊成功率,而其他基線則大幅落后。注意 HSJA 攻擊在 ImageNet 模型上實現了相似甚至略好的平均(中位數)查詢次數,這表明 HSJA 對于最脆弱的樣本是高效的,但在處理難以攻擊的樣本時效果不佳。
圖 2 顯示了在不同模型上,所有基線方法的攻擊成功率隨查詢次數變化的曲線圖。我們再次可以看到,與其他硬標簽攻擊基線相比,RayS 攻擊總體上實現了最高的攻擊成功率和最好的查詢效率。
? 原文此處為“SignOPT”,但根據上下文(CIFAR-10表2中HSJA成功率99.7% > SignOPT的60.1%),應為“OPT”。此處按原文翻譯。
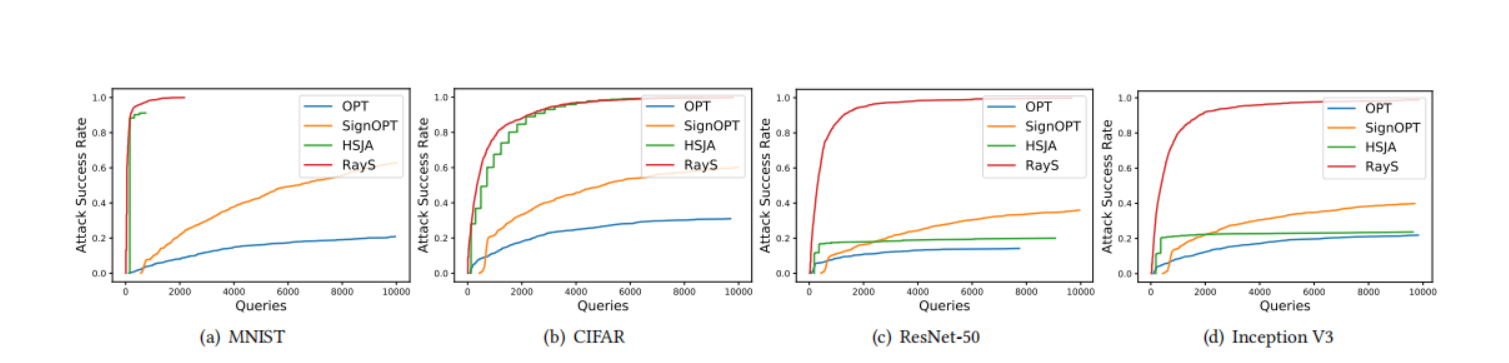
圖 2. MNIST、CIFAR-10 和 ImageNet 數據集上不同硬標簽攻擊的攻擊成功率隨查詢次數變化圖。
4.4 評估最先進魯棒模型的魯棒性
在本小節中,我們通過將我們提出的光線搜索攻擊應用于最先進的魯棒訓練模型來進一步測試它。具體來說,我們在 CIFAR-10 數據集和 WideResNet(Wu 等人, 2019)架構上選擇了五個最近提出的開源防御模型。對于測試樣本,我們從 CIFAR-10 測試集中隨機選擇 1000 張圖像。我們將最大查詢次數設置為 40000。
在評估指標方面,遵循魯棒訓練文獻(Zhang 等人, 2017; Wang 等人, 2018),我們報告防御模型的自然精度(natural accuracy)和魯棒精度(robust accuracy,即在對抗攻擊下的分類精度)。此外,我們報告了一個名為**平均決策邊界距離(Average Decision Boundary Distance, ADBD)**的新指標,它定義為所有測試樣本到其最近決策邊界的平均 L∞L_{\infty}L∞? 范數距離。注意,ADBD 對于遵循公式 (3.1) 的白盒和黑盒攻擊無效,因為它們無法為所有測試樣本找到最近的決策邊界。
