文章目錄
- 1 不同的注意力機制
- 1.1 自注意力
- 1.2 多頭注意力
- 1.3 交叉注意力
- 1.3.1 基礎
- 1.3.2 進階
1 不同的注意力機制
在學習的過程中,發現有很多計算注意力的方法,例如行/列注意力、交叉注意力等,如果對注意力機制本身不是特別實現,很難進行自己的網絡設計。
1.1 自注意力
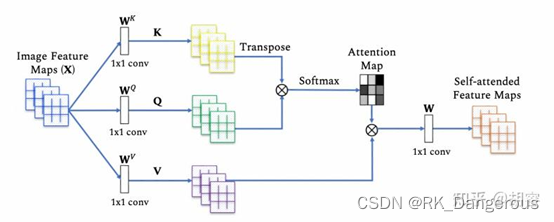
又拿出這張快被我盤包漿的圖。假設輸入序列的維度為(batch_size, seq_len, d_model),通過線性變換矩陣 W Q , W K , W V ∈ R d m o d e l × d m o d e l W^Q, W^K, W^V ∈ \mathbb{R}^{d_{model}×d_{model}} WQ,WK,WV∈Rdmodel?×dmodel?生成 Q Q Q/ K K K/ V V V,形狀為(batch_size, seq_len, d_model)。注意到, Q ? K T Q·K^T Q?KT再通過Softmax操作得到了Attention Map,是注意力權重矩陣(后續用 A A A表示)。通過之前的學習可以知道,注意力權重矩陣A的格式為二維矩陣,形狀為(batch_size, n,n),其中 n n n是輸入序列的長度(即token數量)。假設輸入序列長度為3,每個token的長度為4:
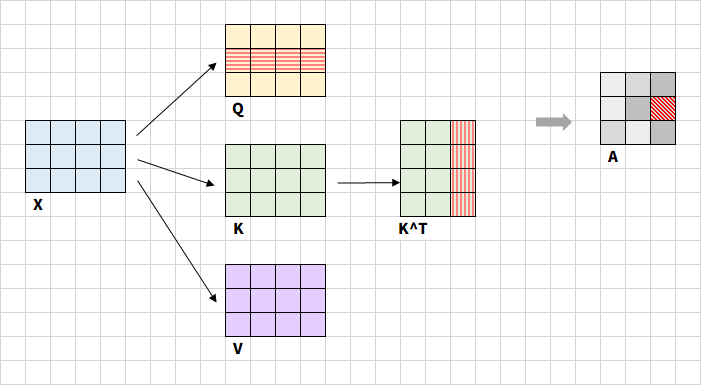
那么 A A A中紅色格子表示第二個token與第三個token的關聯,即 A [ i ] [ j ] A[i][j] A[i][j]每個元素表示輸入序列中第 i i i個序列對第 j j j個序列的注意力權重。這里要注意,是否 A A A是一個以對角線為對稱軸的對稱矩陣呢?雖然 Q ? K T Q·K^T Q?KT是對稱的,但是經過Softmax后,每一行都會轉換為概率分布,這樣“位置3對位置2的影響”與“位置2對位置3的影響”就不同了。
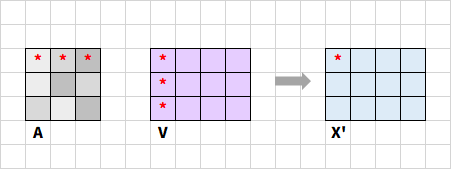
接下來要計算 A ? V A·V A?V,表示每個位置綜合其他位置的加權求和。
1.2 多頭注意力
若使用多頭注意力,只是列的長度發生改變,被均分成頭的數量。假設輸入序列的維度為(batch_size, seq_len, d_model),通過線性變換矩陣 W Q , W K , W V ∈ R d m o d e l × d k W^Q, W^K, W^V ∈ \mathbb{R}^{d_{model}×d_{k}} WQ,WK,WV∈Rdmodel?×dk?生成 Q Q Q/ K K K/ V V V,形狀為(batch_size, seq_len, d_k),其中 d k = d m o d e l h d_k=\frac{d_model}{h} dk?=hdm?odel?(h為多頭注意力頭數)。
