
大家好,我是 Ai 學習的老章
看論文時,經常看到漂亮的圖表,很多不知道是用什么工具繪制的,或者很想復刻類似圖表。
實測,大模型?LaTeX?公式識別,出乎預料
前文,我用 Kimi、Qwen-3-235B-A22B、Claude-3.7-sonnet、GPT-4.1、Gemini 2.5 Pro 測試了其在 LaTeX 公式識別中的表現。
本文就測試一下他們在圖表識別、復刻中的表現,看看誰更擅長干這件事
備注:Kimi 開啟了長思考,Qwen3 未開啟深度思考,因為開啟之后巨慢且失敗
省流:Gemini 2.5 Pro 是最強大的代碼模型,毫無爭議
排名:Gemini 2.5 Pro > Claude 3.7 Sonnet > Kimi = Qwen3 > GPT-4.1
第一題
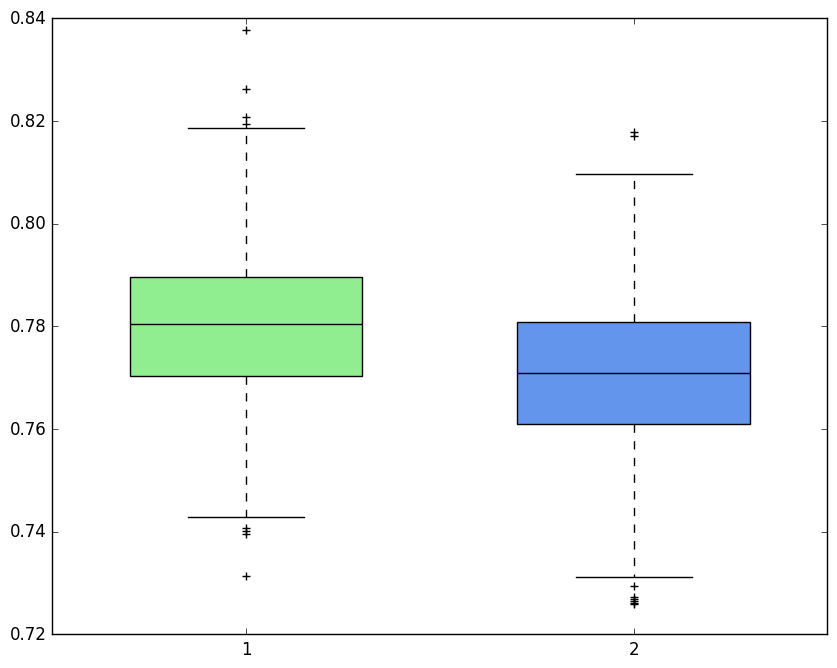
Kimi
有點弱智,繪制了傻瓜箱線圖,圖像理解有問題
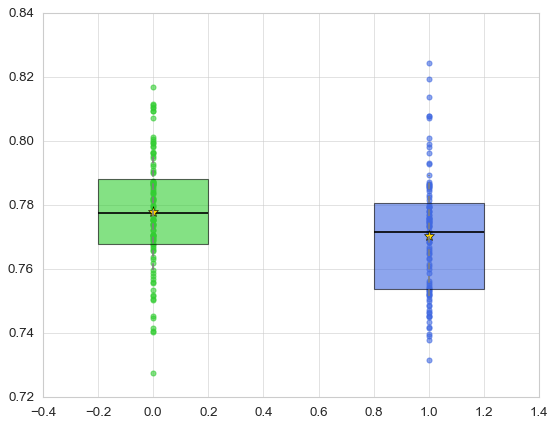
Qwen-3-235B-A22B
也很傻瓜,與 kimi 半斤八兩
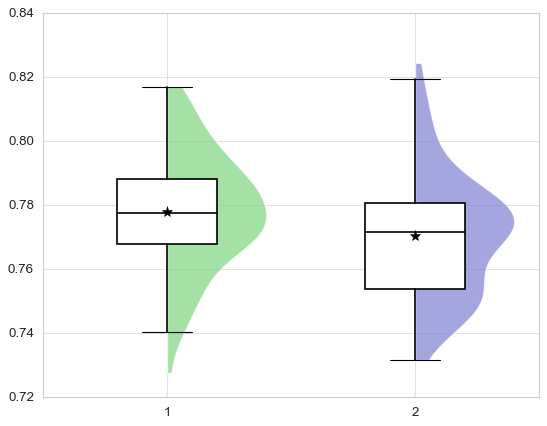
Claude-3.7-sonnet
好一點點,繪制了半小提琴圖 (half-violin plot) 結合箱線圖 (box plot)
后續我又試了一下
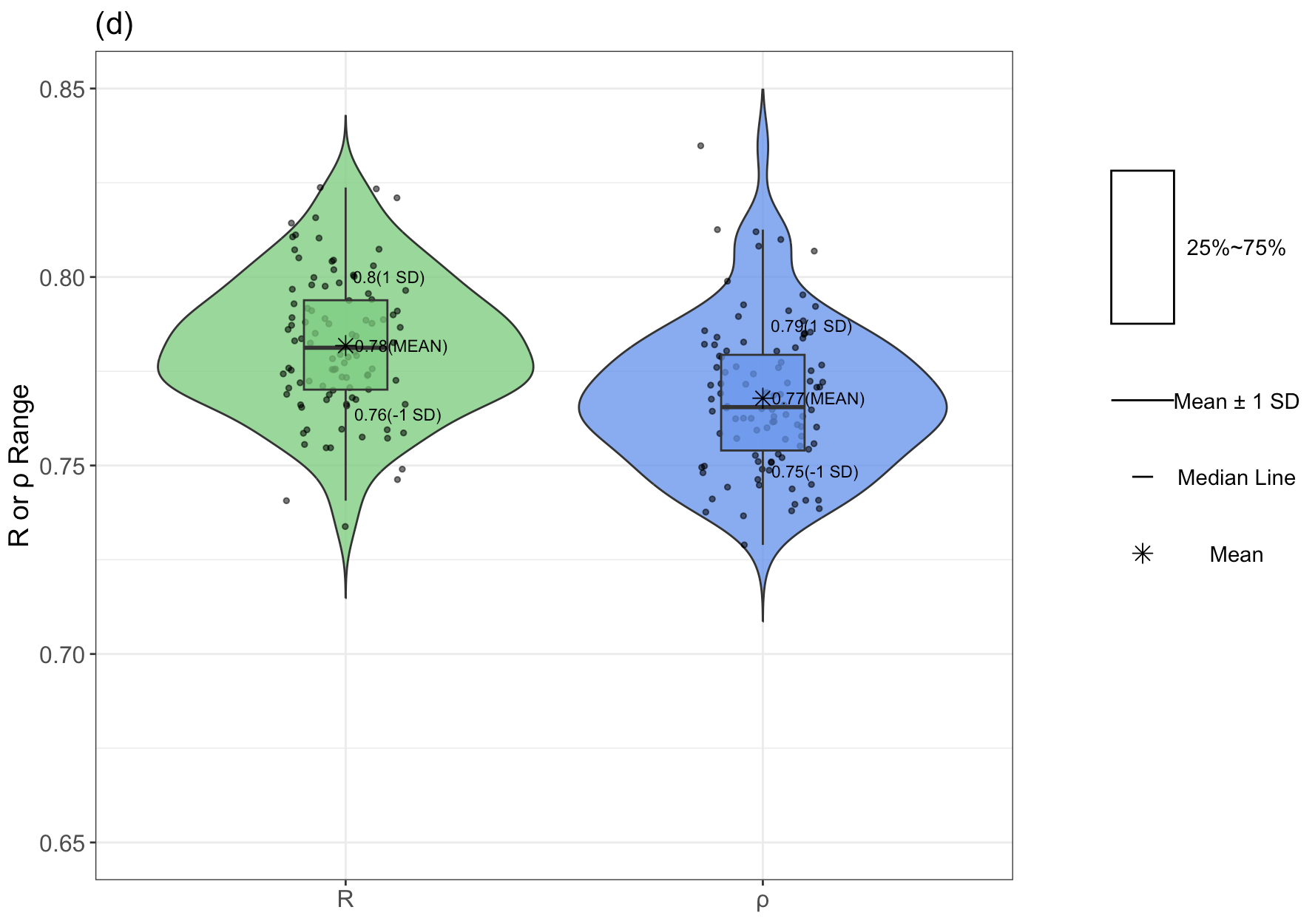
如果明確告訴它用 R 繪制,Claude-3.7 結果如下,還不錯!