這里我們想強調 ADBD 與對抗學習文獻中的平均 L∞L_{\infty}L∞? 失真(L∞L_{\infty}L∞? distortion)的區別。注意,L∞L_{\infty}L∞? 失真? 通常指的是成功的對抗攻擊樣本與其對應的原始干凈樣本之間的 L∞L_{\infty}L∞? 范數距離,因此,它受到最大擾動限制 ?\epsilon? 選擇的影響。對于硬標簽攻擊,只考慮半徑小于 ?\epsilon? 的攻擊會丟失太多信息,無法捕捉模型魯棒性的全貌?。另一方面,ADBD 指標雖然僅對硬標簽攻擊有效,但它提供了對原始干凈樣本到其決策邊界的平均距離的有意義估計。
? 在本實驗中測試的所有白盒和黑盒攻擊,它們的L∞L_{\infty}L∞? 失真都非常接近擾動限制?=0.031\epsilon=0.031?=0.031。因此,我們在表格中沒有報告 L∞L_{\infty}L∞? 失真,因為它沒有提供太多額外信息。
? 對于硬標簽攻擊,ADBD 值總是大于 L∞L_{\infty}L∞? 失真。
表 5、6、7、8 和 9 顯示了在五個選定的魯棒模型上不同對抗攻擊方法的比較結果。具體來說:
- 對于兩個公認的魯棒訓練模型,對抗訓練(表 5)和 TRADES(表 6),我們觀察到白盒攻擊仍然是最強的攻擊,其中 PGD 攻擊和 CW 攻擊實現了非常相似的攻擊性能。對于黑盒攻擊,
SignHunter 攻擊和 Square 攻擊實現了與其白盒對應物相似的攻擊性能。在硬標簽攻擊方面,我們提出的 RayS 攻擊在對目標模型訪問權限最嚴格的情況下,也實現了與黑盒甚至白盒攻擊相當的攻擊性能。當與其他硬標簽攻擊基線比較時,可以看出我們的 RayS 攻擊在魯棒精度(超過 20%)和平均決策邊界距離(減少 30%)方面都取得了顯著的性能提升。攻擊 L∞L_{\infty}L∞? 范數威脅模型的效果較差使得 SignOPT 攻擊和 HSJA 攻擊不太實用。
