一、TL;DR
- 現在的做法有什么問題?主流范式是 “一個類別標簽對應多個錄音”,需要提前標注+預測預先定義的類別,只能做閉集理解,失去靈活性?
- 我們怎么做?通過兩個編碼器和對比學習機制建立語言與音頻的關聯,將音頻和文本描述映射到一個聯合的多模態空間進行對齊
- 做得怎么樣?12.8 萬對音頻 - 文本訓練,在8 個領域的 16 項下游任務中評估,即使訓練數據小于CV模型,Zero-Shot上達到了SoTA。finetune后在5項評估任務中也是SOTA
- 能做什么?消除了對類別標簽訓練的依賴,在推理時靈活預測類別,并能泛化到多個下游任務
- 對應的鏈接:
- paper:https://arxiv.org/pdf/2206.04769v1
-
code:https://github.com/LAION-AI/CLAP
-
?code:https://github.com/microsoft/CLAP
二、方法
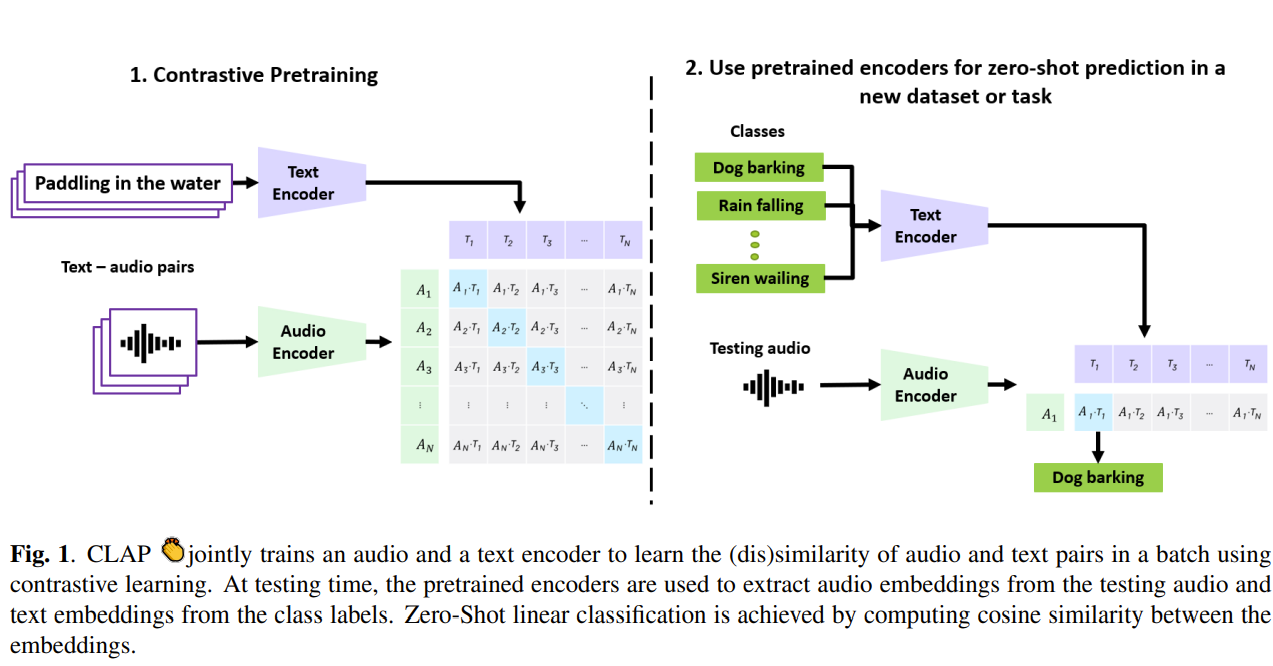
CLAP 的結構如圖 1 所示:
- 輸入為音頻和文本對,分別傳入音頻編碼器和文本編碼器。兩種表示通過線性投影映射到聯合多模態空間中,
- 該空間通過batch中音頻 - 文本對的(不)相似性,利用對比學習進行學習。
- 預訓練的編碼器及其MLP層可用于計算音頻和文本embedding,從而實現zero-shot分類。
2.1 對比語言 - 音頻預訓練
2.1.1 特征提取