在多頭注意力(Multi-Head Attention)中, A A A的格式會擴展為四維張量:(batch_size, num_heads, n, n),batch_size表示樣本批次大小,num_heads表示注意力頭數,n表示序列長度。
1.3 交叉注意力
1.3.1 基礎
標準的自注意力機制中, Q Q Q/ K K K/ V V V通常由同一個輸入矩陣 x x x通過不同的線性變換生成。自注意力機制關注于單一輸入序列內部元素之間的關系,通過同源輸入捕捉序列內部依賴關系。
交叉注意力(Cross-Attention)則關注于兩個不同輸入序列之間的相互作用。 Q Q Q和 K K K可以分布來自不同的輸入序列,常見于編碼器-解碼器架構。
在Transformer模型中,CrossAttention通常用于編碼器和解碼器之間的交互。編碼器負責將輸入序列編碼為一系列特征向量,而解碼器則根據這些特征向量逐步生成輸出序列。為了使解碼器能夠更有效地利用編碼器的信息,CrossAttention層被引入其中。解碼器的每個位置會生成一個查詢向量(query),該向量用于在編碼器的所有位置進行注意力權重計算。編碼器的每個位置則生成一組鍵向量(keys)和值向量(values)。通過計算查詢向量與鍵向量的相似度,并經過softmax函數歸一化后,得到注意力權重。最后,注意力權重與值向量相乘并求和,得到編碼器調整后的輸出,供解碼器使用。
Q Q Q是來自解碼器的當前狀態(例如翻譯任務中的目標語言詞, K K K和 V V V是來自編碼器的輸出(例如源語言的特征)。
Softmax僅要求 Q Q Q和 K K K的維度匹配,并不限制來源。
假設 Q Q Q的輸入形狀為(batch_size, seq_len_q, d_model),seq_len_q為目標序列長度; K K K/ V V V的輸入形狀為(batch_size, seq_len_kv, d_model),seq_len_kv為源序列長度,輸出的形狀為(batch_size, h, seq_len_q, seq_len_kv)。
最終輸出的注意力權重矩陣 A A A作用于 V V V矩陣,生成融合跨序列信息的輸出 O u t p u t = A ? V Output=A·V Output=A?V。
Q Q Q由解碼器的自注意力層輸出生成,解碼器在生成目標序列的每一步時,會將已生成的部分序列通過掩碼自注意力層處理,生成當前步的上下文表示,這一表示作為 Q Q Q的輸入。
以機器翻譯為例,將“我喜歡狼”由中文翻譯成英文。每次生成一個詞,假設當前已經生成了"I"、“LIKE”,接下來要進行后面的詞的翻譯,如下圖。 x 1 ′ x1' x1′是已經生成的上下文表示,由解碼器的自注意力層輸出。 x 2 ′ x2' x2′是源序列“我喜歡狼”經編碼器輸出的特征向量。
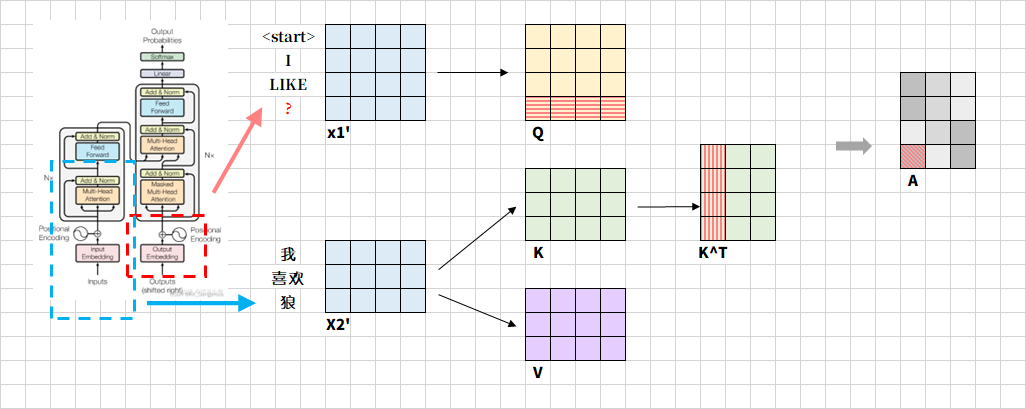