- 對于 Sensible Adversarial Training 模型(表 7),與對抗訓練和 TRADES 相比,它在白盒攻擊下確實實現了總體上更好的魯棒精度。對于黑盒攻擊,SignHunter 攻擊實現了與 PGD 攻擊相似的性能,Square 攻擊實現了與 CW 攻擊相似的性能。有趣的是,我們觀察到對于硬標簽攻擊,我們提出的 RayS 攻擊實現了 42.5% 的魯棒精度,比 PGD 攻擊降低了 20%,比 CW 攻擊降低了 15%,這表明 Sensible Adversarial Training 的魯棒性實際上并不比 TRADES 和對抗訓練更好,只是在 PGD 攻擊和 CW 攻擊下看起來更好。
- 對于基于特征散射的對抗訓練模型(Feature Scattering-based Adversarial Training,表 8),注意 CW 攻擊比 PGD 攻擊有效得多。同樣對于黑盒攻擊,Square 攻擊的性能比 SignHunter 攻擊好得多?,這表明在攻擊基于特征散射的對抗訓練模型時,CW 損失比交叉熵損失更有效。再次,我們可以觀察到我們提出的 RayS 攻擊將 PGD 攻擊的魯棒精度降低了 28%,將 CW 攻擊的魯棒精度降低了 10%。這也表明基于特征散射的對抗訓練模型并沒有真正提供比對抗訓練或 TRADES 更好的魯棒性。
