引言
自然語言處理(Natural Language Processing, NLP)是人工智能領域中最具活力和潛力的分支之一。從智能客服到機器翻譯,再到語音識別,NLP技術正以其強大的功能改變著我們的生活方式和工作模式。
Catalyst的推出極大降低了NLP技術的應用門檻。它支持文本分類、實體識別等多種功能,并配備了詳盡的API文檔和預訓練模型,讓開發者能夠快速上手并構建功能強大的應用。無論是打造智能對話系統、自動化文本分析工具,還是實時監測平臺,Catalyst都能提供可靠的支持。
本文將通過一個具體的實踐任務——使用Catalyst進行操作,深入展示如何在.NET環境中應用NLP技術。這個實踐任務貼近實際業務需求,不僅能幫助讀者掌握Catalyst的核心用法,還能加深對NLP基本原理的理解。
Catalyst簡介
在深入實踐之前,我們先來了解Catalyst的本質及其在NLP開發中的價值。
什么是Catalyst?
Catalyst是一個開源的.NET庫,專為自然語言處理任務設計,旨在為.NET開發者提供一個簡單而強大的工具集。它支持多種NLP功能,如文本分類、命名實體識別(NER)和詞性標注,并通過直觀的API和預訓練模型,幫助開發者快速構建和部署智能應用。
Catalyst融合了先進的機器學習和深度學習技術,它與.NET生態系統無縫集成,開發者可以使用C#或F#直接調用其功能,無需轉向Python或其他語言環境。
此外,Catalyst還支持與主流NLP框架(如Transformers、spaCy)的集成,使開發者能夠輕松利用最新的技術成果。無論是處理簡單的文本分類,還是構建復雜的對話系統,Catalyst都能提供靈活而高效的解決方案。
Catalyst的優勢
相比其他NLP工具,Catalyst具有以下獨特優勢:
- 無縫集成:通過NuGet包分發,開發者可在Visual Studio等IDE中輕松安裝使用。
- 功能全面:支持文本分類、實體識別等多種任務,覆蓋廣泛的應用場景。
- 預訓練支持:內置多種預訓練模型,開箱即用,同時支持模型微調。
- 性能優異:針對.NET環境優化,確保高效的數據處理和模型推理。
- 社區活躍:擁有開放的社區支持,開發者可通過GitHub等問題平臺獲取幫助。
這些特性使Catalyst成為.NET開發者探索NLP的理想選擇。無論你是初學者還是資深開發者,都能借助Catalyst快速實現創意,開發出智能化的應用程序。
安裝和配置Catalyst
在使用Catalyst之前,我們需要完成其安裝和基本配置。以下是詳細步驟,確保你的開發環境順利就緒。
安裝Catalyst
Catalyst通過NuGet包管理系統分發,安裝過程簡單明了:
- 打開Visual Studio,創建一個新的.NET項目(如控制臺應用程序)。
