Transformer架構圖

?transformer整體架構
1. Transformer 的參數配置
Transformer 的Encoder層和Decoder層都使用6個注意力模塊,所有的子網絡的輸出維度均為512維,多頭注意力部分使用了8個注意力頭。
2. 歸一化的方式
歸一化的方式為LayerNorm,因為當時18年還沒有其他更好的歸一化方式,LayerNorm是對同一個樣本的特征進行標準化,從而保證模型訓練時不同網絡層的輸入輸出分布的穩定,從而加速訓練。
3. 注意力得分的計算為什么要除

因為不除的話會導致梯度消失的問題。
- 當兩個分布為(均值=0,方差=1)的向量相乘時,其內積的結果的分布為(均值=0,方差=d),其中d是向量的維度,這就導致注意力分數中可能出現一些非常大的值,這種大值會在softmax中占據主導地位。
- softmax的計算公式為:

其梯度的計算公式為:

這里可以看出,一旦softmax處理的向量的某一項的值很大,那么softmax的結果對原向量的每一個輸入x的梯度都會趨近于0,因為如果softmax(x_i) -> 1,那么其他的softmax(x_j) 就趨近于0了,在梯度公式里面無論哪一種情況都會導致梯度計算趨近于0,最終引起梯度消失,導致訓練困難。
4. 什么是長程依賴問題?
長程依賴問題是說當輸入序列很長時,模型難以記住序列早期的關鍵信息,導致輸出時模型忘記這些關鍵內容。
RNN和LSTM是因為把長上下文壓縮成一個或兩個固定大小的向量,從而難以表示上下文中所有的關鍵信息,才導致了長程依賴問題。
5. Self-Attention中Dropout層的作用
Dropout層用于增強模型的泛化能力,防止模型過擬合。
具體來說:Dropout層是隨機將目前的隱藏層中的值(即神經元的輸出)以一定概率置為0丟棄。
Dropout一般運用在注意力得分矩陣,FeedForward輸出,和殘差連接之前。
通過Dropout,可以防止模型過度關注某些節點的輸出。
6. 多頭注意力中最后一層線性層的作用是什么
由于多頭注意力里面每個頭的value是獨立計算的,計算過程彼此之間并沒有任何交互,也沒有任何信息傳遞,所以通過一個線性層來讓不同的注意力頭的輸出結果相連,從而彼此之間有信息交互。

7.?Position Encoding位置編碼專題
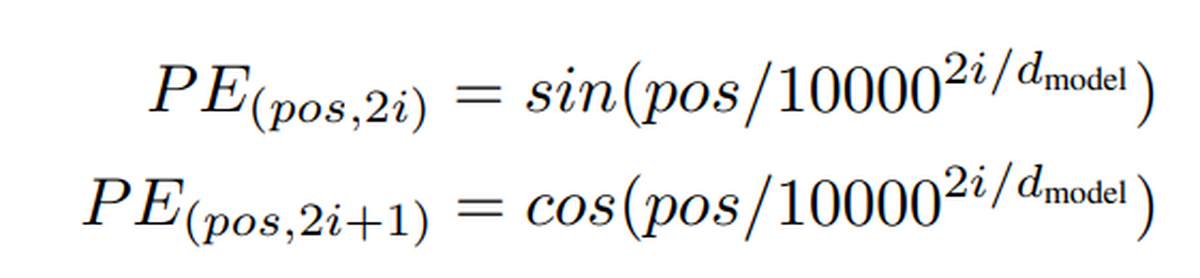

1)位置編碼的目的和設計要求
由于self-attention機制利用的是全局的token信息,token和token的先后順序性就丟失了,所以需要用一種方式來描述token之間的相對位置,于是transformer采用了位置編碼的方式,位置編碼函數的設計需要保證以下幾點:
- 模型能夠利用位置編碼的信息間接捕獲到token之間的相對位置或絕對位置
- 不同位置的token的位置編碼不能相同
- 位置編碼函數不能是隱函數
2)位置編碼為什么采用三角函數?
因為位置編碼是被加到嵌入中的,在后面的注意力計算中不同的token之間會有乘積運算,所以這里的位置編碼在不同的token之間會有乘積的運算,而三角函數的積化和差公式則可以很好的建模這種內積到位置差的關系。
![]()
3)既然一個cos和sin就已經能夠表達積化和差了,那直接用位置i交替使用cos i, sin i,cos i,sin i編碼不就行了嗎,為什么要設計不同頻率的系數?
因為如果只有一種頻率,模型其實是無法解構出真正的相對位置關系的,因為模型只能拿到內積的計算結果,假定為一個值v,這個v實際上等于cos(a-b+k*T),其中T為三角函數的周期,由于三角函數的周期性,這里沒辦法定位到真正的a-b那個解,所以通過不同的頻率來求解到真正的相對位置解。所以在位置編碼中,pos不變,隨著i的增大,三角函數的周期在變大,且不同的i能保證周期不一致,高維的周期更長,頻率更低。

4)為什么采用10000做分母的底數?
因為如果底數是一個較小值,那這會導致最高維的周期不會太大。試想,當token數量變多的時候,一旦后面某個token的位置正好是前面某個token的位置編碼中所有三角函數周期的公倍數的整數倍(因為計算機浮點精度的存在),這會導致不同位置的token具有完全相同的位置編碼,所以所有維度的三角函數周期的公倍數必須足夠大,當選擇10000時,最高維的周期已經足夠長,可以滿足絕大多數場景的需求了。
8. 為什么FeedForward層要先升維?
升維可以為模型提供更廣闊的特征空間,使其能夠捕捉到更豐富的信息,模型可以學習到更復雜的特征組合和交互,增強模型的表達能力。
9. 多頭交叉注意力與多頭自注意力的區別是什么?
多頭交叉注意力中key和value來自于Encoder的輸出,而query則來自于解碼器中對生成的token的自注意力輸出,多頭交叉注意力的作用是希望生成的token能夠利用到先前輸入中存在的一些關鍵信息。

開發運行Scala應用)


的簡單了解)

)


 快速入門 - 用戶管理(上))


----安裝e2 studio)

)




)