一、LSTM 與?BiLSTM對比
1.1、LSTM
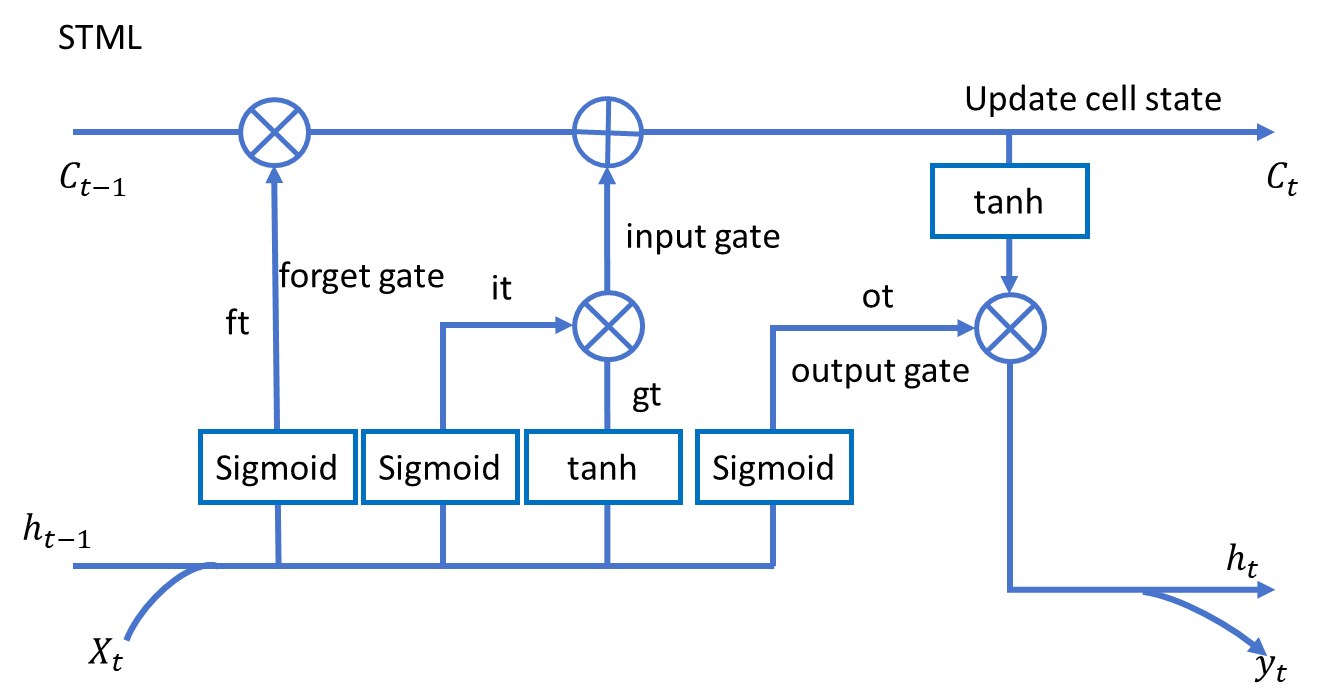
????????LSTM(長短期記憶網絡)?是一種改進的循環神經網絡(RNN),專門解決傳統RNN難以學習長期依賴的問題。它通過遺忘門、輸入門和輸出門來控制信息的流動,保留重要信息并丟棄無關內容,從而有效處理長序列數據。LSTM的核心是細胞狀態,它像一條傳送帶,允許信息在不同時間步之間穩定傳遞,避免梯度消失或爆炸,適用于時間序列預測、語音識別等任務。
1.2、BiLSTM?
????????BiLSTM(雙向長短期記憶網絡)?在LSTM的基礎上增加反向處理層,同時捕捉過去和未來的上下文信息。前向LSTM按時間順序處理序列,后向LSTM逆序處理,最終結合兩個方向的輸出,增強模型對全局上下文的理解。BiLSTM在自然語言處理任務(如機器翻譯、命名實體識別)中表現優異,但計算成本更高。它特別適合需要雙向信息交互的場景,如語義理解、情感分析等。?