GPT-4.1
失敗,生成的代碼滿滿得 bug,無法生成圖表
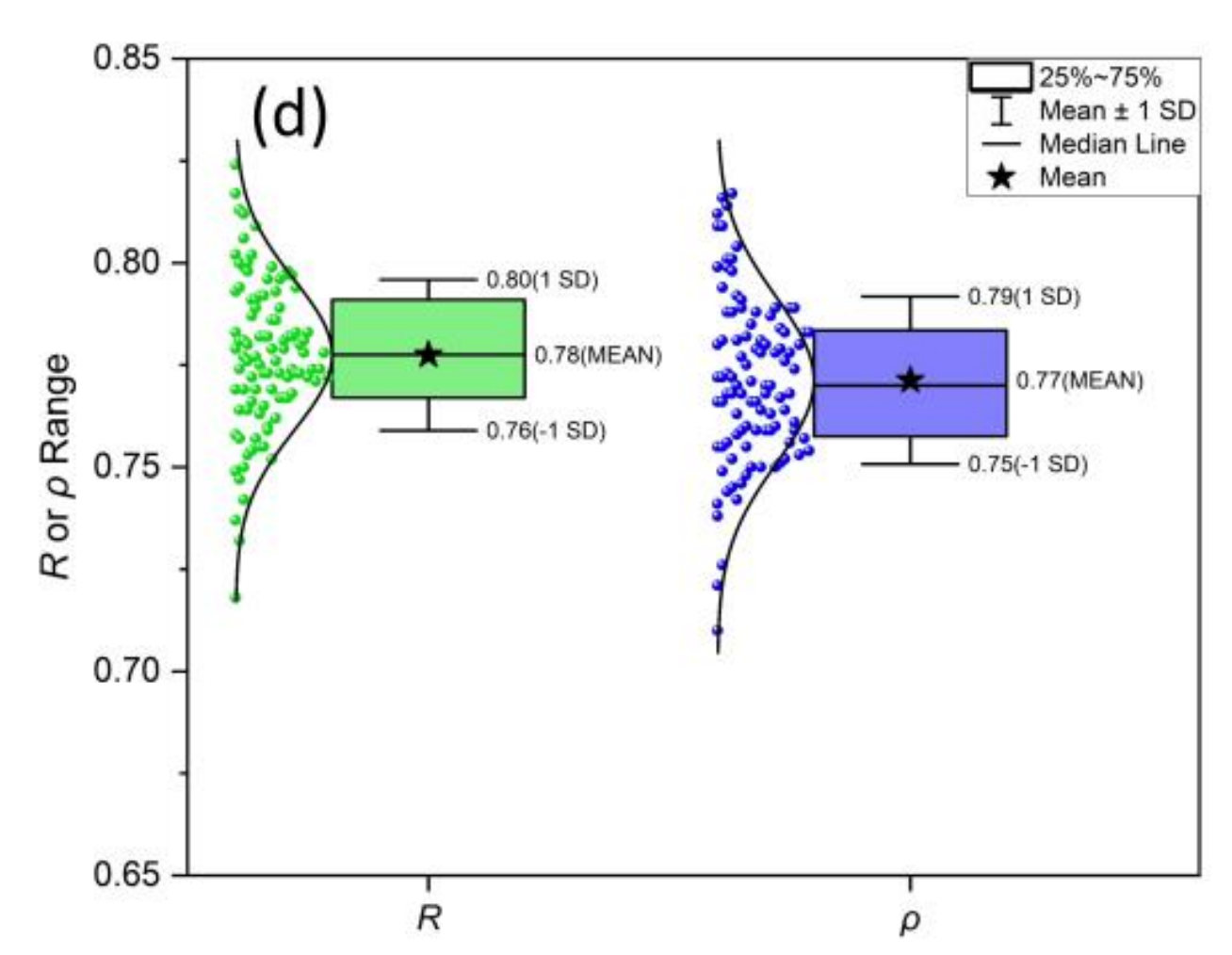
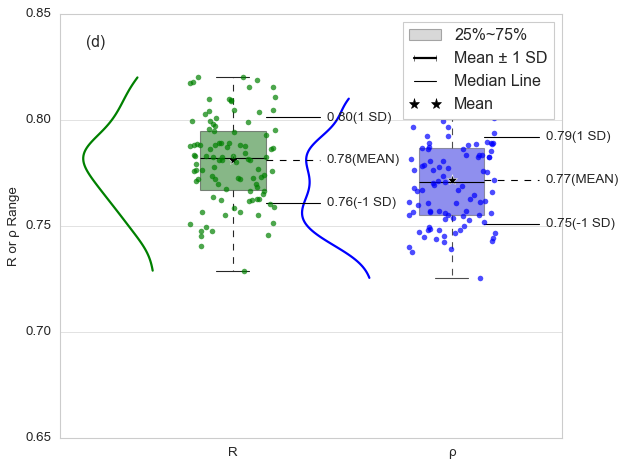
Gemini 2.5 Pro
震驚了
它識別出這是雨云圖 (raincloudplot),結合了以下 3 圖表的元素:
散點圖 (Scatter/Strip plot):顯示每 1.個單獨的數據點 (圖中的綠色和藍色小點)
箱形圖 (Box plot):顯示數據的分布摘要 (中位數、四分位數、均值和標準差范圍)
小提琴圖 (Violin plot) 或 核密度估計圖 (KDE plot):顯示數據分布的平滑曲線 (圖中數據點左側的曲線)
代碼放文末了,大家欣賞一下
第二題
上難度,一次性復刻、輸出 4 張圖表
Kimi
看了下,其樣例數據很簡單,第四幅圖沒有完美復刻
Qwen-3-235B-A22B
沒理解意思,且只生成了一張,出現 bug
沒想到它居然還不如 kimi。。。
Claude-3.7-sonnet
第四幅圖沒有繪制成功,報錯是顏色問題
讓其修復顏色問題后,輸出如下,第四幅圖沒有依然沒有完美復刻
GPT-4.1
繪制失敗,換了 GPT-4o 依然失敗
Gemini 2.5 Pro
第四張繪制失敗
第三題
換個簡單點的
省點事兒,直接讓大模型用 R 復刻
用?R?_復刻_了一張圖,附代碼
Kimi
復刻失敗
Qwen-3-235B-A22B
還行,有點丑
Claude-3.7-sonnet
“徑向條形圖”或“放射狀條形圖”(Radial Bar Chart)
GPT-4.1
復刻失敗
Gemini 2.5 Pro
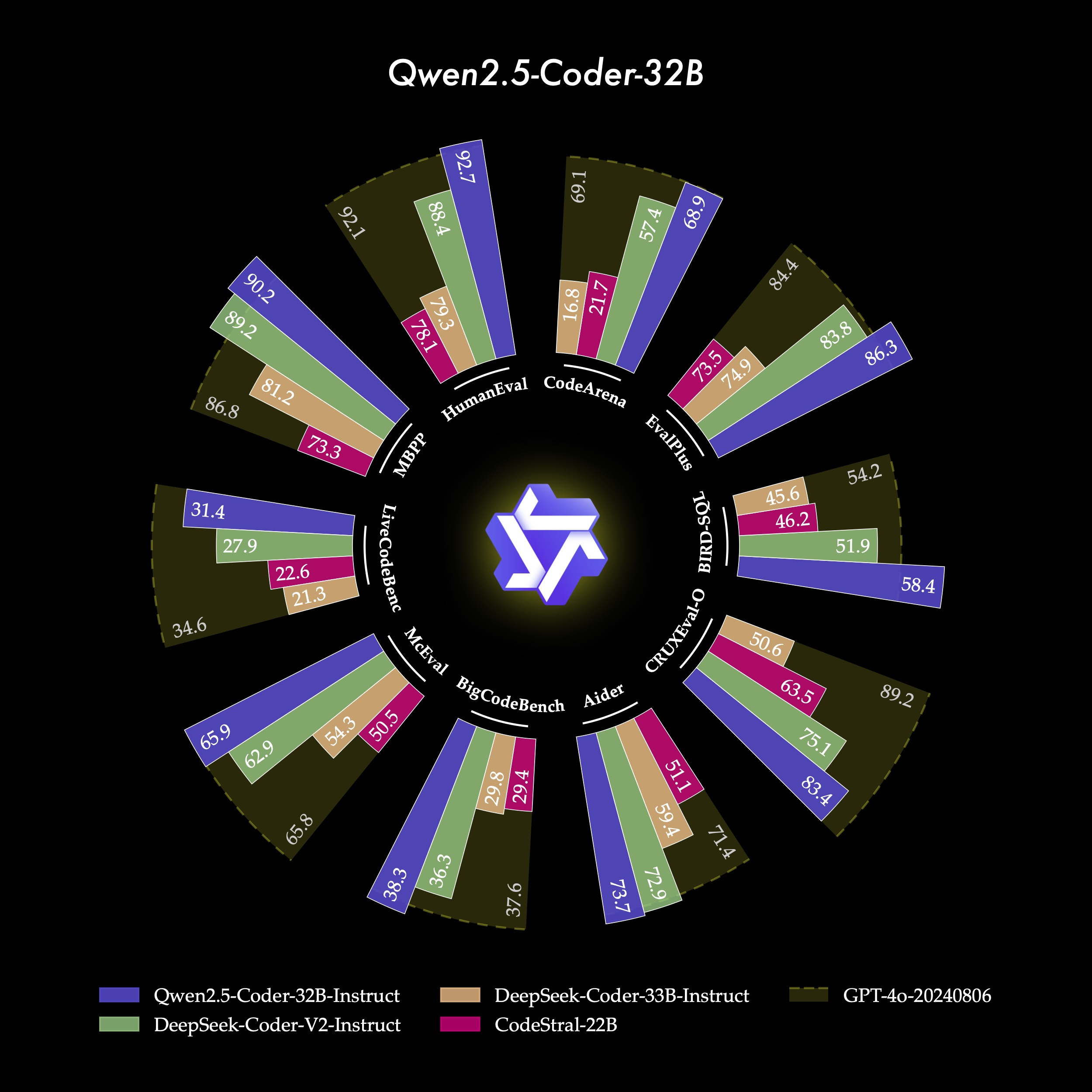
接近完美復刻
Gemini-2.5-Pro 繪制的云雨圖代碼
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np# 1. 生成模擬數據
# 根據圖片估算 R 和 rho 的數據特征
np.random.seed(0) # 為了結果可復現# R 的數據
r_mean = 0.78
r_std = 0.02 # 根據 1 SD 范圍 (0.76-0.80) 估算
r_data = np.random.normal(loc=r_mean, scale=r_std, size=100)
# 限制數據在圖中大致范圍內
r_data = np.clip(r_data, 0.72, 0.82)# rho 的數據
rho_mean = 0.77
rho_std = 0.02 # 根據 1 SD 范圍 (0.75-0.79) 估算
rho_data = np.random.normal(loc=rho_mean, scale=rho_std, size=100)
# 限制數據在圖中大致范圍內
rho_data = np.clip(rho_data, 0.70, 0.81)# 將數據整合到 Pandas DataFrame 中,方便 seaborn 處理
df_r = pd.DataFrame({'value': r_data, 'category': 'R'})
df_rho = pd.DataFrame({'value': rho_data, 'category': 'ρ'})
df_combined = pd.concat([df_r, df_rho])# 2. 繪制圖表
fig, ax = plt.subplots(figsize=(8, 6))# 使用 seaborn 繪制
# 為了實現雨云圖的效果,我們會組合 stripplot, boxplot, 和 violinplot (只顯示一半)# 定義顏色
colors = {"R": "green", "ρ": "blue"}# 繪制 R
# 散點 (左移一點,給箱線圖和 KDE 留空間)
sns.stripplot(x='category', y='value', data=df_r, order=['R'],color=colors['R'], alpha=0.7, jitter=0.2, size=5, ax=ax, dodge=True, label='_nolegend_')# 箱線圖 (居中)
