cs224w課程學習筆記-第12課 知識圖譜問答
- 前言
- 一、問答類型分類
- 二、路徑查詢(Path queries)
- 2.1 直觀查詢方法
- 2.2 TransE 擴展
- 2.3 TransE 能力分析
- 三、連詞查詢(conjunctive queries)
- 3.1 Query2box 原理
- 1)、投影
- 2)、交集查詢(AND 操作)
- 3)、聯合查詢(OR 操作)
- 4)、and_or操作
- 3.2 Query2box 訓練
- 1)、正負樣本采樣
- 2)、查詢過程可視化
- 四、總結
前言
前面一節課講了知識圖譜的嵌入,其常用的加法,乘法模型及其各自的嵌入原理,表征能力與嵌入輸出情況.本節課將就最經典的知識圖譜的問答任務,闡述如何將問答任務進行任務分析,轉化為可以使用知識圖譜嵌入模型的嵌入進行任務訓練,最終完成該類問答任務.
一、問答類型分類
以下圖中的藥理知識圖譜為例,邊有四種,分別是造成causes,相關Assoc,治療Treat,相互Interact關系,節點有藥物,疾病,副作用與蛋白質,右側是幾種類型的問題
- 直接已知一個節點,通過一種關系邊,到達目標節點可得到問題的答案(one-hop): Fulvestrant會造成什么副作用(開始節點為Fulvestrant,邊為causes,目標節點副作用)
- 路徑問答:已知一個節點,通過多種節點關系邊,到達目標節點可得到問題的答案: Fulvestrant會造成副作用相關的蛋白質(開始節點為Fulvestrant,邊為causes,Assoc,中途節點為副作用,目標節點蛋白質)
- 連詞查詢:已知多個節點,經過多種節點關系邊,得到交互的目標節點,得到問題的答案:造成頭疼與治療乳腺癌的藥物是什么(開始節點為(Headache,邊為causes),(Breast Cancer ,邊Treat)
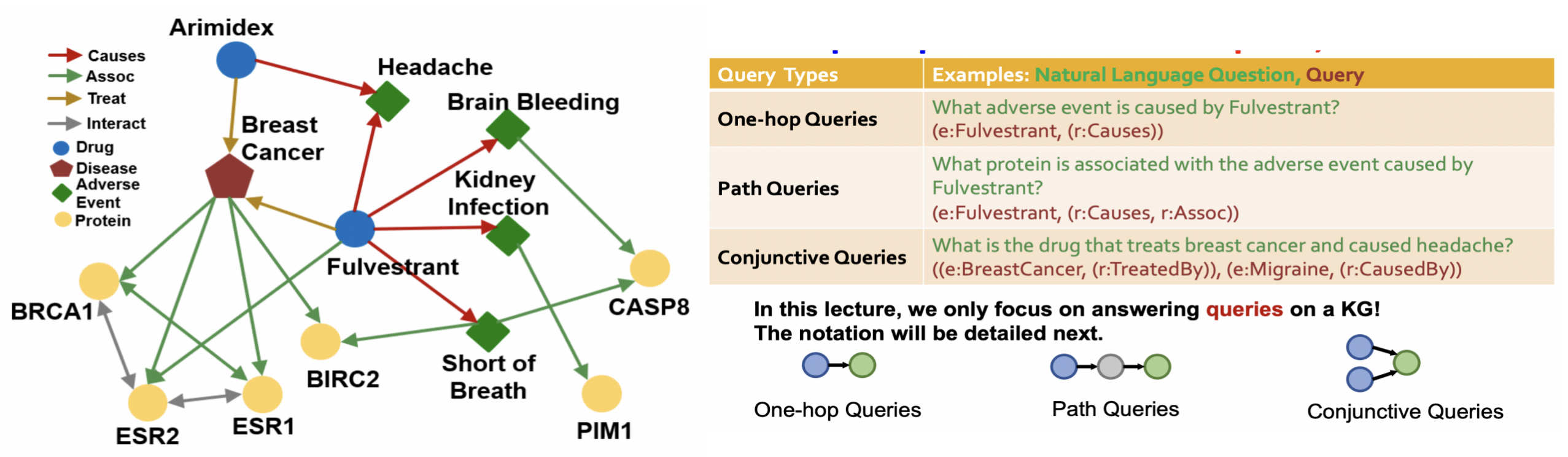
從節點與邊的結構圖上可以看到其第二種與第三種的差異在于交互上,第一種與第二種的差異在于中間是否需要通過多次路徑.因此第一種可以看作是第二種的特例.在接下來我們將區別第二種問答與第三種問答進行其任務求解的說明.
二、路徑查詢(Path queries)
2.1 直觀查詢方法
緊接前面的第二個問題,其涉及兩種類型邊,因此我們有知識圖后,從起始節點出發遍歷所有第一個類型Causes的邊,到達其連接的節點后,再以連接的節點遍歷第二類型Assos的邊,到達其連接的節點即為答案(圖中綠色節點).可以發現的每一類邊所到的節點是一個節點集,而不是單個節點,結果也可能是一個節點集.那么在實際場景中,知識圖譜往往是不完整的,若此時有一個結果里的節點是缺失的,按當前搜索圖的方法就會發現結果集沒有拿到全部答案.