- 對于對抗插值訓練模型(Adversarial Interpolation Training,表 9),在白盒攻擊下,它實現了驚人的高魯棒精度 75.3%(在 PGD 攻擊下)和 68.9%(在 CW 攻擊下),在相應的黑盒攻擊下也能獲得類似的結果。然而,在我們的 RayS 攻擊下,它仍然不是真正魯棒的,將 PGD 攻擊的魯棒精度降低了 28%,CW 攻擊降低了 22%。注意,在這個實驗中,HSJA 攻擊也實現了比 PGD 攻擊更低的魯棒精度,這表明所有硬標簽攻擊都可能具有檢測那些欺騙當前白盒/黑盒攻擊的虛假魯棒模型的潛力,但 HSJA 的低效率限制了其更廣泛使用的能力。
? Square 攻擊基于 CW 損失,而 SignHunter 攻擊基于交叉熵損失。
為了獲得五個選定的魯棒訓練模型在我們提出的 RayS 攻擊下魯棒性的總體比較,我們在圖 3 中繪制了平均決策邊界距離(ADBD)隨 RayS 攻擊迭代次數的變化圖,在圖 4 中繪制了魯棒精度隨 RayS 攻擊迭代次數的變化圖。首先,可以看出平均決策邊界距離和魯棒精度確實在大約 10000 次 RayS 攻擊迭代后收斂并保持穩定。圖 3 和圖 4 表明,在五個選定的魯棒訓練模型中,TRADES 和對抗訓練仍然是最魯棒的模型,而 Sensible Adversarial Training、Feature Scattering-based Adversarial Training 和 Adversarial Interpolation Training 在 PGD 攻擊和 CW 攻擊下表現出的魯棒性并不像它們看起來那樣好。還要注意,盡管 Sensible Adversarial Training、Feature Scattering-based Adversarial Training 和 Adversarial Interpolation Training 在 RayS 攻擊下的魯棒精度結果差異很大,但它們的 ADBD 結果非常相似。
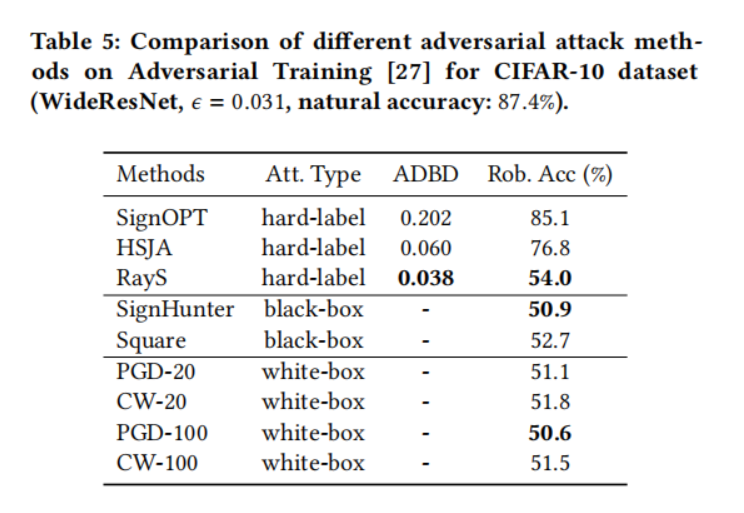