- 在解決方案資源管理器中,右鍵項目,選擇“管理NuGet包”。
- 在NuGet包管理器中搜索“Catalyst”,選擇最新版本的“Catalyst”核心包并安裝。
- 根據需求,可選安裝附加包,如“Catalyst.Models.Chinese”以加載中文預訓練模型。
安裝完成后,項目將自動引用Catalyst的程序集,你即可開始編寫NLP代碼。
配置開發環境
Catalyst的配置相對簡單,通常無需復雜調整。為確保最佳體驗,建議以下設置:
- 目標框架:項目需使用.NET Core 3.1或更高版本,以保證兼容性。
- GPU加速(可選):若需使用GPU提升性能,需安裝CUDA工具包并配置環境變量,具體參考官方文檔。
- 模型下載:部分功能依賴預訓練模型,Catalyst支持自動下載,也可手動指定路徑。
注意事項
- 版本匹配:確保Catalyst版本與項目框架一致,避免兼容性問題。
- 網絡環境:首次使用可能需要下載模型,需確保網絡暢通。
- 開源許可:Catalyst遵循MIT許可證,可自由使用和修改。
完成以上步驟,你的開發環境已準備就緒,可以進入NLP開發的實戰環節。
文本處理基礎
在進一步使用之前,我們需要掌握文本處理的基本技能,包括文本加載、分詞、詞性標注和清洗。這些操作是所有NLP任務的基礎。
文本加載與分詞
Catalyst提供了便捷的工具來加載和分詞文本。以下是一個中文的簡單示例,注意安裝 NuGet 包Catalyst.Models.Chinese:
using Catalyst;
using Mosaik.Core;string text = "你好, 朋友";Catalyst.Models.Chinese.Register();// 創建中文NLP管道
Pipeline? nlp = Pipeline.For(Language.Chinese);// 處理文本
IDocument? doc = nlp.ProcessSingle(new Document(text, Language.Chinese));// 輸出分詞結果
foreach (IToken? token in doc.ToTokenList())
{Console.WriteLine(token.Value);
}Console.WriteLine(doc.ToJson());
輸出示例:
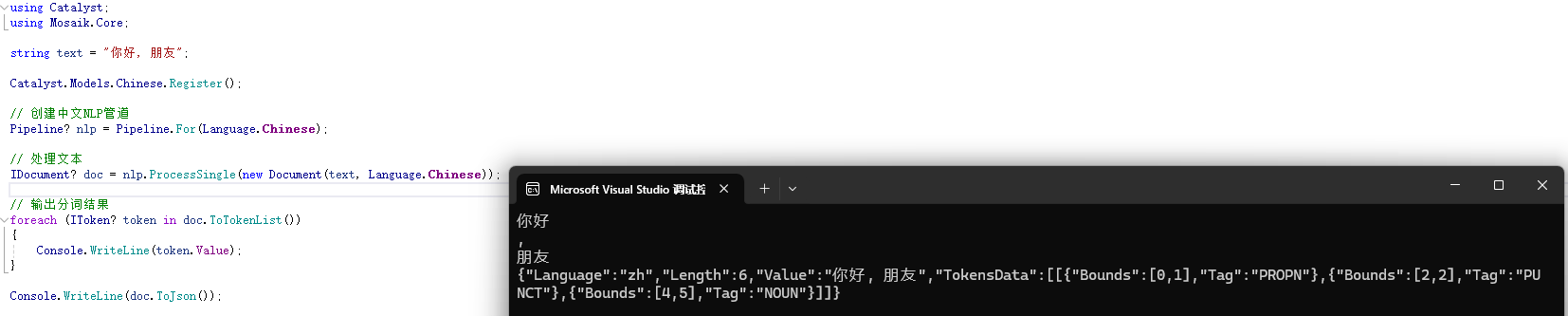
代碼解析:
Pipeline.For創建了一個針對英文的NLP處理管道。Document封裝了輸入文本及其語言信息。ProcessSingle對文本進行分詞,Tokens屬性返回分詞結果。
詞性標注
詞性標注是NLP的核心任務,用于識別每個詞的語法類別。Catalyst內置支持:
// 輸出詞性標注
foreach (var token in doc.ToTokenList)
{Console.WriteLine($"{token.Value}: {token.POS}");
}
輸出示例:

這里,token.POS返回詞性標簽,如名詞(NOUN)、動詞(PUNCT)等。
文本數據表示
Catalyst使用Document類表示文本數據,包含原始文本、分詞結果和詞性信息等。例如:
Console.WriteLine($"語言: {doc.Language}");
Console.WriteLine($"分詞數: {doc.TokensCount}");
輸出示例:
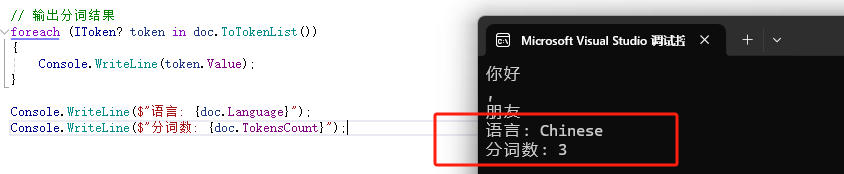
理解Document的結構有助于后續的高級任務。
實體識別實踐
掌握文本處理后,我們將通過實體識別任務展示Catalyst的實戰能力。實體識別分析旨在判斷文本的實體,在信息提取、機器翻譯、問答系統中應用廣泛。
使用預訓練模型
Catalyst提供預訓練實體識別分析模型主要有三類:
- Spotter:基于詞典的模型
- PatternSpotter:基于正則的模型
- AveragePerceptronEntityRecognizer:感知機模型
由于我嘗試了多次的中文文本,但都沒有取得比較好的效果,所以我改用了英文文本。
Spotter
Spotter 是 Catalyst(一個 C# 自然語言處理庫)中提供的一個實體識別工具,其主要作用是進行 基于詞典的實體識別(Dictionary-based Entity Recognition)。它通過一個預定義的實體詞典,快速識別和標注文本中的特定實體,適用于需要高效、定制化實體識別的場景。
主要功能
Spotter 的核心功能是通過匹配用戶提供的詞典來識別文本中的實體,具體包括:
- 詞典匹配:將文本中的詞或短語與預定義的實體列表進行精確匹配。
- 實體標注:將匹配到的文本片段標注為用戶指定的實體類型,例如“編程語言”、“公司名稱”等。
- 快速處理:基于詞典的直接查找使其速度快,適合實時或輕量級應用。
工作原理:
- 構建詞典:用戶需要為
Spotter提供一個包含目標實體的詞典,詞典條目可以是單個詞(如“C#”)或短語(如“New York”)。 - 文本匹配:在處理輸入文本時,
Spotter將文本分詞(tokens)后,與詞典中的實體進行逐一比對。 - 標注實體:當發現匹配時,
Spotter會為該文本片段添加實體標簽,例如標記“C#”為“ProgrammingLanguage”。
此外,Spotter 支持一些靈活性設置,例如通過 IgnoreCase 屬性忽略大小寫,從而提高匹配的適應性。
