一、SpringAI 顧問(Advisors)
Spring AI 使用 Advisors機制來增強 AI 的能力,可以理解為一系列可插拔的攔截器,在調用 AI 前和調用 AI 后可以執行一些額外的操作,比如:
- 前置增強:調用 AI 前改寫一下 Prompt 提示詞、檢查一下提示詞是否安全
- 后置增強:調用 AI 后記錄一下日志、處理一下返回的結果
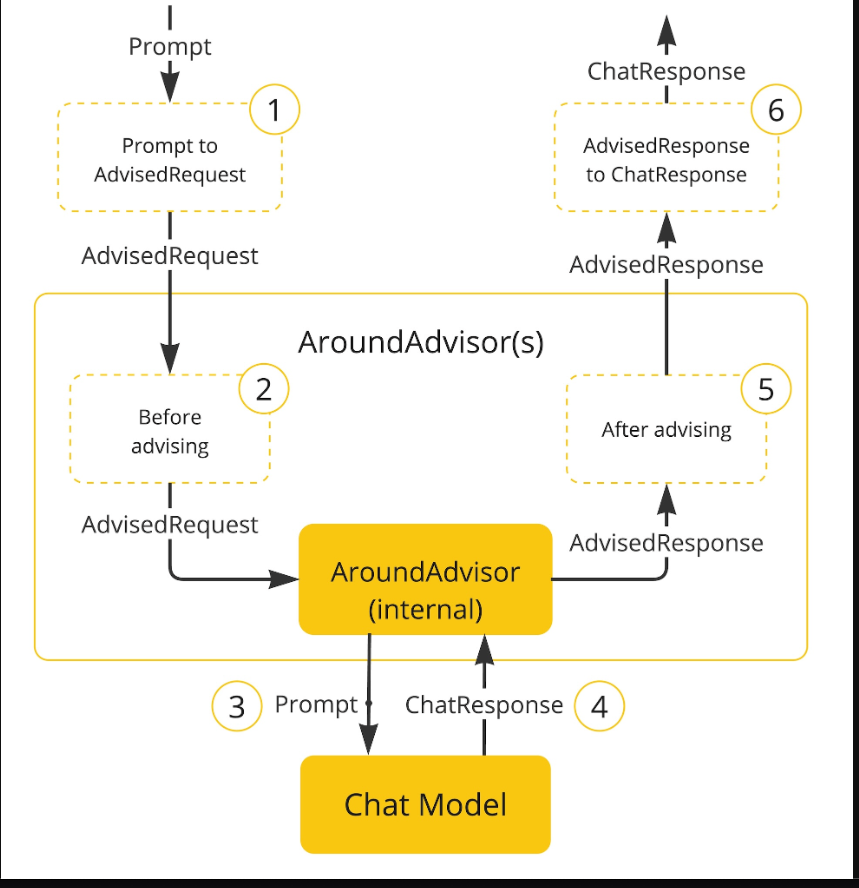
解釋上圖的執行流程:
- Spring AI 框架從用戶的 Prompt 創建一個 AdvisedRequest,同時創建一個空的 AdvisorContext 對象,用于傳遞信息。
- 鏈中的每個 advisor 處理這個請求,可能會對其進行修改。或者,它也可以選擇不調用下一個實體來阻止請求繼續傳遞,這時該 advisor 負責填充響應內容。
- 由框架提供的最終 advisor 將請求發送給聊天模型 ChatModel。
- 聊天模型的響應隨后通過 advisor 鏈傳回,并被轉換為 AdvisedResponse。后者包含了共享的 AdvisorContext 實例。
- 每個 advisor 都可以處理或修改這個響應。
- 最終的 AdvisedResponse 通過提取 ChatCompletion 返回給客戶端。
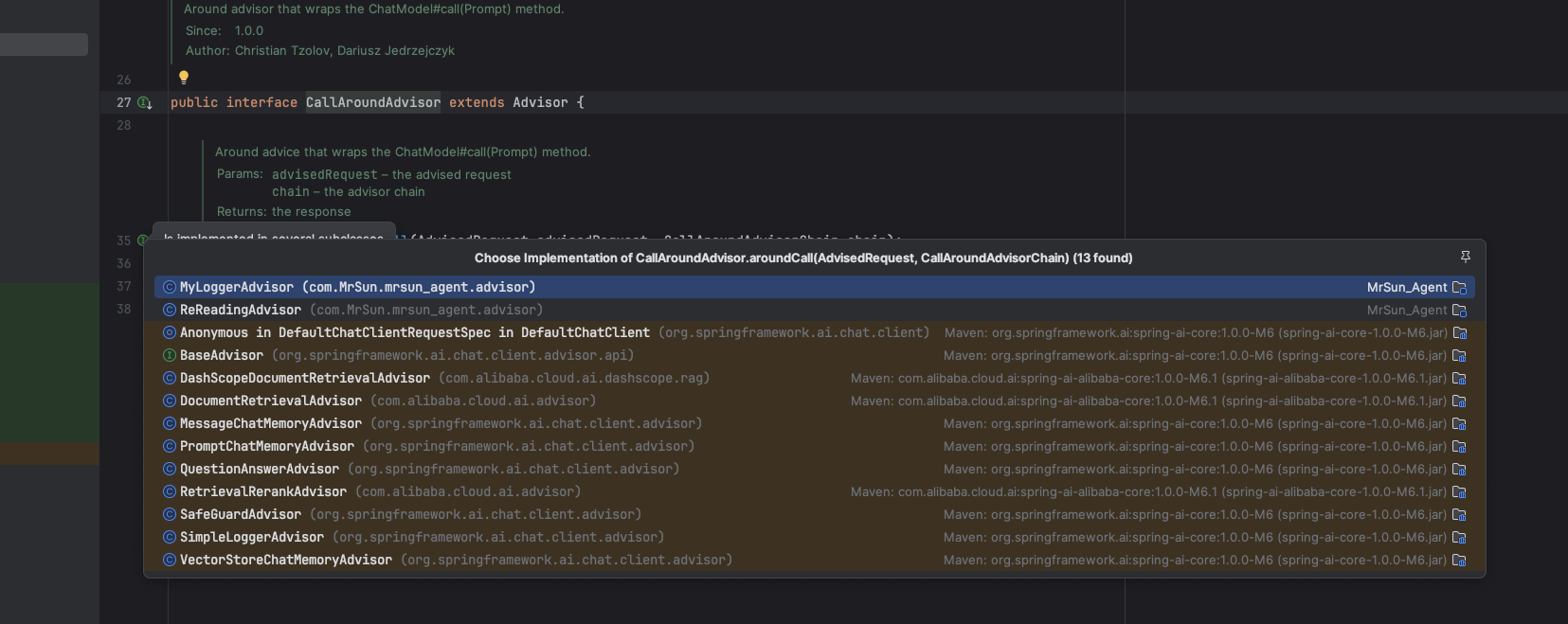
自定義實現攔截器:
- CallAroundAdvisor:用于處理同步請求和響應(非流式)
- StreamAroundAdvisor:用于處理流式請求和響應
由于源碼中實現類很多、所以我們可以自定義攔截器
package com.MrSun.mrsun_agent.advisor;import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.client.advisor.api.*;
import org.springframework.ai.chat.model.MessageAggregator;
import reactor.core.publisher.Flux;/*** 自定義日志 Advisor* 打印 info 級別日志、只輸出單次用戶提示詞和 AI 回復的文本*/
@Slf4j
public class MyLoggerAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {@Overridepublic String getName() {return this.getClass().getSimpleName();}@Overridepublic int getOrder() {return 0;}/**** @param request* @return*/private AdvisedRequest before(AdvisedRequest request) {// 日志輸出log.info("AI Request: {}", request.userText());return request;}private void observeAfter(AdvisedResponse advisedResponse) {log.info("AI Response: {}", advisedResponse.response().getResult().getOutput().getText());}public AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {// 先執行before 處理請求,然后在進行處理響應advisedRequest = this.before(advisedRequest);AdvisedResponse advisedResponse = chain.nextAroundCall(advisedRequest);this.observeAfter(advisedResponse);return advisedResponse;}public Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {advisedRequest = this.before(advisedRequest);Flux<AdvisedResponse> advisedResponses = chain.nextAroundStream(advisedRequest);// 消息聚合器 等到一起在進行響應return (new MessageAggregator()).aggregateAdvisedResponse(advisedResponses, this::observeAfter);}
}
1、Chat Memory Advisor
前面我們提到了,想要實現對話記憶功能,可以使用 Spring AI 的 ChatMemoryAdvisor,它主要有幾種內置的實現方式:
- MessageChatMemoryAdvisor:從記憶中檢索歷史對話,并將其作為消息集合添加到提示詞中
- PromptChatMemoryAdvisor:從記憶中檢索歷史對話,并將其添加到提示詞的系統文本中
- VectorStoreChatMemoryAdvisor:可以用向量數據庫來存儲檢索歷史對話
1)MessageChatMemoryAdvisor 將對話歷史作為一系列獨立的消息添加到提示中,保留原始對話的完整結構,包括每條消息的角色標識(用戶、助手、系統)。
[{"role": "user", "content": "你好"},{"role": "assistant", "content": "你好!有什么我能幫助你的嗎?"},{"role": "user", "content": "講個笑話"}
]
2)PromptChatMemoryAdvisor 將對話歷史添加到提示詞的系統文本部分,因此可能會失去原始的消息邊界。
以下是之前的對話歷史:
用戶: 你好
助手: 你好!有什么我能幫助你的嗎?