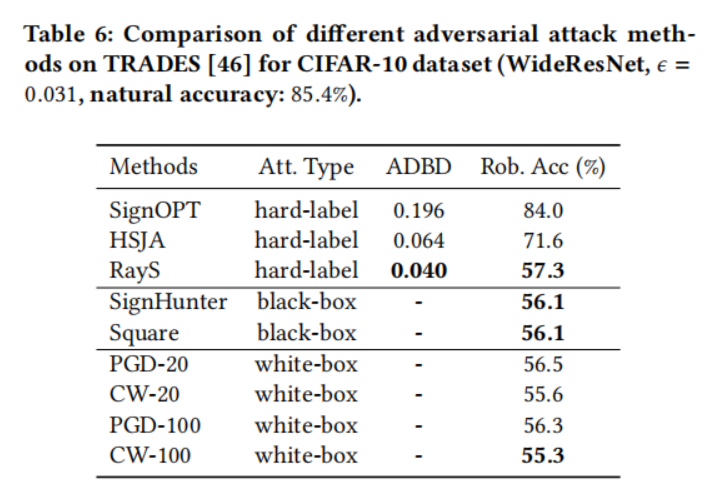
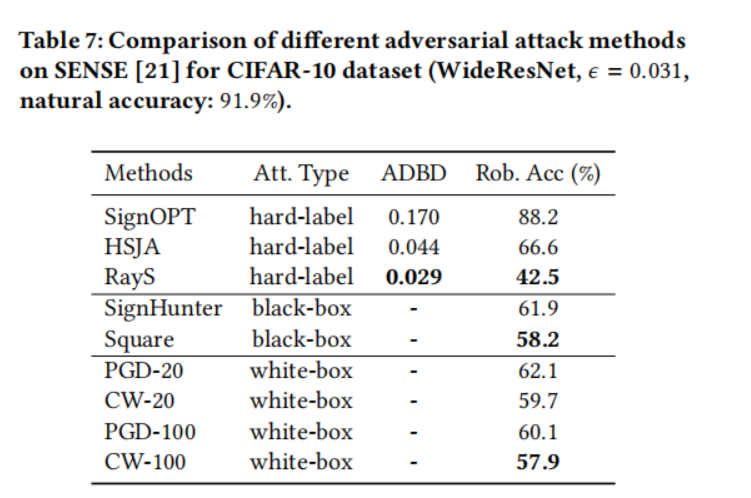
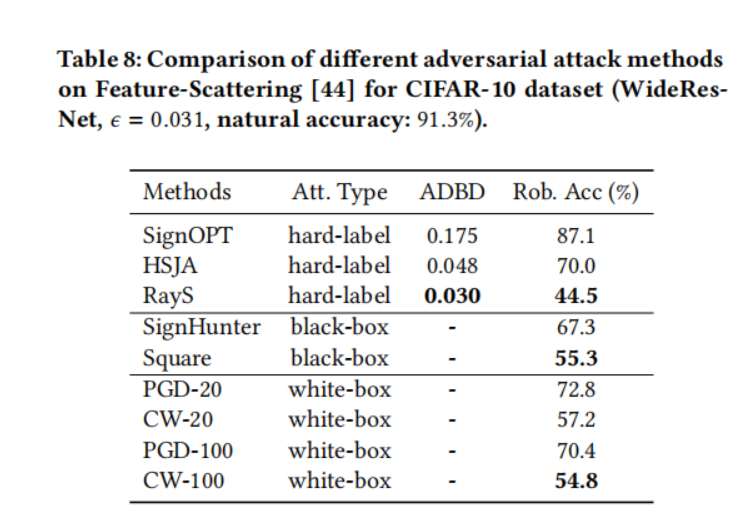
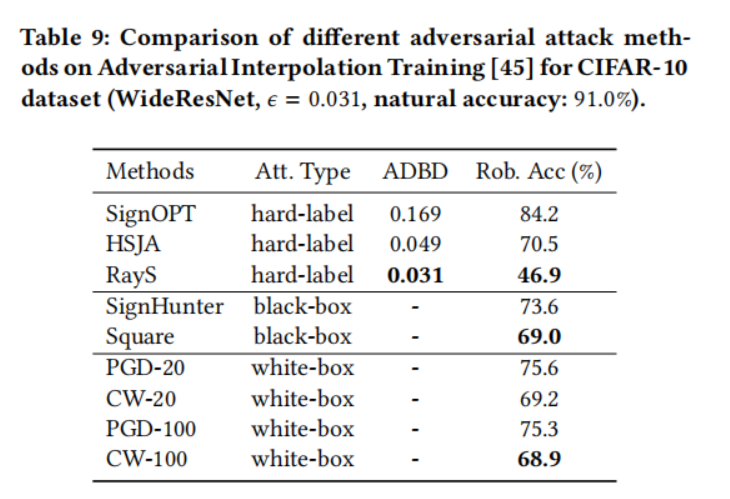
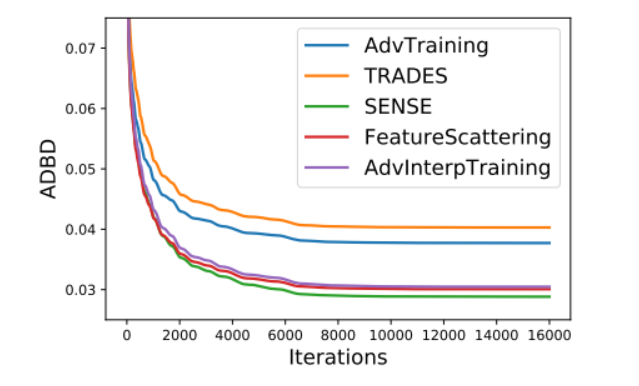
圖 3. 幾個魯棒模型的平均決策邊界距離(ADBD)隨 RayS 攻擊迭代次數變化圖。
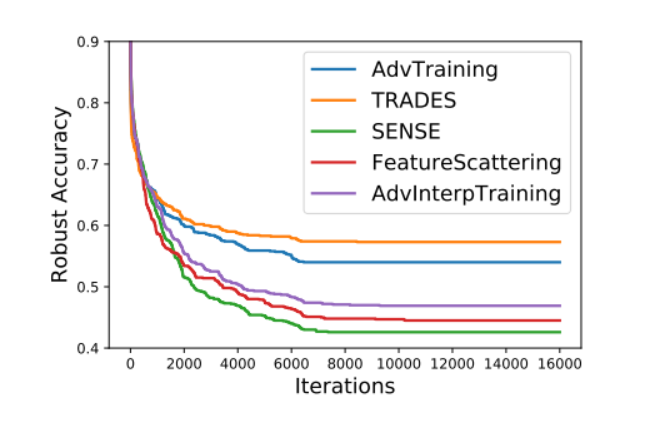
圖 4. 幾個魯棒模型的魯棒精度隨 RayS 攻擊迭代次數變化圖。
5. 討論與結論
在本文中,我們提出了光線搜索攻擊(Ray Searching attack),它只需要目標模型的硬標簽輸出。所提出的光線搜索攻擊在攻擊成功率方面比其他硬標簽攻擊更有效,在查詢復雜度方面也更高效。此外,它可以用作檢測可能欺騙當前白盒和黑盒攻擊的“虛假魯棒”模型的健全性檢查工具。
在下面的討論中,我們嘗試分析所提出的光線搜索攻擊成功的關鍵要素。
-
為什么 RayS 攻擊比其他硬標簽基線更有效和高效?
正如我們之前提到的,傳統的硬標簽攻擊更側重于 $L_{2} $ 范數威脅模型,只有少數擴展到 L∞L_{\infty}L∞? 范數威脅模型。而對于我們的 RayS 攻擊,我們基于 L∞L_{\infty}L∞? 范數威脅模型中的經驗發現,將尋找最近決策邊界的連續問題重新表述為一個離散問題,從而產生了一種更有效的硬標簽攻擊。另一方面,直接搜索最近決策邊界的策略加上快速檢查步驟,消除了不必要的搜索,顯著提高了攻擊效率。 -
為什么 RayS 攻擊可以檢測到可能的“虛假”魯棒模型,而傳統的白盒和黑盒攻擊不能?