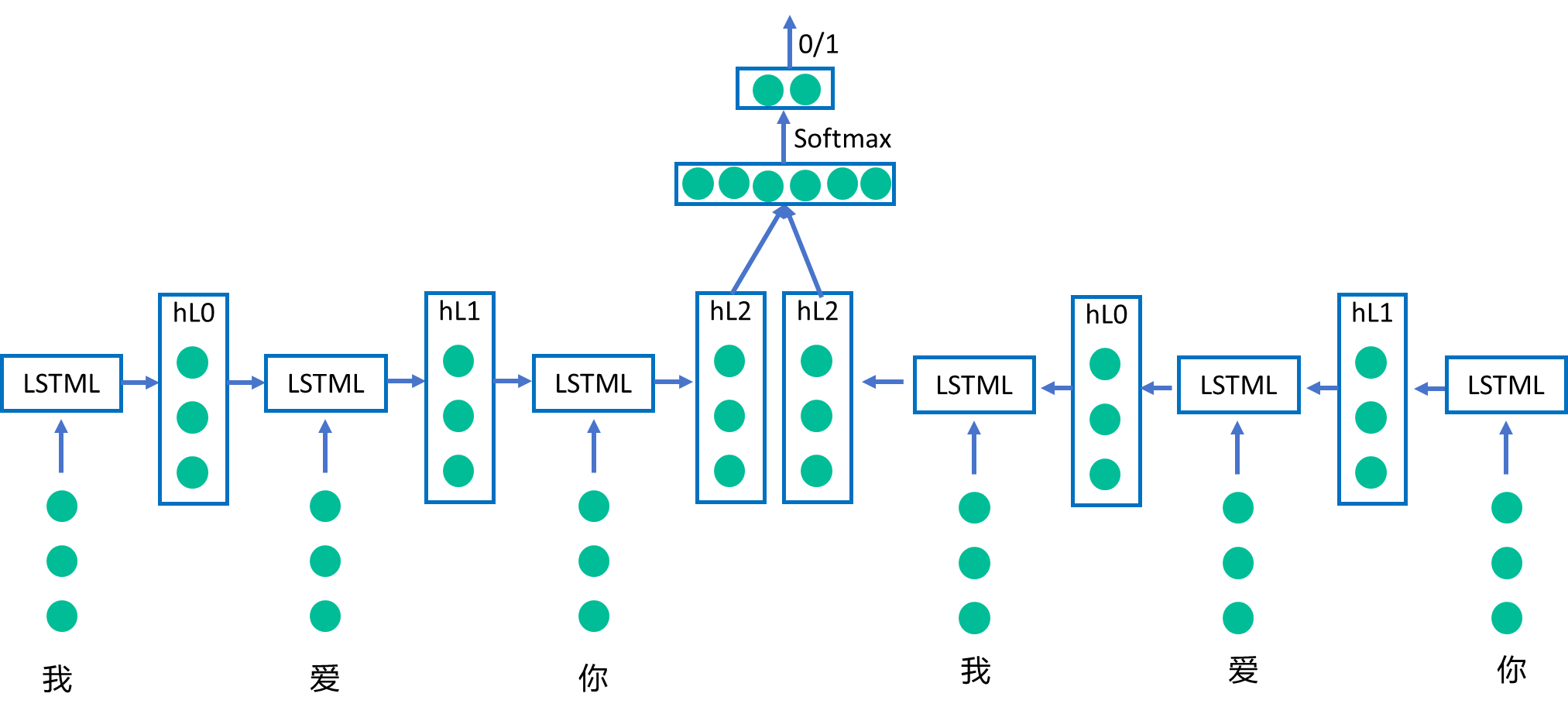
????????BiLSTM結構包含兩個方向的LSTM網絡:一個正向(forward)LSTM和一 個反向(backward)LSTM。
????????這兩個方向的LSTM在模型訓練過程中分別處理輸入序列,最后的隱藏狀態 由這兩個方向的LSTM拼接而成。這樣的結構使得模型能夠同時考慮到輸入 序列中每個位置的過去和未來信息,更全面地捕捉序列中的上下文信息。
????????如下面這個情感分類的例子,正向的LSTM按照從左到右的順序處理“我”、 “愛”、“你”,反向的LSTM按照從右到左的順序處理“你”、“愛”、“我”,然后 將兩個LSTM的最后一個隱藏層拼接起來再經過softmax等處理得到分類結果。
????????舉一個例子,如一句話“我今天很開心,因為我考試考了 100 分”要做情感 分類,LSTM只能從左到右的看,因此在看到“很開心”這個關鍵詞時它獲得 的只有上文的信息,而BiLSTM是雙向的因此也能看到“因為我考試考了 100 分”這一部分,而這一部分對應最終結果是否準確有很大的幫助。?
| 特征 | LSTM | BiLSTM |
|---|---|---|
| 方向性 | 單向(僅過去信息) | 雙向(過去和未來信息) |
| 計算復雜度 | 較低 | 較高(約2倍) |
| 典型應用 | 時間序列預測、語言模型 | 文本分類、序列標注、機器翻譯 |
| 內存需求 | 較少 | 較多 |
13、優勢?
