筆者在2022年開始學習目標檢測的時候,對各種框的概念那是相當混淆,比如:
- 中文名詞:邊界框、錨框、真實框、預測框等
- 英文名詞:BoundingBox、AnchorBox、Ground Truth等
同一個英文名詞比如BoundingBox翻譯成中文也有多個叫法。下面注重區分這些概念。
一、真實框Ground Truth & 邊界框Bounding Box
1??真實框Ground Truth與邊界框Bounding Box的定義
目標檢測需要識別圖片中多個物體的位置與類別。
為了方便模型訓練,我們人為地將圖片中物體的位置與種類標注出來,這就是真實邊界框Ground Truth。
- 「Ground Truth」等價于「Ground Truth Bounding Box(GT BBox)」
邊界框Bounding Box則更多的是一種泛指,它可以指代各個類型的框。
2??GT BBox的標注常見于兩種形式:
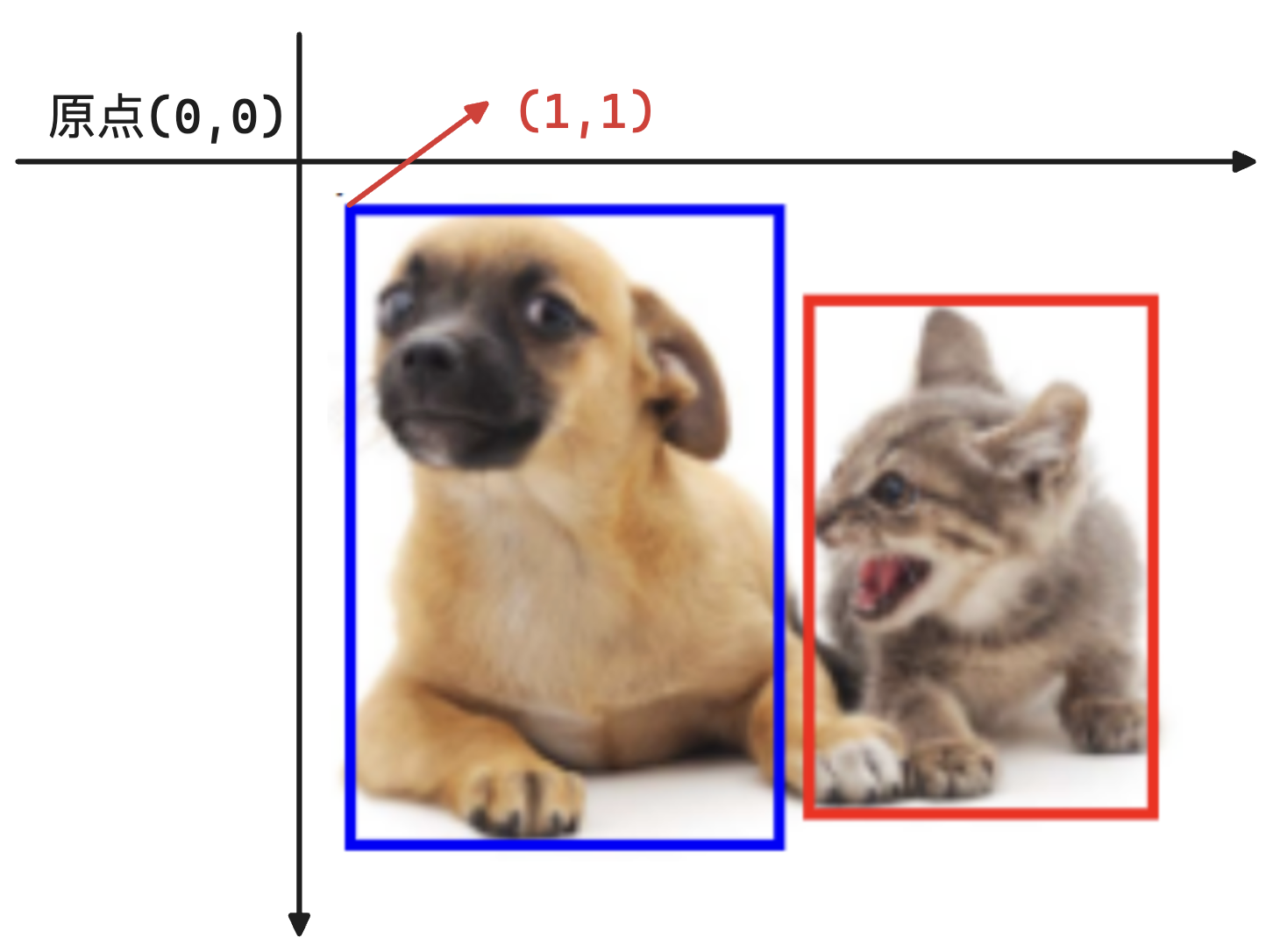
- PascalVOC的xml標注文件: ( x 1 , y 1 , x 2 , y 2 ) (x_1, y_1, x_2, y_2) (x1?,y1?,x2?,y2?),分別是矩形框左上角、右下角的坐標;
如下圖中的坐標(1, 1)。 - COCO的json標注文件: ( x , y , w , h ) (x, y, w, h) (x,y,w,h),xy是矩陣框的中心點坐標,wh是矩陣框的寬高;
標注文件中每行表示一個物體,一般是:圖片文件名、物體類別、邊緣框。
二、邊界框的回歸 BoundingBox Regression
模型對其「預測框」進行微調,使其接近Ground Truth Bounding Box。
如下圖對紅色的BBox回歸,使其接近綠色的GT Box。