我們從第 4 節觀察到的一件事是,盡管不同的攻擊導致不同的魯棒精度結果,但它們的攻擊性能與攻擊損失函數的選擇相關。例如,PGD 攻擊和 SignHunter 攻擊都利用交叉熵損失,在大多數情況下它們的攻擊性能相似。對于 CW 攻擊和 Square 攻擊(兩者都利用 CW 損失函數)也可以看到類似的效果。然而,這些損失函數被用作問題 (3.1) 的替代損失,它們可能無法真正反映中間樣本(一個靠近原始干凈樣本但還不是有效對抗樣本的樣本)的質量/潛力。例如,考慮這種情況:兩個中間樣本在真實類別 yyy 上具有相同的對數概率,但在其他類別上差異很大。在這種情況下,它們的交叉熵損失是相同的,但其中一個可能比另一個有更大的潛力發展成一個有效的對抗樣本(例如,第二大概率接近最大概率)。因此,交叉熵損失并不能真正反映中間樣本的真實質量/潛力。類似的情況也可以為 CW 損失構造。與之形成鮮明對比的是,我們的 RayS 攻擊將決策邊界半徑視為搜索準則2。當我們比較決策邊界上的兩個樣本時,顯然更近的那個更好。在攻擊問題難以解決且攻擊者容易陷入中間樣本的情況下(例如,攻擊魯棒訓練模型),很容易看出 RayS 攻擊有更好的機會找到成功的攻擊。這部分解釋了 RayS 攻擊在檢測“虛假魯棒”模型方面的優越性。
我們提出的光線搜索攻擊是硬標簽對抗攻擊領域的一個有前景的方向。它提供了一種高效、有效且易于使用的方法來評估模型在最嚴格的威脅模型下的魯棒性,并有助于揭示潛在的虛假魯棒性。
致謝
我們感謝匿名審稿人和高級程序委員會的寶貴意見。本研究部分由國家科學基金會 CIF-1911168、SaTC-1717950 和 CAREER Award 1906169 贊助。本文中包含的觀點和結論是作者的觀點和結論,不應被解釋為代表任何資助機構的觀點。
參考文獻
[1] Abdullah Al-Dujaili and Una-May O’Reilly. 2020. Sign Bits Are All You Need for
Black-Box Attacks. In International Conference on Learning Representations.
[2] Maksym Andriushchenko, Francesco Croce, Nicolas Flammarion, and Matthias
Hein. 2019. Square Attack: a query-efficient black-box adversarial attack via
random search. arXiv preprint arXiv:1912.00049 (2019).
[3] Anish Athalye, Nicholas Carlini, and David Wagner. 2018. Obfuscated Gradients
Give a False Sense of Security: Circumventing Defenses to Adversarial Examples.
In International Conference on Machine Learning.
[4] Wieland Brendel, Jonas Rauber, and Matthias Bethge. 2018. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models.
In International Conference on Learning Representations.
[5] Nicholas Carlini and David Wagner. 2017. Towards evaluating the robustness
of neural networks. In 2017 IEEE Symposium on Security and Privacy (SP). IEEE,
39–57.
[6] Jianbo Chen, Michael I Jordan, and Martin J Wainwright. 2019. Hopskipjumpattack: A query-efficient decision-based attack. arXiv preprint arXiv:1904.02144 3
(2019).
[7] Jinghui Chen, Dongruo Zhou, Jinfeng Yi, and Quanquan Gu. 2020. A Frank-Wolfe
framework for efficient and effective adversarial attacks. AAAI (2020).
[8] Pin-Yu Chen, Huan Zhang, Yash Sharma, Jinfeng Yi, and Cho-Jui Hsieh. 2017.
Zoo: Zeroth order optimization based black-box attacks to deep neural networks
without training substitute models. In Proceedings of the 10th ACM Workshop on
Artificial Intelligence and Security. ACM, 15–26.
[9] Minhao Cheng, Thong Le, Pin-Yu Chen, Huan Zhang, JinFeng Yi, and Cho-Jui
Hsieh. 2019. Query-Efficient Hard-label Black-box Attack: An Optimization-based
Approach. In International Conference on Learning Representations.
[10] Minhao Cheng, Simranjit Singh, Patrick H. Chen, Pin-Yu Chen, Sijia Liu, and
Cho-Jui Hsieh. 2020. Sign-OPT: A Query-Efficient Hard-label Adversarial Attack.
In International Conference on Learning Representations.
[11] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern
Recognition, 2009. CVPR 2009. IEEE Conference on. Ieee, 248–255.