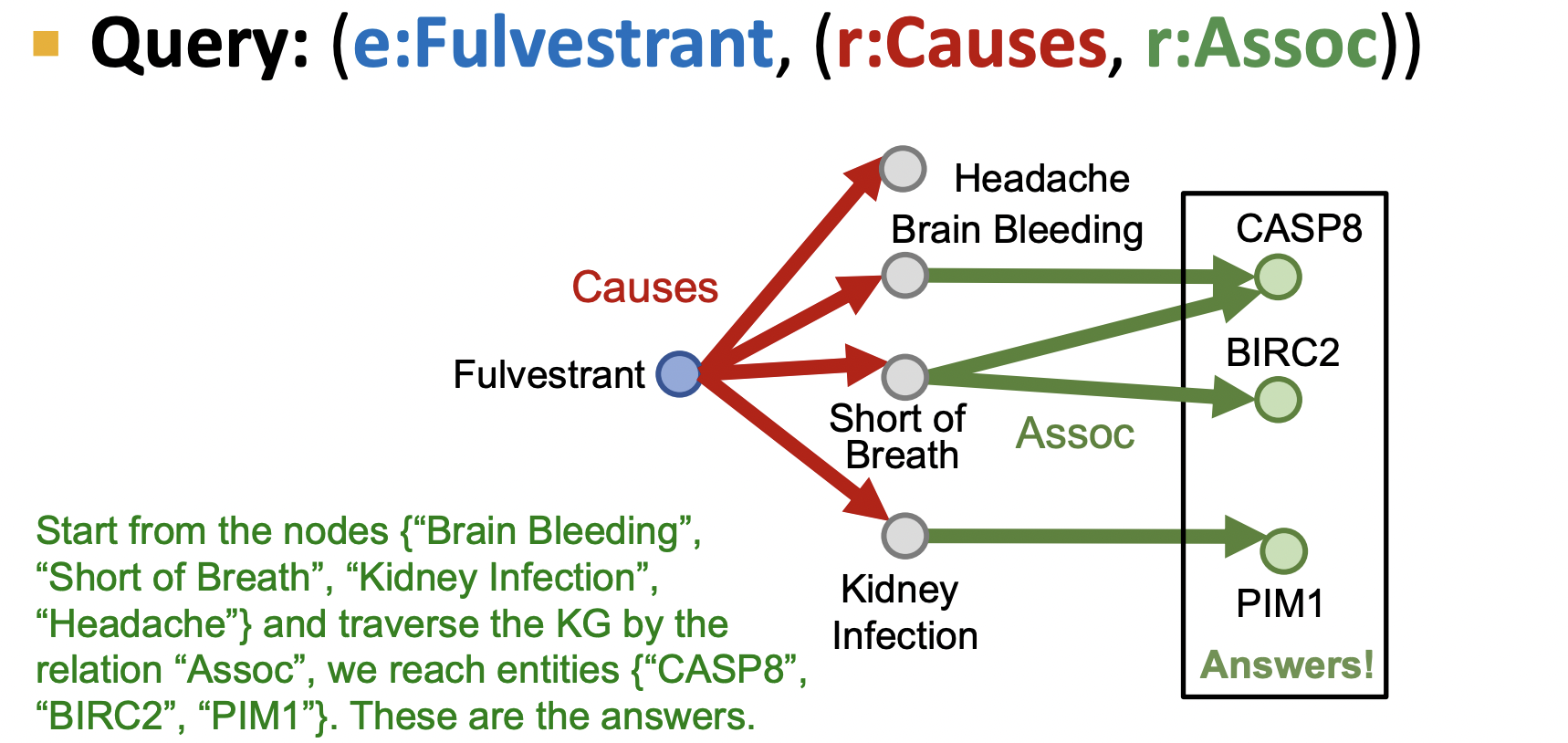
2.2 TransE 擴展
前面我們看到知識圖譜往往是缺失的,那么是否可以先補足知識圖譜再做查詢?
如果先做補足,知識圖譜通常非常大,這會導致后續查詢時間指數上升.因此我們希望在回答任意問題時,能夠隱式推理缺失的答案.
還記得TransE嵌入模型的原理嗎?空間向量平移,得分函數為起始節點向量加關系向量減去結束節點向量,其原理是起始節點向量與結束節點存在連接,其起始節點向量加關系向量就越靠近結束節點;對照問答場景,這起始節點向量加關系向量不就是問題的嵌入嗎?如果它們之間是存在連接的,那么兩者就越接近,那說明這個結束節點就是答案.
因此我們的核心問題就是將TransE 擴展為問題嵌入, 得分函數 f r = ? ∣ ∣ h + r ? t ∣ ∣ , h + r = > ( v a + r 1 + . . . + r n ) 得分函數f_r=-||h+r-t||,h+r=>(v_a+r_1+...+r_n) 得分函數fr?=?∣∣h+r?t∣∣,h+r=>(va?+r1?+...+rn?),其中 v a v_a va?是節點嵌入,r是關系嵌入,其計算原理使其獨立于中間過程的那些節點集,同時TransE模型本身對傳遞關系的表征能力也保證了這樣操作后不會丟失信息.

使用TransE 的路徑查詢步驟如下所示:
1、訓練TransE 模型,該步驟與前面提到的知識圖譜嵌入模型學習一致,輸入三元組(h,r,t),學習實體和關系的向量表示,使得對于每個正確三元組,h+r≈t,同時最小化錯誤三元組的得分。
2. 預測階段(路徑查詢):輸入是 v a v_a va?頭部節點,關系路徑[r1,r2,r3,…,rn]
- 向量映射:從訓練好的嵌入矩陣中獲取頭實體和關系向量
- 路徑向量合成:將路徑中的關系向量累加
- 目標位置計算:將頭實體向量與路徑向量相加,得到預測的目標位置 t ′ t' t′
- 相似度匹配:計算 t ′ t' t′與所有實體向量的距離(如L2距離或余弦相似度),排序后得到最可能的尾實體。
- 輸出按相似度排序的尾實體列表(如Top-K個候選實體)
該方法的實現細節中,多跳路徑的隱式推理未顯式考慮中間實體約束,可能影響復雜推理的準確性。二是關系向量直接相加可能導致誤差累積(尤其是長路徑).當然這個模型的潛在限制不是本課核心關注點,感興趣的小伙伴可以自行搜索相關優化模型.