使用場景:
- 專有名詞:如人名、地點、組織名稱(例如“Microsoft”)。
- 技術術語:如編程語言(“Python”)、科學名詞等。
- 自定義實體:用戶可以根據需求定義特定領域的實體列表,例如產品名稱或品牌。
- 快速原型開發:在需要快速實現實體識別功能的場景中,
Spotter是一個簡單高效的選擇。
使用方式
Spotter spotter = new Spotter(Language.Any, 0, "programming", "ProgrammingLanguage")
{Data ={IgnoreCase = true}
};spotter.AddEntry("C#");
spotter.AddEntry("Python");
spotter.AddEntry("Python 3");// 條目可以有多個詞,會自動在空格處進行標記化
spotter.AddEntry("C++");
spotter.AddEntry("Rust");
spotter.AddEntry("Java");Pipeline? nlp = Pipeline.TokenizerFor(Language.English);
nlp.Add(spotter);Document docAboutProgramming = new Document(Data.SampleProgramming, Language.English);nlp.ProcessSingle(docAboutProgramming);PrintDocumentEntities(docAboutProgramming);輸出示例
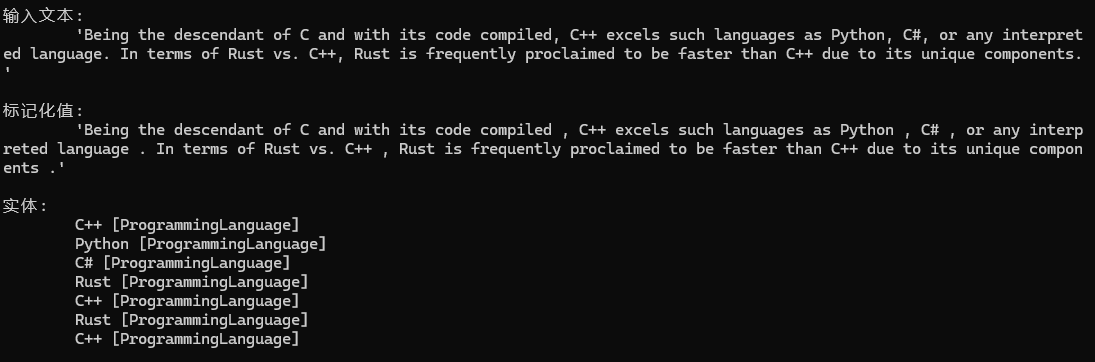
PatternSpotter
該類的主要作用是進行基于模式的實體識別(Pattern-based Entity Recognition),允許用戶通過定義自定義的語言模式來識別和標注文本中的特定實體或結構。
主要功能
PatternSpotter 提供了一種靈活的方式,用于在文本中識別符合特定語言規則的片段,例如:
- 語法結構:如 “is a” 后面的名詞短語。
- 詞性組合:如動詞后跟多個名詞或專有名詞。
- 自定義實體:根據用戶定義的規則識別特定類型的實體。
這種方法類似于使用正則表達式進行文本匹配,但 PatternSpotter 是在**標記化(tokenized)**的文本上操作,結合了詞性(POS)、實體類型等語言特征,使得模式匹配更加智能和精確。
工作原理
- 定義模式:用戶通過 PatternSpotter 類定義一個或多個模式,這些模式可以基于詞性、詞形、實體類型等特征。
- 文本:在處理文本時,PatternSpotter 會掃描標記化的文本,尋找與定義的模式相匹配的片段。