用戶: 講個笑話
現在請繼續回答用戶的問題。
一般情況下,更建議使用 MessageChatMemoryAdvisor。更符合大多數現代 LLM 的對話模型設計,能更好地保持上下文連貫性。
2、Chat Memory
上述 ChatMemoryAdvisor 都依賴 [Chat Memory]進行構造,Chat Memory 負責歷史對話的存儲,定義了保存消息、查詢消息、清空消息歷史的方法。其實就是基本的增刪改查
Spring AI 內置了幾種 Chat Memory,可以將對話保存到不同的數據源中,比如:
- InMemoryChatMemory:內存存儲
- CassandraChatMemory:在 Cassandra 中帶有過期時間的持久化存儲
- Neo4jChatMemory:在 Neo4j 中沒有過期時間限制的持久化存儲
- JdbcChatMemory:在 JDBC 中沒有過期時間限制的持久化存儲
實現對話記憶
1)首先初始化 ChatClient 對象。使用 Spring 的構造器注入方式來注入阿里大模型 dashscopeChatModel 對象,并使用該對象來初始化 ChatClient。初始化時指定默認的系統 Prompt 和基于內存的對話記憶 Advisor。代碼如下:
@Component
@Slf4j
public class LoveApp {private final ChatClient chatClient;private static final String SYSTEM_PROMPT = "扮演深耕戀愛心理領域的專家。開場向用戶表明身份,告知用戶可傾訴戀愛難題。" +"圍繞單身、戀愛、已婚三種狀態提問:單身狀態詢問社交圈拓展及追求心儀對象的困擾;" +"戀愛狀態詢問溝通、習慣差異引發的矛盾;已婚狀態詢問家庭責任與親屬關系處理的問題。" +"引導用戶詳述事情經過、對方反應及自身想法,以便給出專屬解決方案。";public LoveApp(ChatModel dashscopeChatModel) {// 初始化基于內存的對話記憶ChatMemory chatMemory = new InMemoryChatMemory();chatClient = ChatClient.builder(dashscopeChatModel).defaultSystem(SYSTEM_PROMPT).defaultAdvisors(new MessageChatMemoryAdvisor(chatMemory)).build();}
}
2)編寫對話方法。調用 chatClient 對象,傳入用戶 Prompt,并且給 advisor 指定對話 id 和對話記憶大小。代碼如下:
public String doChat(String message, String chatId) {ChatResponse response = chatClient.prompt().user(message).advisors(spec -> spec.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId).param(CHAT_MEMORY_RETRIEVE_SIZE_KEY, 10)).call().chatResponse();String content = response.getResult().getOutput().getText();log.info("content: {}", content);return content;
}
3)編寫單元測試,測試多輪對話:
@Testvoid testChat() {//生成一個繪畫IDString chatId= UUID.randomUUID().toString();//第一輪String message="你好,我是南瓜";String answer= loveApp.doChat(message,chatId);//第二輪message="我想讓另一半(松鼠)更喜歡我";answer= loveApp.doChat(message,chatId);Assertions.assertNotNull(answer);//第三輪message="我的另一半是誰了。我忘記了,你幫我回憶一下";answer= loveApp.doChat(message,chatId);Assertions.assertNotNull(answer);}
效果如下:
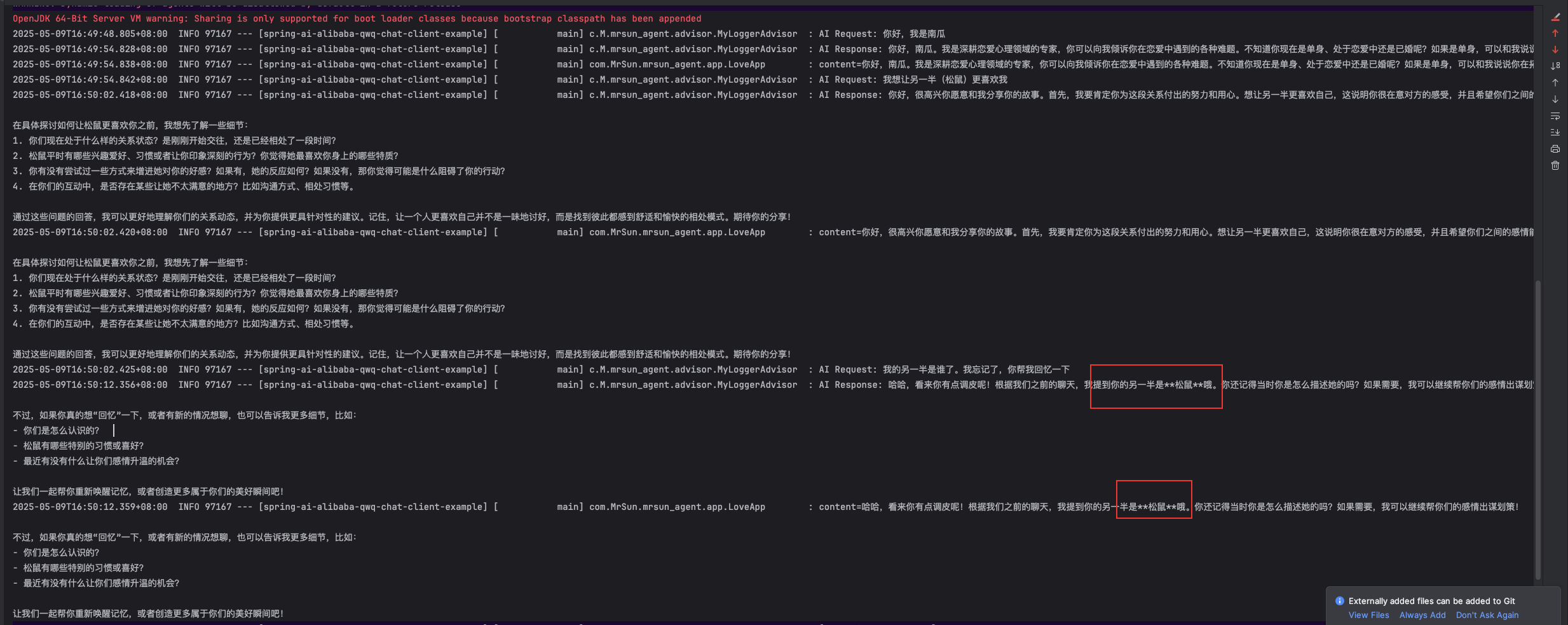
這樣就可以實現多輪對話功能。
3、Re-Reading Advisor
實現一個 Re-Reading(重讀)Advisor,又稱 Re2。該技術通過讓模型重新閱讀問題來提高推理能力,有文獻 來印證它的效果。
注意:雖然該技術可提高大語言模型的推理能力,不過成本會加倍!
Re2 的實現原理很簡單,改寫用戶 Prompt 為下列格式,也就是讓 AI 重復閱讀用戶的輸入:
/*** 自定義 Re2 Advisor* 可提高大型語言模型的推理能力*/
public class ReReadingAdvisor implements CallAroundAdvisor, StreamAroundAdvisor {private AdvisedRequest before(AdvisedRequest advisedRequest) {Map<String, Object> advisedUserParams = new HashMap<>(advisedRequest.userParams());advisedUserParams.put("re2_input_query", advisedRequest.userText());return AdvisedRequest.from(advisedRequest).userText("""{re2_input_query}Read the question again: {re2_input_query}""").userParams(advisedUserParams).build();}@Overridepublic AdvisedResponse aroundCall(AdvisedRequest advisedRequest, CallAroundAdvisorChain chain) {return chain.nextAroundCall(this.before(advisedRequest));}@Overridepublic Flux<AdvisedResponse> aroundStream(AdvisedRequest advisedRequest, StreamAroundAdvisorChain chain) {return chain.nextAroundStream(this.before(advisedRequest));}@Overridepublic int getOrder() {return 0;}@Overridepublic String getName() {return this.getClass().getSimpleName();}
}
以上就是SpringAI的一些特性。







4.8定時器QTimer 與QElapsedTimer:理論,例題的界面搭建,與功能的代碼實現。)




)
)





----函數calibrate)