2.3 TransE 能力分析
我們看到TransE可以解決路徑查詢問題,那么它可以同時解決連詞查詢問題嗎?
先來看看連詞查詢,直接遍歷知識圖譜是如何遍歷的,如下圖所示,遍歷兩條路徑,其分別以ESR2,Short of Breath 為起始節點,兩條路徑的結尾交互點為答案.
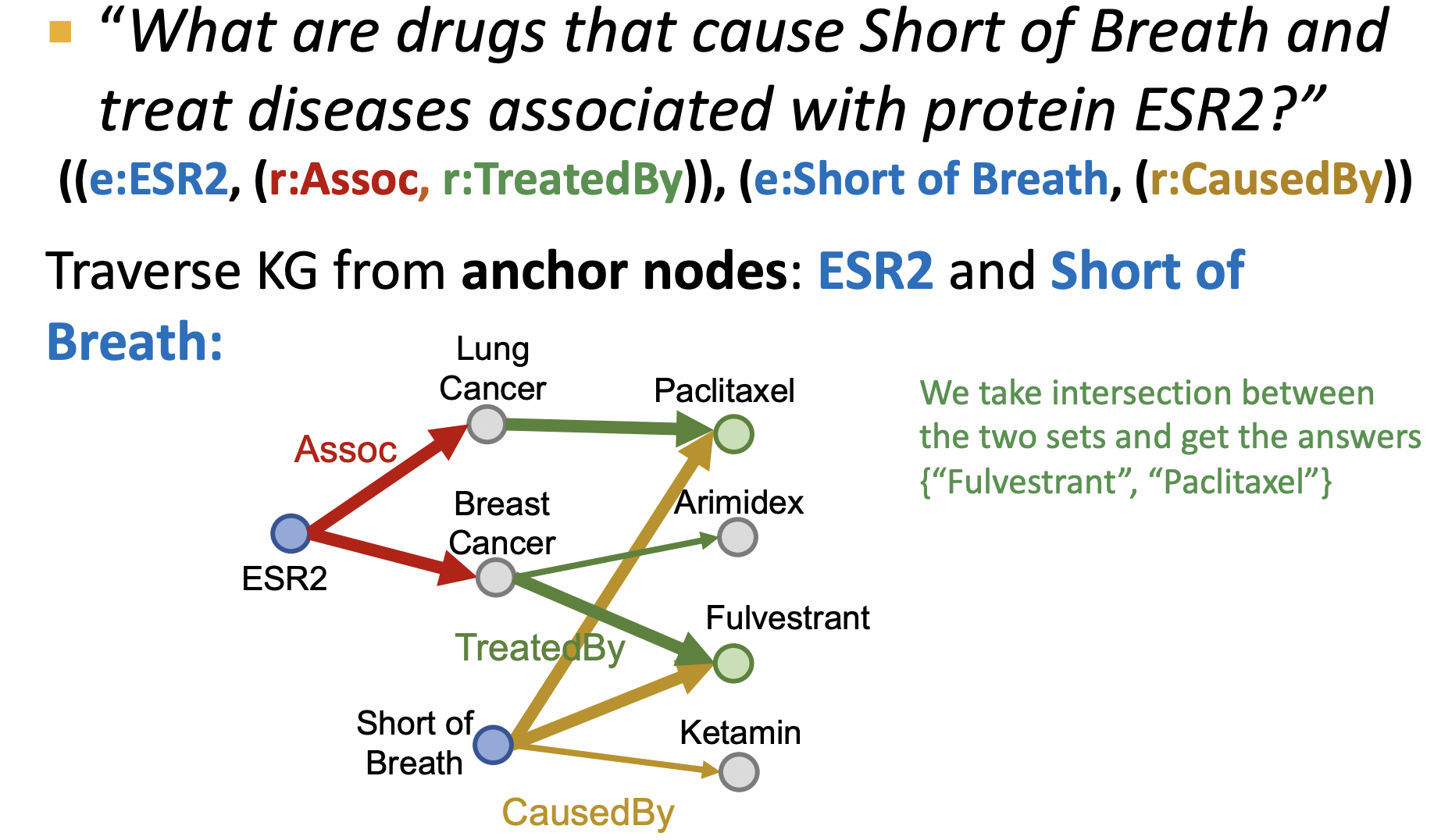
這個遍歷在TransE,則為先得到兩條路徑的嵌入p1,p2, p 1 ≈ t 1 p1\approx t1 p1≈t1, p 2 ≈ t 2 p2\approx t2 p2≈t2,t1=t2時為答案,但因為是線性的,不同關系對應的平移方向可能沖突(例如 r1 和 r2 方向不一致),導致無法找到同時滿足條件的解;同時兩條路徑,會導致累積誤差更加嚴重,從而更難找到合理的答案,因此TransE無法有效的解決連詞查詢問題.
三、連詞查詢(conjunctive queries)
該類型查詢需要一個更復雜的方法去實現,其(Query2box)箱型查詢模型是代表,接下對該模型原理,訓練,特點,表征能力,以及連詞查詢的擴展進行闡述.
3.1 Query2box 原理
回顧TransE模型是向量平移原理,節點,關系都嵌入到一個向量空間,其嵌入范圍是點狀的,且平移相加,會忽略多次平移中間的節點集的限制.最關鍵的是無法很好表現與的邏輯操作.這個數學直觀會想到集合之間的交集操作,換到集合空間里很容易想象出是多個箱子疊加的部分就是交集.
