? ? ? ? 之前有說過,通過pytest測試框架標記參數化功能可以實現數據驅動測試。數據驅動測試使用的文件主要有以下類型:
- txt 文件?
- csv 文件
- excel 文件
- json 文件
- yaml 文件
- ....
本文主要講的就是以上幾種文件類型的讀取和使用
一.txt 文件讀取使用
? ? ? ? 首先創建一個 txt 文件,文件內容為:
張三,男,2024-09-10
李四,女,2022-09-10
王五,男,2090-09-10
?然后讀取文件內容
def get_txt_data():with open(r"D:\python_project\API_Auto\API3\data\txt_data", encoding="utf-8") as file:content = file.readlines()# print(content)# 去掉數據后面的換行符list_data = []list_data1 = []for i in content:list_data.append(i.strip())# 將數據分割for i in list_data:list_data1.append(i.split(","))return list_data1
這樣就得到了 符合參數化要求的參數,對讀取的內容進行使用:
@pytest.mark.parametrize(("name", "gender", "data"), get_txt_data())
def test_txt_func(name, gender, data):print(f'輸入名字:{name}')print(f'輸入性別 :{gender}')print(f'輸入日期:{data}')
輸出為:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... [['張三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_txt_func[張三-男-2024-09-10] 輸入名字:張三
輸入性別 :男
輸入日期:2024-09-10
PASSED
testcases/test_ddt.py::test_txt_func[李四-女-2022-09-10] 輸入名字:李四
輸入性別 :女
輸入日期:2022-09-10
PASSED
testcases/test_ddt.py::test_txt_func[王五-男-2090-09-10] 輸入名字:王五
輸入性別 :男
輸入日期:2090-09-10
PASSED============================== 3 passed in 0.06s ==============================
Report successfully generated to .\reportProcess finished with exit code 0
二.csv 文件讀取使用
首先創建一個csv文件,內容為:
1,2,3 1,3,3 2,2,4
?然后讀取文件內容
import csvdef get_csv_data():list1 = []f = csv.reader(open(r"D:\python_project\API_Auto\API3\data\x_y_z.csv", encoding="utf-8"))for i in f:# list1.append(i.strip())# [int(element) for element in i], 列表推導式,它的作用是對 i 中的每個元素進行遍歷,并將每個元素從字符串(str)轉換為整數(int)a = [int(element) for element in i]list1.append(a)return list1
然后使用讀取到的數據
@pytest.mark.parametrize(("x", "y", "z"), get_csv_data()
)
def test_csv_func(x, y, z):assert x * y == z
輸出為:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... [['張三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_csv_func[1-2-3] FAILED
testcases/test_ddt.py::test_csv_func[1-3-3] PASSED
testcases/test_ddt.py::test_csv_func[2-2-4] PASSED================================== FAILURES ===================================
____________________________ test_csv_func[1-2-3] _____________________________x = 1, y = 2, z = 3@pytest.mark.parametrize(("x", "y", "z"), get_csv_data())def test_csv_func(x, y, z):
> assert x * y == z
E assert (1 * 2) == 3testcases\test_ddt.py:21: AssertionError
----------------------------- Captured log setup ------------------------------
WARNING pytest_result_log:plugin.py:122 ---------------Start: testcases/test_ddt.py::test_csv_func[1-2-3]---------------
---------------------------- Captured log teardown ----------------------------
WARNING pytest_result_log:plugin.py:128 ----------------End: testcases/test_ddt.py::test_csv_func[1-2-3]----------------
=========================== short test summary info ===========================
FAILED testcases/test_ddt.py::test_csv_func[1-2-3] - assert (1 * 2) == 3
========================= 1 failed, 2 passed in 0.13s =========================
Report successfully generated to .\reportProcess finished with exit code 0
三.excel 文件讀取使用
首先創建一個excel文件,文件內容為:
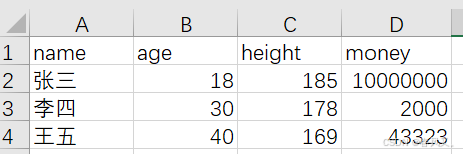
然后在讀取Excel數據內容前,要針對不同版本使用不同的第三方庫
- xls
- office 2003版本
- 安裝:xlrd第三庫
- 必須指定版本
- pip install xlrd==1.2.0
- office 2003版本
- xlsx
