Python 線性回歸詳解:從原理到實戰
線性回歸(Linear Regression)是機器學習中最基礎也是最重要的算法之一,廣泛應用于預測分析領域,例如房價預測、銷售額預測等。本文將帶你從理論出發,用 Python 手把手實現線性回歸,助你邁出機器學習實戰第一步。
一、線性回歸是什么?
線性回歸是一種用于預測目標變量(因變量)與一個或多個特征變量(自變量)之間關系的模型,其核心思想是擬合一條“最佳直線”:
y=w1?x1?+w2?x2?+?+wn?xn?+b
其中:
y:預測值
x1?,x2?,…,xn:特征
w1?,w2?,…,wn?:系數(權重)
b:截距項
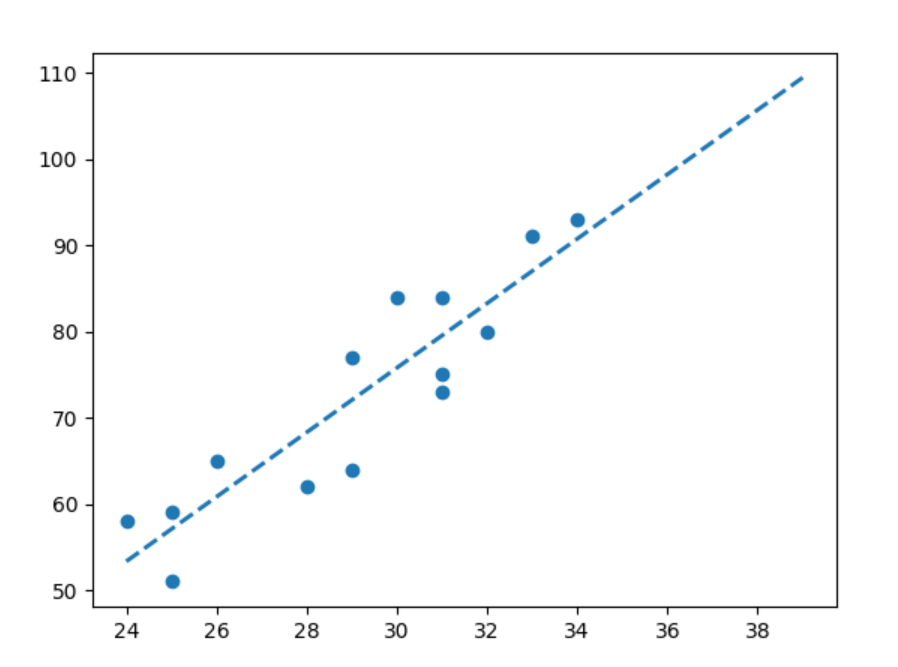
二、使用 sklearn 實現一元線性回歸
我們從簡單的一元線性回歸入手,使用 scikit-learn 庫實現。
先創建一個csv數據:
import csv# 數據
data = [["廣告投入", "銷售額"],[29, 77],[28, 62],[34, 93],[31, 84],[25, 59],[29, 64],[32, 80],[31, 75],[24, 58],[33, 91],[25, 51],[31, 73],[26, 65],[30, 84]
]# 創建 CSV 文件并寫入數據
with open('test1.csv', 'w', newline='', encoding='utf-8') as csvfile:writer = csv.writer(csvfile)writer.writerows(data)
實現一元線性回歸:
此代碼看似長,其實是因為打印了很多數據和注釋,為了讓初學者加深了解。
實際作用代碼就幾行
import pandas as pd
from sklearn.linear_model import LinearRegression
import numpy as npdata = pd.read_csv("data.csv")
# 準備訓練數據:X為特征矩陣(所有列除了"銷售額"),y為目標變量("銷售額")
X = data.drop("銷售額",axis=1) # 特征矩陣
y = data[["銷售額"]] # 目標變量# 創建線性回歸模型實例
# 使用特征矩陣X和目標變量y訓練線性回歸模型
lr_model = LinearRegression()
lr_model.fit(X,y)# 計算"廣告投入"和"銷售額"兩列之間的相關系數矩陣
corr = data[["廣告投入","銷售額"]].corr() # 關系系數矩陣
print(corr)
print("-----")# 計算模型在訓練數據上的擬合優度(R2值),評估模型性能
score = lr_model.score(X,y)
print(f"模型擬合優度(R2): {score}")# 獲取模型參數:a為自變量系數(斜率),b為截距(偏置)
a = lr_model.coef_
b = lr_model.intercept_
print(f"自變量系數: {a}")
print(f"截距: {b}")# 打印線性回歸方程
print(f"線性回歸模型為: y = {a[0][0]:.2f}x1 + {b[0]:.2f}")# 預測廣告投入為28時的銷售額
print(f"當廣告投入為28時,預測銷售額為: {lr_model.predict([[28]])}")import matplotlib.pyplot as plt
# 生成用于繪制回歸線的新數據點(廣告投入范圍從24到39)
# 使用模型預測新數據點對應的銷售額
x_new = np.arange(20, 40).reshape(-1, 1)
y_new = lr_model.predict(x_new)
# 繪制回歸線
plt.plot(x_new, y_new, '--', color='#1F77B4', linewidth=2)
# 繪制散點圖
plt.scatter(X,y)
plt.show()三、多元線性回歸示例
如果有多個特征變量:
創建數據:
import csvdata = [["體重", "年齡", "血壓收縮"],[76.0, 50, 120],[91.5, 20, 141],[85.5, 20, 124],[82.5, 30, 126],[79.0, 30, 117],[80.5, 50, 125],[74.5, 60, 123],[79.0, 50, 125],[85.0, 40, 132],[76.5, 55, 123],[82.0, 40, 132],[95.0, 40, 155],[92.5, 20, 147]
]with open('test2.csv', 'w', newline='') as csvfile:writer = csv.writer(csvfile)writer.writerows(data)多元線性回歸示例:
import pandas as pd
from sklearn.linear_model import LinearRegression# 導入數據
data = pd.read_csv("test2.csv", encoding='gbk', engine='python')# 打印相關系數矩陣
corr = data[["體重", "年齡", "血壓收縮"]].corr()
print("相關系數矩陣:")
print(corr)# 第二步,估計模型參數,建立回歸模型
lr_model = LinearRegression()
x = data[['體重', '年齡']]
y = data['血壓收縮']# 訓練模型
lr_model.fit(x, y)# 第四步,對回歸模型進行檢驗
score = lr_model.score(x, y) # 利用 score 方法獲取模型擬合優度(R2)
print("模型擬合優度(R2):", score)# 第五步,利用回歸模型進行預測
print("預測結果 1:", lr_model.predict([[80, 60]]))
print("預測結果 2:", lr_model.predict([[70, 30], [70, 20]]))# 獲取自變量系數和截距
a = lr_model.coef_
b = lr_model.intercept_
print("線性回歸模型為: y = {:.2f}x1 + {:.2f}x2 + {:.2f}".format(a[0], a[1], b))
四、模型評估:R2 分數
線性回歸模型的評估通常使用決定系數 R2:
r2 = model.score(X, y)
print(f"模型 R2 分數: {r2:.2f}")
R2=1:完美預測
R2=0:模型沒有預測能力
R2<0:預測還不如使用平均值
五、相關系數矩陣
相關系數矩陣(Correlation Matrix)是描述多個變量之間兩兩線性相關程度的矩陣,通常使用皮爾遜相關系數(Pearson Correlation Coefficient)來衡量。
一、皮爾遜相關系數公式
皮爾遜相關系數 rrr 公式如下:
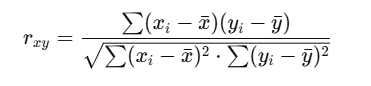
其取值范圍為:
r=1:完全正相關
r=?1:完全負相關
r=0:無線性關系
二、相關系數的解釋
| 相關系數范圍 | 線性相關強度 | 解釋 |
|---|---|---|
| 0.9 ~ 1.0 | 極強正相關 | 幾乎嚴格線性關系 |
| 0.7 ~ 0.9 | 強正相關 | 明顯線性趨勢 |
| 0.5 ~ 0.7 | 中等正相關 | 有一定線性趨勢 |
| 0.3 ~ 0.5 | 弱正相關 | 稍有線性趨勢 |
| 0.0 ~ 0.3 | 極弱或無相關 | 幾乎無線性關系 |
| < 0 | 負相關 | 越小,反向關系越強 |
六、幾點注意事項
特征縮放:當特征尺度差異較大時,應使用
StandardScaler進行歸一化或標準化。共線性問題:特征之間高度相關可能導致模型不穩定。
異常值:極端值會顯著影響回歸線。
殘差分析:擬合后應分析殘差是否符合正態分布。
七、總結
線性回歸是回歸分析的入門基礎;
使用
sklearn.linear_model.LinearRegression可以快速構建模型;可以可視化預測結果和分析模型性能;
推薦在實際應用中注重數據預處理、特征選擇與殘差分析。
)




)




)