三、錨框Anchor Box
1??Ground Truth Bounding Box與Anchor的區別:
錨框Anchor是算法自動生成出的,GT BBox是人為的標注框。
目前定位精準的目標檢測算法還是基于錨框的,即Anchor-based。
2??錨框的使用:
3??在目標檢測任務中,我們如何選擇錨框尺寸?
1)要么設定好錨框的尺寸:
-
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32
2)要么通過k-means自動生成錨框,比如yolov5默認通過k-means自動生成錨框尺寸
3)作為超參數學習。我還沒見過,估計這會產生額外的計算量
4??錨框的標注過程
主流的目標檢測算法大多基于錨框Anchor Box,每一個錨框都是一個訓練樣本。
對于每個錨框,要么標注成背景(負樣本),要么關聯上一個真實邊界框(正樣本)。
一張圖片可能會產生上萬個錨框,其中絕大多數都是背景,即大量的負樣本,與之相比,正樣本可能只有幾十個。
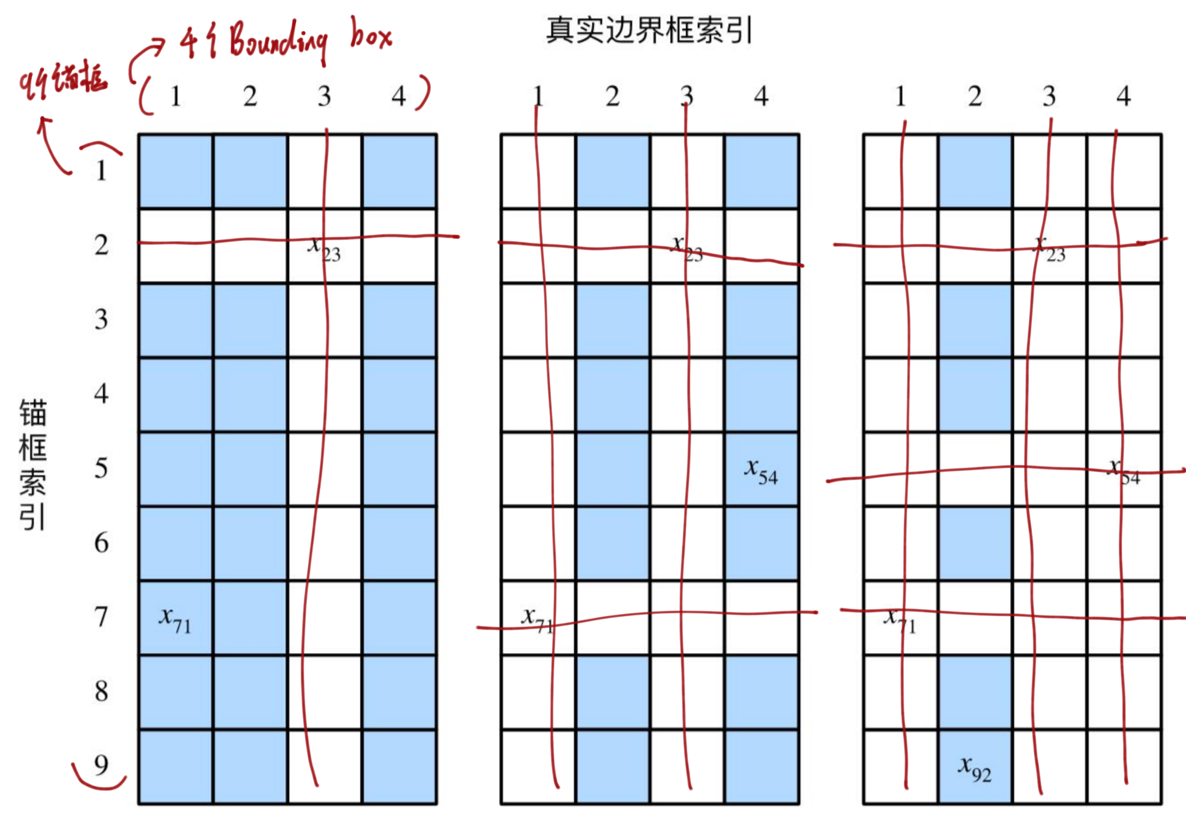
- 假設4個目標物體對應著4個GT BBox,模型對每個目標物體各生成9個錨框;
- 計算每個GT與Anchor之間的IoU值,找到當前最大的IoU值 x 23 x_{23} x23?,將錨框關聯上BBox_3,由它去預測BBox_3。刪去該行該列;
- 繼續找當前最大的IoU值 x 71 x_{71} x71?,重復如上操作,刪去該行該列;
與BBox關聯的錨框作為正樣本,其他的作為背景就是負樣本。
PS:Anchor的概念最早出現在Faster RCNN提出的RPN網絡,RPN網絡的Anchor啟發了后面的SSD和Yolov2算法。
四、額外:召回與排序的概念
召回:將所有“可能的正確結果”返回給排序
排序:會將所有召回的結果進行排序,將最靠前的結果作為最終答案
如果這篇文章對您有些許幫助,請幫忙點個贊👍或收個藏📃。您的支持是我繼續創作的動力💪!
不要害怕,不要著急。保持每日的前進??與積極的內心??,命運總在曲折中饋贈最好的禮物。
:[macOS 64bit App開發]: [1]如何使用原生NSAlert消息框 (runModal模式)](http://pic.xiahunao.cn/[原創](現代Delphi 12指南):[macOS 64bit App開發]: [1]如何使用原生NSAlert消息框 (runModal模式))

![[特殊字符] Spring Cloud 微服務配置統一管理:基于 Nacos 的最佳實踐詳解](http://pic.xiahunao.cn/[特殊字符] Spring Cloud 微服務配置統一管理:基于 Nacos 的最佳實踐詳解)







: ておき ます)


)

--圖片上傳與OCR識別)
)