2.1.2 線性變化

2.1.3 計算相似性

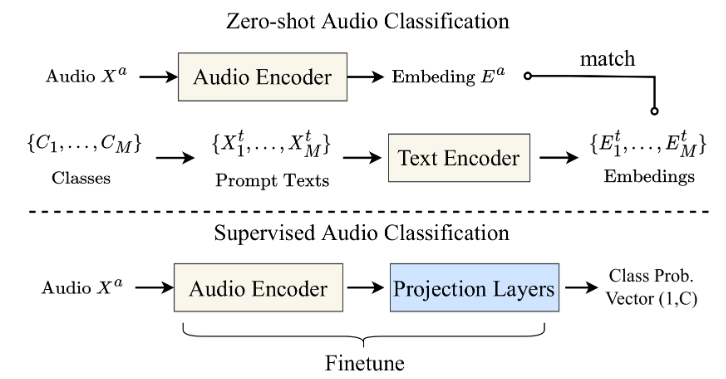
2.2 zero-shot線性分類
對于零樣本分類,利用 CLAP 判斷音頻與文本相似性的能力。考慮一個包含C個類別標簽和N個測試音頻的目標數據集:
- 首先,使用預訓練的編碼器及其投影層,計算N個音頻的音頻嵌入和C個類別的文本嵌入;
- 由于兩種嵌入處于同一空間,計算每個測試音頻與所有類別標簽的余弦相似度,每個音頻將獲得與類別標簽數量相同的 logits;
- 對 logits 應用 softmax 函數(適用于二分類或多分類任務)或 sigmoid 函數(適用于多標簽分類任務),將其轉換為概率分布。
三、Experiments
3.1 數據集
訓練數據:從4 個數據集中選取了12.8萬對音頻 - 文本數據對構建 CLAP 的訓練集,具體包括:
- 從 FSD50k 中提取 36,796 對,從 ClothoV2 ?中提取 29,646 對,從 AudioCaps 中提取 44,292 對,從 MACS中提取 17,276 對。數據集詳細信息見附錄 A 和表 4。
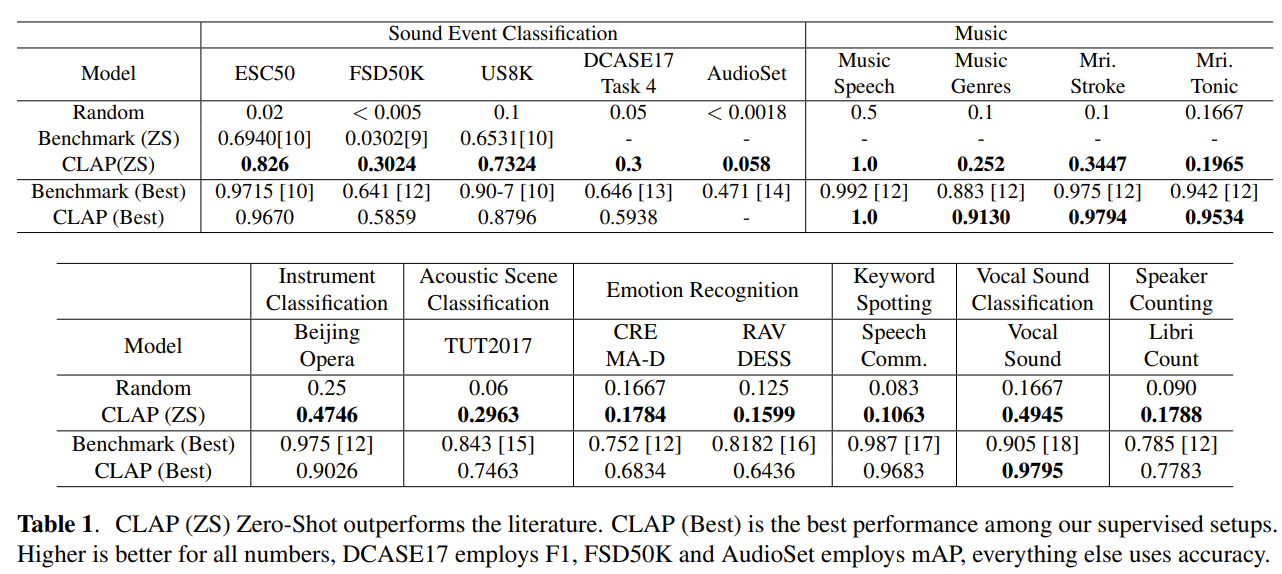
下游任務:我們選取了 8 個領域的 16 個數據集作為下游任務,包括:
- 5 項聲音事件分類任務;
- 5 項音樂相關任務(音樂與語音分類、音樂流派分類、音樂節拍與調性分類等);
- 1 項聲學場景分類任務;
- 4 項語音相關任務(情感識別、關鍵詞識別、人聲分類(如咳嗽、噴嚏、笑聲等));
- 1 項說話人計數任務(統計錄音中 0-10 人的說話人數)。
數據集信息見表 1,詳細說明見附錄 B 和表 5。
3.2 實驗設置
預處理:音頻采用對數梅爾頻譜表示,采樣率為 44.1 kHz,跳步大小為 320 秒,窗口大小為 1024 秒,梅爾 bins 數量為 64,頻率范圍為 50-8000 Hz。訓練時,每個音頻片段隨機截斷為 5 秒的連續片段,若長度不足則進行填充。文本描述未做修改,訓練時音頻 - 文本對按批次隨機采樣。
編碼器:
- 音頻編碼器選用 CNN14 ,以便與現有最優模型公平對比。該模型含 8080 萬參數,嵌入維度為 2048,已在 AudioSet 的 200 萬音頻片段上預訓練。