- office 2016版本
- 安裝:openpyxl第三方庫
- 默認安裝最新的版本庫即可
- pip install openpyxl
- office 2016版本
安裝完后,讀取 數據:
import xlrd# # 讀取excel 文件數據獲取xls文件對象
# xls = xlrd.open_workbook(r'D:\python_project\API_Auto\API3\data\test.xlsx')
#
# # 獲取excel 中的sheet 表,0代表第一張 表的索引、
# sheet = xls.sheet_by_index(0)
#
# # 輸出數據列
# print(sheet.ncols)
#
# # 輸出數據行
# print(sheet.nrows)
#
# # 讀取具體某一行內容,0代表第一行數據索引
# print(sheet.row_values(1))
#def get_excel_data(path):list_excel = []xls = xlrd.open_workbook(path)# 獲取excel 中的sheet 表,0代表第一張 表的索引、sheet = xls.sheet_by_index(0)for i in range(sheet.nrows):list_excel.append(sheet.row_values(i))# 刪除表頭數據list_excel.pop(0)# print(list_excel)return list_excel
使用讀取到的數據:
@pytest.mark.parametrize(("name", "age", "height", "money"), get_excel_data(r"D:\python_project\API_Auto\API3\data\test.xlsx")
)
def test_excel_func(name, age, height, money):print(f"name是{name},age是{age},height是{height},money是{money}")
輸出結果為 :
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... collected 3 itemstestcases/test_ddt.py::test_excel_func[張三-18.0-185.0-10000000.0] name是張三,age是18.0,height是185.0,money是10000000.0
PASSED
testcases/test_ddt.py::test_excel_func[李四-30.0-178.0-2000.0] name是李四,age是30.0,height是178.0,money是2000.0
PASSED
testcases/test_ddt.py::test_excel_func[王五-40.0-169.0-43323.0] name是王五,age是40.0,height是169.0,money是43323.0
PASSED============================== 3 passed in 0.09s ==============================
Report successfully generated to .\reportProcess finished with exit code 0
四.json 文件的讀取使用
首先創建一個json文件,內容為:
[[1,2,3],[4,2,6],[7,8,9] ]
然后讀取文件內容
def get_json_data(path):with open(path, encoding="utf-8") as file:content = file.read()# print(eval(content))# print(type(eval(content)))# eval() : 去掉最外層的引號return eval(content)
對讀取到的內容進行使用:
@pytest.mark.parametrize(("x", "y", "z"), get_json_data(r'D:\python_project\API_Auto\API3\data\json.json')
)
def test_json_func(x, y, z):assert x + y == z
輸出結果為:
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... collected 3 itemstestcases/test_ddt.py::test_json_func[1-2-3] PASSED
testcases/test_ddt.py::test_json_func[4-2-6] PASSED
testcases/test_ddt.py::test_json_func[7-8-9] FAILED================================== FAILURES ===================================
____________________________ test_json_func[7-8-9] ____________________________x = 7, y = 8, z = 9@pytest.mark.parametrize(("x", "y", "z"), get_json_data(r'D:\python_project\API_Auto\API3\data\json.json'))def test_json_func(x, y, z):
> assert x + y == z
E assert (7 + 8) == 9testcases\test_ddt.py:35: AssertionError
----------------------------- Captured log setup ------------------------------
WARNING pytest_result_log:plugin.py:122 --------------Start: testcases/test_ddt.py::test_json_func[7-8-9]---------------
---------------------------- Captured log teardown ----------------------------
WARNING pytest_result_log:plugin.py:128 ---------------End: testcases/test_ddt.py::test_json_func[7-8-9]----------------
=========================== short test summary info ===========================
FAILED testcases/test_ddt.py::test_json_func[7-8-9] - assert (7 + 8) == 9
========================= 1 failed, 2 passed in 0.14s =========================
Report successfully generated to .\reportProcess finished with exit code 0
五.yaml 文件讀取使用?