sns.boxplot(x='category', y='value', data=df_r, order=['R'],color=colors['R'], width=0.3, showfliers=False, ax=ax,boxprops=dict(alpha=0.5), medianprops=dict(color='black'))# 小提琴圖/KDE (右移一點,只畫一半)
# Seaborn 的 violinplot 可以通過 cut=0 和 inner=None 以及調整位置來實現類似效果
# 或者更精確地使用 KDE 圖并手動定位
from scipy import stats
kde_r = stats.gaussian_kde(df_r['value'])
x_vals_r = np.linspace(df_r['value'].min(), df_r['value'].max(), 100)
y_vals_r = kde_r(x_vals_r)
# 將 KDE 曲線畫在散點圖的左邊
# 需要計算合適的橫坐標位置,這里簡化處理,通常雨云圖庫會處理這個對齊
ax.plot(0 - 0.35 - y_vals_r / (y_vals_r.max()*3) , x_vals_r, color=colors['R'], lw=2) # 調整分母控制寬度# 繪制 ρ
# 散點
sns.stripplot(x='category', y='value', data=df_rho, order=['ρ'],color=colors['ρ'], alpha=0.7, jitter=0.2, size=5, ax=ax, dodge=True, label='_nolegend_')# 箱線圖
sns.boxplot(x='category', y='value', data=df_rho, order=['ρ'],color=colors['ρ'], width=0.3, showfliers=False, ax=ax,boxprops=dict(alpha=0.5), medianprops=dict(color='black'))# 小提琴圖/KDE for rho
kde_rho = stats.gaussian_kde(df_rho['value'])
x_vals_rho = np.linspace(df_rho['value'].min(), df_rho['value'].max(), 100)
y_vals_rho = kde_rho(x_vals_rho)
ax.plot(1 - 0.35 - y_vals_rho / (y_vals_rho.max()*3) , x_vals_rho, color=colors['ρ'], lw=2)# 3. 添加圖例和標簽 (類似原圖)
# R 的均值和標準差標注
mean_r_val = df_r['value'].mean()
std_r_val = df_r['value'].std()
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val + std_r_val, mean_r_val + std_r_val], color='black', lw=1)
ax.text(0.28 + 0.15, mean_r_val + std_r_val, f'{mean_r_val + std_r_val:.2f}(1 SD)', va='center')
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val, mean_r_val], color='black', lw=1, linestyle='--') # 均值線 (用星號表示)
