1.?客戶端類型? ?推薦場景? ?版本兼容性?
Elasticsearch Java API Client 新項目、ES 8.x+集群 8.x及以上
Spring Data Elasticsearch Spring生態項目、簡化ORM操作 ES 7.x-8.x(需版本匹配)
Low-Level REST Client 需要底層HTTP控制、兼容多版本ES 全版本
high-level已經被棄用。
2.ik_smart 分出后不再細分。程序員
ik_max_word. 程序員 程序 員 多次遞歸分解。
3.ELK:
典型架構演變
?基礎架構?:
Beats/Logstash → Elasticsearch → Kibana
適用于小型系統,資源占用低,但缺乏緩沖和復雜處理能力
。
?生產級架構?:
Beats → Kafka → Logstash → Elasticsearch → Kibana
引入消息隊列(如Kafka)緩沖數據,支持高并發和大規模日志處理
。
?混合架構?:
結合Beats和Logstash優勢,Beats負責輕量采集,Logstash處理復雜過濾和格式轉換
。
4.原理:
構建了詞到text的映射:

5.為什么使用nested object 嵌套對象
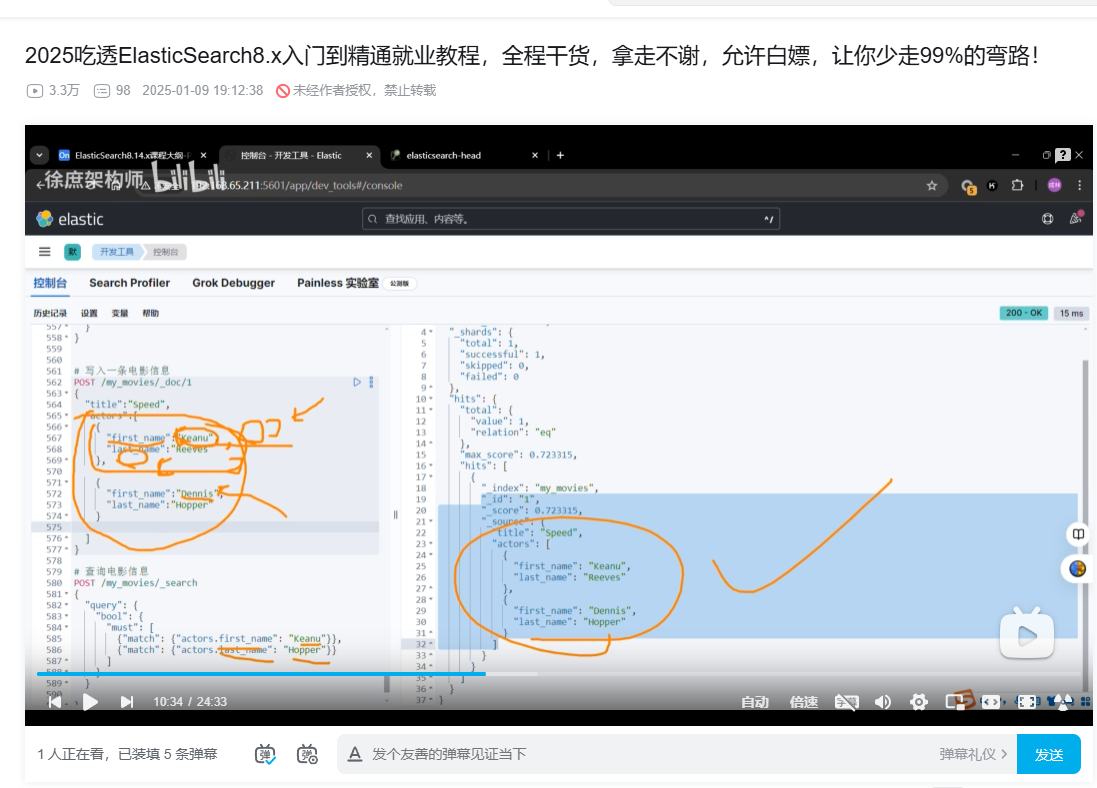
es存儲時對 數組對象的屬性做了扁平化處理。
比如firstName 單獨生成一個數組,把其他對象的這個字段一起存起來。
這樣在嘗試多個屬性的與查詢時,會遇到非預期結果。
如圖,只要一個屬性匹配到就會出結果。
所以使用nested object.
“tie”表示“平局、膠著”,“break”意為“打破”。組合后指通過特定規則或操作解決勢均力敵的狀態,常見于以下場景:
?體育比賽?
如網球中“搶七”(tie-break):當雙方局分6:6時,通過搶七局決勝負,避免比賽無限延長
。規則要求選手至少領先2分(如7:5或8:6)才能勝出,體現對“絕對優勢”的要求。
其他應用:板球通過“超級輪”(super over)、足球通過點球大戰打破平局
。
?編程與算法?
在哈希沖突或排序邏輯中,當兩個對象的哈希值(hashCode)相同且無法直接比較時,需通過額外規則(如內存地址、插入順序)決定優先級,稱為“tie-break order”[^用戶代碼注釋]。
無論是體育還是Elasticsearch,tie break的本質都是通過規則設計,在平衡狀態中選擇更合理的勝出方。
參考來源: concurrentHashMap中的比較hash大小 以及 Elasticsearch:dis_max查詢與tie_breaker參數
在 Elasticsearch 的 Mapping 定義中,title 字段下定義的 sdt 是子字段(sub-field)?,而非子對象或子屬性。這是通過 fields 參數實現的多字段(multi-field)特性,允許一個字段以不同方式被索引和分析。
一、核心概念解析
?fields 的作用?
fields 參數允許為同一字段定義多個子字段,每個子字段可指定不同的數據類型或分詞器。例如:
jsonjson復制markdown復制"title": {
“type”: “text”,
“analyzer”: “english”, // 主字段使用英文分詞器
“fields”: {
“sdt”: { // 子字段 sdt
“type”: “text”,
“analyzer”: “standard” // 使用標準分詞器
}
}
}
?主字段? title:默認使用 english 分詞器(如詞干提取、停用詞過濾)。
?子字段? title.sdt:使用 standard 分詞器(僅按空格分割,無詞干處理)。
這個是為實現multi-field 查詢而增加的子字段。(即表示此字段可以以其他類型或分詞方式去進行搜索。)
)









)