- 標注實體:一旦找到匹配的片段,PatternSpotter 會將這些片段標注為用戶指定的實體類型。
使用場景
- 義實體識別:識別特定領域中的專有術語,如法律文件中的法律條款或醫療文本中的疾病名稱。
- 關系抽取:識別文本中的特定關系模式,如 “X 是 Y” 結構中的 X 和 Y。
- 文本結構分析:識別文本中的特定句法結構,如引用、列表等。
使用方式
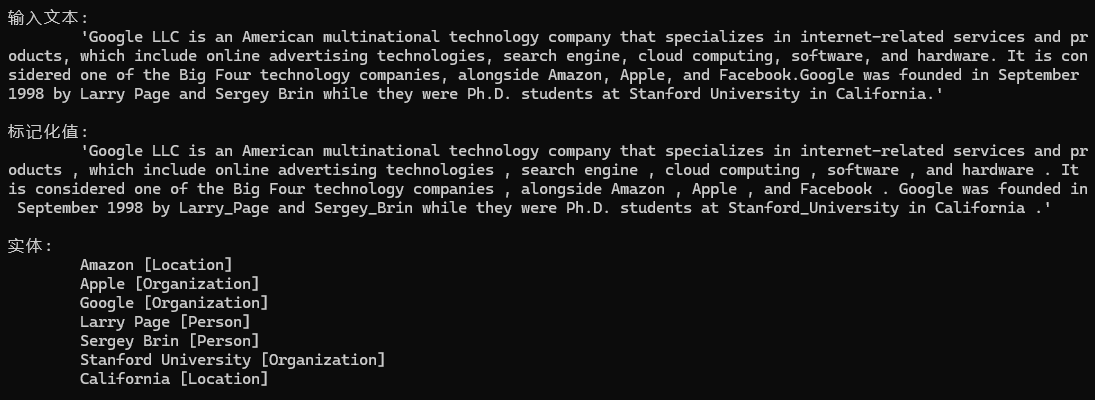
PatternSpotter isApattern = new PatternSpotter(Language.English, 0, tag: "is-a-pattern", captureTag: "IsA");
isApattern.NewPattern("Is+Noun",mp => mp.Add(new PatternUnit(P.Single().WithToken("is").WithPOS(PartOfSpeech.VERB)),new PatternUnit(P.Multiple().WithPOS(PartOfSpeech.NOUN, PartOfSpeech.PROPN, PartOfSpeech.AUX, PartOfSpeech.DET, PartOfSpeech.ADJ))
));
nlp.Add(isApattern);
輸出示例1
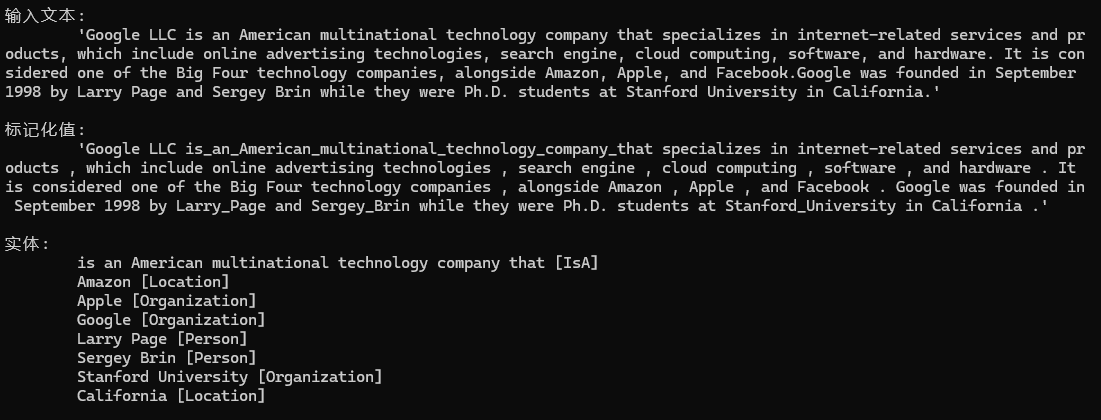
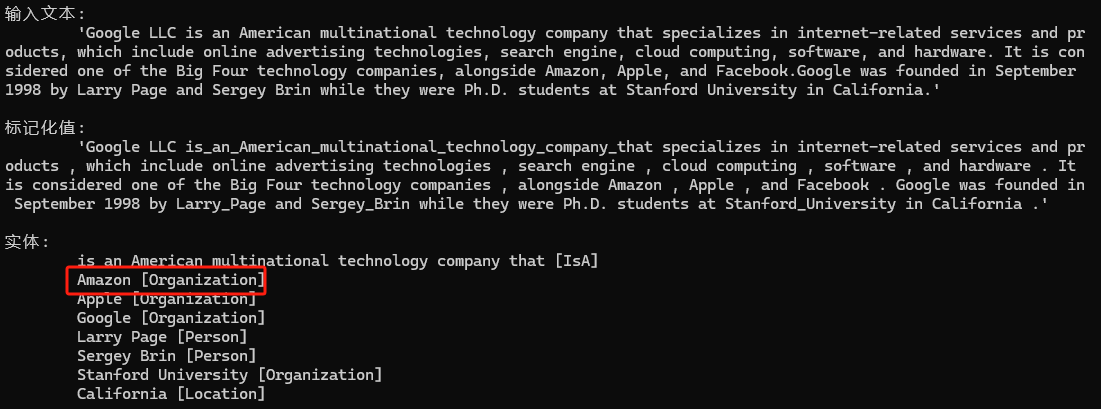
在這個示例里面Amazon既是地點名稱,又是企業組織的名稱,所以可以考慮使用糾錯類Neuralyzer,幫助我們得到想要的答案。
Neuralyzer neuralizer = new Neuralyzer(Language.English, 0, "WikiNER-sample-fixes");
neuralizer.TeachForgetPattern("Location", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon").WithEntityType("Location"))));
neuralizer.TeachAddPattern("Organization", "Amazon", mp => mp.Add(new PatternUnit(P.Single().WithToken("Amazon"))));// 將 Neuralyzer 添加到管道中
nlp.UseNeuralyzer(neuralizer);
輸出示例2
現在你可以看到Amazon被正確識別為實體類型Organization.