[12] Guneet S Dhillon, Kamyar Azizzadenesheli, Zachary C Lipton, Jeremy Bernstein,
Jean Kossaifi, Aran Khanna, and Anima Anandkumar. 2018. Stochastic activation
pruning for robust adversarial defense. International Conference on Learning
Representations (2018).
[13] Ian J Goodfellow, Jonathon Shlens, and Christian Szegedy. 2015. Explaining and
harnessing adversarial examples. International Conference on Learning Representations (2015).
[14] Chuan Guo, Mayank Rana, Moustapha Cisse, and Laurens Van Der Maaten.
2018. Countering adversarial images using input transformations. International
Conference on Learning Representations (2018).
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual
learning for image recognition. In CVPR. 770–778.
[16] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Identity mappings
in deep residual networks. In European Conference on Computer Vision. Springer,
630–645.
[17] Geoffrey Hinton, Li Deng, Dong Yu, George Dahl, Abdel-rahman Mohamed,
Navdeep Jaitly, Andrew Senior, Vincent Vanhoucke, Patrick Nguyen, Brian Kingsbury, et al. 2012. Deep neural networks for acoustic modeling in speech recognition. IEEE Signal processing magazine 29 (2012).
[18] Weiwei Hu and Ying Tan. 2017. Generating adversarial malware examples for
black-box attacks based on GAN. arXiv preprint arXiv:1702.05983 (2017).
[19] Andrew Ilyas, Logan Engstrom, Anish Athalye, Jessy Lin, Anish Athalye, Logan
Engstrom, Andrew Ilyas, and Kevin Kwok. 2018. Black-box Adversarial Attacks
with Limited Queries and Information. In Proceedings of the 35th International
Conference on Machine Learning.
[20] Andrew Ilyas, Logan Engstrom, and Aleksander Madry. 2019. Prior convictions:
Black-box adversarial attacks with bandits and priors. International Conference
on Learning Representations (2019).
[21] Jungeum Kim and Xiao Wang. 2020. Sensible adversarial learning. https:
//openreview.net/forum?id=rJlf_RVKwr
[22] Alex Krizhevsky, Geoffrey Hinton, et al. 2009. Learning multiple layers of features
from tiny images. (2009).
[23] Alexey Kurakin, Ian Goodfellow, and Samy Bengio. 2016. Adversarial examples
in the physical world. arXiv preprint arXiv:1607.02533 (2016).
[24] Yann LeCun, Corinna Cortes, and CJ Burges. 2010. MNIST handwritten digit
database. (2010).
[25] Yandong Li, Lijun Li, Liqiang Wang, Tong Zhang, and Boqing Gong. 2019. NATTACK: Learning the Distributions of Adversarial Examples for an Improved
Black-Box Attack on Deep Neural Networks. In International Conference on Machine Learning. 3866–3876.
[26] Xingjun Ma, Bo Li, Yisen Wang, Sarah M Erfani, Sudanthi Wijewickrema, Grant
Schoenebeck, Dawn Song, Michael E Houle, and James Bailey. 2018. Characterizing adversarial subspaces using local intrinsic dimensionality. International
Conference on Learning Representations (2018).
[27] Aleksander Madry, Aleksandar Makelov, Ludwig Schmidt, Dimitris Tsipras, and
Adrian Vladu. 2018. Towards deep learning models resistant to adversarial attacks.
International Conference on Learning Representations (2018).
[28] Seungyong Moon, Gaon An, and Hyun Oh Song. 2019. Parsimonious Black-Box
Adversarial Attacks via Efficient Combinatorial Optimization. In International
Conference on Machine Learning. 4636–4645.
[29] Seyed-Mohsen Moosavi-Dezfooli, Alhussein Fawzi, and Pascal Frossard. 2016.
Deepfool: a simple and accurate method to fool deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2574–
2582.
[30] Nicolas Papernot, Patrick McDaniel, and Ian Goodfellow. 2016. Transferability
in machine learning: from phenomena to black-box attacks using adversarial
samples. arXiv preprint arXiv:1605.07277 (2016).