因此Query2box 原理是將節點嵌入為一個箱子,關系作為偏移方向,可以將原箱子映射得到一個通過該關系把箱子投影,生成了新箱子;其支持的邏輯操作如下:
-
聯合查詢(OR 操作):通過取兩個盒子的并集實現。
兩個盒子的并集在空間中被表示為包含范圍更大的一個盒子。
并集操作調整 c 和 r 的取值。 -
交集查詢(AND 操作):通過取兩個盒子的交集實現。
交集操作調整盒子的范圍使得最終盒子嵌入更加緊致,表示符合兩個查詢的共同答案。 -
關系追蹤(投影操作):從當前盒子沿著特定關系跳轉到下一個范圍。 通過關系嵌入來修改盒子的中心和范圍。
如下圖所示,節點ESR2通過關系Assoc投影到一個紅色的新箱子,同樣的原理重復該過程直到最后一個關系投影,取兩條路徑最后的投影箱子進行與邏輯操作得到最后的箱子為當前連詞查詢的答案.
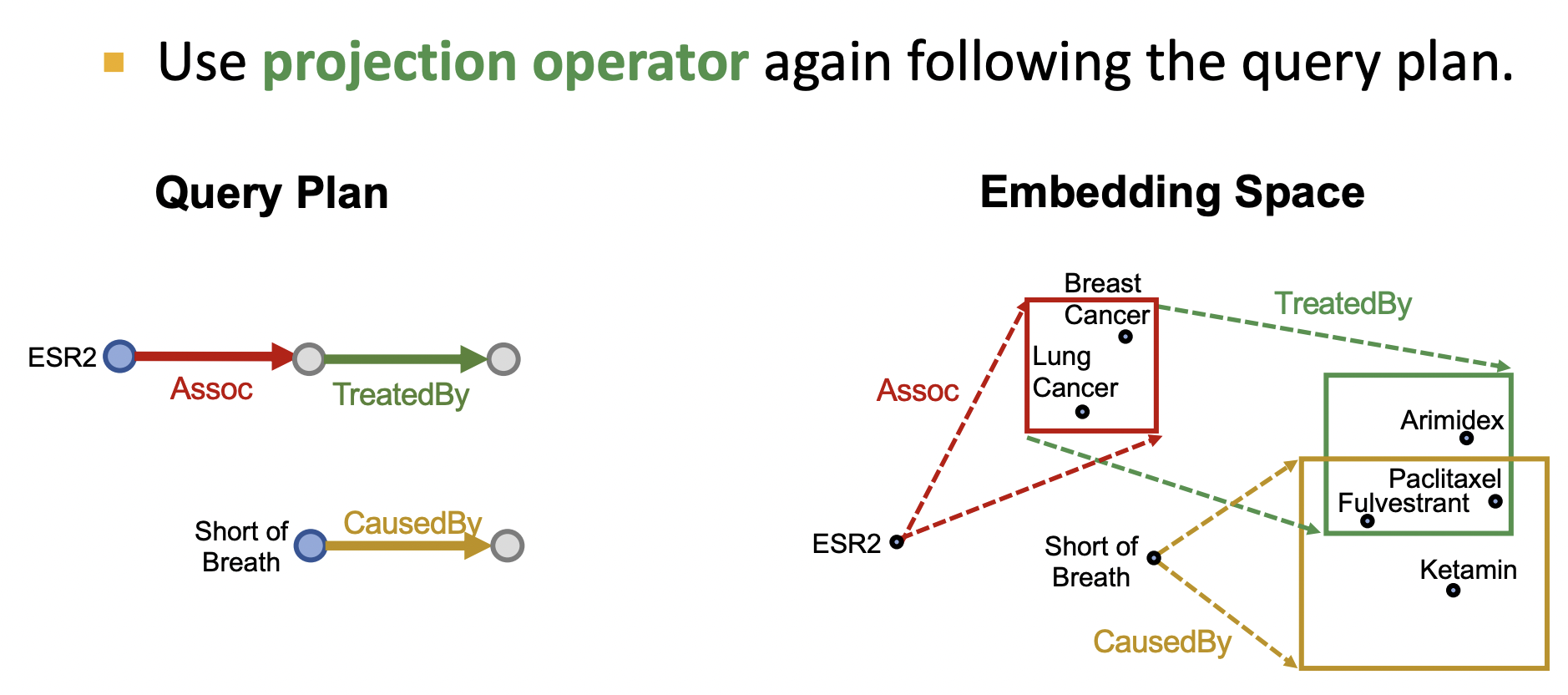
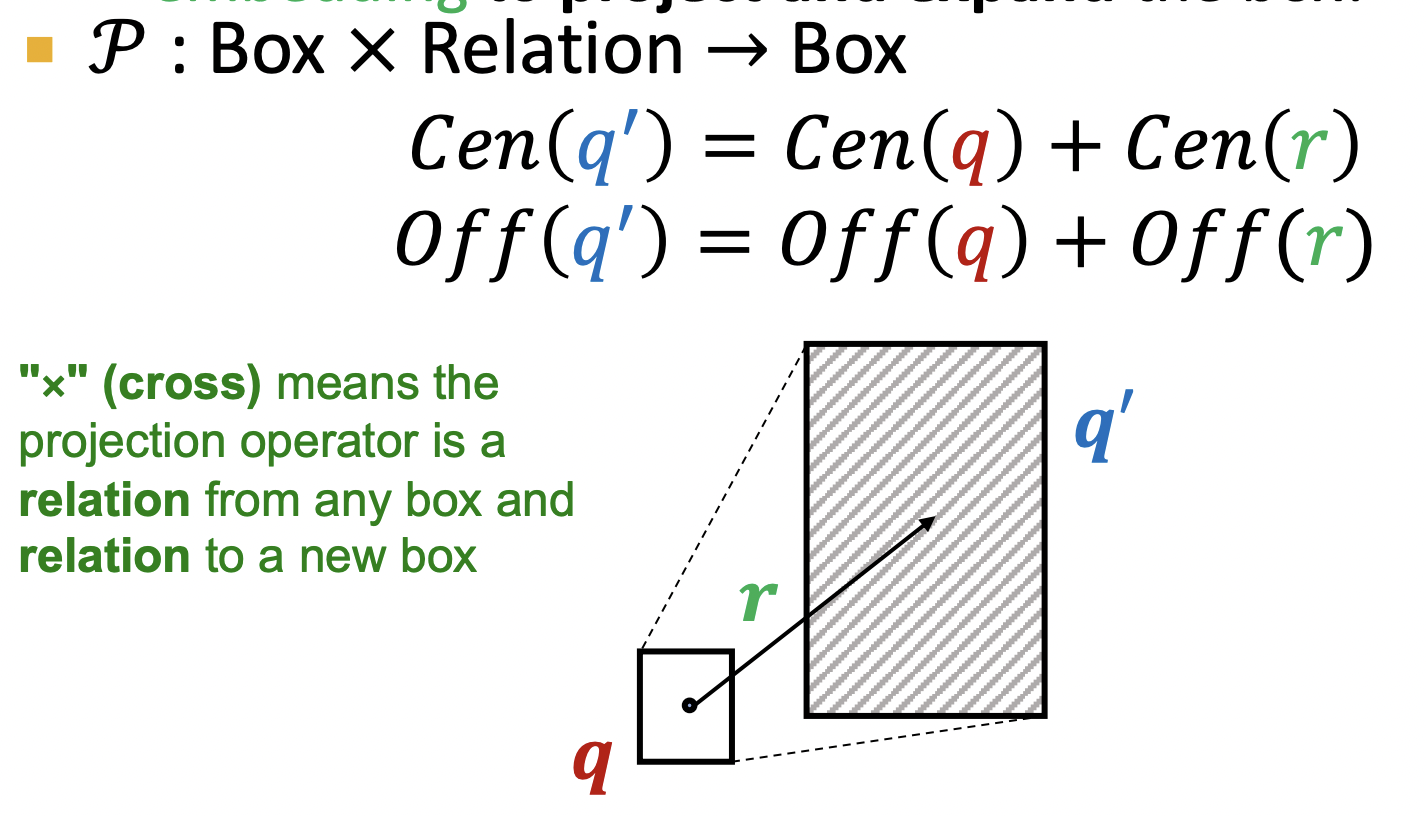
1)、投影
首先一個箱子嵌入定義為中心點的與偏移量,如一個箱子q由中心點cen(q)=(4,3),偏移量off(q)=(1,2);關系r指明投影方向與偏移量,得到一個新箱 q ′ q' q′,其投影操作如下圖所示.
2)、交集查詢(AND 操作)
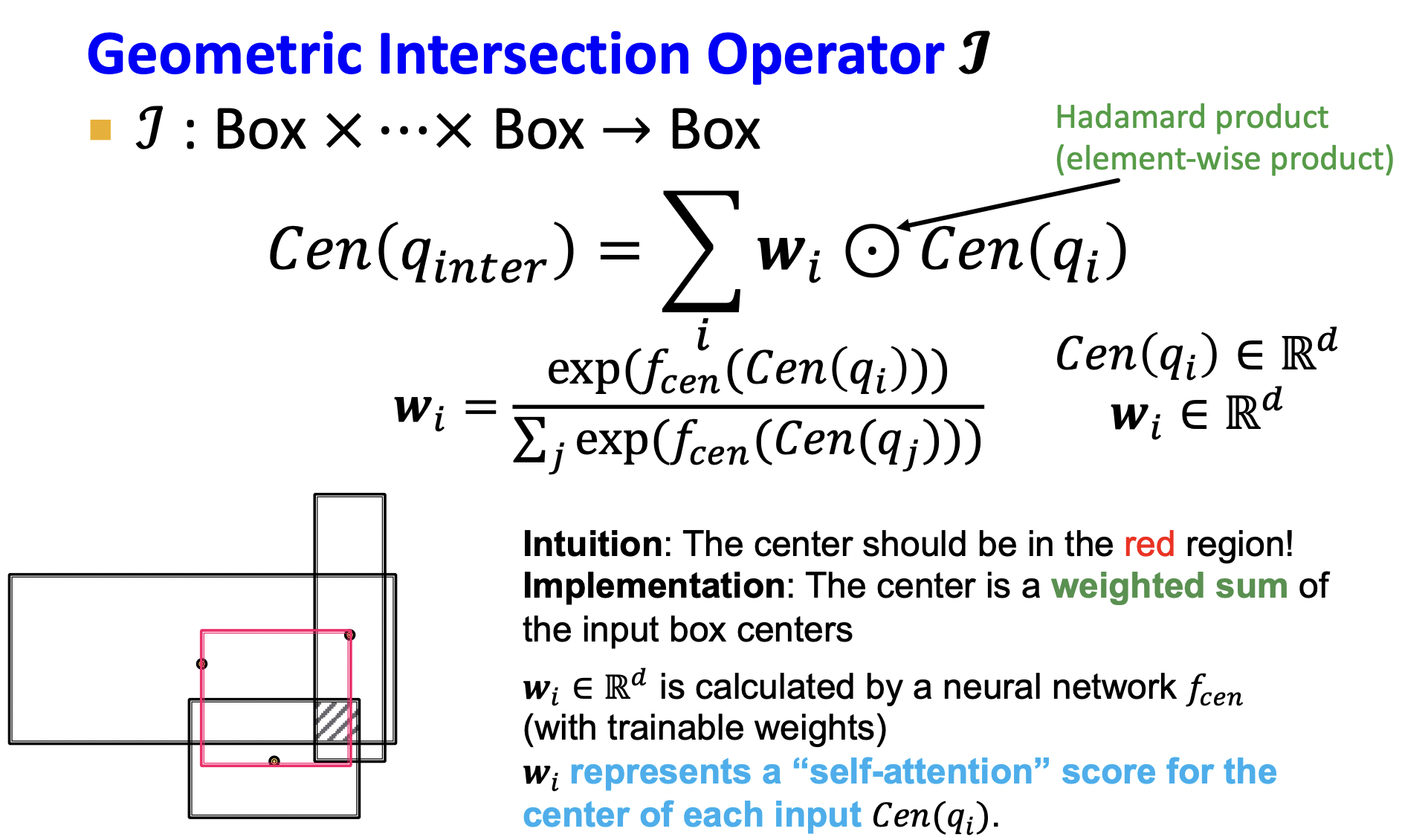
交集是求多個箱子交集的部分,我們知道箱子由中心點,偏移量表示,因此就是求取交集后的新箱子的中心點與偏移量.