1.yaml數據讀寫
序列化:內存中數據,轉化為文件
反序列化:將文件轉化為內存數據 需要操作yaml文件,安裝第三方庫
? ? ? ? ? ? ? ? ??pip install pyyaml
2.序列化 ?將yaml 數據寫入文件中
"""
YAML 是一個可讀性 高,用來達標數據序列化的格式基本語法格式:1.區分大小寫2.使用縮進表示層級 關系3.縮進不能 使用 tab 建,只能使用空格4.縮進的空格數不重要,只要相同 層級的元素左對齊即可5.可以使用 注釋符號 #yaml 序列化 常用數據類型:1.對象(python中的 字段,鍵值對)2.數組(python 中的列表 )3.純量:單個的、不可再分值4.布爾值5.空值YAML 數據讀寫:序列化:將內存 中數據轉化為文件反序列化 :將文件轉化為內存數據需要安裝第三方庫:pip install pyyaml
"""data = {'數字': [1, 2, 3, 4, -1],'字符串': ["a", "@#", "c"],'空值': None,'布爾值': [True, False],'元組': (1, 2, 3)
}import yaml# 將 python 數據類型,轉換為yaml 格式
yaml_data = yaml.safe_dump(data, # 要轉化的數據內容allow_unicode=True, # 允許unicode 字符,中文原樣顯示sort_keys=False # 不進行排序,原樣輸出
)# 序列化 將yaml 數據寫入文件中
f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "w", encoding="utf-8")
f.write(yaml_data)
f.close()
3.反序列化 讀取yaml 文件中的數據
# 反序列化 讀取yaml 文件中的數據
f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "r", encoding="utf-8")
s = f.read()
data_yaml = yaml.safe_load(s)
print(data_yaml)4.寫入一個大列表里面嵌套小列表
# 寫入一個大列表里面嵌套小列表list1 = [['張三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]yaml_data = yaml.safe_dump(list1, # 要轉化的數據內容allow_unicode=True, # 允許unicode 字符,中文原樣顯示sort_keys=False # 不進行排序,原樣輸出
)# 序列化 將yaml 數據寫入文件中
f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "w", encoding="utf-8")
f.write(yaml_data)
f.close()完整代碼為:
data = {'數字': [1, 2, 3, 4, -1],'字符串': ["a", "@#", "c"],'空值': None,'布爾值': [True, False],'元組': (1, 2, 3)
}import yamldef get_yaml_data():# 將 python 數據類型,轉換為yaml 格式yaml_data = yaml.safe_dump(data, # 要轉化的數據內容allow_unicode=True, # 允許unicode 字符,中文原樣顯示sort_keys=False # 不進行排序,原樣輸出)# 序列化 將yaml 數據寫入文件中f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "w", encoding="utf-8")f.write(yaml_data)f.close()# 反序列化 讀取yaml 文件中的數據f = open(r"D:\python_project\API_Auto\API3\data\yaml.yaml", "r", encoding="utf-8")s = f.read()data_yaml = yaml.safe_load(s)print(data_yaml)# 寫入一個大列表里面嵌套小列表list1 = [['張三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]yaml_data = yaml.safe_dump(list1, # 要轉化的數據內容allow_unicode=True, # 允許unicode 字符,中文原樣顯示sort_keys=False # 不進行排序,原樣輸出)# 序列化 將yaml 數據寫入文件中f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "w", encoding="utf-8")f.write(yaml_data)f.close()# 反序列化 讀取yaml 文件中的數據f = open(r"D:\python_project\API_Auto\API3\data\yaml1.yaml", "r", encoding="utf-8")s = f.read()data_yaml1 = yaml.safe_load(s)print(data_yaml1)return data_yaml1
使用讀取到的數據:
@pytest.mark.parametrize(("x"), get_yaml_data()
)
def test_yaml_func(x):for i in x:print(i)
輸出為 :
D:\python_project\API_Auto\API3\venv\Scripts\python.exe D:\python_project\API_Auto\API3\main.py
============================= test session starts =============================
platform win32 -- Python 3.10.6, pytest-8.3.5, pluggy-1.5.0 -- D:\python_project\API_Auto\API3\venv\Scripts\python.exe
cachedir: .pytest_cache
rootdir: D:\python_project\API_Auto\API3
configfile: pytest.ini
plugins: allure-pytest-2.13.5, result-log-1.2.2
collecting ... {'數字': [1, 2, 3, 4, -1], '字符串': ['a', '@#', 'c'], '空值': None, '布爾值': [True, False], '元組': [1, 2, 3]}
[['張三', 18.0, 185.0, 10000000.0], ['李四', 30.0, 178.0, 2000.0], ['王五', 40.0, 169.0, 43323.0]]
collected 3 itemstestcases/test_ddt.py::test_yaml_func[x0] 張三
18.0
185.0
10000000.0
PASSED
testcases/test_ddt.py::test_yaml_func[x1] 李四
30.0
178.0
2000.0
PASSED
testcases/test_ddt.py::test_yaml_func[x2] 王五
40.0
169.0
43323.0
PASSED============================== 3 passed in 0.10s ==============================
Report successfully generated to .\reportProcess finished with exit code 0


閃屏)











)




VTK C++開發示例 ---紋理地球)