ax.plot(0, mean_r_val, marker='*', markersize=10, color='black', markeredgecolor='white') # 原圖是星號
ax.text(0.28 + 0.15, mean_r_val, f'{mean_r_val:.2f}(MEAN)', va='center')
ax.plot([0 + 0.15, 0.25 + 0.15], [mean_r_val - std_r_val, mean_r_val - std_r_val], color='black', lw=1)
ax.text(0.28 + 0.15, mean_r_val - std_r_val, f'{mean_r_val - std_r_val:.2f}(-1 SD)', va='center')# ρ 的均值和標準差標注
mean_rho_val = df_rho['value'].mean()
std_rho_val = df_rho['value'].std()
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val + std_rho_val, mean_rho_val + std_rho_val], color='black', lw=1)
ax.text(1.28 + 0.15, mean_rho_val + std_rho_val, f'{mean_rho_val + std_rho_val:.2f}(1 SD)', va='center')
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val, mean_rho_val], color='black', lw=1, linestyle='--')
ax.plot(1, mean_rho_val, marker='*', markersize=10, color='black', markeredgecolor='white')
ax.text(1.28 + 0.15, mean_rho_val, f'{mean_rho_val:.2f}(MEAN)', va='center')
ax.plot([1 + 0.15, 1.25 + 0.15], [mean_rho_val - std_rho_val, mean_rho_val - std_rho_val], color='black', lw=1)
ax.text(1.28 + 0.15, mean_rho_val - std_rho_val, f'{mean_rho_val - std_rho_val:.2f}(-1 SD)', va='center')# 圖表標題和軸標簽
ax.set_ylabel('R or ρ Range')
ax.set_xlabel('') # X 軸通常不顯示標簽,直接用類別名
ax.set_xticks([0, 1])
ax.set_xticklabels(['R', 'ρ'])
ax.set_ylim(0.65, 0.85) # 根據原圖設定
ax.text(0.05, 0.95, '(d)', transform=ax.transAxes, fontsize=14, va='top') # 子圖標簽# 添加圖例 (模擬原圖的圖例)
from matplotlib.lines import Line2D
from matplotlib.patches import Patch
legend_elements = [Patch(facecolor='grey', alpha=0.3, edgecolor='black', label='25%~75%'),Line2D([0], [0], color='black', lw=2, label='Mean ± 1 SD', marker='|', markersize=5, linestyle='-'),Line2D([0], [0], color='black', lw=1, label='Median Line'),Line2D([0], [0], marker='*', color='w', label='Mean',markerfacecolor='black', markersize=10)