AveragePerceptronEntityRecognizer
利用**平均感知機(Average Perceptron)**算法來訓練和執行實體識別任務。
AveragePerceptronEntityRecognizer 利用**平均感知機(Average Perceptron)**算法來訓練和執行實體識別任務。它的核心功能包括:
主要功能
- 訓練模型:通過帶標簽的訓練數據(如 WikiNER 數據集),學習如何識別不同類型的實體。
- 實體識別:對新的文本進行處理,識別并標注出其中的命名實體。
- 多語言支持:支持多種語言的實體識別,適應不同語言環境下的需求。
2.##### 工作原理
- 特征提取:將輸入文本分解為標記(tokens),并提取每個標記的特征,例如詞形、詞性、上下文信息等。
- 分類:使用平均感知機算法對每個標記進行分類,判斷其是否屬于某個實體類別。
- 實體標注:根據分類結果,將連續的標記組合成完整的實體,并賦予相應的標簽(如“人名”、“地點”)。
平均感知機算法是感知機的一種改進版本,通過對多次迭代的權重取平均值,提升了模型的穩定性和泛化能力,使其在處理大規模文本數據時表現更為出色。
使用場景
- 信息抽取:從新聞文章、社交媒體等文本中提取關鍵信息,如公司名稱、事件地點等。
- 問答系統:識別用戶提問中的實體,以便提供更精準的回答。
- 文本分析:作為預處理步驟,為情感分析、主題建模等任務提供實體信息。
它通過高效的訓練和識別能力,幫助開發者從文本中提取結構化的實體信息,適用于多種 NLP 應用場景。
使用方式
本示例使用預訓練的 WikiNER 模型,詳情請查看 https://github.com/dice-group/FOX/tree/master/input/Wikiner。
為英文創建一個新的管道,并將 WikiNER 模型添加到其中
Pipeline? nlp = await Pipeline.ForAsync(Language.English);
nlp.Add(await AveragePerceptronEntityRecognizer.FromStoreAsync(language: Language.English, version: Version.Latest, tag: "WikiNER"));
輸出示例
Catalyst的意義與挑戰
Catalyst為.NET開發者帶來了NLP的強大能力,但其應用也伴隨著深遠意義和現實挑戰。
意義
- 用戶體驗:分析和對話系統提升交互質量。
- 效率提升:自動化文本任務節省資源。
- 全球化:多語言支持助力跨國應用。
挑戰
- 模型優化:需根據任務選擇合適模型并調優。
- 性能瓶頸:實時應用中需平衡速度與資源。
- 隱私保護:處理用戶數據需遵守法規。
- 文化差異:多語言模型需適應多樣化語境。
技術倫理
Catalyst不僅是一款工具,更啟發我們思考NLP的深層問題:
- 倫理考量:模型偏見可能導致不公,開發者需確保公平性。
- 隱私權衡:數據處理需兼顧功能與用戶權益。
這些議題提醒我們,開發者具備技術與倫理的雙重素養。
結語
本文通過Catalyst的基礎知識、安裝配置、文本處理、實體識別分析實踐及意義挑戰的全面探討,為.NET開發者提供了一份深入的NLP指南。Catalyst以其易用性和強大功能,為開發者開啟了智能語言處理的大門。希望你能從中獲得啟發,加深自己對.NET的理解和使用!
參考鏈接
https://github.com/curiosity-ai/catalyst/blob/master/samples/EntityRecognition/Program.cs
)





)