- 首先看中心點,直觀上感覺交集的中心點應該在多個中心點圍成的范圍內,因此可以表示為每個箱子中心點的線性和,其中每個箱子的權重不一樣,該權重由模型學習得到.
- 偏移量直觀為交集的箱子最小偏移量,為了更精準,乘以一個收縮量,該收縮量由模型學習得到.

3)、聯合查詢(OR 操作)
在聯合查詢前,我們先要定義箱子之間的距離計算,其距離可通過歐幾里得計算,也可以使用其它方法.

有了箱子的距離后,假設我們的答案是V ,問題有m個,其問題間進行OR操作,則其先對每個一問題求其嵌入,然后進行聚合,其聚合方式如下,其理解為,答案只要是其中一個問題的答案,就應該是聯合問題的答案,因此取所以箱子距離之間的最小值.

4)、and_or操作
當一個查詢里既有and,也有or時,最佳實現是將查詢先拆解為多條and查詢,在最后一步再or查詢.其原因是不拆解無法在當前維度空間得到嵌入,需要嵌入到更高維度(如下圖所示),為在當前維度實現,就要進行先拆解,然后嵌入,最后or.

3.2 Query2box 訓練
整體的訓練過程與TransE 類似,比較特別的在于這是查詢場景的嵌入,因此正負樣本采集時會有所差異.接下我們先看訓練步驟:
- 1、從知識圖譜中采樣得到問題集q,答案集 v v v與非答案集 v ′ v' v′
- 2、計算q的嵌入
- 3、計算打分函數 f q ( v ) f_q(v) fq?(v)
- 4、優化loss,正確的越大越好,錯誤的越小越好
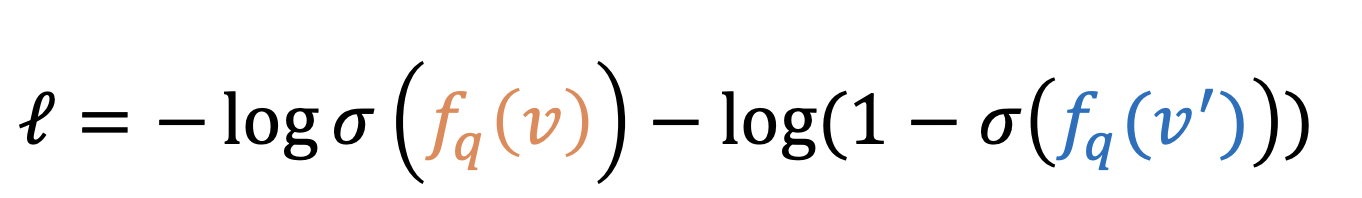
1)、正負樣本采樣
從開章我們就知道問題分為三種類型,因此采樣時候,各類型均要包含在內,
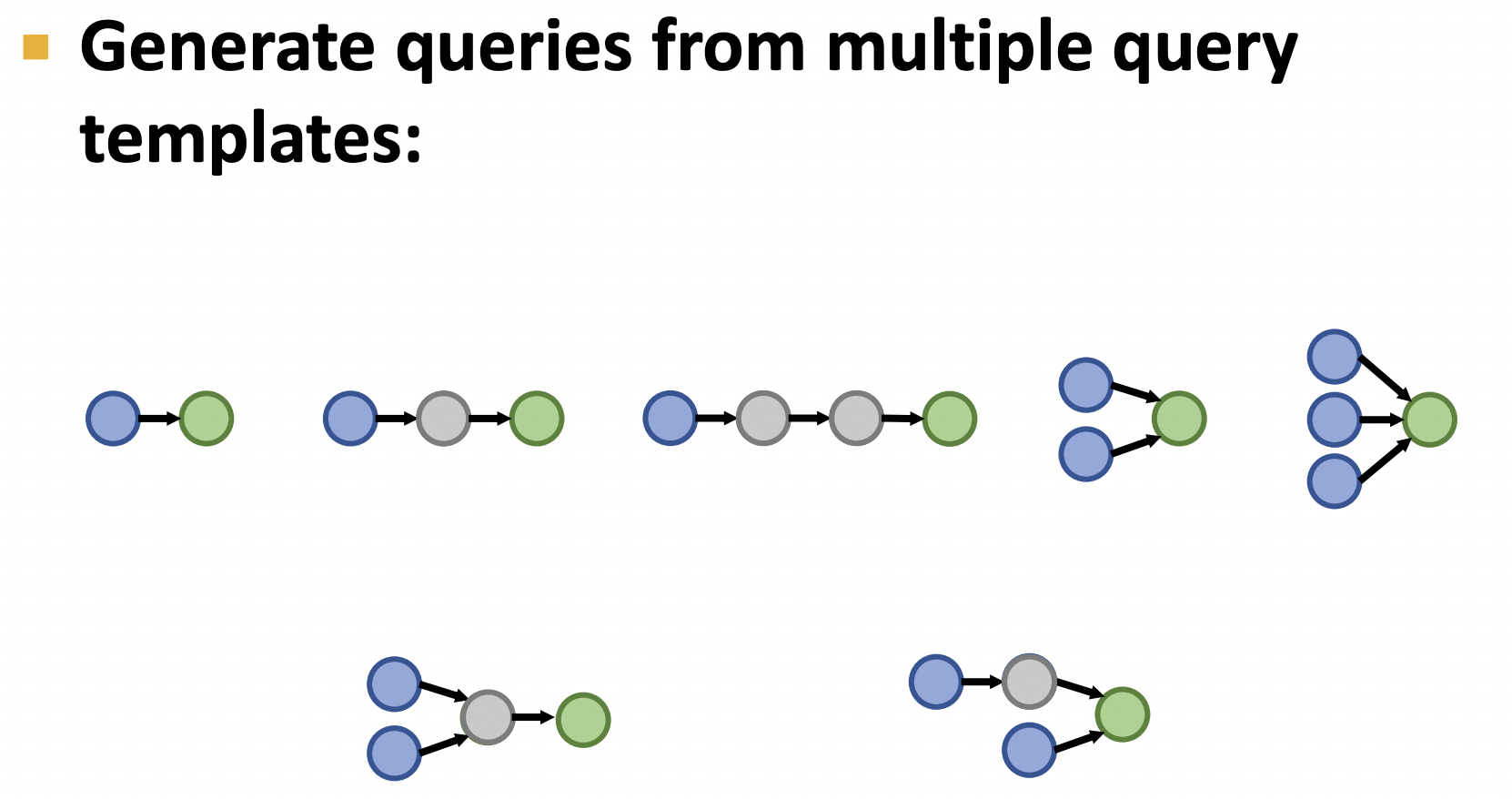
以其中一個問題類型為例,其綠色節點為答案.
- 我們從答案節點開始(隨機選擇一個),沿著圖中的邊遍歷,直到所有起始節點均獲得;
- 有了起始節點后再沿著圖遍歷得到滿足條件的所有答案;
- 得到了問題集,答案集與非答案集.
接下來以下圖問題類型為例,我們隨機采樣到Fulverstrant 為答案節點,隨機選取與其相連的邊如TreatedBy獲得與該邊相連的節點Breast Cancer,同樣選取與其相連的邊如Assoc得到起始點ESR2;重復隨機選取邊的過程,將得到問題節點集與關系集,再通過問題節點集與關系集(構成多個Query template 樣本)得到Fulverstrant再內的其它答案節點,得到答案集,不在問題集與答案集里的節點則為非答案節點,采樣得到非答案集,