]
ax.legend(handles=legend_elements, loc='upper right', bbox_to_anchor=(1.0, 1.0))plt.tight_layout()
plt.show()
Gemini-2.5-Pro 繪制南丁格爾玫瑰圖代碼
# 安裝和加載必要的包
# install.packages("ggplot2")
# install.packages("dplyr")
# install.packages("tidyr") # For pivot_longer if neededlibrary(ggplot2)
library(dplyr)# 1. 準備數據
# 主模型數據
model_data <- data.frame(benchmark = factor(rep(c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP"), each = 4),levels = c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP")),model = factor(rep(c("Qwen2.5-Coder-32B-Instruct", "DeepSeek-Coder-V2-Instruct", "DeepSeek-Coder-33B-Instruct", "CodeLlama-Instruct-22B"), times = 10),levels = c("Qwen2.5-Coder-32B-Instruct", "DeepSeek-Coder-V2-Instruct", "DeepSeek-Coder-33B-Instruct", "CodeLlama-Instruct-22B")),value = c(# HumanEval92.7, 88.4, 79.3, 78.1,# CodeArena68.9, 57.4, 21.7, 16.8,# EvalPlus86.3, 83.8, 74.9, 73.5,# BIRD-SQL58.4, 51.9, 46.2, 45.6,# CRUXEval-O83.4, 75.1, 63.5, 50.6,# Aider73.7, 72.9, 59.4, 51.1,# BigCodeBench38.3, 36.3, 29.8, 29.4,# McEval65.9, 62.9, 54.3, 50.5,# LiveCodeBench31.4, 27.9, 22.6, 21.3,# MBPP90.2, 89.2, 81.2, 73.3)
)# GPT-4o 背景數據 (定義每個 benchmark "軌道" 的最大值)
gpt4o_data <- data.frame(benchmark = factor(c("HumanEval", "CodeArena", "EvalPlus", "BIRD-SQL", "CRUXEval-O", "Aider", "BigCodeBench", "McEval", "LiveCodeBench", "MBPP"),levels = levels(model_data$benchmark)),value = c(92.1, 69.1, 84.4, 54.2, 89.2, 71.4, 37.6, 65.8, 34.6, 86.8)
)# 2. 定義顏色
# 順序應與 model factor levels 對應: Blue, Green, Beige, Pink
color_palette <- c("Qwen2.5-Coder-32B-Instruct" = "#2A7FFF", # 鮮艷的藍色"DeepSeek-Coder-V2-Instruct" = "#7CFC00", # 亮綠色/酸橙綠"DeepSeek-Coder-33B-Instruct" = "#E0C097", # 米色/淺棕"CodeLlama-Instruct-22B" = "#FF1493", # 深粉色/品紅"GPT-4o-Track" = "#4A4A3B" # 暗橄欖色 (用于背景軌道)
