隨機過采樣(Random Oversampling)是一種用于平衡數據集的技術,常用于機器學習中處理類別不平衡問題。當某個類別的樣本數量遠少于其他類別時(例如二分類中的正負樣本比例懸殊),模型可能會偏向多數類,導致對少數類的預測性能較差。隨機過采樣通過復制少數類的樣本來增加其數量,從而達到類別平衡的目的。
通俗簡單的來說,隨機過采樣是一種簡單但有效的技術,它從少數類中隨機選擇樣本并復制它們,直到各類樣本數量相等或接近為止。
隨機過采樣的優點:
實現簡單。
不改變原始數據分布。
能有效緩解類別不平衡帶來的偏差。
隨機過采樣的缺點:
容易引起過擬合:因為是直接復制已有樣本,模型可能記住這些樣本而不是學習泛化特征。
沒有引入新的信息,只是重復已有樣本。
下面咱們通過R語言簡單介紹一下使用隨機過采樣(Random Oversampling)平衡數據,方法來源于文章(Lunardon, N., Menardi, G., Torelli, N.J.R.J., 2014. ROSE: a Package for Binary )
Imbalanced Learning, 6, p. 79)
先導入R包
# 加載所需庫
library(ROSE)
library(ggplot2)
library(dplyr)
咱們先生成一個不平衡的二分類數據
# 設置隨機種子以確保結果可復現
set.seed(123)
# 假設有 1000 個樣本,其中只有 10% 是正類(y=1)n <- 1000
X1 <- rnorm(n) # 特征1
X2 <- rnorm(n) # 特征2
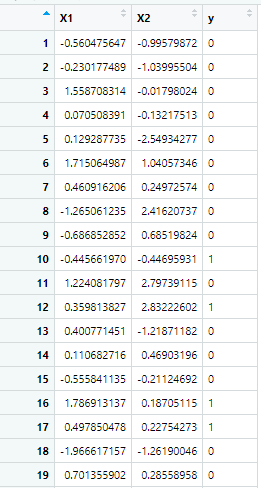
y <- rbinom(n, size = 1, prob = 0.1) # 少數類只占10%# 構建數據框
data <- data.frame(X1 = X1, X2 = X2, y = as.factor(y))
咱們可以看到數據的0很多1很少,這個屬于數據陽性比例過少,數據不平衡,
table(data$y)
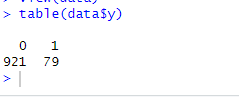
可以看到,陽性結果大概只有十分之一,圖示一下
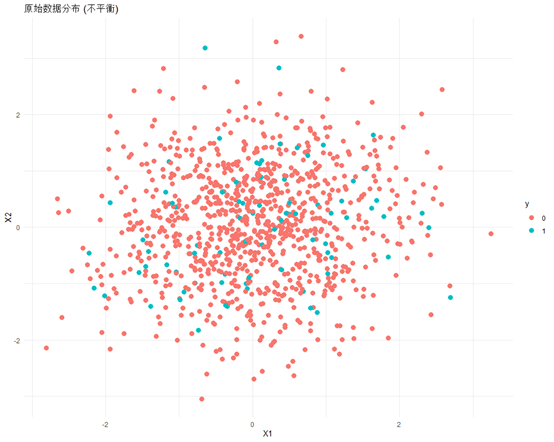
# 繪制原始數據分布圖
ggplot(data, aes(x = X1, y = X2, color = y)) +geom_point(size=2) +ggtitle("原始數據分布 (不平衡)") +theme_minimal()
下面咱們使用隨機過采樣(Random Oversampling)平衡數據,使用 ROSE 包中的 ovun.sample 函數,設置 method = “over”,默認將各類樣本數量調整為與最多類相同,其實非常用以,就是一句話代碼
data_over <- ovun.sample(y ~ ., data = data, method = "over", seed = 123)$data
查看過采樣后的類別分布
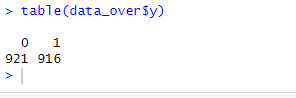
可以看到,1明顯增多了,圖示一下
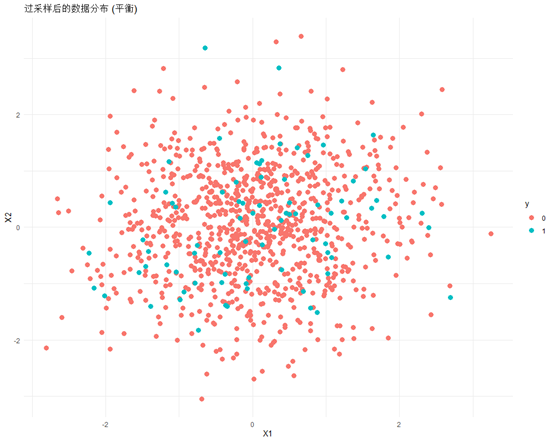
# 繪制過采樣后的數據分布圖
ggplot(data_over, aes(x = X1, y = X2, color = y)) +geom_point(size=3) +ggtitle("過采樣后的數據分布 (平衡)") +theme_minimal()
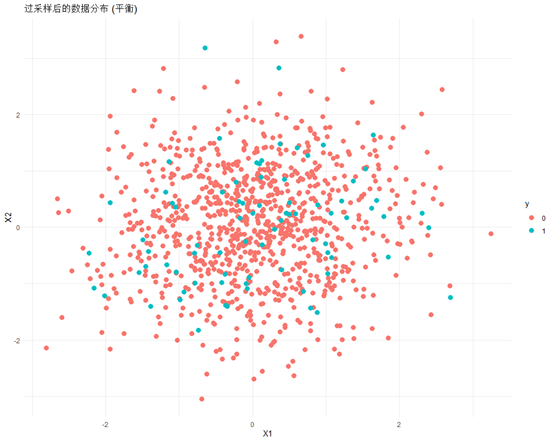
最后我來總結一下,ROSE法隨機過采樣方法,屬于比較簡單的平衡數據集方法,隨機過采樣最簡單的方式是直接從少數類中隨機抽取樣本并復制它們。這種做法會使得少數類的樣本數量增加,從而在某種程度上改變了原始的數據分布。特別是當過采樣的比例較高時,會導致模型看到更多的重復樣本。
由于少數類樣本被重復使用,模型可能學會這些特定樣本的細節和噪音,而非一般化的模式。這意味著模型可能會對訓練集上的表現非常好,但在未見過的數據(測試集或真實世界中的新數據)上表現較差,即發生過擬合。
目前這類方法用于機器學習比較多,對于邏輯回歸這樣的線性分類器,隨機過采樣可以通過增加少數類的權重來幫助模型“注意到”這些樣本。然而,這也可能導致模型對少數類的預測過于樂觀,因為它是在一個經過人為調整的數據分布上進行訓練的。因此進行敏感性分析我認為是十分必要的。
后面會介紹一下更加高級的方法,如SMOTE合成采樣。










詳細講解)




)