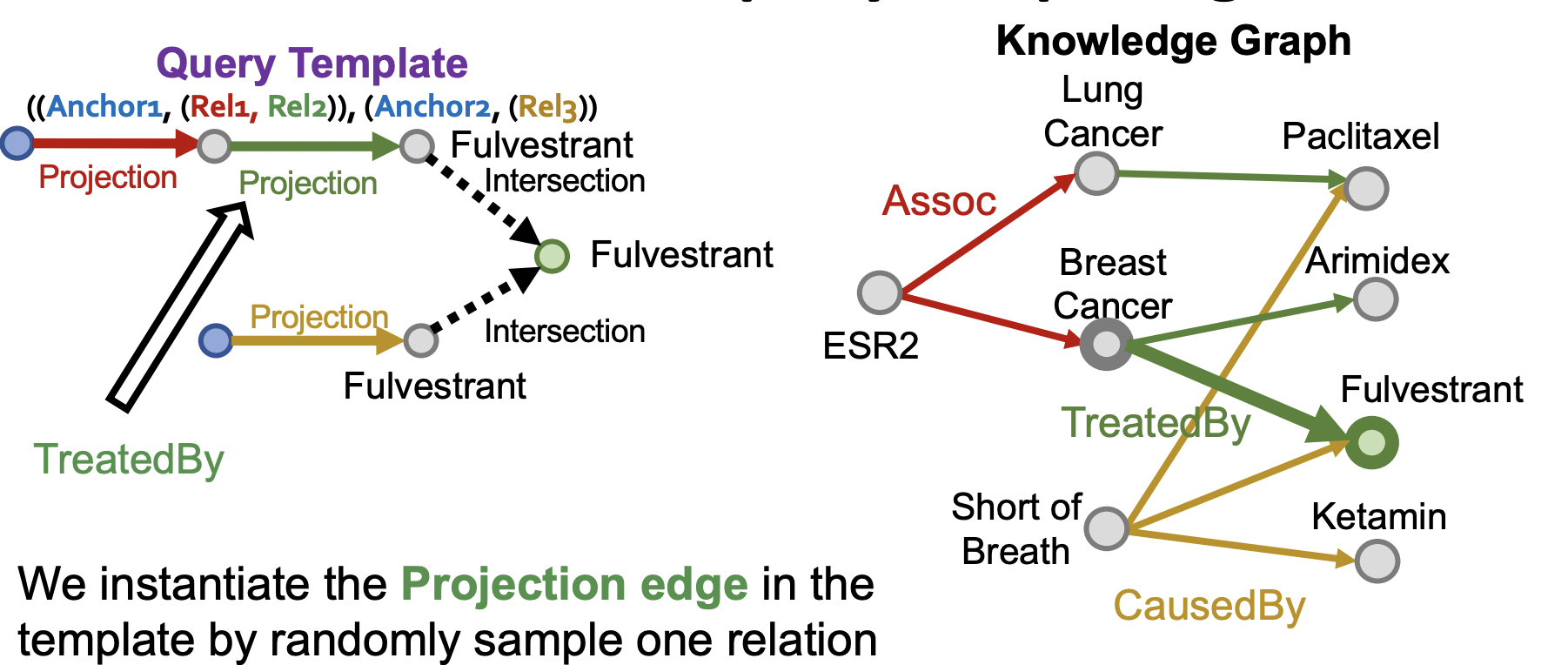
2)、查詢過程可視化
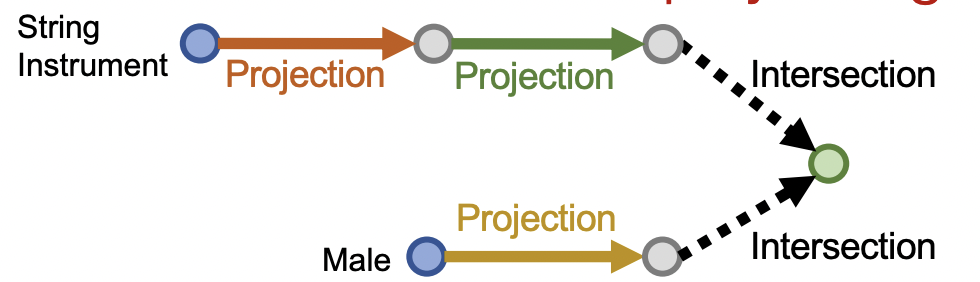
以問題:“List male instrumentalists who play string instruments”為例,將其嵌入到2維空間,這樣可以觀測其嵌入過程的變化,其問題分解路徑如下
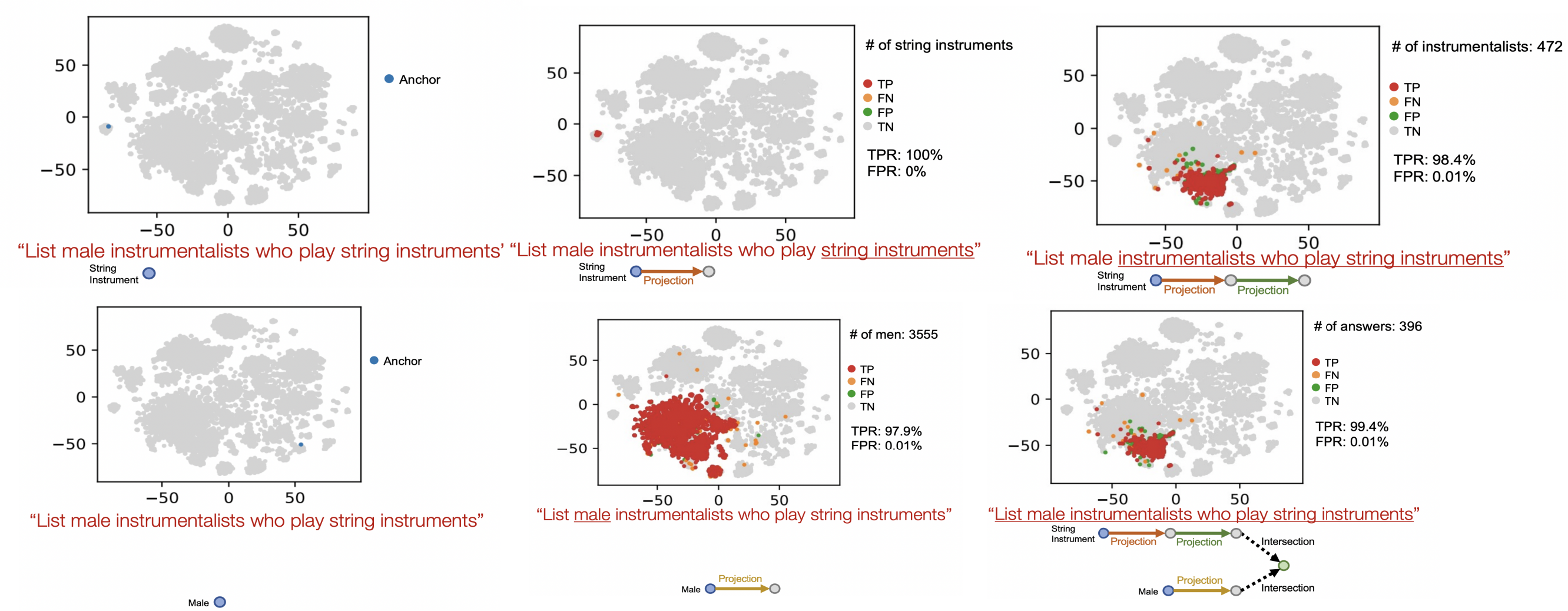
其查詢過程如下圖所示
四、總結
本課主要講知識圖譜下的查詢應用如何實現,首先對查詢進行分析,通過其不同類型,與知識圖譜嵌入模型特點聯系起來,其中路徑類查詢使用前面的TransE 即可解決,因為其傳遞的表達能力;而有交集,OR類的查詢,則需要更復雜的嵌入模型,文中介紹了queryBox的嵌入算法,該嵌入算法為箱子的思想,類比集合操作,從而實現該類查詢的學習;深入介紹了queryBox的嵌入算法的原理,訓練過程,最后對查詢可視化進行了一個例子的說明,加深對嵌入模型在查詢應用上的理解.


)











)