)# 3. 創建圖表
# 計算 benchmark 標簽的位置
num_benchmarks <- length(levels(model_data$benchmark))
benchmark_labels_data <- data.frame(benchmark = levels(model_data$benchmark),angle = 90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2,hjust_val = ifelse( (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) < -90 | (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) > 90, 1, 0),angle_text = ifelse( (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) < -90 | (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) > 90, (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) + 180, (90 - seq(0, 360 - 360/num_benchmarks, length.out = num_benchmarks) - (360/num_benchmarks)/2) )
)
# 合并以獲取 benchmark 的 x 值
benchmark_labels_data <- benchmark_labels_data %>%mutate(x_pos = as.numeric(factor(benchmark, levels = levels(model_data$benchmark))))# 調整y軸上限以容納標簽
y_axis_max <- 115 #max(c(model_data$value, gpt4o_data$value)) * 1.15p <- ggplot() +# A. 繪制 GPT-4o 背景 "軌道"# 使用 geom_col 為每個 benchmark 創建一個單獨的背景條,寬度覆蓋整個類別geom_col(data = gpt4o_data,aes(x = benchmark, y = value), # 使用 y = y_axis_max 來創建完整的扇區背景fill = color_palette["GPT-4o-Track"], # 使用預定義的顏色alpha = 0.8, # 透明度width = 0.95) + # 寬度,確保覆蓋# B. 繪制模型數據條形geom_col(data = model_data, aes(x = benchmark, y = value, fill = model),position = position_dodge2(width = 0.9, preserve = "single"), # 分組條形width = 0.85, # 條形寬度alpha = 0.9) + # 條形透明度# C. 在 GPT-4o 軌道上添加數值標簽geom_text(data = gpt4o_data,aes(x = benchmark, y = value + 4, label = sprintf("%.1f", value)), # 標簽位置略高于軌道末端color = "white", size = 2.5, fontface = "bold", vjust = 0.5) +# D. 在模型數據條形上添加數值標簽geom_text(data = model_data,aes(x = benchmark, y = value + 2, label = sprintf("%.1f", value), group = model),position = position_dodge2(width = 0.9, preserve = "single"),color = "white", size = 2, vjust = 0.5, hjust=0.5, fontface="bold") +# E. 