BiLSTM相對于單向LSTM具有以下優勢:
????????能夠捕捉到輸入序列中每個位置的過去和未來信息,更全面地捕捉序列 中的上下文信息。
????????可以更好地處理長距離的依賴關系。
????????在許多自然語言處理任務中都取得了良好的效果。
二、庫函數-LSTM
torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0.0, bidirectional=False, proj_size=0, device=None, dtype=None)LSTM — PyTorch 2.7 documentation
| 參數 | 描述 |
| input_size | 輸入?x?中預期特征的數量 |
| hidden_size | 處于隱藏狀態?h?的特征數量 |
| num_layers | 循環層數。例如,設置意味著將兩個 LSTM 堆疊在一起以形成一個堆疊的 LSTM。 第二個 LSTM 接收第一個 LSTM 的輸出,并且 計算最終結果。默認值:1num_layers=2 |
| bias | 偏置如果 ,則層不使用?b_ih?和?b_hh?的偏差權重。 違約:FalseTrue |
| batch_first? | 如果 ,則提供輸入和輸出張量 作為?(batch, seq, feature)?而不是?(seq, batch, feature)。?請注意,這不適用于隱藏狀態或單元格狀態。請參閱 Inputs/Outputs 部分了解詳細信息。違約:TrueFalse |
| dropout? | 如果為非零,則在每個?除最后一層外的 LSTM 層,其 dropout 概率等于 。默認值:0dropout |
| bidirectional | 如果 ,則變為雙向 LSTM。違約: ?
|
| proj_size | 如果 ,將使用 LSTM 和相應大小的投影。默認值:0 |

import torch
import numpy as np
from torch import nn# 1.字符輸入
text = "In Beijing Sarah bought a basket of apples In Guangzhou Sarah bought a basket of bananas"torch.manual_seed(1)# 3.數據集劃分
input_seq = [text[:-1]]
output_seq = [text[1:]]
print("input_seq:", input_seq)
# print("output_seq:", output_seq)# 4.數據編碼:one-hot
chars = set(text)
chars = sorted(chars)
# print("chars:", chars)
# {" ":0, "a":1 }
char2int = {char: ind for ind, char in enumerate(chars)}
# print("char2int:", char2int)
# {0:" ", 1: "a"}
int2char = dict(enumerate(chars))# 將字符轉成數字編碼
input_seq = [[char2int[char] for char in seq] for seq in input_seq]
# print("input_seq:", input_seq)
output_seq = [[char2int[char] for char in seq] for seq in output_seq]# one-hot 編碼,pytorch的RNN的輸入張量的填充
def one_hot_encode(seq, bs, seq_len, size):features = np.zeros((bs, seq_len, size), dtype=np.float32)for i in range(bs):for u in range(seq_len):features[i, u, seq[i][u]] = 1.0return torch.tensor(features, dtype=torch.float32)input_seq = one_hot_encode(input_seq, 1, len(text)-1, len(chars))
output_seq = torch.tensor(output_seq, dtype=torch.long).view(-1)
print("output_seq:", output_seq)# 5.定義前向模型
class Model(nn.Module):def __init__(self, input_size, hidden_size, out_size):super(Model, self).__init__()self.hidden_size = hidden_sizeself.bilstm1 = nn.LSTM(input_size, hidden_size, num_layers=1, batch_first=True, bidirectional=True)self.fc1 = nn.Linear(hidden_size * 2, out_size)def forward(self, x):out, hidden = self.bilstm1(x)x = out.contiguous().view(-1, self.hidden_size * 2)x = self.fc1(x)return x, hiddenmodel = Model(len(chars), 32, len(chars))# 6.定義損失函數和優化器
cri = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)# 7.開始迭代
epochs = 1000
for epoch in range(1, epochs+1):output, hidden = model(input_seq)loss = cri(output, output_seq)optimizer.zero_grad()loss.backward()optimizer.step()# 8.顯示頻率設置if epoch == 0 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}], Loss {loss:.4f}")# print("input_seq.shape:", input_seq.shape)
# print("hidden.shape:", hidden.shape)
# print("output.shape:", output.shape)
# print("input_w:", model.rnn1.weight_ih_l0.shape)# 預測下面幾個字符
input_text = "In Beijing Sarah bought a basket of" # re
to_be_pre_len = 20for i in range(to_be_pre_len):chars = [char for char in input_text]# print(chars)character = np.array([[char2int[c] for c in chars]])character = one_hot_encode(character, 1, character.shape[1], 23)character = torch.tensor(character, dtype=torch.float32)out, hidden = model(character)char_index = torch.argmax(out[-1]).item()input_text += int2char[char_index]
print("預測到的:", input_text)?


:類、命名空間和作用域)








)