圖示紅色問號表示待生成的詞語,當生成第三個目標詞時,原矩陣新增一行,該行表示問號詞對源序列所有三個詞的關注權重,而該行的初始值是基于已生成的詞的嵌入向量和位置編碼生成。對于A,表示接下來要生成的詞與源序列的相關度,比如紅色陰影部分表示問號詞與“我”的語義依賴強度。
?強對齊??:目標詞與源詞存在直接翻譯關系(如"WOLVES"→"狼"),對應權重接近1。
??弱對齊??:目標詞依賴源序列的上下文(如生成冠詞 “THE” 時可能關注源序列的主語位置)。
??零權重??:源詞與當前目標詞無關(如生成英文標點時,權重集中于源序列的句尾詞)。
1.3.2 進階
編碼器的 K K K和 V V V在推理時是固定不變的,但解碼器的 Q Q Q隨著目標序列生成動態擴展。例如,生成“WOLVES”時, Q 3 Q_3 Q3?需與編碼器的 K K K計算相似度,而歷史 Q Q Q和編碼器的 K K K可能已經被緩存,然后只需要計算 ∑ j = 0 4 A 3 ? V j \sum_{j=0}^{4}A_3·V_j ∑j=04?A3??Vj?即可。
訓練階段,不需要考慮生成詞的先后順序,模型并行處理整個目標序列而非逐詞生成,此時所有目標詞的 Q Q Q必須同時計算,以利用GPU的并行計算能力加速訓練。同時,需要通過反向傳播更新所有Q的權重矩陣 W Q W_Q WQ?,這要求通過計算完整的 Q Q Q矩陣計算所有注意力權重 A A A,才能正確更新權重矩陣 W Q W_Q WQ?,如果僅計算 Q 3 ? K T Q_3·K^T Q3??KT,將導致 W Q W_Q WQ?的梯度無法涵蓋歷史位置的語義關聯。
每個注意力頭的 W Q W_Q WQ?矩陣是固定維度的(d_model×d_k),將每行向量從原來指定的特征向量長度轉換為分多頭之后的特征向量長度,無論目標序列長度如何,所有 Q Q Q向量均通過同一組 W Q W_Q WQ?進行投影。這種設計使得模型能夠處理任意長度的目標序列,但要求所有 Q Q Q的投影邏輯一致。
解碼器隱狀態 H i H_i Hi?指的是解碼器在第 i i i步生成的動態時序表示,包含目標序列的生成進度(如已生成的詞數 i i i)、上下文語義、目標序列內部依賴,計算公式為 s i = g ( s i ? 1 , y i ? 1 , c ) s_i=g(s_{i-1}, y_{i-1}, c) si?=g(si?1?,yi?1?,c),其中 g g g是解碼器的更新函數, c c c是編碼器的上下文向量。
參考來源:
AIGC
深入理解CrossAttention:交叉注意力機制的奧秘
【深度學習】Cross-Attention(交叉注意力)機制詳解與應用
![洛谷 P1955 [NOI2015] 程序自動分析](http://pic.xiahunao.cn/洛谷 P1955 [NOI2015] 程序自動分析)
![[Java] 輸入輸出方法+猜數字游戲](http://pic.xiahunao.cn/[Java] 輸入輸出方法+猜數字游戲)
)













)


介紹)