應用極坐標轉換coord_polar(theta = "x", start = 0, direction = 1) +# F. 設置 Y 軸范圍和刻度 (半徑)# 移除默認的Y軸網格線和標簽,因為它們在極坐標圖中通常不直觀scale_y_continuous(limits = c(-20, y_axis_max), breaks = c(0, 25, 50, 75, 100), labels = c("0", "25", "50", "75", "100")) +# G. 自定義顏色scale_fill_manual(values = color_palette, name = "Model") +# H. 添加 Benchmark 標簽 (X軸標簽)# 使用 annotate 或 geom_text 來手動放置 benchmark 標簽# 這里我們使用 scale_x_discrete 并嘗試通過主題調整,但自定義 geom_text 通常效果更好geom_text(data = benchmark_labels_data,aes(x = x_pos, y = y_axis_max * 0.95, label = benchmark, angle = angle_text, hjust = hjust_val), # y值設在外部color = "white", size = 3.5, fontface = "bold") +# I. 設置主題和樣式theme_minimal() +theme(plot.background = element_rect(fill = "black", color = "black"),panel.background = element_rect(fill = "black", color = "black"),panel.grid = element_blank(), # 移除主要網格線axis.title = element_blank(),axis.text.y = element_text(color = "white", size = 8), # Y軸刻度標簽(半徑)axis.text.x = element_blank(), # 移除默認的X軸標簽,因為我們用geom_text自定義了legend.position = "bottom",legend.background = element_rect(fill = "black"),legend.title = element_text(color = "white", face = "bold"),legend.text = element_text(color = "white"),plot.title = element_text(color = "white", size = 20, hjust = 0.5, face = "bold", margin = margin(b = 20))) +# J. 添加標題ggtitle("Qwen2.5-Coder-32B")# 顯示圖表
print(p)制作不易,如果這篇文章覺得對你有用,可否點個關注。給我個三連擊:點贊、轉發和在看。若可以再給我加個🌟,謝謝你看我的文章,我們下篇再見!
搭建完美的寫作環境:工具篇(12 章)
圖解機器學習 - 中文版(72 張 PNG)
ChatGPT、大模型系列研究報告(50 個 PDF)
108 頁 PDF 小冊子:搭建機器學習開發環境及 Python 基礎?
116 頁 PDF 小冊子:機器學習中的概率論、統計學、線性代數?
史上最全!371 張速查表,涵蓋 AI、ChatGPT、Python、R、深度學習、機器學習等



)


Java/python/JavaScript/C/C++/GO最佳實現)





)