[31] Nicolas Papernot, Patrick McDaniel, Ian Goodfellow, Somesh Jha, Z Berkay
Celik, and Ananthram Swami. 2017. Practical black-box attacks against machine
learning. In Proceedings of the 2017 ACM on Asia Conference on Computer and
Communications Security. ACM, 506–519.
[32] Nicolas Papernot, Patrick McDaniel, Somesh Jha, Matt Fredrikson, Z Berkay Celik,
and Ananthram Swami. 2016. The limitations of deep learning in adversarial
settings. In Security and Privacy (EuroS&P), 2016 IEEE European Symposium on.
IEEE, 372–387.
[33] Nicolas Papernot, Patrick McDaniel, Xi Wu, Somesh Jha, and Ananthram Swami.
2016. Distillation as a defense to adversarial perturbations against deep neural
networks. In 2016 IEEE Symposium on Security and Privacy (SP). IEEE, 582–597.
[34] Pouya Samangouei, Maya Kabkab, and Rama Chellappa. 2018. Defense-gan:
Protecting classifiers against adversarial attacks using generative models. International Conference on Learning Representations (2018).
[35] Yang Song, Taesup Kim, Sebastian Nowozin, Stefano Ermon, and Nate Kushman.
2018. Pixeldefend: Leveraging generative models to understand and defend
against adversarial examples. International Conference on Learning Representations
(2018).
[36] Ilya Sutskever, Geoffrey E Hinton, and A Krizhevsky. 2012. Imagenet classification with deep convolutional neural networks. Advances in neural information
processing systems (2012), 1097–1105.
[37] Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew
Wojna. 2016. Rethinking the inception architecture for computer vision. In
Proceedings of the IEEE conference on computer vision and pattern recognition.
2818–2826.
[38] Christian Szegedy, Wojciech Zaremba, Ilya Sutskever, Joan Bruna, Dumitru Erhan,
Ian Goodfellow, and Rob Fergus. 2013. Intriguing properties of neural networks.
arXiv preprint arXiv:1312.6199 (2013).
[39] Jonathan Uesato, Brendan Oa??Donoghue, Pushmeet Kohli, and Aaron Oord.
2018. Adversarial Risk and the Dangers of Evaluating Against Weak Attacks. In
International Conference on Machine Learning. 5025–5034.
[40] Yisen Wang, Xingjun Ma, James Bailey, Jinfeng Yi, Bowen Zhou, and Quanquan
Gu. 2019. On the Convergence and Robustness of Adversarial Training. In
International Conference on Machine Learning. 6586–6595.
[41] Yisen Wang, Difan Zou, Jinfeng Yi, James Bailey, Xingjun Ma, and Quanquan
Gu. 2020. Improving Adversarial Robustness Requires Revisiting Misclassified
Examples. In International Conference on Learning Representations.
[42] Cihang Xie, Jianyu Wang, Zhishuai Zhang, Zhou Ren, and Alan Yuille. 2018.
Mitigating adversarial effects through randomization. International Conference
on Learning Representations (2018).
[43] Sergey Zagoruyko and Nikos Komodakis. 2016. Wide residual networks. arXiv
preprint arXiv:1605.07146 (2016).
[44] Haichao Zhang and Jianyu Wang. 2019. Defense against adversarial attacks using
feature scattering-based adversarial training. In Advances in Neural Information
Processing Systems. 1829–1839.
[45] Haichao Zhang and Wei Xu. 2020. Adversarial Interpolation Training: A Simple
Approach for Improving Model Robustness. https://openreview.net/forum?id=
Syejj0NYvr
[46] Hongyang Zhang, Yaodong Yu, Jiantao Jiao, Eric Xing, Laurent El Ghaoui, and
Michael Jordan. 2019. Theoretically Principled Trade-off between Robustness
and Accuracy. In International Conference on Machine Learning. 7472–7482.




)