- 文本編碼器選用 BERT,采用 HuggingFace實現的 BERT-base-uncased 版本,含 1.1 億參數。為提高計算效率,文本序列最大長度限制為 100 字符,取 BERT 最后一層的 [CLS] token 作為文本嵌入(維度 768)。
音頻嵌入和文本嵌入通過兩個可學習的投影矩陣映射到維度為 1024 的多模態空間中。溫度參數 τ 為可學習參數,初始值設為 0.007;為避免訓練不穩定,經 τ 縮放后的 logits 最大值被限制為 100。
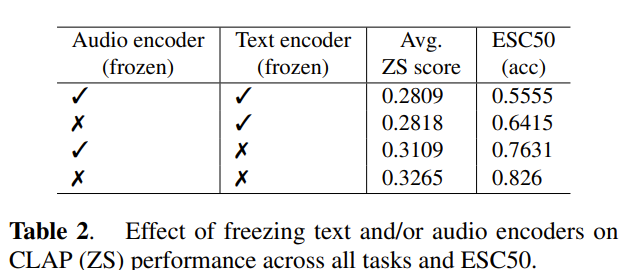
微調時候固定text/audio encoder參數對表現的影響:
3.3 CLAP 的評估設置
零樣本評估:驗證 CLAP 對未見過的類別和音頻的泛化能力,具體設置見 2.2 節。評估時不直接使用類別標簽,而是構建自然語言提示模板:“This is a sound of [class label]”。除 3 個任務外,所有領域均使用統一模板:
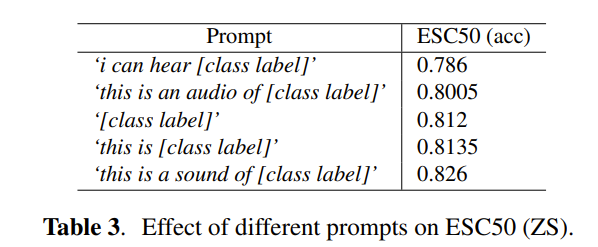
- 情感識別任務使用:“this person is feeling [class label]”;
- 關鍵詞識別任務直接使用關鍵詞作為文本;
- 說話人計數任務使用:“[number between 0-10] persons speaking”。
有監督特征提取評估:驗證 CLAP 學習的音頻表示質量。針對下游任務,將 CLAP 作為特征提取器,后續接 1 層或 3 層全連接分類器(分別記為 Freeze L1 和 Freeze L3),參考 [23] 的設置。訓練采用 Adam 優化器,學習率 10?3,訓練 30 個 epoch。受計算資源限制,未進行超參數網格搜索。
有監督微調評估:對比 CLAP 與文獻中各任務的最優性能。針對下游任務,解凍音頻編碼器并與附加的 1 層或 3 層全連接分類器共同微調,優化器為 Adam,學習率 10??,訓練 30 個 epoch。受計算資源限制,未進行超參數網格搜索。







)





持續報異常)
》免費中文翻譯 (第2章) --- Workflow: basics)


(二))
--4、權限維持(2))
